
从理论到实践:构建一个基于机器学习的地铁客流预测系统
随着城市轨道交通网络的日益复杂,精准的客流预测已成为提升运营效率、优化乘客体验的关键。传统的人工统计方法已难以应对海量、实时的数据挑战。本文将深入探讨如何利用现代技术栈,从零开始构建一个集数据可视化与智能预测于一体的地铁客流分析系统,为智慧交通提供切实可行的技术方案。
一、 系统架构与技术选型:为何选择这套组合拳?
一个成功的预测系统始于稳固的技术基础。本系统采用前后端分离的经典架构,旨在兼顾开发效率、系统性能与用户体验。
- 后端核心(Python + Flask):Python凭借其丰富的数据科学生态(如Pandas, Scikit-learn),成为数据处理与机器学习建模的不二之选。相较于Django等“重量级”框架,轻量灵活的Flask框架更适合快速构建RESTful API,实现业务逻辑与数据接口的敏捷开发。
- 前端展示(Vue.js + ECharts):Vue.js的响应式与组件化特性,使得构建交互复杂的数据看板变得清晰高效。结合百度开源的ECharts图表库,可以轻松实现客流趋势折线图、站点热力图等动态、美观的数据可视化效果。
- 数据存储(MySQL):作为成熟稳定的关系型数据库,MySQL能够可靠地存储用户信息、历史客流记录、模型参数等结构化数据,保障数据的完整性与一致性。
这套技术栈(Python, JavaScript)与业界其他主流选择(如Java Spring Boot, C++高性能计算后端,或TypeScript增强前端)相比,在快速原型开发、数据分析和社区资源方面具有独特优势。[AFFILIATE_SLOT_1]
二、 核心预测引擎:随机森林算法如何赋能客流预测?
预测的准确性直接决定系统的价值。我们选用随机森林(Random Forest)这一集成学习算法作为核心预测模型。它通过构建多棵决策树并综合其结果,能有效避免过拟合,对包含多种因素(如时间、天气、节假日)的客流数据表现出良好的鲁棒性。
其关键实施步骤包括:
- 数据准备与预处理:清洗原始客流数据,处理缺失值与异常值,并进行特征工程,例如提取“小时”、“星期几”、“是否节假日”等关键时间特征。
- 模型训练与调优:将历史数据划分为训练集与测试集,使用Scikit-learn库训练随机森林模型,并通过网格搜索(Grid Search)调整树的数量、深度等超参数以优化性能。
- 评估与部署:采用均方根误差(RMSE)、平均绝对百分比误差(MAPE)等指标评估模型精度。训练好的模型通过Flask接口封装,提供实时预测服务。
(上图:随机森林算法在客流预测中的工作流程示意图)
三、 系统功能设计:管理员与用户各取所需
系统围绕两类核心用户角色构建功能,确保既满足运营管理需求,又服务公众出行。
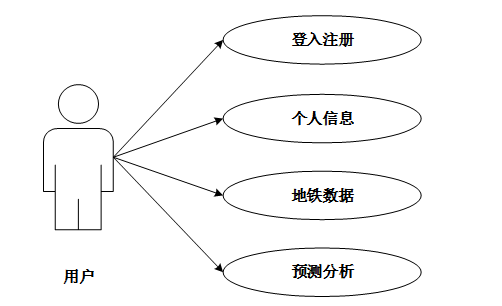
- 普通用户功能:用户可注册登录,查看个人中心。核心功能在于查询地铁客流数据,如实时拥挤度、历史流量趋势,并获取系统基于模型生成的未来时段客流预测,辅助规划出行,避开高峰。
- 管理员功能:管理员拥有更全面的数据视图和管理权限。除了查看所有预测分析,还能管理用户账户、导入/导出客流数据、监控模型运行状态,并对预测结果进行人工校准与标注,形成数据闭环,持续优化模型。
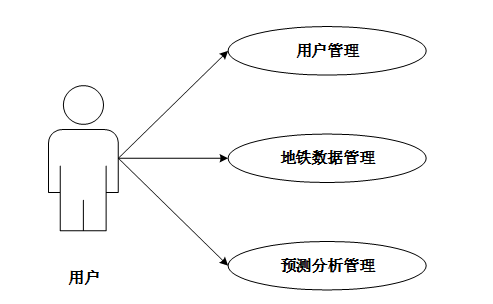
(上图:系统用户功能用例图)
四、 工程实现细节:Flask后端与数据库设计
后端采用Flask框架进行模块化设计,确保代码可维护性。
- 应用初始化与配置:通过工厂模式创建Flask应用,便于在不同环境(开发/测试/生产)下灵活配置。
- 路由与业务逻辑:设计清晰的路由(如
/api/predict,/api/data),将预测请求、数据查询等业务逻辑封装在对应的视图函数中。 - 数据库建模:设计核心数据表,例如:
user(用户表)、passenger_flow(客流记录表)、station(站点信息表)、prediction_result(预测结果表)。表结构设计需充分考虑查询效率,如在passenger_flow表的日期和站点字段上建立索引。
编号 | 字段名 | 类型 | 长度 | 是否非空 | 是否主键 | 注释 |
1 | article_id | mediumint | 是 | 是 | 文章id | |
2 | title | varchar | 125 | 是 | 是 | 标题 |
3 | type | varchar | 64 | 是 | 否 | 文章分类 |
4 | hits | int | 是 | 否 | 点击数 | |
5 | praise_len | int | 是 | 否 | 点赞数 | |
6 | create_time | timestamp | 是 | 否 | 创建时间 | |
7 | update_time | timestamp | 是 | 否 | 更新时间 | |
8 | source | varchar | 255 | 否 | 否 | 来源 |
9 | url | varchar | 255 | 否 | 否 | 来源地址 |
10 | tag | varchar | 255 | 否 | 否 | 标签 |
11 | content | longtext | 4294967295 | 否 | 否 | 正文 |
12 | img | varchar | 255 | 否 | 否 | 封面图 |
13 | description | text | 65535 | 否 | 否 | 文章描述 |
(上表:核心数据表结构设计示例)
五、 数据可视化:让数据“说话”
利用Vue.js和ECharts,我们将枯燥的数据转化为直观的图表。前端通过Axios调用Flask后端API获取数据,ECharts则负责渲染:
- 趋势预测图:折线图展示历史客流与未来预测值的对比,清晰呈现变化趋势。
- 站点热力图:在地铁线路图上,用颜色深浅直观展示各站点的实时客流量或拥挤度。
- 高峰分析图:柱状图显示每日不同时间段的客流量分布,一目了然地识别早、晚高峰。
(上图:客流数据可视化看板界面示意)
这种可视化方式不仅提升了管理者的决策效率,也让普通用户能快速理解复杂的客流信息。[AFFILIATE_SLOT_2]
六、 系统测试与可行性分析
在部署前,需对系统进行全面验证。
- 功能测试:覆盖用户登录注册、数据查询、预测生成等所有功能点,确保流程正确。
- 性能测试:评估系统在高并发请求下的响应时间与稳定性,确保预测接口的延迟在可接受范围内(如<2秒)。
- 可行性保障:
✅ 技术可行:所选技术栈成熟、社区活跃。
✅ 操作可行:界面友好,无需专业培训即可使用。
✅ 经济可行:基于开源技术,开发与部署成本可控。
七、 总结与展望
本文详细阐述了构建一个基于机器学习的地铁客流预测系统的完整路径,从技术选型(Python/Flask/Vue)、核心算法(随机森林),到系统设计与工程实现。该系统将数据挖掘、机器学习与Web开发相结合,实现了客流从“事后统计”到“事前预测”的跨越,为地铁运营的精细化、智能化提供了有力工具。未来,可考虑引入深度学习模型(如LSTM)处理更复杂的时间序列模式,或集成实时天气、事件数据,使预测更加精准,持续赋能智慧城市交通。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号