
从一维方差到多维协方差阵:深入解析其数学必然性与工程实践
在数据科学、机器学习以及高精度定位(如GNSS)等领域,方差-协方差阵是一个基石般的概念。它远不止是一个数学符号,更是描述随机变量间关系、量化不确定性、实现最优估计的核心工具。本文将深入探讨其定义背后的数学必然性、几何直观,并结合现代编程实践,揭示其在复杂系统中的关键作用。
一、 从单变量到多变量:数学定义的优雅推广
理解协方差阵,最好从我们熟悉的单变量方差开始。对于一个随机变量X,其方差Var(X) = E[(X - μ)²]衡量的是数据围绕均值μ的离散程度。这是一个标量,描述了“一维数据云”的宽度。
当我们面对多个随机变量组成的随机向量时,一个自然的想法是:如何同时描述每个变量的离散度以及变量之间的联动关系?数学上最直接、最优雅的推广,便是构建一个矩阵:
- 对角线元素:放置每个随机变量自身的方差,延续了一维的定义。
- 非对角线元素:放置任意两个随机变量之间的协方差,即Cov(X, Y) = E[(X - μ_x)(Y - μ_y)],它刻画了X和Y是如何共同变化的。

这种定义绝非随意,它完美地将一维的“离散度”概念,扩展到了多维的“形状”描述。 正如在Python的NumPy库中,
正如在Python的NumPy库中,np.cov()函数正是基于此定义计算样本协方差矩阵,成为数据分析的标配。
二、 几何直观:描绘高维数据云的形状
将随机向量的每次观测看作高维空间中的一个点,所有观测值便形成一片“数据云”。协方差阵就是这片云的数学素描。
一维情况:数据云是一条线段,方差σ²描述了它的长度(离散度)。
一维正态分布:N(μ, σ²)
│
│ █
│ ███
│ █████
───────┼──────────────
μ二维情况:数据云是一个椭圆状的平面点集。我们需要三个参数来完整描述它:
- σ_x²:椭圆在x轴方向的伸展(方差)。
- σ_y²:椭圆在y轴方向的伸展(方差)。
- σ_xy:椭圆轴的倾斜程度(协方差)。若σ_xy > 0,椭圆主轴沿y=x方向倾斜(正相关);若σ_xy < 0,则沿y=-x方向倾斜(负相关)。
二维正态分布:N(μ, Σ)
y↑
│ ...::..
│ ..::**::..
│ ..::****::..
│..::******::..
│..::******::..
└─────────────→ x推广到n维,协方差阵Σ(一个n×n的对称半正定矩阵)就完整刻画了这个n维椭球体的所有形态特征——每个轴的尺度(方差)和轴之间的夹角(协方差)。在Java或C++中实现主成分分析(PCA)时,核心步骤就是计算并分解这个协方差矩阵,以找到数据的主要伸展方向。
三、 数学必然性:为何是此定义而非其他?
协方差阵的这一定义,因其在核心数学和统计性质上的优越性而成为必然。
1. 马氏距离与多元正态分布
普通的欧氏距离假设各向同性,不适用于相关数据。 而基于协方差阵逆矩阵定义的马氏距离:d_M = √[(x-μ)^T Σ^{-1} (x-μ)],才是真正的“统计距离”,它考虑了数据的内部结构。
而基于协方差阵逆矩阵定义的马氏距离:d_M = √[(x-μ)^T Σ^{-1} (x-μ)],才是真正的“统计距离”,它考虑了数据的内部结构。 令人惊叹的是,多元正态分布的概率密度函数核心指数项正是马氏距离的平方:
令人惊叹的是,多元正态分布的概率密度函数核心指数项正是马氏距离的平方:
f(x) ∝ exp( -1/2 * (x-μ)^T Σ^{-1} (x-μ) )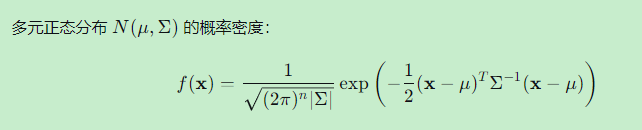 协方差阵的定义使得这个最重要的多元分布拥有如此简洁优美的形式。
协方差阵的定义使得这个最重要的多元分布拥有如此简洁优美的形式。
2. 线性变换下的完美传播(误差传播定律)
这是工程应用中的关键。若随机向量y由x经线性变换y=Ax+b得到,则其协方差阵满足:Σ_y = A Σ_x A^T。 这一性质是卡尔曼滤波和最小二乘估计中误差分析的基石。无论你用Go处理流数据,还是用TypeScript进行前端数据可视化,只要涉及线性模型的不确定性传递,都依赖于这个公式。
这一性质是卡尔曼滤波和最小二乘估计中误差分析的基石。无论你用Go处理流数据,还是用TypeScript进行前端数据可视化,只要涉及线性模型的不确定性传递,都依赖于这个公式。
3. 与其他矩阵定义的关联
协方差阵与相关系数矩阵、散度矩阵等密切相关。通过标准化,可以从协方差阵得到相关系数矩阵,后者消除了量纲,专注于描述线性关系的强度。
四、 工程实践:以GNSS高精度定位为例
全球导航卫星系统是协方差阵理论应用的绝佳舞台。在这里,它从抽象的数学对象变成了物理世界的精确度量。
1. 观测值的不确定性建模
GNSS接收机测量的伪距和载波相位包含多种误差:
# 假设有4颗卫星的伪距和相位观测
Σ = [
[σ_P1², ρσ_P1σ_P2, ρσ_P1σ_P3, ...], # 伪距之间的相关性
[ρσ_P2σ_P1, σ_P2², ρσ_P2σ_P3, ...],
...
]这些误差并非独立:大气延迟对天空相邻的卫星影响相似(正相关),多径效应与环境强相关。因此,观测值的方差-协方差阵Σ_L是一个非对角阵,精确刻画了这种复杂的误差关联。
2. 参数估计与加权最小二乘
求解接收机位置时,我们使用加权最小二乘。其最优权重矩阵正是观测值协方差阵的逆:W = Σ_L^{-1}。 这赋予了算法智能:不仅给高精度观测值(小方差)更高权重,还通过非对角元素抵消相关误差的影响,从而得到更优、更可靠的位置解。其参数解的协方差阵为:Σ_x = (A^T W A)^{-1},其中A为设计矩阵。
这赋予了算法智能:不仅给高精度观测值(小方差)更高权重,还通过非对角元素抵消相关误差的影响,从而得到更优、更可靠的位置解。其参数解的协方差阵为:Σ_x = (A^T W A)^{-1},其中A为设计矩阵。
typedef struct {
double sigma_east; // 东方向标准差 = sqrt(Σ[0,0])
double sigma_north; // 北方向标准差 = sqrt(Σ[1,1])
double sigma_up; // 天方向标准差 = sqrt(Σ[2,2])
double correlation_en; // 东-北相关系数 = Σ[0,1]/(σ_east*σ_north)
double correlation_eu; // 东-天相关系数
double correlation_nu; // 北-天相关系数
} PositionUncertainty;3. 精度衰减因子与完好性监测
DOP值是Σ_x的衍生品,它描述了卫星几何构型对定位精度的放大效应。
def compute_dop_from_covariance(Q):
"""
Q: 位置解的协因数矩阵 (4×4,包含钟差)
"""
q11, q22, q33, q44 = Q[0,0], Q[1,1], Q[2,2], Q[3,3]
GDOP = sqrt(q11 + q22 + q33 + q44)
PDOP = sqrt(q11 + q22 + q33)
HDOP = sqrt(q11 + q22)
VDOP = sqrt(q33)
TDOP = sqrt(q44)
return {'GDOP': GDOP, 'PDOP': PDOP, 'HDOP': HDOP, 'VDOP': VDOP, 'TDOP': TDOP} [AFFILIATE_SLOT_1]
[AFFILIATE_SLOT_1]五、 核心算法引擎:卡尔曼滤波与信息论视角
1. 卡尔曼滤波中的灵魂角色
在GNSS/INS组合导航中,卡尔曼滤波是核心融合算法。协方差阵P在这里代表了状态估计的不确定性,是滤波器的“记忆”和“信心”。
- 预测步骤:不仅预测状态,也通过系统模型传播不确定性(P_k|k-1 = Φ P_k-1 Φ^T + Q)。
def kalman_predict(x, P, F, Q): """ x: 状态向量 P: 状态协方差阵 F: 状态转移矩阵 Q: 过程噪声协方差阵 """ x_pred = F @ x P_pred = F @ P @ F.T + Q # 协方差传播! return x_pred, P_pred - 更新步骤:协方差阵决定了卡尔曼增益K。K的本质是一个“最优混合系数”,它告诉滤波器应该如何权衡模型预测和新的观测值。
最终,状态和协方差同时得到更新,不确定性在融合后降低。def kalman_update(x_pred, P_pred, z, H, R): """ z: 观测向量 H: 观测矩阵 R: 观测噪声协方差阵 """ # 卡尔曼增益 S = H @ P_pred @ H.T + R # 新息协方差 K = P_pred @ H.T @ np.linalg.inv(S) # 状态更新 x_updated = x_pred + K @ (z - H @ x_pred) P_updated = (I - K @ H) @ P_pred return x_updated, P_updated
2. 信息论视角:费舍尔信息矩阵
从参数估计角度看,费舍尔信息矩阵I(θ)衡量了观测数据所能提供的关于参数θ的信息量。在GNSS等线性高斯模型中,信息矩阵与协方差阵存在优美的对偶关系:I(θ) = A^T Σ_L^{-1} A,而这正是参数估计协方差阵Σ_x的逆。
# 在GNSS定位中
information_matrix = A.T @ inv(Sigma_L) @ A
covariance_matrix = inv(information_matrix)
# 信息矩阵大 ⇔ 协方差矩阵小 ⇔ 估计精度高六、 理论到实践:简化、近似与编程实现
尽管理论完美,但工程中常需在精度和复杂度间权衡。
常用简化模型:
// 简化的观测值协方差模型
void build_simple_covariance_matrix(int n, float elevation[], float sigma_base,
float Sigma[n][n]) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
if (i == j) {
// 对角线:方差,与高度角相关
float el_rad = elevation[i] * DEG_TO_RAD;
Sigma[i][i] = pow(sigma_base / sin(el_rad), 2);
} else {
// 非对角线:通常假设不相关
Sigma[i][j] = 0.0;
// 或简单相关性模型
// Sigma[i][j] = correlation_coef * sqrt(Sigma[i][i]*Sigma[j][j]);
}
}
}
}例如,为简化计算,有时会假设不同卫星的观测误差互不相关,从而使用对角协方差阵。但这会损失部分估计效率。
编程实现要点:
- 数值稳定性:直接求逆Σ^{-1}可能不稳定,应使用Cholesky分解或SVD等数值方法。在C++的Eigen库或Python的SciPy中都有成熟实现。
- 存储与计算优化:实时系统可能只存储标准差(方差平方根)而非完整矩阵,或采用稀疏矩阵格式存储具有特定结构(如分块对角)的协方差阵。
- 自适应估计:在动态环境中,协方差阵的参数(如过程噪声Q和观测噪声R)可能需要在线自适应估计,这是高级滤波算法的关键。

 这些简化和实现策略,是连接严谨数学理论与高效工程产品的桥梁。[AFFILIATE_SLOT_2]
这些简化和实现策略,是连接严谨数学理论与高效工程产品的桥梁。[AFFILIATE_SLOT_2]
七、 总结
方差-协方差阵之所以被如此定义,是因为它集数学的优雅与工程的实用于一身的必然选择:
| 原因 | 解释 |
|---|---|
| 数学自然性 | 从单变量方差到多变量的最直接推广 |
| 几何完备性 | 完整描述数据云的形状和方向 |
| 物理必要性 | GNSS误差本质上是相关的,必须用矩阵描述 |
| 算法基础 | 最小二乘、Kalman滤波等算法的核心 |
| 传播一致性 | 线性变换下自动满足误差传播定律 |
| 统计最优性 | 基于协方差阵的加权是最小方差无偏估计 |
从一维方差到多维协方差阵的推广,是数学自然性的体现。它不仅是描述随机向量二阶统计特性的最小完备工具,更在误差传播、最优估计(如加权最小二乘、卡尔曼滤波)、模式识别(如马氏距离、PCA)等领域发挥着不可替代的核心作用。无论你是用Python进行数据分析,还是用C++编写高性能导航算法,深入理解协方差阵,都将使你具备透过数据噪声看清系统本质的能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号