
深入解析Apriori算法:从“啤酒与尿布”到现代数据挖掘的关联规则引擎
在数据挖掘的广阔领域中,关联规则挖掘犹如一座桥梁,连接着海量数据与可执行的商业洞察。而Apriori算法,作为这座桥梁的经典奠基者,自1994年诞生以来,便以其直观的原理和强大的发现能力,成为理解关联分析不可或缺的基石。无论是零售业的购物篮分析,还是推荐系统的底层逻辑,Apriori都提供了清晰的范式。本文将带你深入其核心原理,剖析完整流程,并通过Python实战演示,让你彻底掌握这一经典算法的精髓与应用。
一、核心思想:先验原理与反单调性
Apriori算法的卓越之处,在于它巧妙地利用了先验原理来大幅削减计算量,避免了组合爆炸。这个原理包含两个相辅相成的方面:
- 正向性质:如果一个项集是频繁的,那么它的所有子集也必然是频繁的。这很好理解,因为子集的支持度只会比父集更高或持平。
- ⚡ 反向性质(反单调性):这是算法高效的关键。如果一个项集是非频繁的,那么它的所有超集也一定是非频繁的。这意味着一旦发现一个“不合格”的项集,就可以果断地将其所有扩展路径剪除,无需再进行无谓的计算。
正是基于这种“由下至上,逐层筛选,及时剪枝”的策略,Apriori算法才能在庞大的搜索空间中高效地定位出频繁模式。这种思想不仅适用于Python实现的数据分析,其优化逻辑也同样启发着Java、C++等高性能计算场景下的算法设计。
二、算法流程详解:两步走战略
Apriori算法的执行可以清晰地分为两个核心阶段,如同精密的流水线。
阶段一:频繁项集挖掘(生成-计数-剪枝循环)
这是算法的主体,采用逐层迭代的宽度优先搜索:
- 初始化:扫描数据库,计算所有单个项(1-项集)的支持度,筛选出满足最小支持度阈值(min_sup)的项,形成第一层频繁项集 L₁。
- 迭代循环(k≥2):
- 连接(Join):通过将Lₖ₋₁中的项集两两连接,生成候选k-项集Cₖ。连接条件是两个项集的前(k-2)项相同。
- 剪枝(Prune):利用先验原理,检查Cₖ中每个候选集的所有(k-1)-子集是否都在Lₖ₋₁中。只要有一个子集不频繁,则该候选集被剪枝。
- 计数与筛选:再次扫描数据库,计算剩余候选集的支持度,保留达到min_sup的项集,形成Lₖ。
循环直至无法产生新的频繁项集为止。这个过程在JavaScript或Go语言实现时,需要特别注意数据结构和循环效率。
阶段二:关联规则生成
基于挖掘出的所有频繁项集,生成有意义的规则:
- 对于每个频繁项集F,生成其所有非空真子集S。
- 对于每个子集S,计算规则 S → (F - S) 的置信度(即同时包含S和F-S的事务占包含S的事务的比例)。
- 保留置信度不低于最小置信度阈值(min_conf)的规则,即为强关联规则。
这里同样可以利用置信度的反单调性进行优化剪枝。
三、关键概念与评估指标
要理解Apriori的输出,必须掌握三个核心指标:
| 术语 | 定义 | 计算公式 |
|---|---|---|
| 事务 (Transaction) | 数据库中的一条记录,如一次购物的商品清单 | - |
| 项 (Item) | 事务中的基本单位,如一件商品 | - |
| 项集 (Itemset) | 若干项的集合,k 个项的集合称为 k - 项集 | - |
| 支持度 (Support) | 包含项集的事务数占总事务数的比例,衡量项集的普遍性 | Support (X) = (包含 X 的事务数)/(总事务数) |
| 置信度 (Confidence) | 事务包含 X 时也包含 Y 的概率,衡量规则 X→Y 的可靠性 | Confidence(X→Y) = Support(X∪Y) / Support(X) |
| 频繁项集 (Frequent Itemset) | 支持度≥最小支持度阈值 (min_sup) 的项集 | - |
| 强关联规则 (Strong Rule) | 同时满足最小支持度和最小置信度 (min_conf) 的关联规则 | - |
| 提升度 (Lift) | 规则 X→Y 的置信度与 Y 的支持度之比,衡量规则的有效性 | Lift(X→Y) = Confidence(X→Y) / Support(Y) |
除了支持度和置信度,提升度(Lift)也是一个重要指标,用于衡量规则的有效性。提升度等于1表示两者独立,大于1表示正相关,小于1表示负相关。在实际业务中,综合考量这些指标才能筛选出真正有价值的规则。[AFFILIATE_SLOT_1]
四、实战演示:从理论到数据
让我们通过一个经典的购物篮小例子,直观感受算法的运行过程。
示例数据集
| 事务 ID | 购买商品 |
|---|---|
| T1 | 牛奶,面包,尿布 |
| T2 | 可乐,面包,尿布,啤酒 |
| T3 | 牛奶,尿布,啤酒,鸡蛋 |
| T4 | 面包,牛奶,尿布,啤酒 |
| T5 | 面包,牛奶,尿布,可乐 |
假设最小支持度min_sup=0.6(即出现3次以上),最小置信度min_conf=0.8。
挖掘过程简述
- L₁:{牛奶,面包,尿布,啤酒}(可乐支持度仅为2,被过滤)。
- L₂:通过连接L₁并剪枝、计数后得到,如{牛奶,面包}、{尿布,啤酒}等。 L₃:进一步得到如{牛奶,面包,尿布}等三元频繁项集。
规则生成示例
以频繁项集{牛奶,尿布,啤酒}为例:
- 规则 {尿布,啤酒} → {牛奶}:置信度 = 支持度({牛奶,尿布,啤酒}) / 支持度({尿布,啤酒}) = 3/3 = 1.0 ≥ 0.8 ✅ 强规则。
- 规则 {牛奶} → {尿布,啤酒}:置信度 = 3/4 = 0.75 < 0.8 ❌ 被过滤。
五、Python实战:快速应用与可视化
现代数据分析中,我们无需从头造轮子。使用Python的`mlxtend`库可以快速实现Apriori算法并分析结果。
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori, association_rules
import pandas as pd
# 1. 准备数据
dataset = [
['牛奶', '面包', '尿布'],
['可乐', '面包', '尿布', '啤酒'],
['牛奶', '尿布', '啤酒', '鸡蛋'],
['面包', '牛奶', '尿布', '啤酒'],
['面包', '牛奶', '尿布', '可乐']
]
# 2. 数据编码
te = TransactionEncoder()
te_ary = te.fit(dataset).transform(dataset)
df = pd.DataFrame(te_ary, columns=te.columns_)
# 3. 挖掘频繁项集(min_sup=0.6)
frequent_itemsets = apriori(df, min_support=0.6, use_colnames=True)
print("频繁项集:")
print(frequent_itemsets)
# 4. 生成关联规则(min_conf=0.8)
rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.8)
print("\n强关联规则:")
print(rules[['antecedents', 'consequents', 'support', 'confidence', 'lift']])这段代码清晰地展示了如何使用第三方库高效完成频繁项集挖掘和规则生成。对于希望深入理解底层机制的学习者,手动实现算法是更好的途径。
六、手动实现与深度优化
为了彻底掌握算法,理解其每一步的细节,手动实现一个Apriori算法是宝贵的经历。以下是一个完整的、不依赖第三方库的实现示例,它包含了数据加载、核心算法、以及丰富的结果可视化功能。
首先,准备示例数据文件:
矿泉水,薯片,酸奶,面包,鸡蛋
啤酒,尿布,面包,鸡蛋
可乐,啤酒,尿布,牛奶,面包
啤酒,尿布,牛奶,酸奶,面包
可乐,啤酒,尿布,牛奶,薯片
可乐,啤酒,面包,鸡蛋
啤酒,尿布,牛奶,矿泉水
啤酒,尿布,面包
可乐,啤酒,矿泉水,酸奶
啤酒,尿布,火腿肠,牛奶,面包
可乐,尿布,矿泉水
可乐,啤酒,牛奶,酸奶
啤酒,牛奶,薯片,酸奶,面包
可乐,尿布,牛奶,面包,鸡蛋
可乐,啤酒,尿布,面包
可乐,啤酒,尿布,酸奶,鸡蛋
可乐,啤酒,火腿肠,薯片,面包
啤酒,尿布,牛奶,矿泉水,面包
啤酒,尿布,牛奶,酸奶
啤酒,尿布,火腿肠,牛奶,面包,鸡蛋
啤酒,尿布,矿泉水,酸奶,面包
啤酒,尿布,火腿肠,牛奶
尿布,牛奶,矿泉水,酸奶,鸡蛋
啤酒,尿布,酸奶,面包
尿布,火腿肠,牛奶,鸡蛋
可乐,尿布,牛奶,矿泉水
啤酒,火腿肠,矿泉水,薯片,面包
啤酒,尿布,牛奶,薯片,鸡蛋
矿泉水,酸奶,面包
牛奶,矿泉水,鸡蛋
可乐,啤酒,尿布,牛奶,酸奶,面包
啤酒,牛奶,矿泉水,薯片,面包
可乐,啤酒,尿布,酸奶,面包
可乐,尿布,薯片,鸡蛋
可乐,火腿肠,面包
可乐,尿布,矿泉水,薯片,鸡蛋
啤酒,尿布,酸奶,鸡蛋
可乐,火腿肠,酸奶,鸡蛋
啤酒,尿布,牛奶,鸡蛋
尿布,火腿肠,牛奶,薯片,鸡蛋
牛奶,酸奶,面包
啤酒,火腿肠,牛奶,矿泉水,酸奶
啤酒,尿布,火腿肠,面包
啤酒,尿布,薯片,面包
可乐,牛奶,鸡蛋
啤酒,尿布,酸奶
可乐,尿布,薯片,面包,鸡蛋
可乐,啤酒,尿布,矿泉水,面包
啤酒,尿布,牛奶,面包,鸡蛋
尿布,薯片,酸奶,面包,鸡蛋
啤酒,尿布,牛奶,矿泉水,酸奶,面包
啤酒,尿布,牛奶,薯片,面包
啤酒,尿布,薯片,酸奶,面包
火腿肠,牛奶,薯片,鸡蛋
可乐,啤酒,尿布,牛奶
可乐,啤酒,尿布,牛奶,酸奶
啤酒,尿布,牛奶,矿泉水,薯片,面包
啤酒,尿布,牛奶,面包
啤酒,尿布,牛奶
可乐,牛奶,薯片,面包,鸡蛋
尿布,火腿肠,鸡蛋
矿泉水,面包,鸡蛋
啤酒,尿布,牛奶,薯片
可乐,啤酒,尿布,薯片,酸奶
矿泉水,酸奶,面包
火腿肠,矿泉水,薯片,酸奶,面包
可乐,尿布,矿泉水,面包
尿布,牛奶,酸奶,面包
啤酒,火腿肠,牛奶
可乐,尿布,牛奶,薯片,面包
牛奶,矿泉水,面包
啤酒,火腿肠,牛奶,矿泉水,薯片
可乐,尿布,薯片,鸡蛋
啤酒,火腿肠,牛奶,薯片,酸奶
啤酒,火腿肠,面包
可乐,啤酒,酸奶
可乐,尿布,薯片
可乐,啤酒,牛奶,面包,鸡蛋
火腿肠,薯片,酸奶,鸡蛋
可乐,啤酒,薯片,面包
啤酒,尿布,薯片,酸奶,面包
啤酒,面包,鸡蛋
啤酒,尿布,牛奶,面包
可乐,啤酒,牛奶,酸奶,鸡蛋
啤酒,尿布,火腿肠,薯片,面包
尿布,火腿肠,矿泉水,薯片,酸奶
可乐,尿布,牛奶,薯片
可乐,牛奶,鸡蛋
可乐,薯片,酸奶,面包,鸡蛋
啤酒,牛奶,酸奶,鸡蛋
啤酒,牛奶,矿泉水,薯片,鸡蛋
可乐,尿布,火腿肠,鸡蛋
可乐,牛奶,薯片
啤酒,火腿肠,矿泉水,面包,鸡蛋
可乐,啤酒,薯片
火腿肠,矿泉水,薯片
可乐,矿泉水,酸奶
可乐,尿布,牛奶,酸奶
矿泉水,薯片,面包,鸡蛋
火腿肠,矿泉水,薯片,酸奶,面包接着,是Apriori算法的完整Python实现:
import os
import sys
from collections import defaultdict
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import numpy as np
# 3D绘图必备库
from mpl_toolkits.mplot3d import Axes3D
# ===================== 全局配置:Matplotlib中文显示+样式美化 =====================
plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans'] # 解决中文乱码(SimHei=黑体,适配Windows)
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
plt.rcParams['figure.facecolor'] = 'white' # 画布背景色
plt.rcParams['axes.facecolor'] = '#f8f9fa' # 坐标轴背景色
plt.rcParams['grid.alpha'] = 0.3 # 网格透明度
plt.rcParams['savefig.dpi'] = 300 # 保存图片高清DPI
plt.rcParams['figure.dpi'] = 100 # 显示图片DPI
plt.rcParams['font.size'] = 10 # 全局字体大小
# 定义配色方案(贴合数据分析)
COLORS = ['#2E86AB', '#A23B72', '#F18F01', '#C73E1D', '#7209B7', '#0B4F6C']
# 关联类型配色
REL_COLORS = {
"强正关联": "#C73E1D",
"弱正关联": "#F18F01",
"无关联/负关联": "#2E86AB"
}
# ===================== 全局工具函数(辅助功能)=====================
def print_separator(char="-", length=80, title=""):
"""打印分隔线,美化输出(可视化基础)"""
if title:
print(f"{char * ((length - len(title) - 2) // 2)} {title} {char * ((length - len(title) - 2) // 2)}")
else:
print(char * length)
def format_table(headers, rows, align="left"):
"""格式化生成文本表格(核心可视化函数)"""
col_widths = [len(str(h)) for h in headers]
for row in rows:
for i, val in enumerate(row):
val_len = len(str(val))
if val_len > col_widths[i]:
col_widths[i] = val_len
align_fun = {
"left": lambda s, w: str(s).ljust(w),
"right": lambda s, w: str(s).rjust(w),
"center": lambda s, w: str(s).center(w)
}[align]
table = [' | '.join([align_fun(h, col_widths[i]) for i, h in enumerate(headers)])]
table.append(' | '.join(["-" * w for w in col_widths]))
for row in rows:
table.append(' | '.join([align_fun(val, col_widths[i]) for i, val in enumerate(row)]))
return "\n".join(table)
def text_bar_chart(data, title, x_label, y_label, max_bar_len=50):
"""生成文本柱状图(可视化统计分布)"""
if not data:
return f"{title}\n暂无数据"
max_val = max(data.values())
bar_data = {k: int(v / max_val * max_bar_len) if max_val != 0 else 0 for k, v in data.items()}
chart = [f"【{title}】", f"{y_label:>10} | {x_label:<{max_bar_len}} (数值)"]
chart.append("-" * (12 + max_bar_len + 8))
for k, v in sorted(data.items(), key=lambda x: x[1], reverse=True):
bar = "■" * bar_data[k]
chart.append(f"{str(k):>10} | {bar:<{max_bar_len}} ({v})")
return "\n".join(chart)
# ===================== 数据加载与清洗模块 =====================
def load_transactions(data_source="test", file_path=None):
"""加载并清洗事务数据"""
raw_transactions = []
if data_source == "test":
raw_transactions = [
"牛奶,面包,尿布",
"可乐,面包,尿布,啤酒",
"牛奶,尿布,啤酒,鸡蛋",
"面包,牛奶,尿布,啤酒",
"面包,牛奶,尿布,可乐",
"牛奶,面包,啤酒",
"尿布,啤酒,可乐",
"面包,尿布,啤酒"
]
print_separator(title="加载内置测试数据(购物篮数据)")
elif data_source == "file":
if not file_path or not os.path.exists(file_path):
raise FileNotFoundError(f"文件路径无效:{file_path}")
with open(file_path, "r", encoding="utf-8") as f:
raw_transactions = [line.strip() for line in f if line.strip()]
print_separator(title=f"加载本地文件:{os.path.basename(file_path)}")
else:
raise ValueError("数据来源仅支持:test(内置测试)/file(本地文件)")
clean_transactions = []
all_items = set()
for line in raw_transactions:
items = [item.strip() for item in line.replace(" ", ",").replace("\t", ",").split(",")]
valid_items = set([item for item in items if item])
if valid_items:
clean_transactions.append(valid_items)
all_items.update(valid_items)
print(f"原始事务数:{len(raw_transactions)} | 清洗后有效事务数:{len(clean_transactions)}")
print(f"数据集中唯一项总数:{len(all_items)} | 所有项:{sorted(all_items)}")
return clean_transactions, sorted(all_items)
# ===================== Apriori核心算法模块(频繁项集挖掘)=====================
def calculate_support(transaction_set, itemset, total_trans):
"""计算项集的支持度"""
if total_trans == 0:
return 0.0, 0
itemset = set(itemset)
count = 0
for trans in transaction_set:
if itemset.issubset(trans):
count += 1
support = round(count / total_trans, 4)
return support, count
def create_c1(all_items):
"""生成1-候选项集C1"""
return [(item,) for item in all_items]
def apriori_gen(frequent_k_1, k):
"""连接+剪枝,生成k-候选项集Ck"""
Ck = []
len_fk1 = len(frequent_k_1)
for i in range(len_fk1):
for j in range(i + 1, len_fk1):
list_i = list(frequent_k_1[i])[:k - 2]
list_j = list(frequent_k_1[j])[:k - 2]
if list_i == list_j:
new_itemset = tuple(sorted(set(frequent_k_1[i]) | set(frequent_k_1[j])))
if len(new_itemset) == k:
Ck.append(new_itemset)
pruned_Ck = []
frequent_k_1_set = set(frequent_k_1)
for candidate in Ck:
subsets = []
for i in range(len(candidate)):
subset = tuple(sorted(set(candidate) - {candidate[i]}))
subsets.append(subset)
if all(s in frequent_k_1_set for s in subsets):
pruned_Ck.append(candidate)
return pruned_Ck
def get_frequent_itemsets(transaction_set, min_support):
"""逐层挖掘所有频繁项集"""
total_trans = len(transaction_set)
if total_trans == 0:
return {}, 0
all_items = sorted({item for trans in transaction_set for item in trans})
frequent_itemsets = defaultdict(list)
k = 1
C1 = create_c1(all_items)
L1 = []
for itemset in C1:
support, _ = calculate_support(transaction_set, itemset, total_trans)
if support >= min_support:
L1.append((itemset, support))
if not L1:
return frequent_itemsets, total_trans
frequent_itemsets[k] = L1
print_separator(title=f"挖掘到{len(L1)}个1-频繁项集")
while True:
k += 1
frequent_k_1 = [itemset for itemset, sup in frequent_itemsets[k - 1]]
Ck = apriori_gen(frequent_k_1, k)
if not Ck:
break
Lk = []
for candidate in Ck:
support, _ = calculate_support(transaction_set, candidate, total_trans)
if support >= min_support:
Lk.append((candidate, support))
if not Lk:
break
frequent_itemsets[k] = Lk
print_separator(title=f"挖掘到{len(Lk)}个{k}-频繁项集")
return frequent_itemsets, total_trans
# ===================== 关联规则生成模块 =====================
def generate_association_rules(frequent_itemsets, transaction_set, total_trans, min_confidence):
"""基于频繁项集生成强关联规则"""
strong_rules = []
for k in frequent_itemsets:
if k < 2:
continue
for itemset, sup_XY in frequent_itemsets[k]:
itemset_set = set(itemset)
subsets = []
def dfs(remaining, current):
if current and remaining:
subsets.append(tuple(sorted(current)))
for i in range(len(remaining)):
dfs(remaining[i + 1:], current + [remaining[i]])
dfs(sorted(itemset_set), [])
for S in subsets:
S_set = set(S)
Y_set = itemset_set - S_set
Y = tuple(sorted(Y_set))
sup_S, _ = calculate_support(transaction_set, S, total_trans)
if sup_S == 0:
continue
confidence = round(sup_XY / sup_S, 4)
sup_Y, _ = calculate_support(transaction_set, Y, total_trans)
lift = round(confidence / sup_Y if sup_Y != 0 else 0, 4)
support = sup_XY
if confidence >= min_confidence:
strong_rules.append((S, Y, support, confidence, lift))
strong_rules = list(set(strong_rules))
strong_rules.sort(key=lambda x: x[4], reverse=True)
return strong_rules
# ===================== 纯文本可视化模块 =====================
def visualize_analysis_result(transaction_set, frequent_itemsets, strong_rules, total_trans):
"""纯文本可视化所有分析结果"""
all_items = sorted({item for trans in transaction_set for item in trans})
print_separator(char="=", title="Apriori算法分析结果可视化报告", length=100)
print_separator(title="一、数据基本概览")
data_overview = [
["总事务数", total_trans],
["有效事务数", len(transaction_set)],
["唯一项总数", len(all_items)],
["数据稀疏度", f"{round(1 - sum(len(t) for t in transaction_set) / (total_trans * len(all_items)), 4) * 100}%"],
["频繁项集总数量", sum(len(v) for v in frequent_itemsets.values())],
["强关联规则数量", len(strong_rules)]
]
print(format_table(["指标", "数值"], data_overview, align="center"))
print_separator(title="二、频繁项集详情")
if not frequent_itemsets:
print("⚠️ 未挖掘到满足最小支持度的频繁项集,请降低最小支持度阈值!")
else:
for k in sorted(frequent_itemsets.keys()):
fk_items = frequent_itemsets[k]
rows = [[",".join(itemset), support] for itemset, support in fk_items]
print(f"\n【{k}-项集(共{len(fk_items)}个)】")
print(format_table([f"{k}-项集", "支持度"], rows, align="left"))
fk_count = {f"{k}-项集": len(v) for k, v in frequent_itemsets.items()}
print("\n" + text_bar_chart(fk_count, "频繁项集数量分布", "数量", "项集维度"))
print_separator(title="三、强关联规则详情(按提升度降序)")
if not strong_rules:
print("⚠️ 未生成满足最小置信度的强关联规则,请降低最小置信度/支持度阈值!")
else:
rows = []
for S, Y, sup, conf, lift in strong_rules:
rel_type = "强正关联" if lift > 1.2 else "弱正关联" if lift > 1 else "无关联/负关联"
rows.append([",".join(S) + " → " + ",".join(Y), sup, conf, lift, rel_type])
print(format_table(["关联规则", "支持度", "置信度", "提升度", "关联类型"], rows, align="left"))
lift_count = defaultdict(int)
for _, _, _, _, lift in strong_rules:
if lift > 1.2:
lift_count["lift>1.2(强正)"] += 1
elif lift > 1:
lift_count["1= 2 else 1
n_rows = (len(k_sorted) + n_cols - 1) // n_cols
fig, axes = plt.subplots(n_rows, n_cols, figsize=(6 * n_cols, 5 * n_rows), squeeze=False)
axes = axes.flatten()
for idx, k in enumerate(k_sorted):
ax = axes[idx]
fk_items = frequent_itemsets[k]
itemset_str = [",".join(itemset) for itemset, sup in fk_items]
support_list = [sup for itemset, sup in fk_items]
bars = ax.barh(itemset_str, support_list, color=COLORS[0], edgecolor="black", alpha=0.8)
for bar, sup in zip(bars, support_list):
ax.text(bar.get_width() + 0.01, bar.get_y() + bar.get_height() / 2, f"{sup:.4f}", ha="left", va="center",
fontweight="bold")
ax.set_title(f"{k}-项集 支持度分布", fontsize=12, fontweight="bold", pad=15)
ax.set_xlabel("支持度", fontsize=10, labelpad=5)
ax.set_xlim(0, 1.05)
ax.grid(axis="x", linestyle="--")
for idx in range(len(k_sorted), len(axes)):
axes[idx].set_visible(False)
fig.suptitle("各维度频繁项集支持度详情", fontsize=14, fontweight="bold", y=1.02)
fig.tight_layout()
save_file = os.path.join(save_path, "2-频繁项集支持度分布.png")
plt.savefig(save_file, bbox_inches="tight")
print(f"✅ 【频繁项集支持度分布】图已保存至:{save_file}")
def plot_association_rules_scatter(strong_rules, save_path="./"):
"""图3:关联规则 支持度-置信度 散点图(基础版)"""
if not strong_rules:
print("⚠️ 无强关联规则,跳过【关联规则散点图】绘图")
return
support_list, confidence_list, lift_list, rel_type_list = [], [], [], []
for S, Y, sup, conf, lift in strong_rules:
support_list.append(sup)
confidence_list.append(conf)
lift_list.append(lift)
rel_type_list.append("强正关联" if lift > 1.2 else "弱正关联" if lift > 1 else "无关联/负关联")
lift_norm = [(lift - min(lift_list)) / (max(lift_list) - min(lift_list)) * 500 + 100 for lift in lift_list]
fig, ax = plt.subplots(figsize=(10, 6))
for rel_type in ["强正关联", "弱正关联", "无关联/负关联"]:
if rel_type not in rel_type_list:
continue
mask = [r == rel_type for r in rel_type_list]
ax.scatter(
[s for s, m in zip(support_list, mask) if m],
[c for c, m in zip(confidence_list, mask) if m],
s=[l for l, m in zip(lift_norm, mask) if m],
c=REL_COLORS[rel_type], label=rel_type, alpha=0.7, edgecolors="black", linewidth=0.5
)
ax.set_title("关联规则:支持度 × 置信度(点大小=提升度)", fontsize=14, fontweight="bold", pad=20)
ax.set_xlabel("支持度", fontsize=12, labelpad=10)
ax.set_ylabel("置信度", fontsize=12, labelpad=10)
ax.legend(loc="best", frameon=True, shadow=True)
ax.grid(True, linestyle="--", alpha=0.5)
ax.set_xlim(0, 1.05)
ax.set_ylim(0, 1.05)
fig.tight_layout()
save_file = os.path.join(save_path, "3-关联规则_支持度-置信度散点图.png")
plt.savefig(save_file, bbox_inches="tight")
print(f"✅ 【关联规则散点图】已保存至:{save_file}")
def plot_lift_distribution(strong_rules, save_path="./"):
"""图4:提升度区间分布(柱状图+饼图 双图)"""
if not strong_rules:
print("⚠️ 无强关联规则,跳过【提升度分布】绘图")
return
lift_count = defaultdict(int)
for _, _, _, _, lift in strong_rules:
if lift > 1.2:
lift_count["lift>1.2\n(强正关联)"] += 1
elif lift > 1:
lift_count["11.2,添加文字标签)"""
if not strong_rules:
print("⚠️ 无强关联规则,跳过【核心规则标签散点图】绘图")
return
# 筛选核心规则(lift>1.2)+ 所有规则基础数据
support_list, confidence_list, lift_list, rel_type_list, rule_str_list = [], [], [], [], []
core_rule_mask = [] # 标记是否为核心规则
for S, Y, sup, conf, lift in strong_rules:
support_list.append(sup)
confidence_list.append(conf)
lift_list.append(lift)
rel_type = "强正关联" if lift > 1.2 else "弱正关联" if lift > 1 else "无关联/负关联"
rel_type_list.append(rel_type)
rule_str_list.append(f"{','.join(S)}→{','.join(Y)}")
core_rule_mask.append(lift > 1.2)
# 无核心规则则跳过
if not any(core_rule_mask):
print("⚠️ 无核心规则(lift>1.2),跳过【核心规则标签散点图】绘图")
return
# 归一化提升度(点大小)
lift_norm = [(lift - min(lift_list)) / (max(lift_list) - min(lift_list)) * 500 + 100 for lift in lift_list]
fig, ax = plt.subplots(figsize=(12, 7))
# 绘制所有规则散点
for rel_type in ["强正关联", "弱正关联", "无关联/负关联"]:
if rel_type not in rel_type_list:
continue
mask = [r == rel_type for r in rel_type_list]
ax.scatter(
[s for s, m in zip(support_list, mask) if m],
[c for c, m in zip(confidence_list, mask) if m],
s=[l for l, m in zip(lift_norm, mask) if m],
c=REL_COLORS[rel_type], label=rel_type, alpha=0.7, edgecolors="black", linewidth=0.5
)
# 为核心规则添加文字标签(避免重叠,轻微偏移)
for i, is_core in enumerate(core_rule_mask):
if is_core:
ax.annotate(
rule_str_list[i], # 规则标签
xy=(support_list[i], confidence_list[i]), # 标签对应点
xytext=(5, 5), # 标签偏移量
textcoords="offset points",
fontsize=9,
bbox=dict(boxstyle="round,pad=0.3", facecolor="white", alpha=0.8, edgecolor="#333333"),
arrowprops=dict(arrowstyle="->", color="#666666", lw=0.8)
)
# 样式设置
ax.set_title("核心关联规则(lift>1.2)标签散点图", fontsize=14, fontweight="bold", pad=20)
ax.set_xlabel("支持度", fontsize=12, labelpad=10)
ax.set_ylabel("置信度", fontsize=12, labelpad=10)
ax.legend(loc="best", frameon=True, shadow=True)
ax.grid(True, linestyle="--", alpha=0.5)
ax.set_xlim(0, 1.05)
ax.set_ylim(0, 1.05)
fig.tight_layout()
save_file = os.path.join(save_path, "5-核心关联规则标签散点图.png")
plt.savefig(save_file, bbox_inches="tight")
print(f"✅ 【核心关联规则标签散点图】已保存至:{save_file}")
# ---------------------- 3-项集及以上支持度热力图 ----------------------
def plot_3itemset_support_heatmap(frequent_itemsets, save_path="./"):
"""图6:3-项集及以上频繁项集支持度热力图"""
if not frequent_itemsets:
print("⚠️ 无频繁项集,跳过【3-项集支持度热力图】绘图")
return
# 筛选3-项集及以上
high_k_items = []
for k in frequent_itemsets:
if k >= 3:
high_k_items.extend(frequent_itemsets[k])
if not high_k_items:
print("⚠️ 无3-项集及以上频繁项集,跳过【3-项集支持度热力图】绘图")
return
# 处理数据:提取所有唯一元素,构建项集-元素矩阵
all_items = sorted(list(set(item for itemset, _ in high_k_items for item in itemset)))
itemset_str = [",".join(sorted(itemset)) for itemset, sup in high_k_items]
support_vals = [sup for itemset, sup in high_k_items]
# 构建热力图数据矩阵
heatmap_data = np.zeros((len(itemset_str), len(all_items)))
for i, (itemset, sup) in enumerate(high_k_items):
for j, item in enumerate(all_items):
if item in itemset:
heatmap_data[i, j] = sup
# 绘图
fig, ax = plt.subplots(figsize=(10, max(6, len(itemset_str) * 0.8)))
im = ax.imshow(heatmap_data, cmap="Blues", aspect="auto", vmin=0, vmax=1)
# 设置坐标轴标签
ax.set_xticks(range(len(all_items)))
ax.set_xticklabels(all_items, rotation=45, ha="right")
ax.set_yticks(range(len(itemset_str)))
ax.set_yticklabels(itemset_str)
# 添加数值标签
for i in range(len(itemset_str)):
for j in range(len(all_items)):
if heatmap_data[i, j] > 0:
text = ax.text(j, i, f"{heatmap_data[i, j]:.4f}",
ha="center", va="center", color="black" if heatmap_data[i, j] < 0.5 else "white",
fontweight="bold", fontsize=9)
# 颜色条
cbar = fig.colorbar(im, ax=ax)
cbar.set_label("支持度", fontsize=12, labelpad=10)
# 样式设置
ax.set_title("3-项集及以上频繁项集支持度热力图", fontsize=14, fontweight="bold", pad=20)
ax.set_xlabel("项集元素", fontsize=12, labelpad=10)
ax.set_ylabel("3-项集及以上组合", fontsize=12, labelpad=10)
fig.tight_layout()
save_file = os.path.join(save_path, "6-3项集及以上支持度热力图.png")
plt.savefig(save_file, bbox_inches="tight")
print(f"✅ 【3-项集支持度热力图】已保存至:{save_file}")
# ---------------------- 规则置信度分布直方图 ----------------------
def plot_confidence_distribution(strong_rules, save_path="./"):
"""图7:强关联规则置信度分布直方图"""
if not strong_rules:
print("⚠️ 无强关联规则,跳过【置信度分布直方图】绘图")
return
# 提取置信度数据
confidence_vals = [conf for _, _, _, conf, _ in strong_rules]
# 绘图:自动分箱(10个区间,适配0-1范围)
fig, ax = plt.subplots(figsize=(10, 5))
n, bins, patches = ax.hist(confidence_vals, bins=10, range=(0, 1), color=COLORS[1],
edgecolor="black", alpha=0.8, rwidth=0.9)
# 添加频数标签
for patch, count in zip(patches, n):
if count > 0:
ax.text(patch.get_x() + patch.get_width() / 2, patch.get_height() + 0.5,
str(int(count)), ha="center", va="bottom", fontweight="bold")
# 样式设置
ax.set_title("强关联规则置信度分布直方图", fontsize=14, fontweight="bold", pad=20)
ax.set_xlabel("置信度", fontsize=12, labelpad=10)
ax.set_ylabel("规则数量(频数)", fontsize=12, labelpad=10)
ax.grid(axis="y", linestyle="--")
ax.set_xlim(0, 1.05)
ax.set_ylim(0, max(n) * 1.2)
# 添加统计信息
mean_conf = np.mean(confidence_vals)
median_conf = np.median(confidence_vals)
ax.text(0.05, 0.95, f"均值:{mean_conf:.4f}\n中位数:{median_conf:.4f}",
transform=ax.transAxes, ha="left", va="top",
bbox=dict(boxstyle="round,pad=0.5", facecolor="white", alpha=0.8))
fig.tight_layout()
save_file = os.path.join(save_path, "7-关联规则置信度分布直方图.png")
plt.savefig(save_file, bbox_inches="tight")
print(f"✅ 【置信度分布直方图】已保存至:{save_file}")
# ---------------------- 3D支持度-置信度-提升度散点图 ----------------------
def plot_3d_rule_scatter(strong_rules, save_path="./"):
"""图8:3D散点图(x=支持度,y=置信度,z=提升度)"""
if not strong_rules:
print("⚠️ 无强关联规则,跳过【3D规则散点图】绘图")
return
# 提取数据并分类
support_list, confidence_list, lift_list, color_list = [], [], [], []
for S, Y, sup, conf, lift in strong_rules:
support_list.append(sup)
confidence_list.append(conf)
lift_list.append(lift)
# 按关联类型配色
if lift > 1.2:
color_list.append(REL_COLORS["强正关联"])
elif lift > 1:
color_list.append(REL_COLORS["弱正关联"])
else:
color_list.append(REL_COLORS["无关联/负关联"])
# 创建3D画布
fig = plt.figure(figsize=(12, 8))
ax = fig.add_subplot(111, projection='3d')
# 绘制3D散点
scatter = ax.scatter(support_list, confidence_list, lift_list,
c=color_list, s=150, alpha=0.7, edgecolors="black", linewidth=0.5)
# 设置坐标轴标签
ax.set_xlabel("支持度 (Support)", fontsize=12, labelpad=15)
ax.set_ylabel("置信度 (Confidence)", fontsize=12, labelpad=15)
ax.set_zlabel("提升度 (Lift)", fontsize=12, labelpad=15)
# 设置视角(仰角30°,方位角45°,可手动旋转)
ax.view_init(elev=30, azim=45)
# 添加图例
legend_elements = [mpatches.Patch(color=REL_COLORS["强正关联"], label="强正关联 (lift>1.2)"),
mpatches.Patch(color=REL_COLORS["弱正关联"], label="弱正关联 (1 nul")
main() 这个手动实现版本不仅完成了核心的频繁项集挖掘和规则生成,还输出了详细的文本报告和一系列可视化图表,帮助我们从多角度理解数据模式和规则质量。
可视化结果解读
算法生成的可视化图表让我们对结果一目了然:
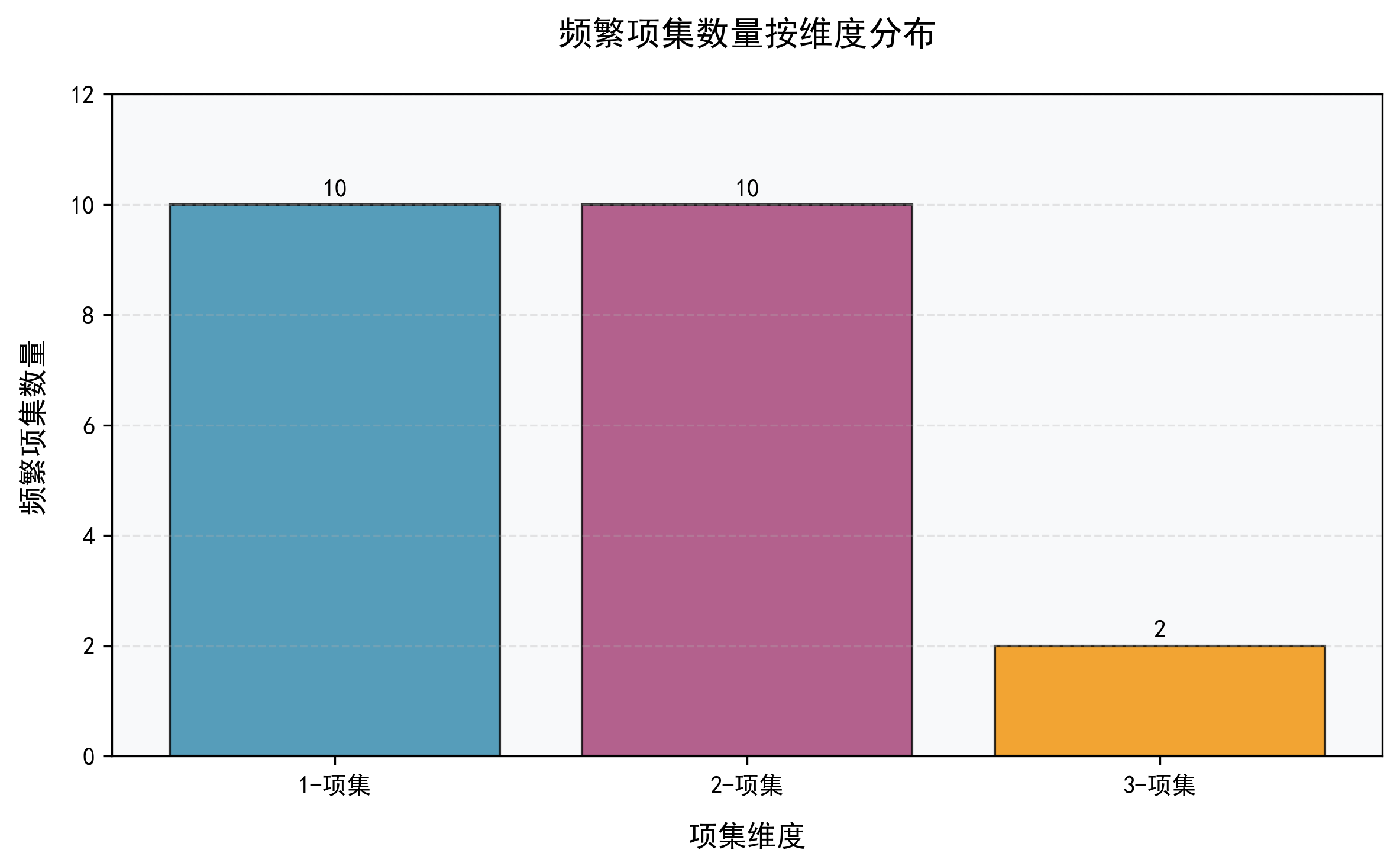
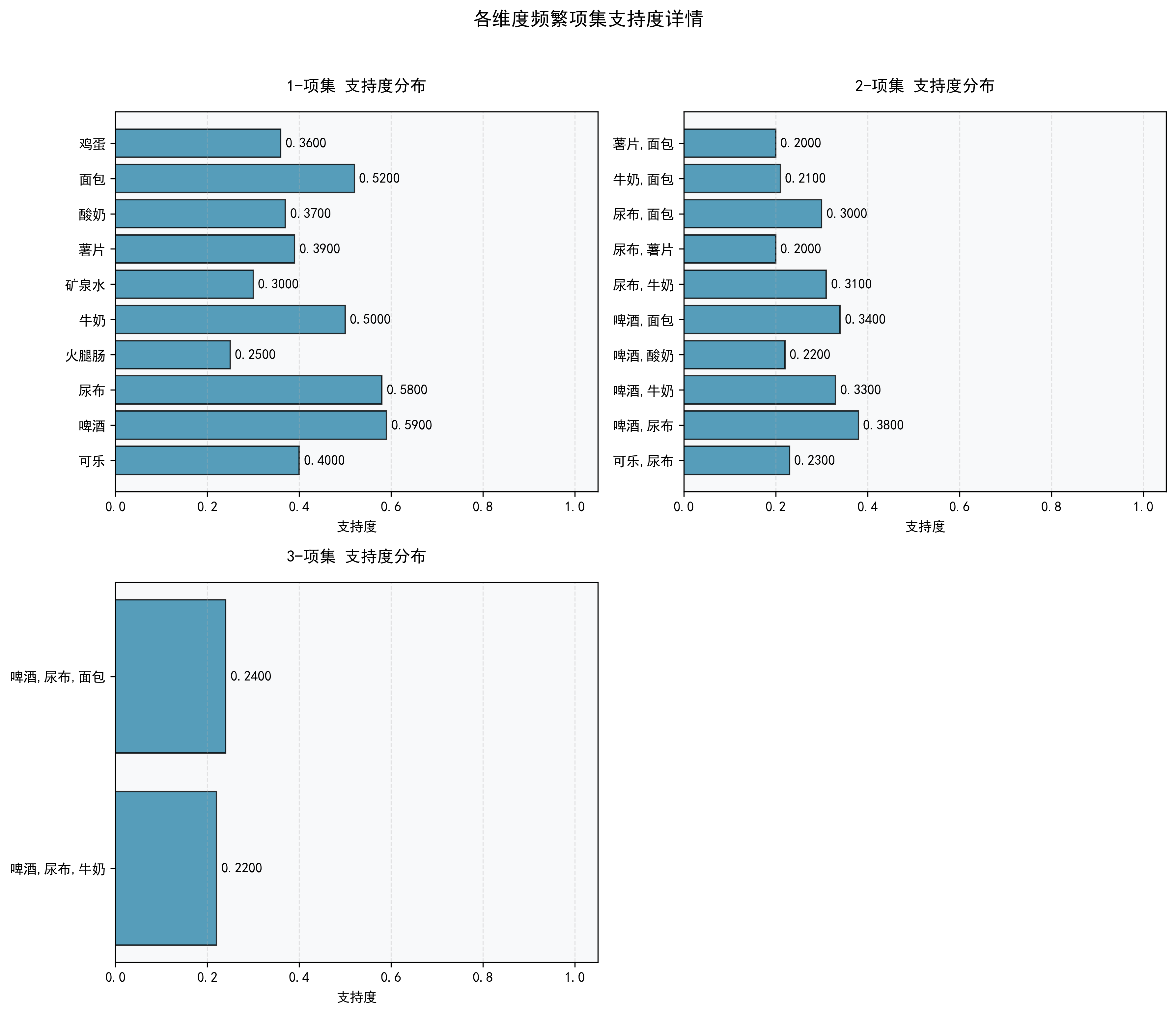
- 频繁项集数量与支持度分布:直观展示了不同维度项集的发现数量及其普遍性。
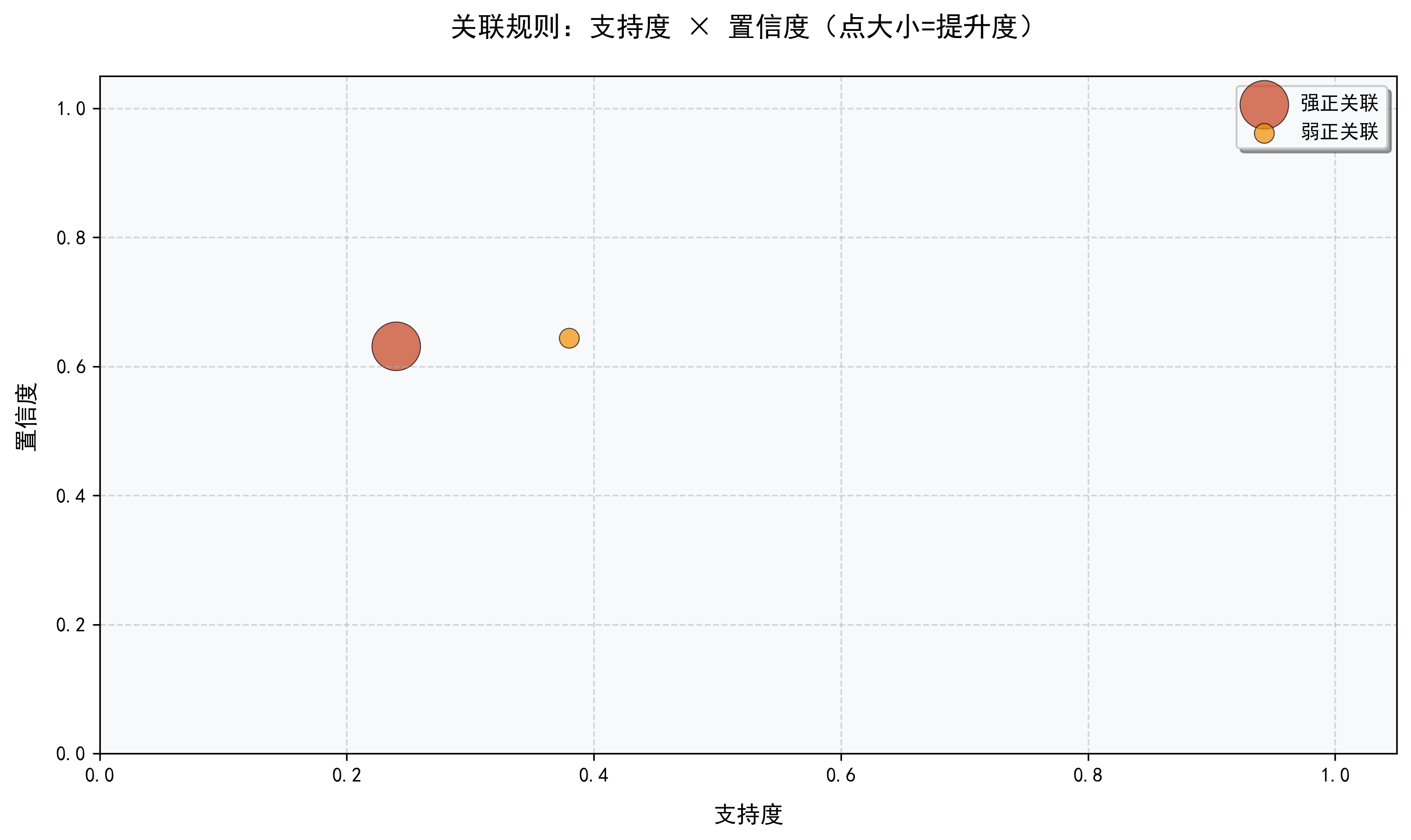
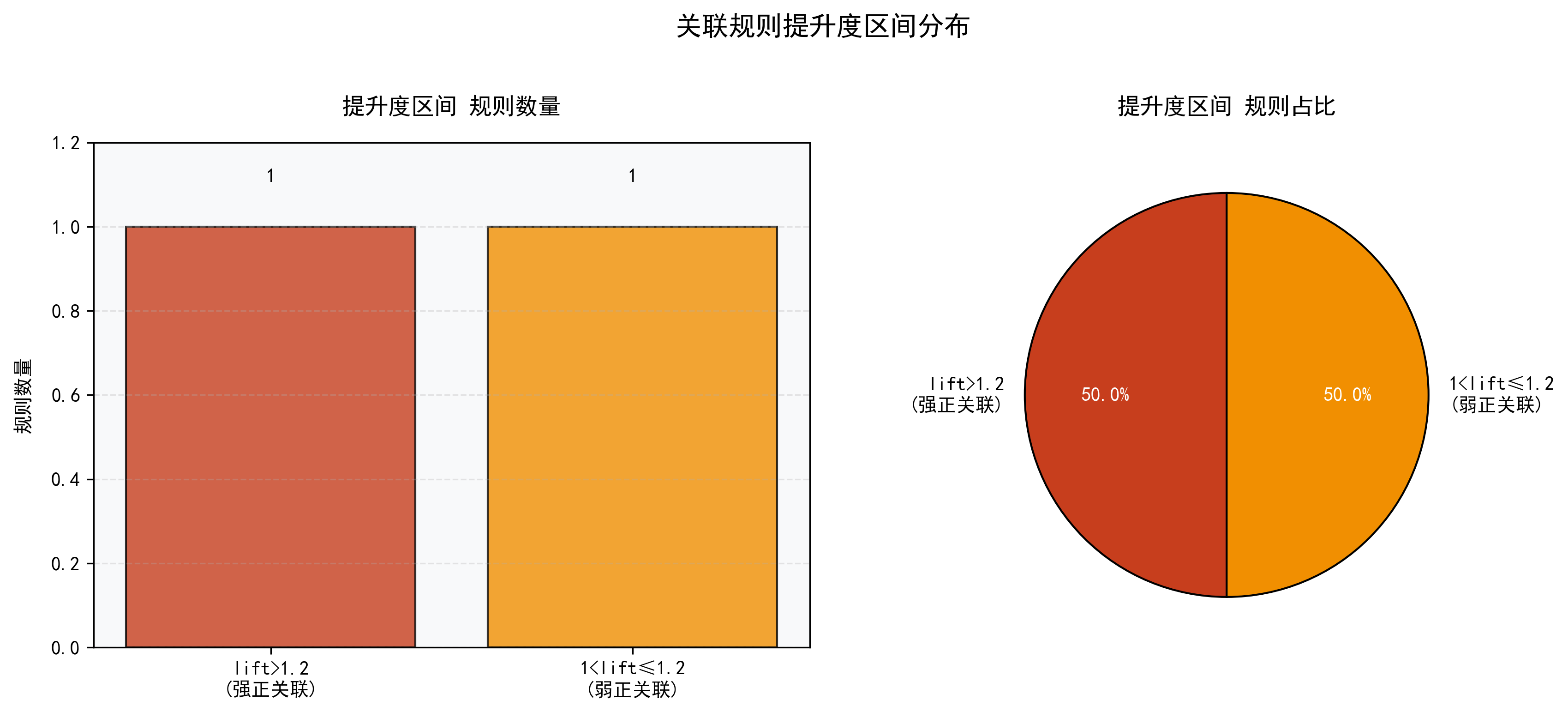
- 关联规则分析图:通过散点图、热力图和3D图多维度揭示规则的支持度、置信度和提升度关系。
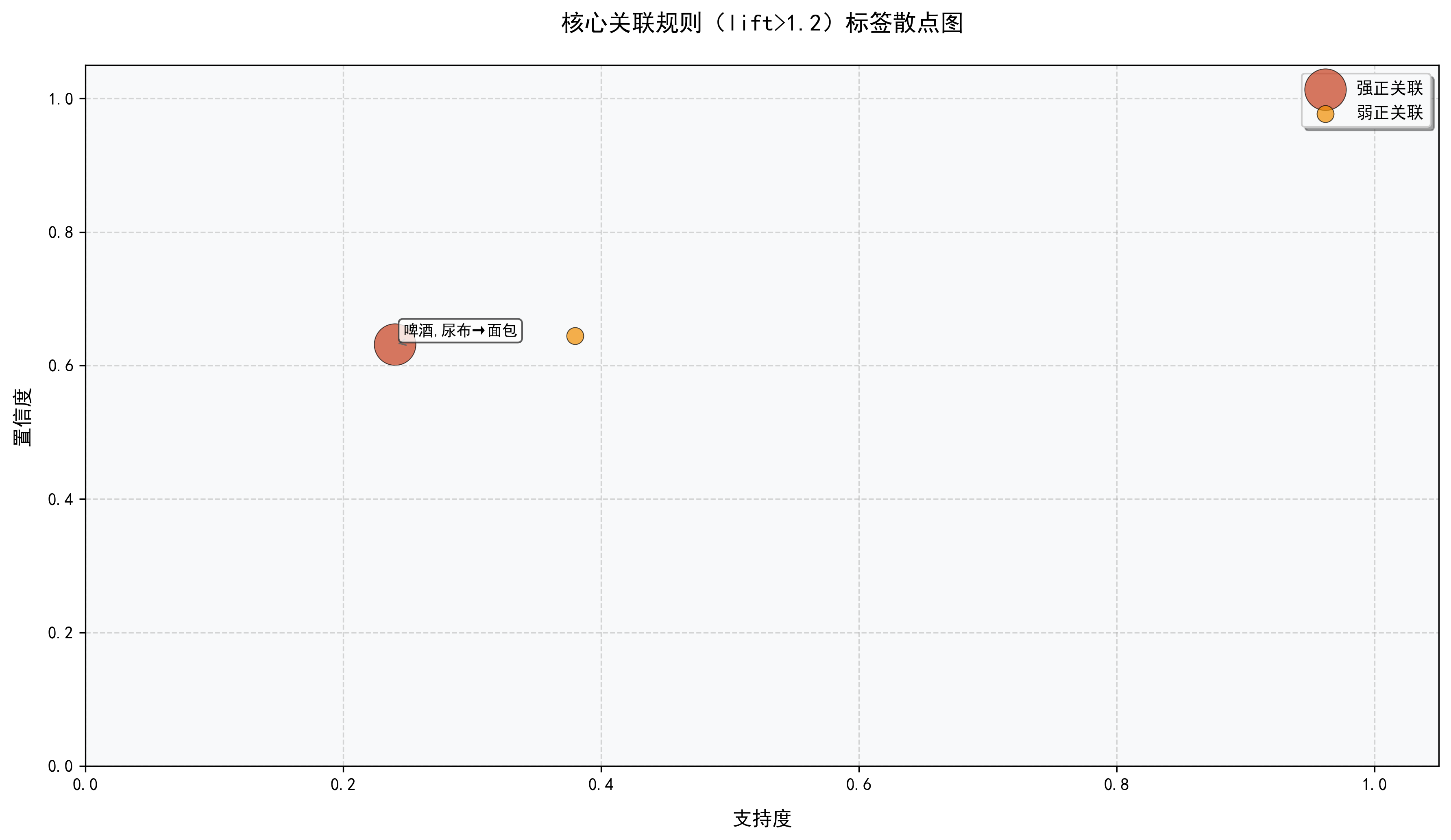
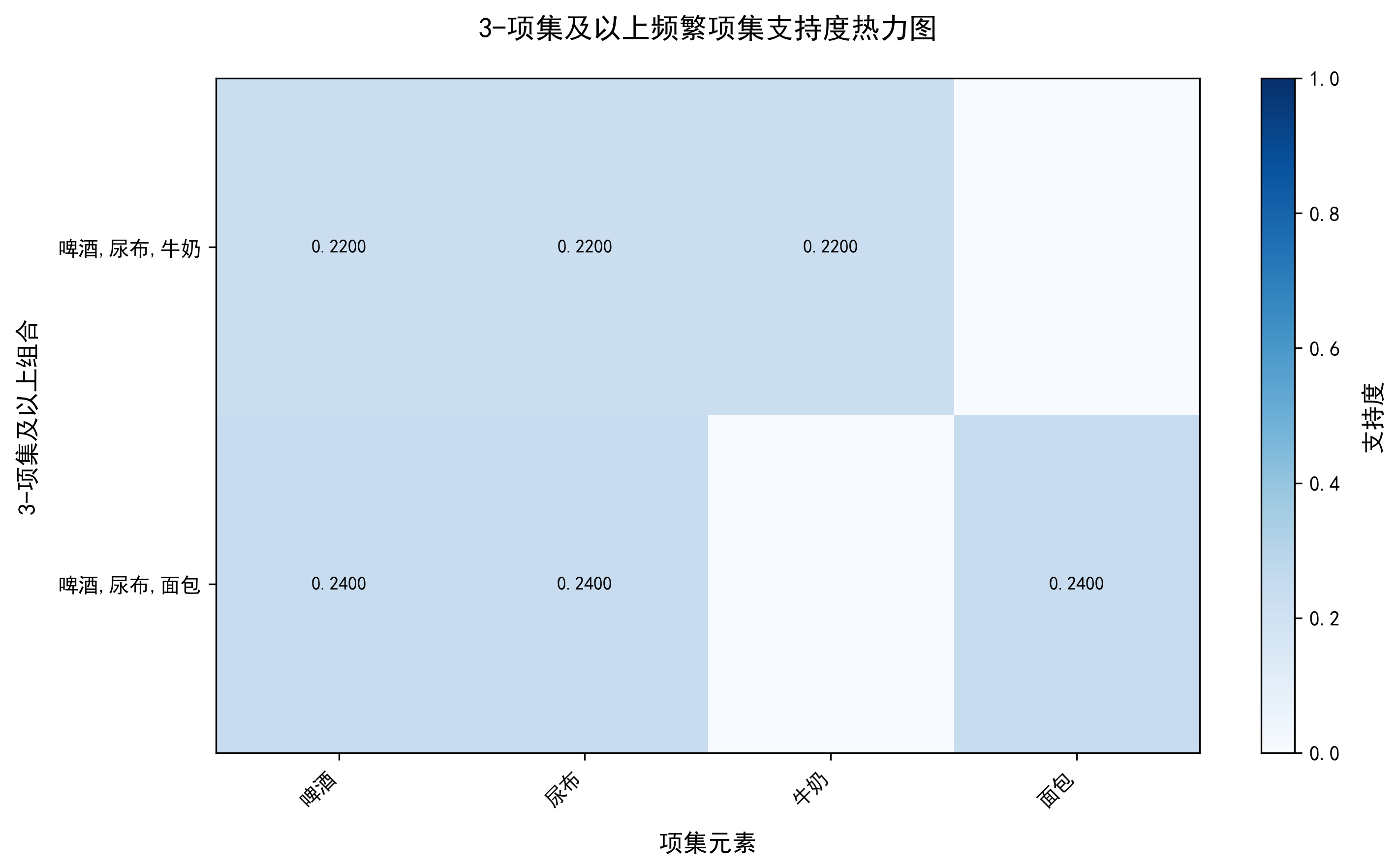
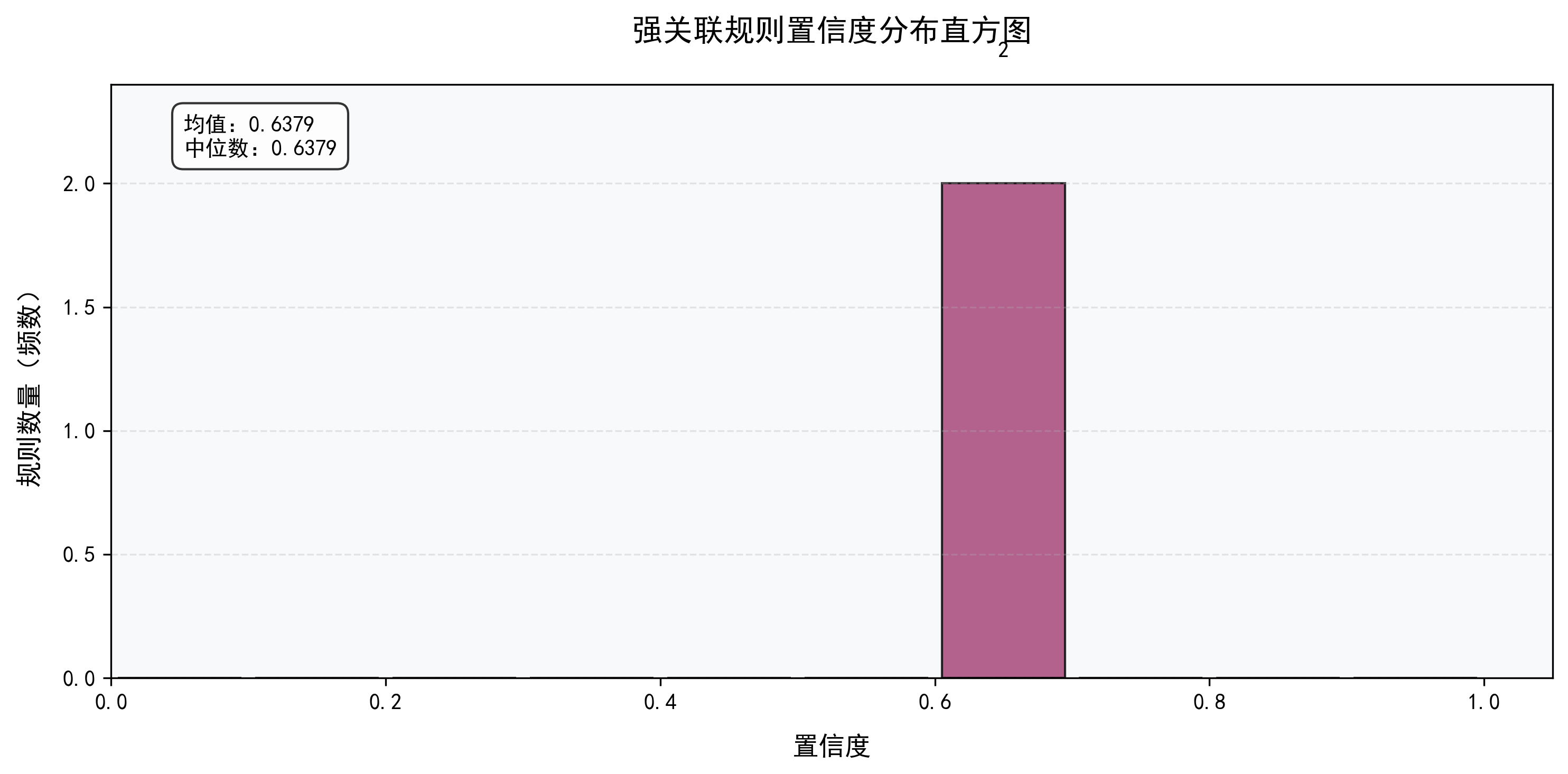
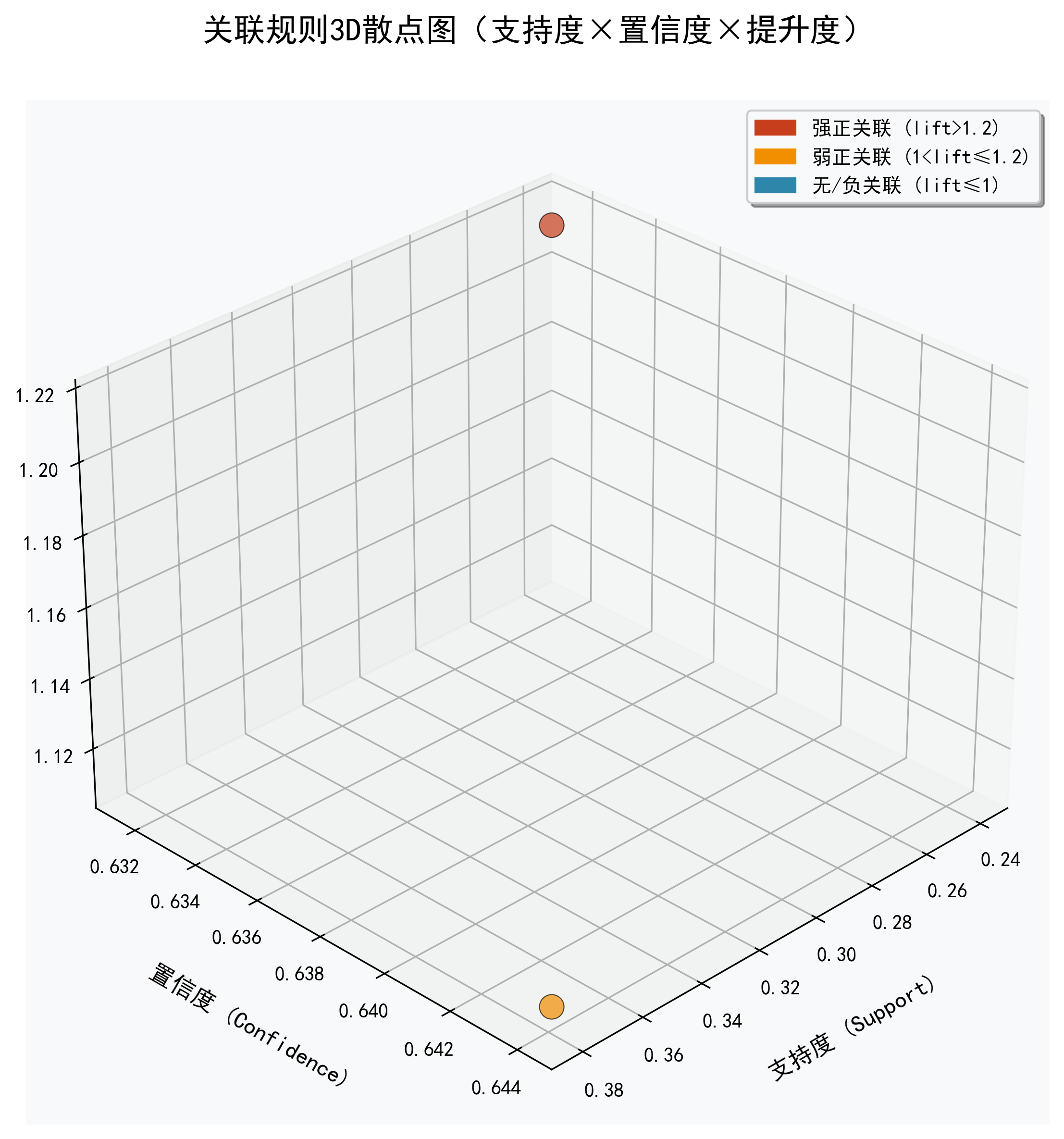
七、优劣审视与未来展望
尽管Apriori是奠基性的经典,但我们仍需客观看待其优缺点。
优点:
- ✅ 原理直观:基于集合论,易于理解和教学。
- ✅ 结果可靠:通过双重阈值保证规则的统计显著性。
- ✅ 适用性广:适用于任何形式的事务数据。
缺点与挑战:
- ⚠️ 性能瓶颈:多次扫描数据库,候选项集可能组合爆炸,I/O成本高。
- ⚠️ 内存消耗大:需要存储大量中间候选集。
- ⚠️ 参数敏感:min_sup和min_conf的设置需要经验,直接影响结果。
优化与演进:
正是为了克服这些缺点,后续诞生了许多更高效的算法:
- FP-Growth:采用FP-Tree数据结构,仅需两次数据库扫描,效率大幅提升,是当前最流行的替代方案之一。
- Eclat:采用垂直数据格式,利用集合交集计算支持度,特别适合稀疏数据集。
这些优化思想,对于使用Java、C++处理大规模数据集的工程师而言,具有重要的借鉴意义。[AFFILIATE_SLOT_2]
总结
Apriori算法作为关联规则挖掘的里程碑,其价值远不止于“啤酒与尿布”的故事。它系统性地定义了从数据中寻找频繁模式并推导可靠规则的标准流程,其核心的先验剪枝思想更是算法设计的典范。虽然在实际处理超大规模数据时,我们可能会转向FP-Growth等更高效的算法,但理解Apriori是深入数据挖掘领域的必经之路。通过本文从理论到Python实战的梳理,希望你能不仅掌握其用法,更能领会其思想,从而在面对复杂的关联分析问题时,能够选择并设计出最合适的解决方案。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号