
从RocketMQ到数据库:消息中间件核心机制深度解析与实战指南
在分布式系统架构中,消息中间件扮演着异步解耦、流量削峰的关键角色。RocketMQ作为一款高性能、高可用的开源消息队列,其设计理念与核心机制是每一位后端开发者必须掌握的知识。本文将深入剖析RocketMQ在消息可靠性、顺序性、幂等性及积压处理等方面的核心原理,并结合数据库(如MySQL、PostgreSQL、Redis)的实践,为你构建一套完整的分布式消息处理知识体系。
一、构建坚不可摧的消息防丢失体系
消息丢失是消息中间件面临的首要挑战。一条消息从生产到消费,需要穿越生产者、网络、Broker服务器、消费者等多个环节,每个环节都存在丢失风险。理解并防范这些风险,是保障业务数据一致性的基石。
消息丢失的核心风险环节如下图所示,其中跨网络传输和Broker端的异步刷盘是丢失的高发区:
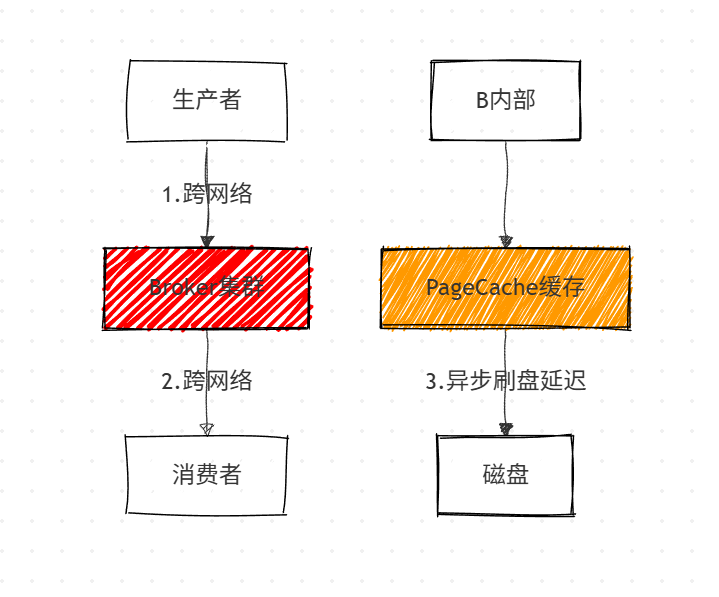
1. 生产者端:发送确认与事务消息
生产者是消息生命周期的起点。RocketMQ提供了同步发送、异步发送和单向发送三种模式。对于关键业务消息,务必使用同步发送并配合重试机制,以确保发送结果可知。下表对比了不同发送方式的可靠性:
| 发送方式 | 特点 | 代码示例 |
|---|---|---|
| 单向发送 | 效率高,可能丢消息 | |
| 同步发送 | 安全可靠,效率低 | |
| 异步发送 | 安全与效率平衡 |
对于涉及本地数据库操作(如MySQL订单表更新)的分布式事务场景,RocketMQ的事务消息机制是绝佳选择。其核心是一个两阶段提交(2PC)的变种:先发送一个“半消息”到Broker,待本地事务(如向PostgreSQL写入数据)执行成功后,再确认提交;若失败则回滚。Broker还会定期回查生产者以确认未决事务的状态,流程如下:
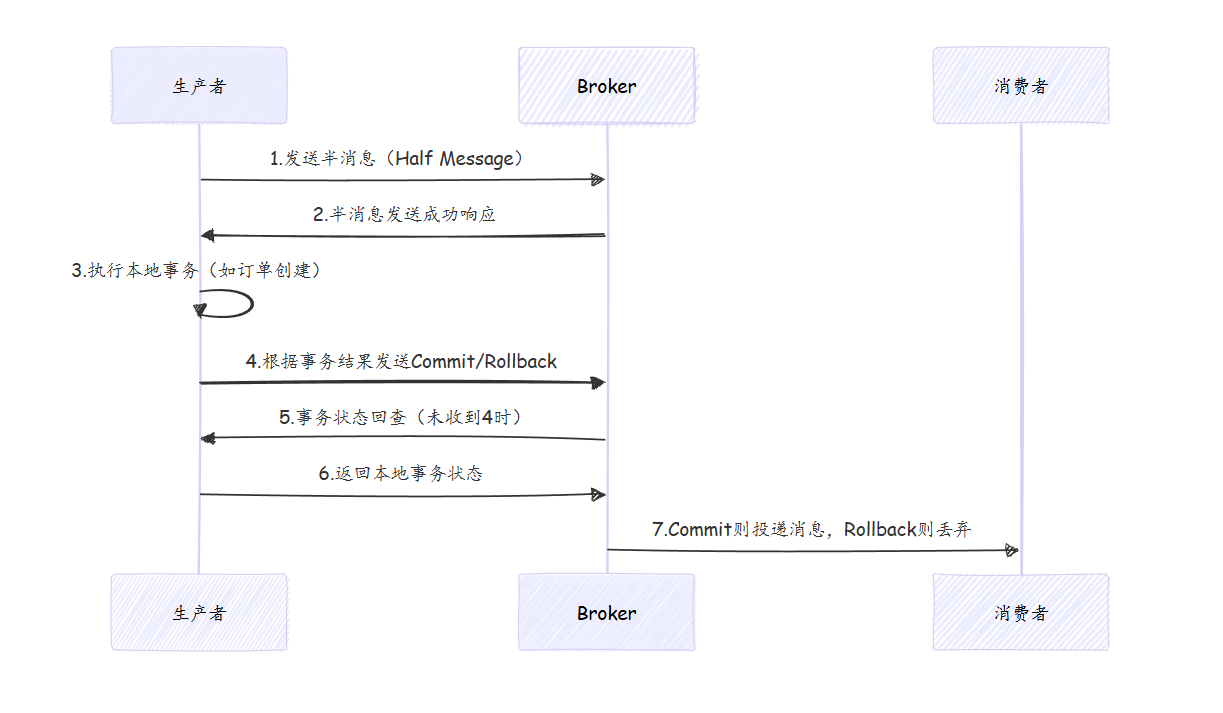
2. Broker端:持久化与高可用
Broker是消息的存储中心,其可靠性配置直接决定消息的生存能力。
- 刷盘机制:分为同步刷盘(SYNC_FLUSH)和异步刷盘(ASYNC_FLUSH)。同步刷盘在消息写入内存后立即调用fsync强制落盘,保证断电不丢,但IO压力大。生产环境通常采用异步刷盘并配合主从复制来平衡性能与可靠性。核心配置示例如下:
flushDiskType=SYNC_FLUSH- 主从同步机制:这是RocketMQ与Kafka在数据安全设计上的一个显著区别。RocketMQ采用主从异步/同步复制,当Master宕机后,Slave可以提供读服务,但不会自动切换为新的Master(除非使用DLedger模式)。原Master恢复后,会继续同步宕机期间未同步的数据,从而避免数据丢失。相比之下,Kafka在Leader崩溃后选举新Leader,可能会丢弃未完全同步到ISR副本的数据。对比如下:
| 集群类型 | 同步方式 | 数据安全性 | 切换逻辑 |
|---|---|---|---|
| 普通集群 | 同步 Master(SYNC_MASTER)/ 异步 Master(ASYNC_MASTER) | 高(SYNC_MASTER) | Master 挂了不自动切换 |
| DLedger 集群 | Raft 协议多数派确认 | 极高 | 自动选举 Leader,数据一致性优先 |
3. 消费者端:确认机制是最后防线
消费者的基本原则是:“先消费,后确认”。只有在业务逻辑处理完成(例如,已将消息内容成功写入MongoDB或更新了Redis缓存)后,才向Broker返回ACK。如果处理前就确认,一旦消费进程崩溃,消息将永久丢失。常见的风险是在异步处理(如开线程池)时,主线程过早返回了成功状态。以下代码展示了错误示例:
// 错误示例(可能丢失消息)
consumer.registerMessageListener((msgs, context) -> {
new Thread(() -> {
// 异步处理业务,可能未执行完就返回成功
}).start();
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
});
// 正确示例(同步处理)
consumer.registerMessageListener((msgs, context) -> {
// 同步处理业务逻辑
processBusiness(msgs);
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
});实践建议:对于耗时操作,应在异步任务完成后再提交ACK。RocketMQ通过消费位点(Offset)管理进度,未确认的消息会被重新投递。
4. 极端情况与零丢失权衡
即使做好了上述所有防护,如果整个MQ集群不可用呢?此时需要降级方案:生产者在发送失败时,将消息持久化到本地文件或Redis等缓存中,并启动一个后台线程定期重试。这是一种最终一致性的保障。
追求“零丢失”是有代价的,需要在性能、复杂度和成本之间做出权衡:
| 环节 | 方案 | 代价 |
|---|---|---|
| 生产者 | 同步发送 + 重试 | 降低吞吐 |
| Broker | 同步刷盘 + DLedger 集群 | IO / 网络负担增加 |
| 消费者 | 同步处理 + 确认 | 无法异步提升效率 |
| 集群故障 | 降级缓存 | 增加存储成本 |
二、消息顺序性:全局与局部的艺术
并非所有业务都需要严格的消息顺序。RocketMQ的设计哲学是保障局部顺序,即同一业务标识(如同一订单ID、同一用户ID)的消息有序,这满足了99%的实际场景(如订单的创建-支付-发货)。而强制整个Topic全局有序(只设置一个Queue)会带来严重的性能瓶颈,应尽量避免。
实现局部有序需要生产者和消费者协同工作:
- 生产者:通过自定义的分区选择器,将具有相同业务标识的消息发送到同一个固定的MessageQueue中。例如,使用 `订单ID % Queue数量` 的算法。
- 消费者:为每个MessageQueue分配独立的消费线程,在一个队列内部串行消费。多个队列之间可以并行,以此提升吞吐量。
其核心机制如下图所示:
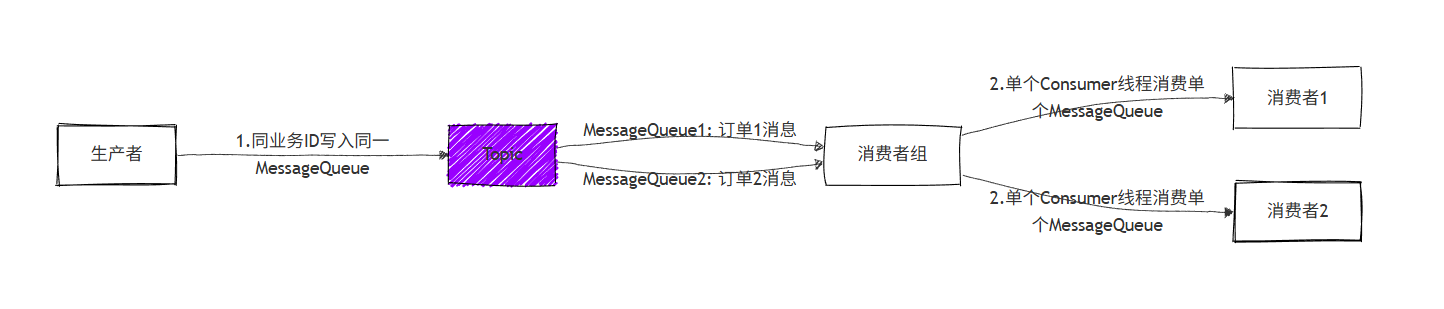
不同消息中间件对顺序性的支持方式不同:
| MQ 产品 | 顺序性保障方式 | 特点 |
|---|---|---|
| RocketMQ | 分区绑定 + 单线程消费 | 支持局部有序,配置灵活 |
| Kafka | 单 Partition 单线程消费 | 天生支持局部有序 |
| RabbitMQ | 单 Queue 对应单 Consumer | 经典队列需手动保证绑定关系 |
三、消息幂等性:应对“至少一次”交付的必杀技
由于网络重传、消费者重启等原因,消息可能会被重复投递(“至少一次”语义)。幂等性意味着多次处理同一消息产生的结果应与处理一次相同,例如不会因为消息重复而创建两个订单或扣款两次。
1. 生产者端的去重努力
- RocketMQ:每条消息会自动生成一个全局唯一的 `msgId`(发送时生成)和可选的 `uniqKey`。Broker可基于此进行一定程度的去重,但主要依赖消费者。
- Kafka:自0.11版本起支持生产者幂等性。它为每个生产者实例分配一个唯一PID,并为每个
2. 消费者端:业务幂等才是根本
生产者端的努力无法覆盖所有场景(如生产者重启导致PID变化),因此消费者必须实现业务逻辑的幂等。
- 去重依据(按优先级):
- 业务唯一标识(推荐):如订单ID、支付流水号。可以在发送消息时通过 `message.setKeys("orderId")` 设置。
- MQ提供的消息ID(`msgId`或`offsetMsgId`),但在批量消息或事务消息场景下可能不可靠。
- 实现方式:最常见的方案是利用数据库(如MySQL)的唯一键约束,或使用Redis的`SETNX`命令记录处理状态。处理前先查询该业务ID是否已处理过。示例代码如下:
// 伪代码示例
public ConsumeConcurrentlyStatus consumeMessage(List msgs) {
for (MessageExt msg : msgs) {
String businessId = msg.getKey(); // 订单ID
// 1.查缓存/数据库判断是否已处理
if (isProcessed(businessId)) {
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
// 2.处理业务逻辑
processBusiness(msg);
// 3.标记为已处理(缓存/数据库)
markAsProcessed(businessId);
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
} - 异常处理:处理失败的消息会进入重试队列(`%RETRY%`),达到最大重试次数后进入死信队列(`%DLQ%`),需要人工介入处理。
四、消息积压:快速诊断与弹性扩容
消息积压是系统负载不均或消费能力不足的警报。不同MQ的积压影响不同:RocketMQ/Kafka基于日志文件,积压可能导致磁盘写满和旧数据被删除;RabbitMQ的经典队列积压则会严重影响Broker性能。
应急处理方案
- 临时扩容消费者:这是最快的方法。但注意,在RocketMQ/Kafka中,一个Queue只能被一个消费者线程消费。因此,Consumer实例数不能超过Topic的Queue总数。扩容时,需要同步增加Queue数量。
- 优化消费逻辑:检查消费者代码,是否可以进行数据库优化(如为查询字段加索引)、将非核心操作异步化、或批量写入以提高效率。
- 分流处理(用于处理历史海量积压):这是“外科手术”式方案。创建一个拥有更多Queue的新Topic,编写临时消费者程序将积压Topic的消息均匀转移到新Topic,然后启动大量消费者并行消费新Topic。流程如下:
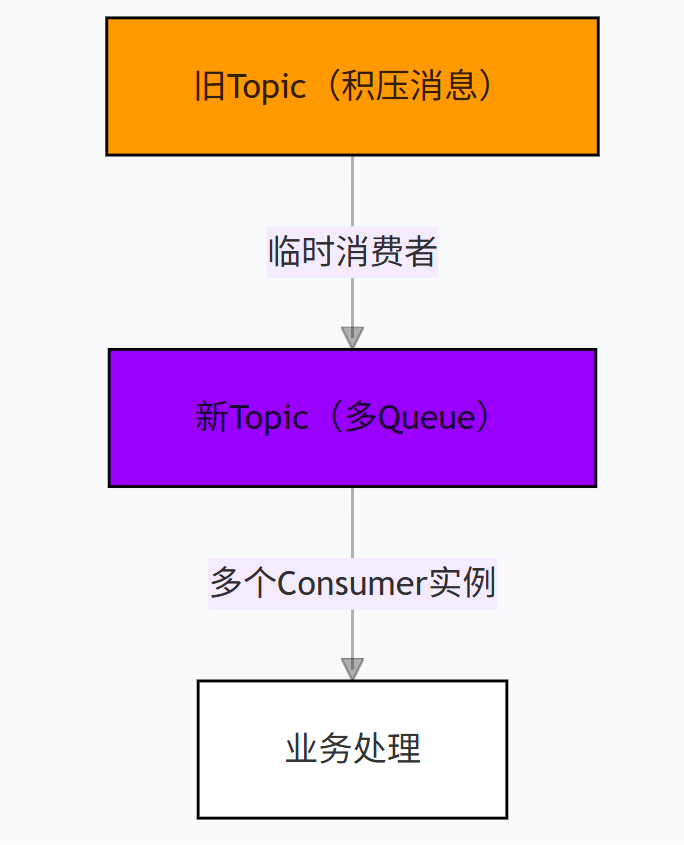
五、核心面试题深度解读
基于以上分析,我们可以更深入地回答常见面试题:
- Q: RocketMQ如何保证消息不丢失?
A: 这是一个端到端的系统工程。生产者同步发送+重试;Broker配置同步刷盘(或异步刷盘+主从同步),并采用DLedger集群模式;消费者业务处理成功后再ACK;最后,为极端情况设计降级方案(本地缓存+重试)。 - Q: 如何保证消息顺序性?
A: 通常指局部有序。生产者将同一业务键的消息通过选择器发往同一Queue;消费者对该Queue采用单线程(或有序线程池)串行消费。全局有序代价高昂,不推荐。 - Q: 如何解决消息重复消费?
A: 关键在于消费者实现业务幂等。利用消息中的业务唯一键(如订单ID),在消费前借助Redis或数据库(PostgreSQL的唯一约束)判断是否已处理。这是最可靠的方案。 - Q: 消息积压怎么处理?
A: 先紧急扩容消费者实例(不超过Queue数)并优化消费代码。若积压量巨大,采用“分流法”:创建多Queue新Topic转移消息,并行消费后再恢复架构。 - Q: RocketMQ事务消息原理?
A: 两阶段提交。先发半消息,执行本地事务(如更新MySQL),根据结果提交或回滚。Broker提供事务状态回查机制作为兜底,防止生产者本地事务状态不明。 - Q: RocketMQ与Kafka在消息安全上的核心差异?
A: 设计哲学不同。RocketMQ源于金融场景,数据安全优先。其主从架构中,Master宕机后优先保证数据不丢(原机恢复后同步数据)。Kafka源于日志处理,可用性优先,Leader宕机后快速选举新Leader,可能牺牲未完全同步的数据。两者都是CAP定理下的合理权衡。
掌握RocketMQ的核心机制,不仅能让你在面试中游刃有余,更能帮助你在实际架构设计中做出合理的技术选型与方案设计。消息中间件的学习,最终要落到与数据库操作、业务逻辑的紧密结合上,从而构建出真正稳定、高效、可扩展的分布式系统。
producer.sendOneway(msg);SendResult result = producer.send(msg, 20000);producer.send(msg, new SendCallback() {<br>@Override<br>public void onSuccess(SendResult res) {}<br>@Override<br>public void onException(Throwable e) {}<br>});

 浙公网安备 33010602011771号
浙公网安备 33010602011771号