
Linux IO知识闭环:从库的构建到进程内存,打通程序运行的底层逻辑
在掌握了Linux文件操作与存储原理后,要真正构建起完整的IO知识体系,还需要理解代码如何被组织复用,以及程序运行时数据如何与内存、磁盘交互。本文将作为Linux基础IO的收官指南,深入剖析静态库与动态库的构建、链接与加载机制,并揭开进程地址空间的神秘面纱,最后补充关键的内存与IO细节,帮助你形成从用户态到内核态的完整认知闭环。
一、代码复用的艺术:静态库与动态库深度解析
在C/C++、Go乃至Rust等系统编程语言中,库是代码复用和模块化开发的基石。理解它们的差异,是高效部署和优化程序性能的关键。简单来说,静态库在编译时被完整地“复制”到最终的可执行文件中,而动态库则在程序运行时才被加载到内存,供多个进程共享。
库的安装其实就是把库搞到系统的默认放这个的位置里去
库文件里面不能包含函数,因为库是被别人调用着来用的
1.1 静态库:独立与便携的代价
静态库(通常以.a为后缀)的构建就像制作一个代码“压缩包”。使用ar命令将多个目标文件(.o)归档而成。它的最大优点是独立性:生成的可执行文件不依赖外部库文件,部署简单。这在嵌入式或需要严格环境控制的场景中非常有用。然而,其缺点也显而易见:
- 体积膨胀:相同的库代码会在每个使用它的程序中重复存储。
- 更新困难:库代码更新后,所有依赖它的程序都必须重新编译链接。
下面是一个创建和使用静态库的典型命令流程:
静态库的话就是把源代码编译之后打包成文件(静态库的命名必须要有哈)–从而让别人获得不到源文件(通常把静态库和头文件搞在这个文件里面给)
静态库的话是给单个程序一份,互不干扰(所以搞成可执行程序之后,把之前静态库删了都没事–因为可执行程序里面有一份)
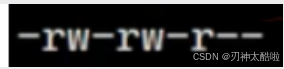
权限一般是这样的:
(没有可执行权限)
生成静态库: 表示存在就替换,不存在就创建
链接:假如长这样的:
则需要(也是这么高搞)
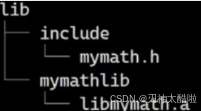
解释:因为头文件和库和不在目录的同一级或者系统默认存这些的位置,所以需要指定头文件和库的位置
:指定头文件的搜索目录。 :指定库文件的搜索目录
:指定要链接的库的名称。(这个不能缺少,而且除去才是库的名字)(一般库名字跟连在一起写,当然中间加个空格也行)
第三方库在使用的时候,必定要(无论是动态库还是静态库,无论放没放在系统默认位置)
可以同时链接多个库
默认是调用动态库,除非只有静态库或者
引申:在使用自定义头文件的时候,记得写路径(没在当前目录且同级的话)
其实也可以直接头文件写绝对路径就行了–但是可移植性差,一般不用
1.2 动态库:共享与灵活的智慧
动态库(共享库,以
.so为后缀)代表了另一种设计哲学。它只在程序运行时被加载到内存,并且同一份库代码可以在内存中被多个进程共享,极大地节省了内存和磁盘空间。系统库(如glibc)几乎都以动态库形式存在。这使得系统更新(如安全补丁)只需替换动态库文件,所有程序在下一次运行时即可生效,无需重新编译。就是把这个库同时给多个程序使用(属于共享的)
库名的格式:
动态库的权限一般是这样的:
(有执行权限–因为它需要独自被加载到内存里)生成动态库:
链接的话,跟上面的静态库是一样的
但是如果想要允许链接之后生成的可执行程序的话,必须先加载动态库,但操作系统不知道这个动态库在哪,现在只有编译器是知道的–所以目前加载器加载不了
引申:命令可以显示可执行文件或共享库所依赖的 动态链接库列表
使用方法:
关键概念:位置无关代码(fPIC)
构建动态库时,必须使用
-fPIC(Position Independent Code)选项编译源文件。这是因为动态库在加载到不同进程的地址空间时,其最终的加载地址是不确定的。PIC技术使得库中的指令不依赖绝对的物理内存地址,而是通过全局偏移表(GOT)等方式进行寻址,从而保证了库代码可以被加载到任意地址正常运行。这个位置无关码的意思:直接用偏移量对库中函数进行编址
让自己内部函数不采用绝对编址的方法去指向动态库里面的这个函数,而是只表示这个函数在库里面的偏移量就行了
这个设计的原因:动态库被加载到内存地址空间里面的位置是不固定的
动态库的加载:让系统找到你的库
编译时使用
-l选项链接动态库,只是告诉链接器库的名称。程序运行时,系统加载器(如ld-linux.so)需要知道去哪里找到这个.so文件。有几种常见方法:
- 使用
-Wl,-rpath指定运行时库路径(硬编码到可执行文件中)。- 将库路径添加到环境变量
LD_LIBRARY_PATH中。- 将库复制到系统默认的库搜索路径中,如
/usr/lib。- 修改
/etc/ld.so.conf配置文件并运行ldconfig。1.拷贝到系统默认的库路径 或者(一般云服务器都是前者才是)
–一般用的是第一种方法
2.在系统默认的库路径下建立软链接
3.将自己库所在的路径(不用写库名,而是上一级)添加到系统的环境变量里面
(这个环境变量里面存的就是动态库的搜索路径)
4.在里面建立自己的动态库路径的配置文件,然后再一下
问题: 为啥动态库需要被加载,但是静态库不用?
因为动态库是被程序共享的,只有一份,存在物理内存里面,程序通过共享区对应的页表去访问它的,所以需要被加载
静态库在链接时是被完整地拷贝到了可执行文件里面,可执行文件外部的那个静态库已经没用了
现代语言的选择:在Go语言中,默认生成的是完全静态链接的可执行文件,极大简化了部署。而在Python或Java的JNI场景中,则经常需要与C/C++编写的动态库交互。TypeScript/Node.js的本地模块(如
[AFFILIATE_SLOT_1]node-gyp)也涉及类似的动态库编译和链接过程。二、进程地址空间:程序运行的沙盒世界
理解了代码如何组织,我们再来看看程序运行时的内存舞台——进程地址空间。这不是真实的物理内存,而是操作系统为每个进程虚拟出来的一个连续、私有的内存视图。它就像一个沙盒,让每个进程都“自以为”独占了整个内存资源,由操作系统和MMU(内存管理单元)负责虚拟地址到物理地址的映射。
程序在没有被加载到内存前,其内部也是有地址的,采用的是平坦模式(0-4GB),里面的地址从0开始这样(这个地址叫做虚拟地址–但是一般在这里喜欢叫成逻辑地址)
程序加载后:
会先把程序的入口地址(是虚拟地址)给CPU,然后发生缺页中断,就会把对应的数据加载到内存里,更新页表,把物理地址和虚拟地址连起来–这样就有了物理地址了
引申:CPU内读取到的指令,内部可能有数据,也可能有虚拟地址(虚拟地址的话交给去用页表去查)
这种设计带来了巨大优势:
- 安全性:进程无法直接访问其他进程或内核的内存。
- 简化编程:程序员使用统一的虚拟地址,无需关心物理内存的碎片化分配。
- 内存超售:通过交换技术(Swap),可以让进程使用的虚拟内存总和超过实际物理内存。
三、关键细节补充:避开开发中的“坑”
要真正吃透IO,还有一些容易忽略但至关重要的细节。
3.1 内存管理底层:页与Slab
操作系统以“页”(通常4KB)为单位管理物理内存。频繁申请小内存(如C++的
new、Go的make)如果都直接向系统申请页,会产生大量碎片。因此,Linux内核使用Slab分配器等机制来高效管理内核对象(如inode、task_struct)的缓存和分配,这类似于用户态的malloc实现(如ptmalloc, jemalloc)。物理内存和磁盘交换数据都是以4KB为单位的,物理内存里面的叫页框,磁盘里面的叫页帧
以4KB为单位的好处:
1.减少IO次数,也就是减少访问外设的次数–硬件层面
2.因为局部性原理,所以有预加载机制–软件层面
3.2 IO数据拷贝流程
一次简单的
write调用,数据并非直接飞入磁盘。路径是:用户态缓冲区 -> 内核页缓存 -> 磁盘驱动队列 -> 持久化存储。内核的页缓存(Page Cache)是提升IO性能的关键,它用内存缓存磁盘数据,减少直接磁盘访问。如果需要存储的数据远小于4KB的话,4KB还可以被细分–比如Linux用的是
局部性原理:在访问数据的时候,有极大概率周围的数据之后也会被用到
⚠️ 重要提醒:数据在到达磁盘驱动队列之前都位于易失性内存中。如果此时断电,数据就会丢失。这就是为什么数据库、消息队列等关键服务需要配置同步写入(O_SYNC)或依赖事务日志来保证持久性。
操作系统管理内存的方法:
操作系统是可以看到内存的物理地址的,对这个物理内存也是采用的先描述再组织
把每个页框的信息放到一个里面,然后搞一个数组去存,就把对内存的管理变成了对数组的管理了
所以访问内存的过程,就是去找这个4KB对应的结构体,然后就能在系统中找到对应的物理页框
所有申请内存的动作,其实都是在访问存的数组
基数树,基树或者叫字典树的概念:
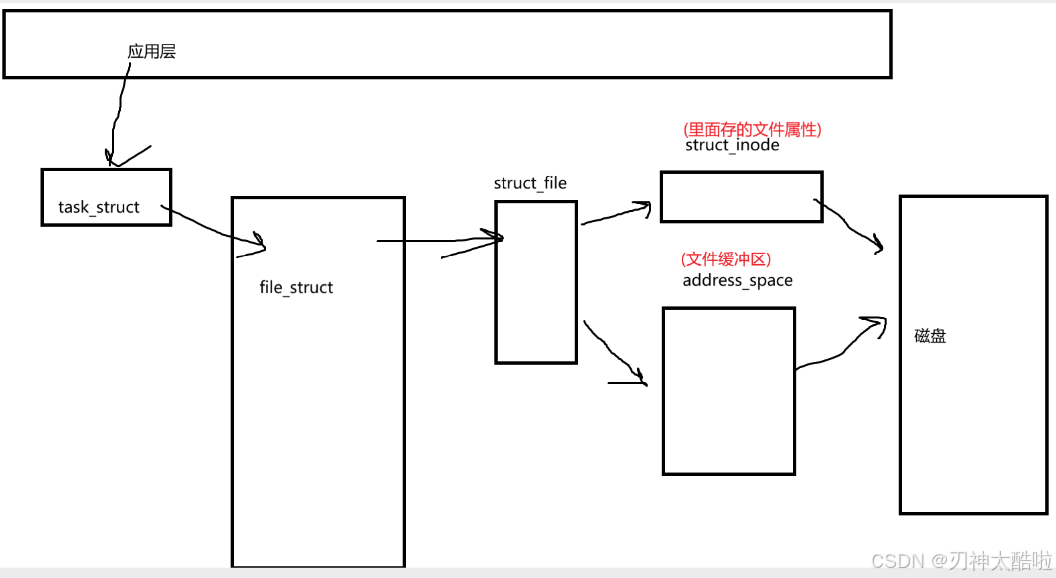
Linux中,我们的每一个进程,打开的每一个文件都有自己的和文件页缓冲区
里面还有其他的文件属性和其他东西哈,比如:
所以:从外设写到磁盘要三次拷贝
eg:用C语言写的话,C语言缓冲区拷贝给内核的缓冲区,内核缓冲区再拷贝给文件缓存区,文件缓存区再给磁盘
引申:到磁盘则只用两次拷贝
3.3 语言相关的未定义行为
在C/C++中,函数参数的求值顺序是未定义的。例如
printf("%d %d\n", i++, i++)的输出结果因编译器而异。而在Java、Python、Go等语言中,函数参数的求值顺序通常是从左到右明确定义的。了解这些差异,能帮助你在跨语言开发或进行性能敏感编码时避免诡异bug。[AFFILIATE_SLOT_2]函数参数的求值顺序是未定义的行为–要看编译器
四、实战巩固:精选作业与思考
理论结合实践才能融会贯通。以下作业将帮助你巩固本文的核心概念:
Linux下两个进程可以同时打开同一个文件,这时如下描述错误的是:(D) A.两个进程中分别产生生成两个独立的fd B.两个进程可以任意对文件进行读写操作,操作系统并不保证写的原子性 C.进程可以通过系统调用对文件加锁,从而实现对文件内容的保护 D.任何一个进程删除该文件时,另外一个进程会立即出现读写失败 //若进程已经打开文件,文件被删除时,并不会影响进程的操作,因为进程已经具备文件的描述信息 E.两个进程可以分别读取文件的不同部分而不会相互影响 F.一个进程对文件长度和内容的修改另外一个进程可以立即感知 //文件内容的修改是直接反馈至磁盘文件系统中的 //因此当文件内容被修改,其他进程因为也是针对磁盘数据的操作,因此可以立即感知到以下描述正确的是(B) --这个选项要知道 A.文件描述符和文件流指针没有任何关系 B.文件流指针结构中封装了文件描述符//文件流指针指的是eg:C语言封装的结构体FILE C.通过open打开文件返回的FILE *fp可以直接使用read读取数据 //open返回的是文件描述符 D.通过open打开文件返回的FILE *fp可以直接使用fread读取数据以下描述正确的是 [多选](ABD) A.程序中打开文件所返回的文件描述符, 本质上在PCB中是文件描述符表的下标 B.多个文件描述符可以通过dup2函数进行重定向后操作同一个文件 C.在进程中多次打开同一个文件返回的文件描述符是一致的 //连续open同一个文件,返回的文件描述符是不一样的 D.文件流指针就是struct _IO_FILE结构体,该结构体当中的int _fileno 保存的文件描述符, 是一对一的关系bash中,需要将脚本demo.sh的标准输出和标准错误输出重定向至文件demo.log,以下哪些用法是正确的 [多选] (ABCD) A.bash demo.sh &>demo.log B.bash demo.sh >&demo.log //这俩都是把12同时重定向到demo.log里面 C.bash demo.sh >demo.log 2>&1 D.bash demo.sh 2>demo.log 1>demo.log下面关于Linux文件系统的inode描述错误的是:(A) A.inode和文件名是一一对应的 B.inode描述了文件大小和指向数据块的指针 C.通过inode可获得文件占用的块数 D.通过inode可实现文件的逻辑结构和物理结构的转换Linux中包括两种链接:硬链接(Hard Link)和软连接(Soft Link),下列说法正确的是(A) A.软连接可以跨文件系统进行连接,硬链接不可以 //因为软连接里面存的是目标文件的路径 B.当删除原文件的时候软连接文件仍然存在,且指向的内容不变 C.硬链接被删除,磁盘上的数据文件会同时被删除 D.硬链接会重新建立一个inode,软链接不会使用In命令将生成了一个指向文件old的符号链接new 如果你将文件old删除,是否还能够访问文件中的数据?(A) A.不可能再访问 B.仍然可以访问 C.能否访问取决于文件的所有者 D.能否访问取决于文件的权限 //因为这里说了是符号链接,所以是软链接关于静态库与动态库的区别,以下说法错误的是(A) A.加载动态库的程序运行速度相对较快 B.静态库会被添加为程序的一部分进行使用 C.动态库可用节省内存和磁盘空间 D.静态库重新编译,需要将应用程序重新编译下面哪一个不是动态链接库的优点?(B) A.共享 B.装载速度快 C.开发模式好 D.减少页面交换总结
至此,我们完成了Linux基础IO的完整拼图:从用户层的fopen/write,到系统调用陷入内核;从内核的VFS、页缓存管理,到文件系统与磁盘的交互;再到本文的代码复用(库)、程序内存基石(地址空间)及关键细节。这条链路揭示了程序如何通过层层抽象,最终完成数据持久化的本质。理解它,不仅让你能更高效地使用C/C++、Go等语言进行系统编程,也为后续学习并发编程、网络IO和高性能服务开发打下了坚实的地基。mainlibxxx.alib .aar -rc libmymath.a add.o sub.o-rcgcc main.c -I ./lib/include/ -L ./lib/mymathlib/ -lmymathg++main.c-I-L-llib 和.a-l-lgccgcc-staticlibxxx.solib和.so必须要有
gcc -fPIC -c mylog.c //生成mylog.o gcc -shared -o liblylog.so mylog.o //生成动态库liblylog.so 这里的-fPIC是产生位置无关码 -shared是生成共享库格式lddldd 文件名/lib64/usr/lib64/LD_LIBRARY_PATH/etc/ld.so.conf.dldconfigeg: 先在这个路径底下创建 xxxxx.conf 然后在里面写动态库所在的路径就行了(不是写到库名哈) --eg:用vim去写MMUslab分配器struct pagestruct pagepage有一个结构体 eg: struct slot { int level; void* slot[3]; } slot里面继续存slot结构体这样,到最后里面才存数据inode当然,struct_filefile_operatorswriteeg:printf("%d,%d",div(10,0),myerrno); 不知道是先执行的div还是先搞得myerrno 这个跟,表达式区分哈

 浙公网安备 33010602011771号
浙公网安备 33010602011771号