
深入Linux进程控制:从fork到waitpid,构建稳健并发程序的基石
在Linux系统编程的广阔天地中,进程是并发与并行执行的灵魂。理解并掌控进程的完整生命周期——创建、执行、终止与回收,是每一位追求高效与稳健的程序员必须跨越的门槛。本文将为你系统性地解析进程控制的三大核心支柱:进程创建(fork)、进程终止与进程等待。通过深入原理、剖析代码与实践建议,你将掌握在多进程编程中避免僵尸进程、优雅管理资源并构建可靠并发系统的关键技能。
一、进程的“分身术”:深入理解fork系统调用
在Linux中,创建新进程的核心函数是fork()。它并非凭空创造,而是通过复制调用它的进程(父进程)来生成一个几乎完全相同的子进程。这个“复制”过程,是理解多进程编程的第一步。
fork的“双重返回”之谜
最令人初学者困惑的是fork()的返回值:它在父进程中返回子进程的PID(进程ID),在子进程中则返回0。这并非函数返回了两次,而是在调用fork()后,操作系统复制了父进程的上下文(包括程序计数器),创建了子进程。从此,父子进程在各自的地址空间中独立执行,fork()的返回值成为了它们区分彼此身份的钥匙。

下面是一个最基本的fork()使用示例:
#include <unistd.h>
pid_t fork(void);子进程返回 0, 父进程返回子进程的 PID,出错返回 -1。
写时拷贝(Copy-On-Write):效率的艺术
早期的Unix系统在fork()时会立即复制父进程的全部内存空间,这无疑是低效的。现代Linux内核采用了写时拷贝(COW)这一精妙的优化技术。
这种延迟复制的策略极大地提升了关键技术特点:
父子进程代码共享,初始数据也共享。
当任一进程试图写入数据时,触发写时拷贝。
操作系统为写入方创建数据副本,实现进程隔离。
优势:
提高内存使用效率(延迟分配)。
保证进程独立性。
减少不必要的内存复制。
fork()的效率,尤其是在配合exec()系列函数执行新程序时。fork的典型应用场景与失败原因
然而,任务并行处理:父进程创建子进程处理不同任务。
服务器编程:父进程监听连接,子进程处理请求。
程序替换:子进程调用 exec 执行新程序。
fork()也可能失败,常见原因包括:在编写高并发服务器程序时,必须妥善处理这些错误。系统进程数达到上限。
用户进程数超过限制。
内存资源不足。
二、进程的“谢幕”:理解进程终止与退出状态
进程的终止如同其创建一样,需要被妥善管理。一个进程的退出主要有三种场景:
代码正常执行完毕,结果正确;代码正常执行完毕,结果错误;代码异常终止(如信号中断)
退出状态码:进程的“遗言”
进程退出时,会向父进程传递一个退出状态码。按照惯例,状态码0表示成功,任何非0值都表示某种形式的失败。在Shell中,你可以使用echo $?
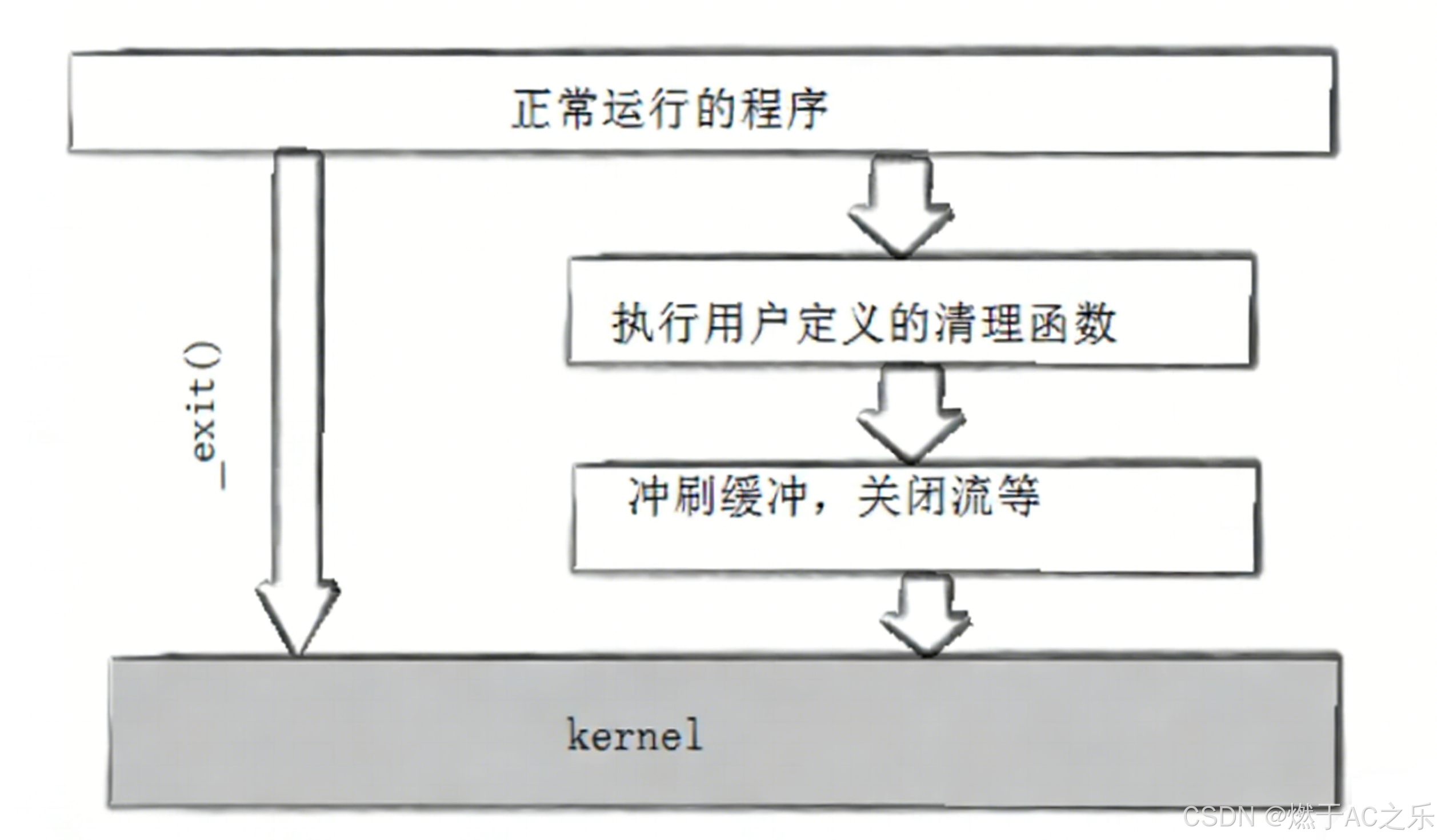
_exit() vs. exit():两种退出的选择
C库提供了两种终止进程的函数,它们的行为有细微但重要的差别:
_exit():
这是一个系统调用,直接进入内核终止进程,不做任何用户态的清理工作。#include <unistd.h> void _exit(int status);exit():
这是一个C库函数,它会按顺序执行:刷新标准I/O缓冲区、调用通过#include <stdlib.h> void exit(int status);atexit()注册的清理函数,最后再调用_exit()。
简单来说,exit()更“文明”,而_exit()更“直接”。在子进程中,如果不想刷新父进程可能共享的缓冲区,通常使用_exit()。
 [AFFILIATE_SLOT_1]
[AFFILIATE_SLOT_1]
三、为何必须等待:僵尸进程与信息获取
创建子进程后,父进程的职责并未结束。如果父进程不“等待”子进程结束,将会引发严重问题。
僵尸进程(Zombie)的威胁
当一个子进程先于父进程终止,内核会保留其退出状态等信息,直到父进程读取。此时,子进程便成为一个“僵尸进程”。
僵尸进程会占用宝贵的进程表项,如果大量产生,可能导致系统无法创建新进程。父进程需要知道:
子进程是否正常结束;
子进程的退出状态;
子进程的执行结果。
信息获取的需求
除了资源回收,父进程通常需要知道子进程是如何结束的:是正常退出(返回值是什么?)还是被信号杀死(哪个信号?)。进程等待机制正是为了满足这两个核心需求:回收资源与获取信息。
四、进程等待的艺术:wait与waitpid详解
Linux提供了wait()和waitpid()系统调用来实现进程等待。它们是解决僵尸进程问题的利器。
基础的wait()函数wait()是最简单的等待函数,它会阻塞调用它的父进程,直到任意一个子进程结束。
#include <sys/wait.h>
pid_t wait(int *status);更强大的waitpid()函数waitpid()提供了更精细的控制,可以等待指定的子进程,并支持非阻塞模式。
pid_t waitpid(pid_t pid, int *status, int options);其参数含义如下:
其中,pid:指定等待的进程ID(-1 表示任意子进程)
status:输出型参数,存储退出状态
options:等待选项(0为阻塞,WNOHANG为非阻塞)
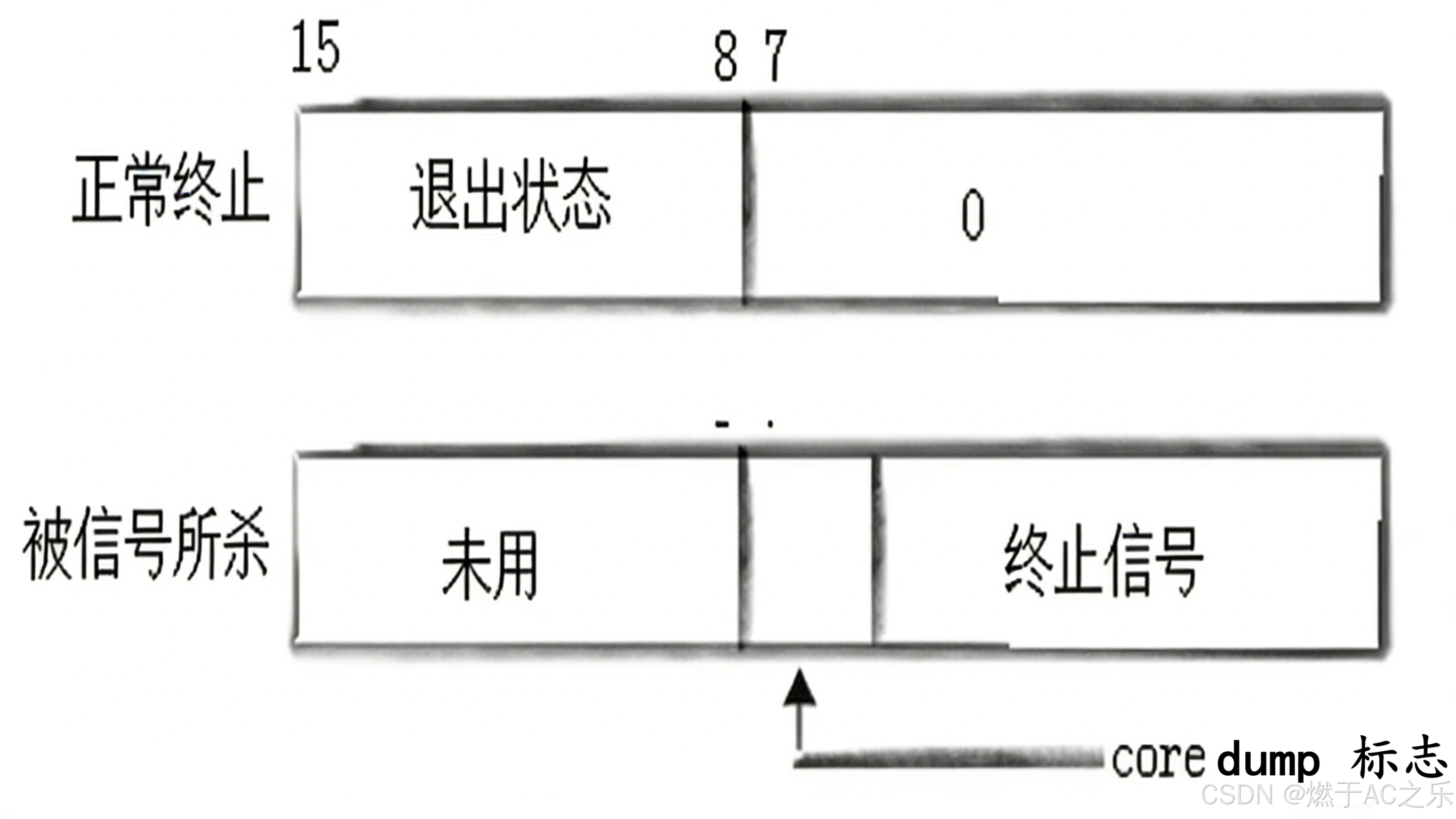
options参数若设置为WNOHANG,则使等待变为非阻塞,这在事件驱动或需要同时处理多个任务的程序中非常有用。解析status:位图里的秘密status参数是一个输出型参数,由内核填充。它不是一个简单的整数,而应被视为一个位图,包含了子进程退出方式的完整信息。
低7位:信号编号(异常终止时)
第8位:core dump 标志
高8位:退出状态码(正常终止时)
为了便于解析,系统提供了一系列宏:
WIFEXITED(status):判断是否正常退出
WEXITSTATUS(status):提取退出码
WIFSIGNALED(status):判断是否信号终止
WTERMSIG(status):提取信号编号
阻塞与非阻塞等待实践
阻塞等待是最简单的模式,父进程暂停直到子进程结束,适合顺序执行逻辑:
int main()
{
pid_t pid;
pid = fork();
if(pid < 0){
printf("%s fork error\n",__FUNCTION__);
return 1;
} else if( pid == 0 ){ //child
printf("child is run, pid is : %d\n",getpid());
sleep(5);
exit(257);
} else{
int status = 0;
pid_t ret = waitpid(-1, &status, 0);//阻塞式等待,等待5S
printf("this is test for wait\n");
if( WIFEXITED(status) && ret == pid ){
printf("wait child 5s success, child return code is
:%d.\n",WEXITSTATUS(status));
}else{
printf("wait child failed, return.\n");
return 1;
}
}
return 0;
}非阻塞等待(轮询)则允许父进程在等待子进程的同时继续工作,是实现响应式程序的关键:
#include <stdio.h>
#include <stdlib.h>
#include <sys/wait.h>
#include <unistd.h>
#include <vector>
typedef void (*handler_t)(); // 函数指针类型
std::vector<handler_t> handlers; // 函数指针数组
void fun_one() {
printf("这是⼀个临时任务1\n");
}
void fun_two() {
printf("这是⼀个临时任务2\n");
}
void Load() {
handlers.push_back(fun_one);
handlers.push_back(fun_two);
}
void handler() {
if (handlers.empty())
Load();
for (auto iter : handlers)
iter();
}
int main() {
pid_t pid;
pid = fork();
if (pid < 0) {
printf("%s fork error\n", __FUNCTION__);
return 1;
} else if (pid == 0) { // child
printf("child is run, pid is : %d\n", getpid());
sleep(5);
exit(1);
} else {
int status = 0;
pid_t ret = 0;
do {
ret = waitpid(-1, &status, WNOHANG); // ⾮阻塞式等待
if (ret == 0) {
printf("child is running\n");
}
handler();
} while (ret == 0);
if (WIFEXITED(status) && ret == pid) {
printf("wait child 5s success, child return code is :%d.\n",
WEXITSTATUS(status));
} else {
printf("wait child failed, return.\n");
return 1;
}
}
return 0;
}五、最佳实践与跨语言视角
掌握了核心机制后,遵循最佳实践能让你写出更健壮的代码:
- 及时回收:务必为每一个创建的子进程安排等待,避免僵尸进程累积。
- 检查状态:不要忽略
status信息,根据子进程的退出原因(正常/信号)做出相应处理。 - 选择模式:根据应用场景选择阻塞或非阻塞等待。服务器程序常使用非阻塞等待配合事件循环。
- 错误处理:始终检查
fork(),waitpid()等系统调用的返回值。
跨语言视角
虽然本文以C语言为例,但进程控制的概念是普适的。在高级语言中,这些细节通常被封装:
- Python:
os.fork(),os.waitpid()提供了类似的底层接口,而subprocess模块则提供了更高级、更安全的进程管理抽象。 - Node.js (JavaScript):通过
child_process模块(如spawn,fork方法)创建子进程,并通过事件(如'exit')来异步处理进程结束。 - Java:使用
ProcessBuilder或Runtime.exec()启动外部进程,并通过Process.waitFor()进行同步等待。
理解底层的C接口,能让你在使用这些高级抽象时更加得心应手,并能更好地调试复杂问题。

进程控制是Linux/Unix系统编程的基石,也是理解现代并发模型(如Prefork服务器、进程池)的基础。从fork的写时拷贝,到waitpid的非阻塞轮询,每一个细节都体现了操作系统设计的精妙。希望本文能帮助你构建起关于进程生命周期的清晰图景,并写出更高效、更稳定的多进程程序。记住,对资源的妥善管理,是程序员专业性的重要体现。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号