
从零到一:使用Scikit-learn与KNN算法实现鸢尾花分类实战指南
在机器学习的浩瀚星空中,总有一些算法因其简洁直观而成为入门者的最佳引路人。K近邻(KNN)算法便是其中之一,它没有复杂的数学推导,其核心思想——“物以类聚,人以群分”——却异常强大。本文将带你使用Python生态中最为流行的机器学习库Scikit-learn,手把手完成一个经典的机器学习实战项目:鸢尾花分类。无论你是刚接触Python的新手,还是从其他语言(如JavaScript、Java或C++)转战数据科学领域的开发者,这篇详尽的指南都将为你铺平道路。
一、Scikit-learn:Python机器学习生态的基石
在深入算法之前,让我们先认识一下今天的核心工具——Scikit-learn。对于任何有志于数据科学和机器学习的Python开发者而言,它几乎是不可或缺的“瑞士军刀”。与专注于深度学习的TensorFlow或PyTorch不同,Scikit-learn主要服务于传统的机器学习领域,提供了从数据预处理到模型评估的一站式解决方案。
它的强大之处在于其一致性、高效性和易用性。无论你处理的是分类、回归还是聚类问题,其API设计都遵循着相似的逻辑(如fit, predict, transform),极大地降低了学习成本。这使得开发者可以快速将想法转化为可运行的代码原型,其地位类似于Web开发中的React或Vue.js,是构建更复杂应用的坚实基础。
安装Scikit-learn非常简单,如果你已经配置好了Python环境,只需一行命令:
pip install scikit-learn对于使用Anaconda科学计算发行版的用户,也可以通过conda进行安装:
conda install scikit-learn安装完成后,你就可以导入这个强大的库,开始你的机器学习之旅了。值得一提的是,Scikit-learn与NumPy、Pandas、Matplotlib等库的无缝集成,构成了Python数据科学生态的核心,其易用性甚至让许多从Java或C++转向数据领域的工程师感到惊喜。
二、深入浅出:理解KNN算法的核心思想
K近邻(K-Nearest Neighbors)是一种惰性学习(Lazy Learning)算法,也是最直观的监督学习算法之一。它既可用于分类(预测离散标签),也可用于回归(预测连续值)。其核心假设非常简单:在特征空间中,彼此靠近的样本很可能属于同一类别或具有相似的目标值。
KNN分类的工作原理可以概括为以下四步:
- 计算距离:对于待预测的新样本,计算它与训练集中每一个样本的距离。
- 寻找邻居:根据距离排序,选出距离最近的K个训练样本(即“K个最近邻”)。
- 统计投票:查看这K个邻居各自属于哪个类别,并进行统计。
- 决策输出:将出现次数最多的类别作为新样本的预测类别。
举个简单的例子,假设我们设置K=5,一个新样本的5个最近邻的类别分别是:[A, A, B, A, C]
若出现平票(如 K=4,结果为 [A, A, B, B]),sklearn 默认选择索引最小的类别,所以最好将K设置为奇数。
KNN回归的思路类似,只不过最后一步不是投票,而是取K个邻居目标值的平均值(或根据距离加权平均)作为预测值。公式如下:
算术平均: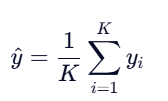
距离加权平均: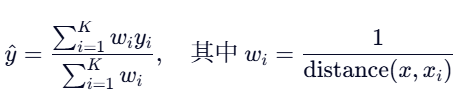
例如,K=3时,三个邻居的目标值为[10.2, 9.8, 10.5](10.2+9.8+10.5)/3 = 10.17。
算法的关键在于“距离”的定义。最常用的是欧式距离(即直线距离),其公式为:
scikit-learn 默认使用欧式距离。
另一种常见距离是曼哈顿距离,适用于类似城市网格的路径,计算公式为: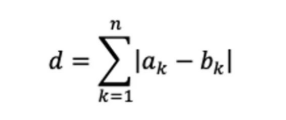 。下图清晰地展示了两种距离的区别:
。下图清晰地展示了两种距离的区别: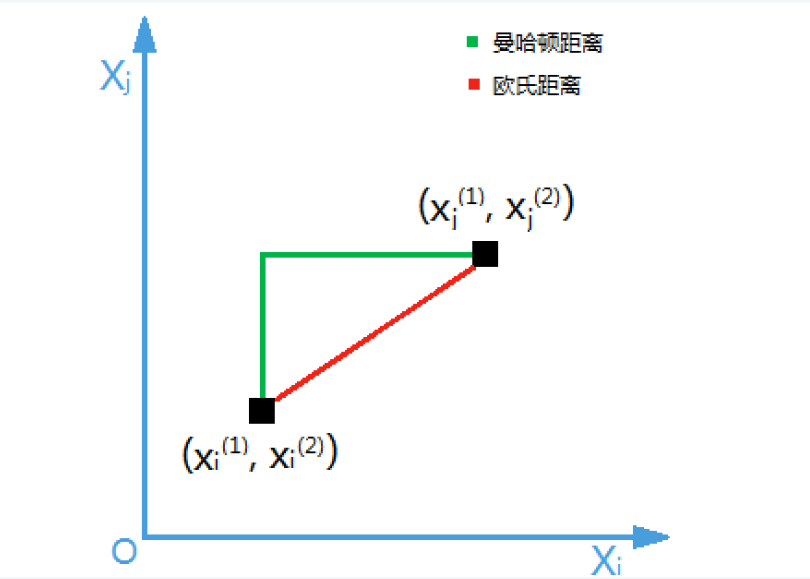 。在实际应用中,选择哪种距离度量需要根据数据特性和业务场景来决定。
。在实际应用中,选择哪种距离度量需要根据数据特性和业务场景来决定。
三、实战准备:认识鸢尾花数据集与数据预处理
鸢尾花(Iris)数据集被誉为机器学习界的“Hello World”。它包含了150个样本,分属三种不同的鸢尾花:山鸢尾(Setosa)、变色鸢尾(Versicolor)和维吉尼亚鸢尾(Virginica),每种各50个样本。每个样本有4个特征:花萼长度、花萼宽度、花瓣长度和花瓣宽度。我们的任务就是根据这4个特征来预测花的种类。
首先,我们使用Scikit-learn内置的功能加载数据,这比从外部文件读取方便得多:
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data # 特征矩阵 (150, 4)
y = iris.target # 标签 (150,),0/1/2 代表三种花这里,sklearndatasetsXy
接下来是机器学习中的关键一步:划分训练集和测试集。我们不能用训练模型的数据来评估模型,那会导致过于乐观的假象。我们使用train_test_split
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42, stratify=y
)参数random_state=42stratify=y
在训练KNN模型前,还有一个至关重要的步骤:特征标准化。由于KNN基于距离计算,如果某个特征(如花瓣长度)的数值范围(例如0-10)远大于另一个特征(如花萼宽度0-1),那么距离计算将完全被大范围的特征主导。标准化可以将所有特征缩放到同一尺度。我们使用Z-Score标准化,使每个特征的均值为0,标准差为1。
什么是Z-Score 标准化?
Z-Score 标准化(是一种常用的数据预处理方法,其核心目标是将原始数据转换为均值为 0、标准差为 1 的分布形式,从而消除不同特征之间的量纲(单位)和数值尺度差异。
标准化的正确流程是:只在训练集上计算均值和标准差,然后用这些参数去转换训练集和测试集。绝对不能用整个数据集(包含测试集)来计算参数,否则就造成了“数据泄露”。具体操作如下:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)| 步骤 | 代码 | 作用 |
|---|---|---|
| 1. 创建标准化器 | 初始化 | |
| 2. 学习训练集统计量并转换 | fit + transform | |
| 3. 用训练集参数转换测试集 | 仅 transform |
四、模型构建、训练与评估:见证KNN的力量
数据准备就绪后,就可以创建我们的KNN分类器了。Scikit-learn中对应的类是KNeighborsClassifier
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5) # 创建KNN模型实例
knn.fit(X_train_scaled, y_train) # 训练模型(拟合)这里我们创建了一个KNN分类器对象,并指定了n_neighbors=5,即寻找5个最近邻进行投票。K值的选择是一个超参数,通常通过交叉验证来确定。选择奇数的K值可以避免平票情况。
训练模型非常简单,只需调用fit方法,传入标准化后的训练特征X_train_scaledy_train.fit().predict()
模型训练好后,我们迫切想知道它的表现如何。评估模型在测试集上的性能有两种常用方式:
方法一:使用模型的score方法(最简洁)
from sklearn.metrics import accuracy_score
score = knn.score(X_train_scaled, y_train)
print("自测准确率:", score)
y_pred = knn.predict(X_test_scaled)
accuracy = accuracy_score(y_test, y_pred)
print("预测准确率:", accuracy)knn.score(X, y_true)y_true
方法二:手动调用predict和评估函数(更灵活,可以查看预测细节)
y_pred = self.predict(X)
return accuracy_score(y_true, y_pred)首先用predict方法得到测试集的预测标签y_predaccuracy_score()
五、完整代码、结果分析与进阶思考
让我们将上述所有步骤整合,得到完整的可执行代码:
# 导入所需库
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# 1. 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data # 特征矩阵 (150, 4)
y = iris.target # 标签 (150,),0/1/2 代表三种花
# 2. 划分训练集和测试集(7:3)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42, stratify=y
)
# 3. 特征标准化(KNN 对量纲敏感!)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test) # 注意:只 transform 测试集!
# 4. 创建并训练 KNN 模型(k=5)
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train_scaled, y_train)
# 5. 自测与预测
y_self = knn.predict(X_train_scaled)
score = knn.score(X_train_scaled, y_self)
print("自测准确率:", score)
y_pred = knn.predict(X_test_scaled)
accuracy = accuracy_score(y_test, y_pred)
print("预测准确率:", accuracy)
print("测试集准确率:", accuracy)
# 输出示例:测试集准确率: 1.0 (几乎完美!)运行这段代码,你可能会得到类似如下的输出: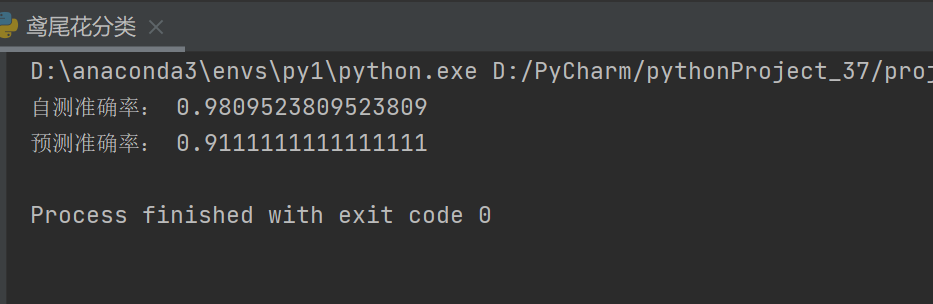 。一个准确率高达95%以上的模型,对于入门实战来说是非常不错的成果!这表明KNN算法能够很好地根据鸢尾花的四个形态特征对其进行分类。
。一个准确率高达95%以上的模型,对于入门实战来说是非常不错的成果!这表明KNN算法能够很好地根据鸢尾花的四个形态特征对其进行分类。
实践建议与注意事项:
- K值选择:K值太小(如K=1)模型容易过拟合,对噪声敏感;K值太大则可能欠拟合,忽略数据局部特征。可以通过网格搜索(GridSearchCV)寻找最优K值。
- 计算效率:KNN在预测时需要计算与所有训练样本的距离,当训练集很大时非常耗时。可以考虑使用KD树、球树等数据结构加速,或使用近似最近邻算法。
- 特征重要性:KNN本身不提供特征重要性度量。如果你需要知道哪些特征对分类贡献大,可以结合其他方法(如随机森林)或进行特征选择实验。
- 与其它语言对比:如果你熟悉JavaScript,可以尝试类似的库(如ml.js);Java开发者则有Weka、DL4J等选择。但Python的Scikit-learn以其极佳的文档和社区支持,在快速原型开发上优势明显。对于追求性能的底层实现,C++是不错的选择,而TypeScript能为大型JavaScript机器学习项目提供更好的类型安全。
⚠️ 局限性:KNN对高维数据效果可能变差(“维数灾难”),且对不平衡数据集敏感。它也无法处理缺失值,需要提前进行数据清洗。
通过这个从数据加载、预处理、模型训练到评估的完整流程,你不仅掌握了KNN算法在Scikit-learn中的应用,更实践了机器学习项目的标准工作流。这个流程是通用的,当你未来面对更复杂的算法(如决策树、SVM、神经网络)或更大的数据集时,其中的思想——数据划分、特征工程、模型训练与评估——依然适用。鸢尾花分类只是起点,希望你能带着从这里学到的知识,去探索更广阔的机器学习世界。
scaler = StandardScaler()X_train_scaled = scaler.fit_transform(X_train)X_test_scaled = scaler.transform(X_test)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号