
MotionTrans:用VR数据教会机器人新技能,零样本迁移不再是梦
在机器人学习领域,数据是燃料,但高质量的机器人演示数据却昂贵且稀缺。想象一下,如果能像训练大语言模型一样,用海量、易得的人类数据来“预训练”机器人,那将极大加速其技能学习。清华大学和北京大学的研究团队提出的MotionTrans框架,正是朝着这个梦想迈出的关键一步。它首次系统性地验证了从人类VR数据到机器人实体的运动级知识迁移,让机器人能在零样本或少样本下学会从未见过的操作动作。
一、核心挑战:从“看”到“动”的鸿沟
以往的研究已经证明,人类数据能有效提升机器人的视觉理解和任务鲁棒性。然而,一个更根本的问题悬而未决:机器人能否直接从人类数据中学会执行新任务所需的“动作模式”? 这就是“运动级迁移”。人类动作与机器人动作在速度、形态和物理约束上存在巨大差异,直接套用往往失败。
MotionTrans的研究动机正是为了解决这一瓶颈。与依赖昂贵机器人数据或复杂仿真不同,它利用VR设备(如Meta Quest 3)便捷采集丰富多样的人类操作数据,并将其转化为机器人能理解和学习的格式。这就像为机器人找到了一个取之不尽、充满“动作灵感”的宝库。
二、框架揭秘:三步实现人机动作对齐
MotionTrans的成功,依赖于一个精心设计的框架,核心在于数据转换与联合训练。
1. 数据采集与“翻译”
研究团队构建了双轨数据采集系统:
- 人类数据轨:通过VR头显和相机,记录手部关键点、手腕姿态和第一视角RGB图像。
- 机器人数据轨:使用Franka机械臂和灵巧手,通过遥操作复现人类动作,形成“真值”数据。
关键创新在于将人类数据“翻译”成伪机器人数据。这涉及:
- 坐标系统一:将所有姿态统一到自身相机坐标系。
- 手部映射:使用逆运动学求解器,将人类手部关键点映射到机器人手部关节。
- 速度与表示优化:对人类动作进行降速插值,并采用基于动作块的相对姿态而非绝对姿态,极大减少了人机动作的分布差异。

上图展示了MotionTrans框架的整体流程,从数据采集到策略部署。


这些图片分别展示了人类VR数据采集和机器人遥操作采集的具体场景。
2. 构建大规模、多样化的MotionTrans数据集
高质量的研究离不开高质量的数据集。MotionTrans数据集包含超过3200条演示,涵盖15个仅有人类数据的任务(如拔充电器、合笔记本)和15个仅有机器人数据的任务(如推方块、倒可乐)。

该数据集的特点是任务不重叠但运动模式可类比,为验证运动迁移提供了完美土壤。与以往数据集相比,它在任务和运动覆盖度上都有显著提升。
| 数据集 | 人类演示 | 人类任务 | 野外场景 | 机器人演示 | 机器人任务 | 野外场景 |
|---|---|---|---|---|---|---|
| EgoMimic | 2,150 | 3 | 0% | 1,000 | 3 | 0% |
| PH²D | 26,842 | 4 | 100% | 1,552 | 4 | 0% |
| MotionTrans | 1,705 | 15 | 100% | 1,508 | 15 | 50% |
3. 加权多任务联合训练策略
研究团队探索了两种主流端到端策略进行训练:Diffusion Policy和π₀-VLA模型。训练的核心是加权联合损失函数,平衡人类数据与机器人数据的贡献,确保两者在训练中权重相等。
一个关键的设计选择是:对人类和机器人数据采用统一的Z-score归一化。这与之前为提升视觉鲁棒性而采用的“实体依赖归一化”相反。实验证明,在运动迁移场景下,统一归一化避免了训练与推理时的分布不匹配,效果更佳。
三、惊艳结果:零样本与少样本下的表现
实验结果是MotionTrans价值最直接的证明。
零样本迁移:无需机器人数据的新技能
在完全不为目标人类任务收集任何机器人数据的情况下,MotionTrans训练的模型成功让机器人完成了9个新任务,平均成功率约20%。例如,将橙子放入桶中成功率高达70%。
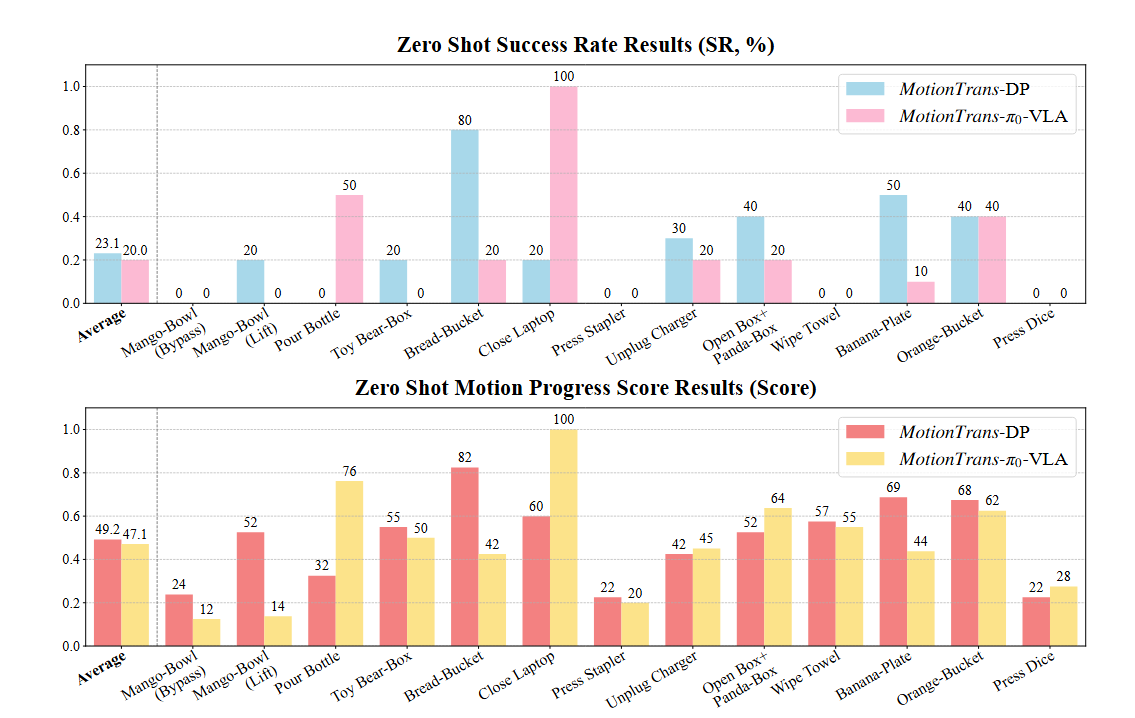
| 模型 | 平均成功率 | 平均运动进度得分 |
|---|---|---|
| MotionTrans-DP | 23.1% | 0.492 |
| MotionTrans-π₀-VLA | 20.0% | 0.471 |
更重要的是,即使任务未完全成功,机器人也展现出了有意义的意图性动作,如接近目标物体、执行推、抬等初步操作。

上图展示了部分任务在真实机器人上的零样本执行效果。
[AFFILIATE_SLOT_1]少样本微调:数据效率大幅提升
当允许为每个新任务收集少量(如5或20条)机器人演示进行微调时,MotionTrans预训练模型展现出巨大优势。在5-shot设置下,其性能比从头训练(from-scratch)的模型高出约40%。
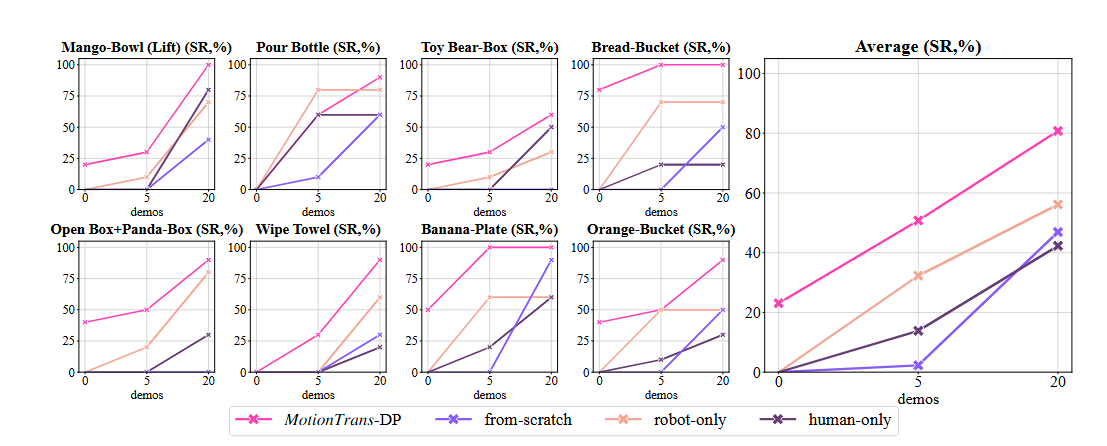
这证明了人类数据作为丰富的运动先验,能极大降低机器人学习新技能的数据需求。对于开发者而言,这意味着可以像使用Python的预训练模型(如TensorFlow或PyTorch的模型库)快速适配新任务一样,来快速赋予机器人新技能。
四、深度洞察:消融实验揭示的设计哲学
为什么MotionTrans能成功?一系列消融实验揭示了关键因素:
| 变体 | 运动进度得分 | 成功率 |
|---|---|---|
| w/ Abs Pose (使用绝对位姿) | 0.370 | 10.0% |
| w/ ED-Norm (具身依赖的归一化) | 0.341 | 8.4% |
| w/ Visual Rendering (视觉渲染) | 0.475 | 23.1% |
| MotionTrans-DP | 0.492 | 23.1% |
- 相对姿态 > 绝对姿态:使用绝对手腕位姿会严重破坏迁移,因为它放大了人机工作空间的本征差异。
- 统一归一化 > 实体依赖归一化:为运动迁移而设计,需保证训练与推理条件一致。
- ⚠️ 视觉渲染收益有限:试图将机器人渲染到人类视频中以增强真实感,并未带来显著提升,神经网络仍能分辨差异。
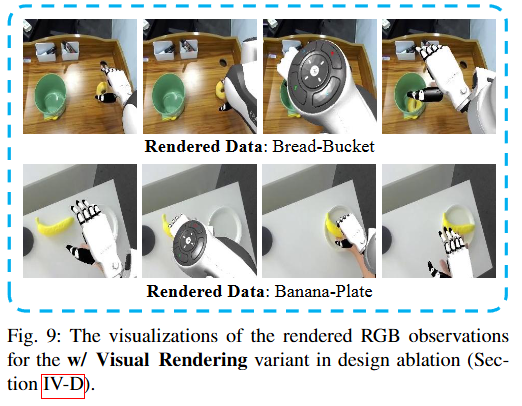
这里再详细补充下什么是视觉渲染:
视觉渲染的具体步骤
- 步骤1:重放机器人轨迹
- 在仿真环境中,按照记录的机器人动作轨迹重新执行一遍
- 这样就能从相同视角渲染出机器人的3D模型
- 步骤2:裁剪机器人
- 从仿真渲染的图像中,把机器人手臂部分单独抠出来
- 类似于抠图,只保留机器人手臂,背景透明- 步骤3:粘贴到原图
- 把抠出来的机器人手臂,粘贴回原始真实拍摄的RGB图像上
- 替换掉原本画面中机器人手臂的位置
当目标是运动级别的迁移和评估时,某些设计的有效性可能与用人类数据提高视觉鲁棒性或训练效率时的有效性不同。
这些发现强调,针对不同的学习目标(视觉鲁棒性 vs. 运动迁移),需要不同的技术策略。这好比在Web开发中,优化首屏加载与优化API响应速度的策略截然不同。
五、机制探索:运动知识如何被“迁移”?
MotionTrans进一步分析了迁移的内在机制。
1. 动作插值假设:研究者认为,策略从人类数据中学到了任务相关的运动模式(如“放置”的高度范围)。当在机器人上执行时,模型会基于任务指令,在机器人数据定义的可行动作分布内进行“插值”,生成适合当前实体的动作。
| 训练集 | 放置高度 | 成功率 |
|---|---|---|
| H-bucket(仅人类) | 15.3cm | 0% |
| H-bucket + R-pad | 0.3cm | 0% |
| H-bucket + R-platform | 20.7cm | 30% |
| H-bucket + R-pad + R-platform | 0.3-20.7cm | 40% |
| + PP-set(更多抓放任务) | - | 70% |
| 全部数据 | - | 80% |
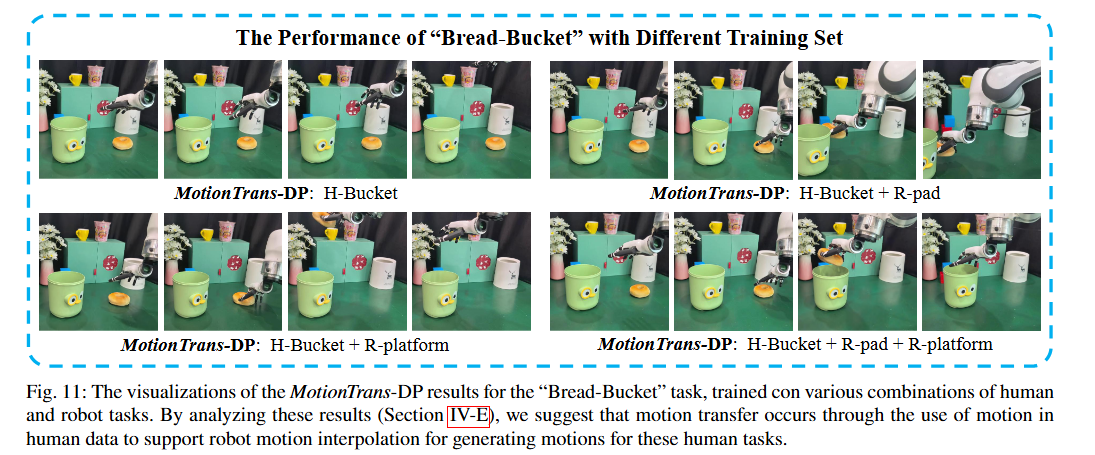
人类任务完成的动作是通过插值机器人数据中的动作生成的(如从R-Pad的0.3cm和R-Platform的20.7cm插值到H-Bucket的15.3cm)。这种插值能力是通过学习人类数据中的任务感知运动获得的。
2. 实体不变的视觉感知:通过注意力可视化发现,模型的视觉编码器学会关注任务关键物体(如要抓取的香蕉),而非执行任务的实体(人手或机械手)。这种任务感知的表示是实现跨实体迁移的基础。
3. 规模化趋势:增加数据集中任务和运动的多样性,能持续提升迁移性能,预示着通往更大规模数据预训练的可能。
运动迁移可能受益于更广泛的任务相关运动覆盖。虽然基于有限子集,但提供了规模化趋势的初步证据。
六、意义、局限与未来
核心贡献:MotionTrans首次系统验证了运动级迁移的可行性,提供了完整的数据集、框架和设计指南,为利用海量人类数据训练具身智能体打开了新大门。
当前局限:包括单目视觉的深度感知限制、数据规模仍属实验室级别等。
未来方向令人兴奋:
- 迈向互联网规模的人类演示数据学习。
- 集成更强的多模态基础模型(如视觉-语言模型)。
- 探索更复杂的双臂和精细操作任务。
与现有工作相比,MotionTrans的独特之处在于它专注于任务不重叠下的运动迁移,而此前工作多关注重叠任务的辅助性能提升。
| 研究 | 数据规模 | 任务数 | 评估方式 | 主要贡献 |
|---|---|---|---|---|
| EgoMimic | 2,150人类+1,000机器人 | 3(重叠) | 视觉鲁棒性 | 提升视觉泛化 |
| PH²D | 26,842人类+1,552机器人 | 4(重叠) | 训练效率 | 大规模数据收集 |
| MotionTrans | 1,705人类+1,508机器人 | 30(不重叠) | 运动级迁移 | 显式运动学习 |
七、总结与启示
MotionTrans是一项里程碑式的工作。它证明,通过精巧的数据转换和训练框架,我们可以将人类在VR世界中展现的丰富运动技能,“蒸馏”并迁移到物理机器人身上。这不仅大幅降低了对机器人演示数据的依赖,也为构建具有通用操作能力的机器人智能体指明了一条可扩展的路径:从互联网规模的人类视频中学习运动常识。
对于机器人学、AI和开发者社区而言,MotionTrans的开源释放了一个强有力的信号:属于机器人“运动基础模型”的时代,或许正在开启。正如JavaScript的Node.js革新了后端开发,MotionTrans所代表的思路,可能正在革新机器人技能学习的方式。
(文中所有代码、数据和模型均已开源,感兴趣的读者可通过论文与项目主页获取。)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号