
从零到一:深入解析五大基础排序算法(附完整代码与性能对比)
排序是计算机科学中最基础、最核心的操作之一,无论是处理海量数据还是优化用户体验,高效的排序算法都扮演着关键角色。本文将从基础概念出发,深入剖析五种经典的排序算法,通过清晰的代码实现和性能对比,帮助你构建坚实的算法基础,并为后续学习更复杂的算法铺平道路。
一、排序算法:概念、分类与应用场景
排序算法的本质,是将一组数据按照特定关键字(如数值大小、字母顺序)进行递增或递减的重新排列。这项操作不仅是数据结构与算法的基石,更渗透在我们日常的数字生活中。
- 电商购物:当你按价格、销量或评分筛选商品时,背后正是排序算法在高效工作。
- 榜单排名:无论是院校排行榜、游戏天梯,还是通讯录列表,都离不开排序的支持。
- 数据处理:在数据分析、数据库索引和机器学习特征工程中,排序通常是预处理的关键一步。
从实现原理上,排序算法主要分为两大类:比较排序和非比较排序。比较排序(如本文将要介绍的插入、选择、交换排序)通过元素间的两两比较来决定次序,通用性强但存在理论效率上限(O(NlogN))。非比较排序(如计数排序、桶排序)则利用数据的特定属性(如整数范围)直接定位,在特定场景下可以达到惊人的O(N)线性时间复杂度。理解这些基础概念,是选择合适算法的第一步。
[AFFILIATE_SLOT_1]二、插入排序:从“整理扑克牌”到效率优化
插入排序的思想非常直观,类似于我们整理手中的扑克牌。它的核心是维护一个“已排序”的序列,然后将未排序的元素逐个“插入”到这个序列的正确位置。
2.1 直接插入排序
直接插入排序是插入排序家族中最基础的成员。它的过程是:假设第一个元素已排序,从第二个元素(即第 i
其性能特点鲜明:数据越接近有序,排序速度越快。在最好情况(数据已有序)下,时间复杂度为O(N);但在最坏情况(数据完全逆序)下,每个元素都需要移动到最前面,时间复杂度退化为O(N²)。因此,它非常适合小规模数据或已基本有序的数据预处理。许多高级语言(如Python、Java)在内部对小数组排序时,会采用类似插入排序的优化策略。
以下是直接插入排序的C++实现代码,请注意其原地排序和稳定性的特点:
void InsertSort(int* arr, int n)
{ // 遍历待插入元素(从第2个元素开始,第1个元素天然有序)
for (int i = 0; i < n - 1; i++)
{
int end = i; // end指向已排序序列的末尾
int tmp = arr[end + 1];// 保存待插入的元素(避免后移时被覆盖)
// 向前查找合适的插入位置,逆序则后移元素
while (end >= 0)
{
if (arr[end] > tmp)
{
arr[end + 1] = arr[end];// 元素后移
end--;
}
else
{
break; // 找到插入位置,退出循环
}
}
arr[end + 1] = tmp; // 将待插入元素放入合适位置 }
}
}为了更直观地理解其“插入”过程,可以参考下面的示意图:
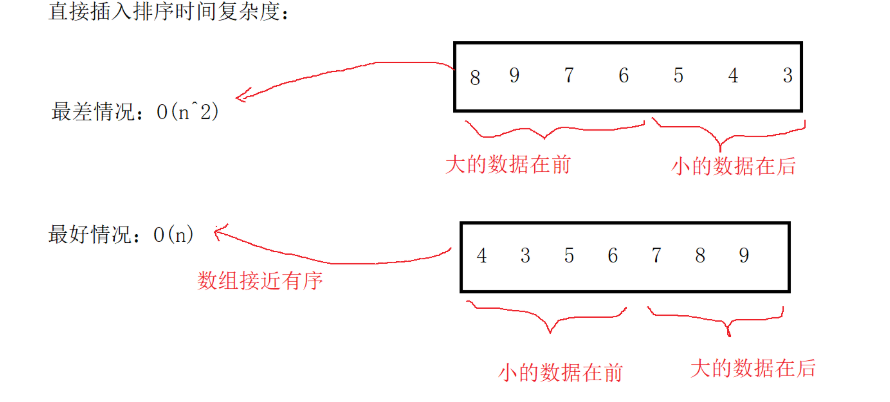
2.2 希尔排序:插入排序的高效升级版
针对直接插入排序在处理逆序数据时效率低下的问题,Donald Shell提出了希尔排序,也称为缩小增量排序。它的核心思想是“化整为零,逐步逼近”:先让数据宏观上基本有序,再进行精细调整。
算法通过一个逐渐缩小的“增量” gapgapgap=1
增量的选择直接影响算法效率,常见序列有希尔原序列(N/2, N/4, ... 1)或更高效的Knuth序列(1, 4, 13, 40...)。其核心步骤可概括为:
初始 (或 ),分组后组内插入排序(预排序,目的是让数组整体趋于有序)。
重复缩小 (如 ),直到 执行最后一次直接插入排序,完成最终排序。
下图展示了希尔排序的分组与排序过程:
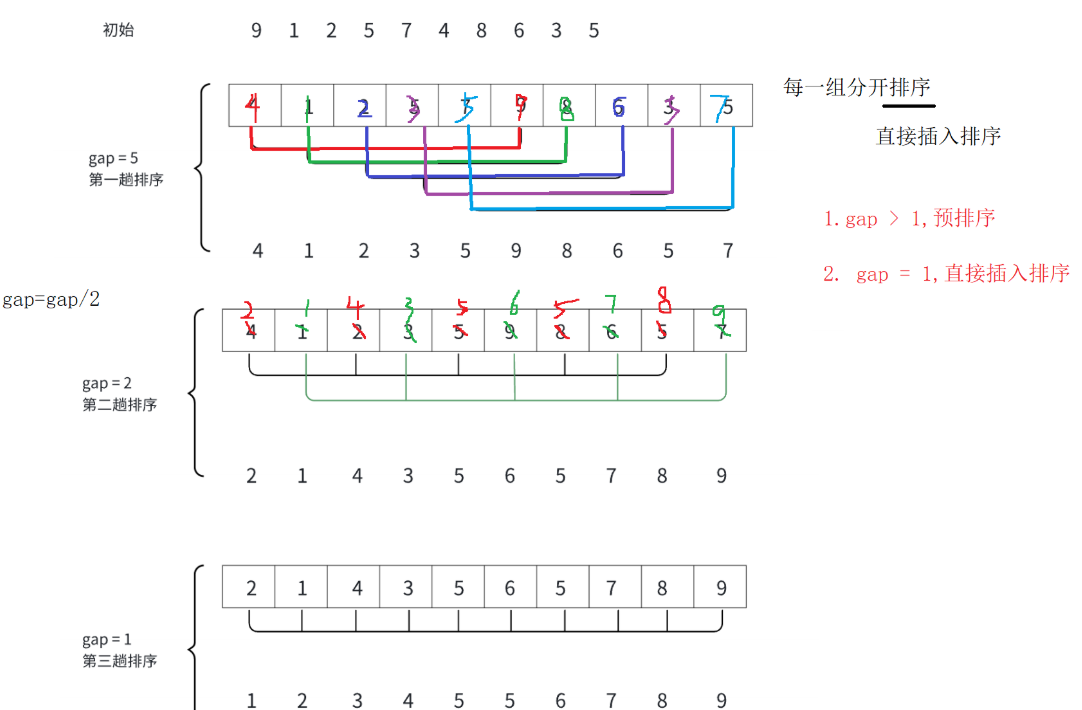
希尔排序的代码实现如下,它是对插入排序思想的一次精彩升华:
void ShellSort(int* arr, int n)
{
int gap = n; // 逐步缩小gap,直到gap=1
while (gap > 1)
{
gap = gap / 3 + 1; // 推荐增量公式,确保最终gap=1
// 分组插入排序,每组间隔为gap
for (int i = 0; i < n - gap; i++)
{
int end = i; // end指向当前组已排序序列的末尾
int tmp = arr[end + gap];// 保存当前组待插入元素
// 组内向前查找插入位置
while (end >= 0)
{
if (arr[end] > tmp)
{
arr[end + gap] = arr[end];// 组内元素后移(间隔gap)
end -= gap;
}
else
{
break;
}
}
arr[end + gap] = tmp; // 插入当前组合适位置
}
}技术要点:希尔排序的时间复杂度分析较为复杂,取决于增量序列,大致在O(n^1.3)到O(n²)之间。它是不稳定的排序算法,因为分组插入可能会打乱相同元素的原始相对顺序。
三、选择排序:在遍历中寻找极值
选择排序的核心思想是“选择”:每一轮都从待排序的数据中选出最小(或最大)的元素,放到已排序序列的末尾。
3.1 直接选择排序
直接选择排序的实现非常直观。一种常见的优化是每轮同时找出最小和最大元素,分别与待排序区间的首尾([begin, end]
⚠️ 这里有一个关键的边界情况需要注意:如果最大值恰好位于区间起始位置(即 begin == maxi
直接选择排序的C++实现代码如下:
// 交换函数(补充,用于元素交换)
void swap(int* a, int* b) {
int tmp = *a;
*a = *b;
*b = tmp;
}
void SelectSort(int* arr, int n) {
int begin = 0, end = n - 1;
// 排序区间逐步缩小,直到begin >= end(排序完成)
while (begin < end) {
int mini = begin, maxi = begin; // 初始化最小、最大元素索引
// 遍历待排序区间,找到最小、最大元素索引
for (int i = begin + 1; i <= end; i++) {
if (arr[i] < arr[mini]) mini = i; // 更新最小元素索引
if (arr[i] > arr[maxi]) maxi = i; // 更新最大元素索引
}
// 处理最大值在起始位置的特殊情况,避免最大值丢失
if (begin == maxi) maxi = mini;
swap(&arr[mini], &arr[begin]); // 最小值交换到区间起始位置
swap(&arr[maxi], &arr[end]); // 最大值交换到区间末尾位置
begin++; // 缩小排序区间(左边界右移)
end--; // 缩小排序区间(右边界左移)
}
}尽管思路简单,但直接选择排序无论数据初始状态如何,都需要进行大量的比较(O(N²)),交换次数相对较少。因此,它在实际开发中应用很少,主要用于教学,帮助理解“选择”的思想。
3.2 堆排序:选择排序的王者
堆排序是选择排序家族中的效率担当,它巧妙地利用了“堆”这种完全二叉树数据结构来高效地选择极值。堆可以用数组完美表示,其中父节点索引 i2i+12i+2
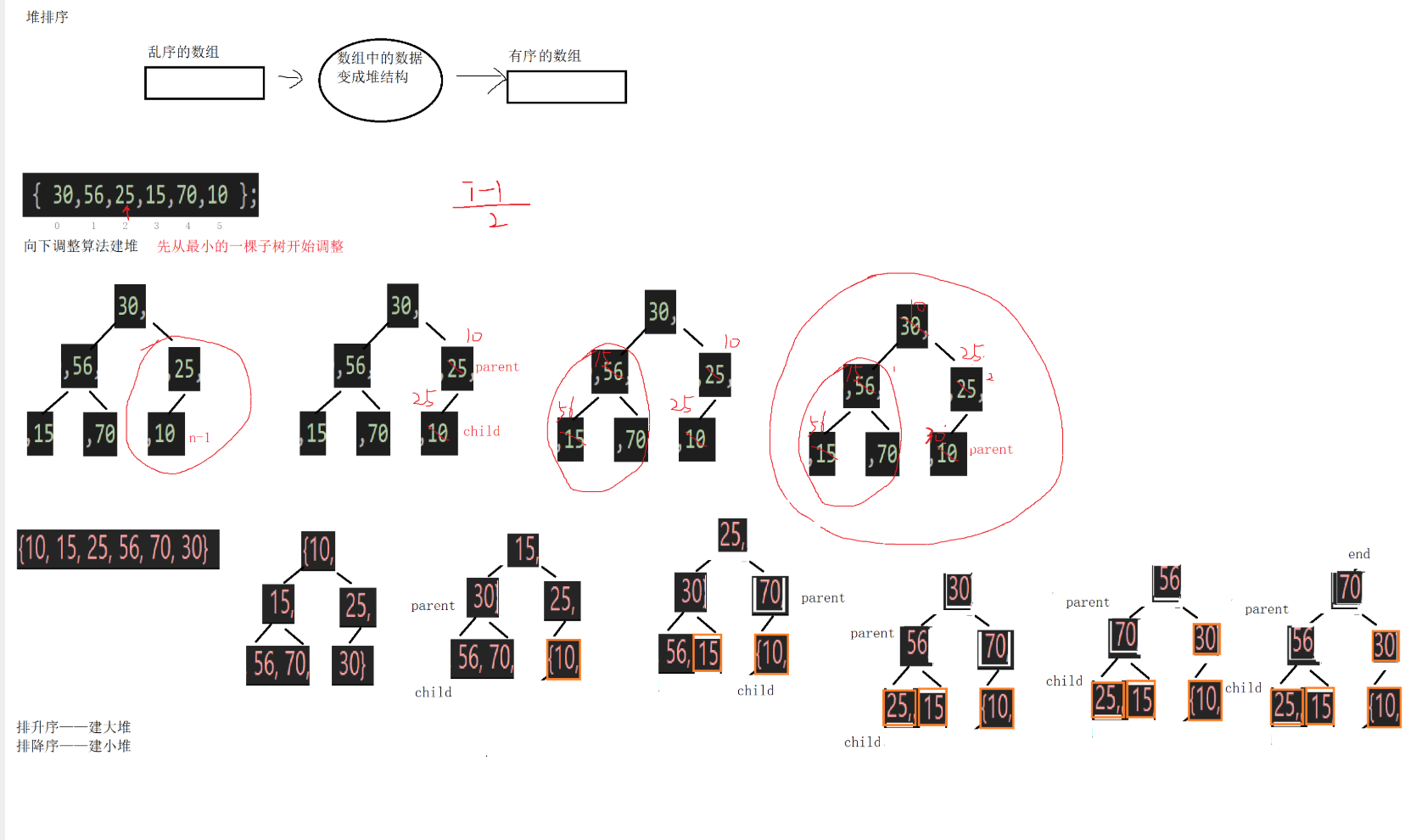
堆排序的步骤清晰分为两步:建堆和排序。若要升序排序,需建立大顶堆(保证堆顶是最大值);若要降序,则建立小顶堆。建堆完成后,每次将堆顶元素(当前最大值)与堆末尾元素交换,然后对新的堆顶元素执行“向下调整”操作,以恢复堆的性质,同时将排序区间缩小。这个过程可以概括为:
建堆:从最后一个非叶子节点(索引)开始,依次向下调整,将数组构建为大堆(升序)/小堆(降序)。
堆排序:将堆顶元素(最大值/最小值)与堆尾元素交换,缩小堆的范围(end--),对新堆顶执行向下调整,重复至堆的范围为1,数组排序完成。
堆排序的调整过程如下图所示:
以下是堆排序的核心代码实现,其中包含了关键的向下调整函数:
// 交换函数(复用)
void swap(int* a, int* b) {
int tmp = *a;
*a = *b;
*b = tmp;
}
// 向下调整函数(建大堆,用于堆排序)
void AdjustDown(int* arr, int n, int parent) {
int child = parent * 2 + 1; // 初始化左孩子索引
// 循环调整,直到孩子节点超出堆的范围
while (child < n) {
// 找到左右孩子中较大的那个
if (child + 1 < n && arr[child + 1] > arr[child]) {
child++; // 右孩子更大,指向右孩子
}
// 若父节点小于孩子节点,交换并继续向下调整
if (arr[parent] < arr[child]) {
swap(&arr[parent], &arr[child]);
parent = child; // 父节点指向当前孩子节点
child = parent * 2 + 1; // 重新计算左孩子索引
} else {
break; // 满足大堆性质,退出调整
}
}
}
// 堆排序(升序排列)
void HeapSort(int* arr, int n) {
// 1. 建堆:从最后一个非叶子节点开始,依次向下调整
for (int i = (n - 2) / 2; i >= 0; i--) {
AdjustDown(arr, n, i);
}
// 2. 堆排序:逐步提取堆顶元素,调整堆
int end = n - 1;
while (end > 0) {
swap(&arr[0], &arr[end]); // 堆顶(最大值)与堆尾交换
AdjustDown(arr, end, 0); // 对新堆顶调整,堆范围缩小为[0, end-1]
end--;
}
}优势:堆排序的时间复杂度稳定在O(NlogN),且是原地排序,空间复杂度为O(1)。这使得它特别适合处理大规模数据且内存受限的场景,例如在嵌入式系统或某些对内存使用有严格要求的C++/Go项目中。
[AFFILIATE_SLOT_2]四、交换排序:冒泡排序的起落
交换排序通过不断比较和交换相邻元素来达到排序目的,其中最具代表性的就是冒泡排序。
4.1 冒泡排序及其优化
冒泡排序的过程就像它的名字一样:每一轮遍历,相邻元素两两比较,如果逆序就交换,这样每轮结束后,最大(或最小)的元素就会像气泡一样“浮”到序列的顶端(末尾)。
一个重要的优化是引入交换标志exchange
冒泡排序的优化版实现如下:
// 交换函数(复用)
void swap(int* a, int* b) {
int tmp = *a;
*a = *b;
*b = tmp;
}
void BubbleSort(int* a, int n) {
int exchange = 0; // 标记本轮是否发生交换
int lastExchange = 0; // 记录本轮最后一次交换的位置
int end = n - 1; // 排序区间的右边界(初始为数组末尾)
for (int i = 0; i < n; i++) {
exchange = 0;
lastExchange = 0;
// 遍历待排序区间,相邻元素两两比较
for (int j = 0; j < end; j++) {
if (a[j] > a[j + 1]) {
swap(&a[j], &a[j + 1]);
exchange = 1; // 标记发生交换
lastExchange = j; // 更新最后一次交换的位置
}
}
if (exchange == 0) break; // 数组已有序,提前退出
end = lastExchange; // 下一轮排序仅需遍历到lastExchange(后续有序)
}
}✅ 特点:冒泡排序是稳定的排序算法,并且是原地排序。它的代码极其简单,是算法入门教学的经典案例。然而,其平均和最坏情况时间复杂度为O(N²),导致它在实际生产环境(如Java企业级应用、TypeScript前端大数据处理)中几乎不会被使用,性能是其主要瓶颈。
五、总结与对比:如何选择你的排序工具?
本文详细解析了五大基础排序算法。为了在实际编程中做出明智选择,我们可以从以下几个维度进行快速对比:
- 时间复杂度:堆排序(O(NlogN))表现最佳且稳定;希尔排序平均接近O(N^1.3);直接插入、选择和冒泡排序在平均和最坏情况下为O(N²)。
- 空间复杂度:本文所有算法均为原地排序,O(1),非常节省内存。
- 稳定性:直接插入排序和冒泡排序是稳定的;希尔排序、选择排序和堆排序是不稳定的。
- 适用场景:
- 小规模/基本有序数据:直接插入排序。
- 中等规模通用排序:希尔排序是不错的选择。
- 大规模数据,且要求原地排序:堆排序是首选。
- 教学与理解:冒泡排序和直接选择排序。
理解这些基础算法,不仅是掌握其代码实现,更是领悟其设计思想。例如,插入排序的“逐步构建有序序列”、希尔排序的“宏观先行微观调整”、堆排序的“利用数据结构优化选择过程”。这些思想会迁移到你未来学习快速排序、归并排序乃至更复杂算法中去。在下一篇中,我们将继续探讨更高效的排序算法,如快速排序和归并排序,并深入非比较排序的世界。
gap = n/3 + 1n/2gapgap = gap/3gap=1(n-2)/2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号