
从逻辑回归到神经网络:揭秘AI分类任务的核心进化之路
在人工智能的宏大叙事中,如何让机器学会“判断”与“分类”是迈向智能的关键一步。从预测房价的线性回归,到诊断疾病的分类模型,再到如今驱动深度学习的神经网络,这条技术演进路径清晰地揭示了现代AI“智能”的底层逻辑。本文将带你深入探索,从逻辑回归的诞生到神经网络的崛起,理解分类任务如何从简单的线性拟合,演变为能够识别猫狗、理解语言的复杂系统。
一、线性回归的局限:当连续预测遭遇离散分类
线性回归是机器学习入门的经典模型,其核心思想简洁明了:寻找特征与连续目标值之间的线性关系。例如,根据房屋面积预测其价格。它的数学形式为 \(y = w_1 x_1 + w_2 x_2 + \dots + b\),目标是让预测值 \(\hat{y}\) 尽可能接近真实值 \(y\)。
然而,现实世界充满了“是非题”。设想一个场景:根据学生的学习时长预测其考试是否通过(通过=1,不通过=0)。如果强行套用线性回归 \(\hat{y} = wx + b\),模型可能会输出 1.2、-0.3 这类毫无意义的数值。这暴露了线性回归应用于分类任务时的根本矛盾:其输出空间是连续的 \((-\infty, +\infty)\),而分类任务需要的是离散的类别或概率。
用一个线性函数去拟合“输入 → 连续输出”的关系
更严重的是,线性回归使用的均方误差损失函数对异常值极其敏感。一个错误的样本就可能导致整个模型决策边界发生剧烈偏移,鲁棒性很差。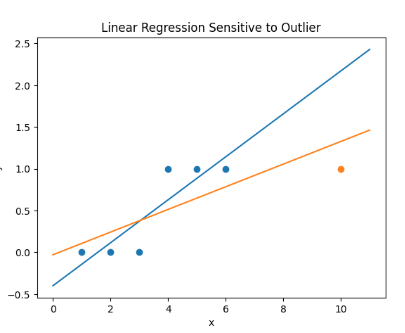 如图所示,一个异常点就能显著改变回归线的走向。这促使我们思考:对于分类,我们真正需要模型输出什么?答案是一个介于0和1之间的、可以解释为“概率”的值,即 \(P(y=1|x)\)。
如图所示,一个异常点就能显著改变回归线的走向。这促使我们思考:对于分类,我们真正需要模型输出什么?答案是一个介于0和1之间的、可以解释为“概率”的值,即 \(P(y=1|x)\)。
二、逻辑回归:为分类而生的“概率压缩器”
为了解决上述矛盾,逻辑回归应运而生。它的核心创新在于:在线性回归的输出之上,套用一个特殊的“压缩函数”。线性部分 \(z = wx + b\) 负责计算特征的加权和,而压缩函数负责将 \(z\) 从任意实数映射到 (0, 1) 区间。
这个理想的压缩函数就是Sigmoid函数:\(\sigma(z) = \frac{1}{1 + e^{-z}}\)。它完美满足了我们的需求:单调递增、光滑可导,并且当 \(z\) 趋于正负无穷时,输出无限逼近于1和0。其图像是一条优美的S型曲线。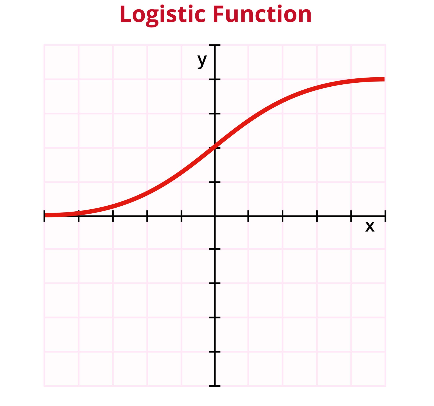
因此,逻辑回归的完整形式是:\(P(y=1|x) = \sigma(wx + b)\)。它不再直接预测0或1,而是预测样本属于正类的概率,再通过设定阈值(通常为0.5)得到最终类别。
逻辑回归 = 线性模型 + Sigmoid
相应地,损失函数也从均方误差换成了交叉熵损失:\(L = -[y\log(p) + (1-y)\log(1-p)]\)。这个损失函数非常直观:当真实标签 \(y=1\) 时,模型会极力推动 \(p\) 接近1;当 \(y=0\) 时,则推动 \(p\) 接近0。预测概率与真实标签差距越大,惩罚呈对数级增长。
[AFFILIATE_SLOT_1]最大化“真实类别的概率”,让损失尽可能小
三、从神经元到网络:组合的力量与非线性之魂
逻辑回归可以被视为一个人工神经元,它是构成现代神经网络的最基本单元。这个单元包含:输入(x)、可调权重(w)、偏置(b)、激活函数(Sigmoid)以及损失函数(交叉熵)。
一个神经元!
然而,单个神经元的能力有限,它只能学习一条直线(或超平面)作为决策边界,只能解决线性可分问题(如逻辑与、或)。对于经典的“异或”(XOR)问题,单神经元就无能为力了。解决之道在于组合:将多个神经元连接起来,形成网络。
x → [神经元1] → h1
x → [神经元2] → h2h1,h2 → 输出层这就是一个简单的前馈神经网络。多层结构的精髓在于特征层次的抽象。第一层神经元从原始数据中提取基础特征(如图像中的边缘),第二层将这些基础特征组合成更复杂的特征(如形状),后续层则构建出更高阶的抽象概念(如物体部件、整体对象)。
多层 = 自动构造特征
这里必须引入一个关键概念:激活函数。如果层与层之间只做线性变换,那么无论堆叠多少层,整个网络等价于一个复杂的线性回归,无法获得更强的表达能力。激活函数(如ReLU, Sigmoid)引入了非线性,使得神经网络能够拟合任意复杂的函数。可以说,激活函数是神经网络拥有强大表达能力的灵魂。
✅ 非线性激活函数
四、从二分类到多分类:Softmax的优雅扩展
逻辑回归和它的Sigmoid函数擅长处理二分类问题。但当任务扩展到多个互斥的类别时(如识别0-9的手写数字,或区分猫、狗、鸟),我们需要新的机制。多分类的本质要求模型输出一组互斥且概率和为1的预测。
Softmax函数优雅地解决了这个问题。假设网络最后一层为三个类别输出了原始分数(logits)\(z = [z_1, z_2, z_3]\),Softmax将其转化为概率分布:\(p_i = \frac{e^{z_i}}{\sum_{j=1}^{3} e^{z_j}}\)。它确保每个 \(p_i\) 都在(0,1)之间,且所有 \(p_i\) 之和为1。概率最大的类别即为模型的预测结果。
Softmax = 多分类版 Sigmoid
一个完整的用于多分类的神经网络结构通常如下所示:
输入 x
↓
[线性层]
↓
ReLU
↓
[线性层]
↓
Softmax
↓
概率分布五、训练的灵魂:反向传播算法
拥有了强大的网络结构,如何训练它?答案是反向传播。这是神经网络学习的核心算法,其思想类似于“责任分摊”。训练过程是一个循环:前向传播计算预测值 -> 计算损失 -> 反向传播更新权重。
前向传播即数据从输入层流向输出层的过程:
x → 线性 → ReLU → 线性 → Softmax → p是在“非线性特征空间”里做线性
计算损失后,关键问题来了:如何将输出层的误差,公平且有效地归因到网络中成千上万个参数上,并指导它们更新?
输出层的一个错误
应该怪谁?(找到主谋)
反向传播利用链式法则,将总损失 \(L\) 对每个权重 \(w\) 的梯度 \(\frac{\partial L}{\partial w}\) 从后向前逐层计算出来。梯度指明了权重调整的方向和幅度。更新规则非常简单:\(w_{new} = w_{old} - \eta \cdot \frac{\partial L}{\partial w}\),其中 \(\eta\) 是学习率。这个过程不断迭代,直到网络预测的损失降到足够低。
[AFFILIATE_SLOT_2]从后往前
一层层“分摊责任”
六、总结:通向智能的基石
从逻辑回归到神经网络的旅程,是人工智能解决分类问题的核心思想进化史。我们首先认识到线性回归在离散世界中的无力,从而引入了能将连续值压缩为概率的Sigmoid函数,诞生了逻辑回归。接着,我们将单个神经元视为基础模块,通过叠加层数和引入非线性激活函数,构建出具有强大特征学习能力的神经网络。为了处理更复杂的多分类世界,Softmax函数提供了优雅的概率归一化方案。最后,反向传播算法作为高效的训练引擎,让这个复杂的系统能够从数据中自动学习。
这条路径不仅是机器学习和深度学习课程的基础,更是理解当今自然语言处理、计算机视觉等AI应用背后“智能”从何而来的钥匙。理解这些基石,才能更好地驾驭和创造未来的AI技术。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号