
吴恩达的Agentic AI新课:让AI学会“干活”,而不只是“答题” - 详解
目录
一、核心理念:从“Agent”到“Agentic”,从“一次性作答”到“分步执行”
2.1 反思(Reflection):让AI学会“自我批评”
2.3 规划(Planning):把“天大的问题”拆解成“一堆小任务”
2.4 多智能体协作(Multi-agent Collaboration)

攻城狮7号:个人主页
个人专栏:《AI前沿技术要闻》
⛺️ 君子慎独!
大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 吴恩达的Agentic AI新课
本期文章收录在《AI前沿技术要闻》,大家有兴趣允许自行查看!
⛺️ 欢迎各位 ✔️ 点赞 收藏 ⭐留言 !
引言:智能体热潮与落地困境
2025年“AI智能体”概念火热,却面临落地难题——企业采购的智能体难跑通基础流程,团队开发的AI助手常出错、成“玩具”。吴恩达最近在新课《Agentic AI》中指出,90%团队失败非因模型弱,而是开发流程不规范;课程核心即以标准化“工程师思维”,教构建可落地的AI智能体。

一、核心理念:从“Agent”到“Agentic”,从“一次性作答”到“分步执行”
要理解这门课的精髓,第一要搞懂一个关键概念的区别:Agent(智能体) 和 Agentic(智能体工作流)。
在很多人的认知里,一个强大的“Agent”,应该像一个无所不知的超级大脑。你给它一个复杂的指令,比如“帮我分析一下新能源汽车行业的现状并写一份报告”,它就应该直接给你一份完美的报告。这种“一步到位”的模式,吴恩达称之为“端到端(End-to-End)”模式。
但现实是,这种模式非常脆弱。模型输出的结果往往像一个“黑箱”,质量好坏全凭运气。一旦出错,你很难知道是哪个环节出了挑战,只能寄希望于优化提示词或者等待下一个更强的模型出现。
而“Agentic”则是一种截然不同的思路。它认为,AI不应该像一个“答题机器”,而应该像一个“干活的人”。人类在面对复杂任务时,不会一步到位,而是会将其拆解成一个流程:
(1)规划:先想想要写什么,列个大纲。
(2)启用工具:上网搜索数据、查阅资料。
(3)执行:根据大纲和资料,撰写初稿。
(4)反思与修改:回头检查初稿,看看逻辑是否通顺、数据是否准确,然后进行修改和润色。
“Agentic AI”的核心,就是为AI设计这样一套多步骤、可迭代的“工作流程”(Workflow)。让AI不再一次性“憋”出答案,而是学会拆解任务、调用设备、反思结果、循环优化。
这种模式的好处是显而易见的:
* 可靠性更高:每一步都相对简单,AI犯错的概率更低。
* 过程透明:整个流程清晰可见,一旦出错,可以敏捷定位到具体是哪一步出了问题。
* 可优化性强:我们可以针对性地改进流程中的某一个环节,从而系统性地提升整体性能。
二、四大设计模式:构建智能体工作流的“钢筋骨架”
那么,如何具体设计这样一套工作流呢?吴恩达在课程中,摒弃了对特定开发框架的依赖,直接用最基础的Python代码,总结出了四大可复用的核心设计模式。
2.1 反思(Reflection):让AI学会“自我批评”
这是最简单,也最有效的设计模式之一。它的核心就是让大模型在输出结果后,再扮演一个“审查员”的角色,自己检查一遍,然后思考如何改进。
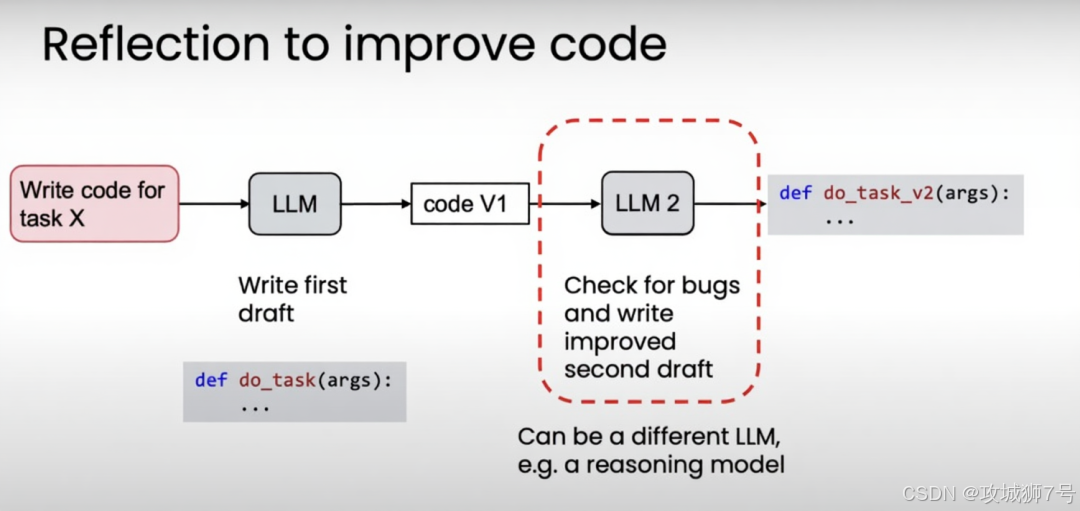
:让GPT-3.5模型编写代码。就是课程中一个惊艳的案例
* 传统方式:直接让GPT-3.5写代码,一次性输出,在某个编程基准测试中的正确率是48%。
* 加入“反思”流程后:
(1)让GPT-3.5生成第一版代码。
(2)运行测试,把代码中的错误信息反馈给GPT-3.5。
(3)让它根据错误信息,自己进行修改。
经过这个方便的“生成-审查-优化”循环,GPT-3.5的最终正确率飙升到了74%,甚至超越了不做反思、直接输出的更强模型GPT-4(其正确率为67%)。
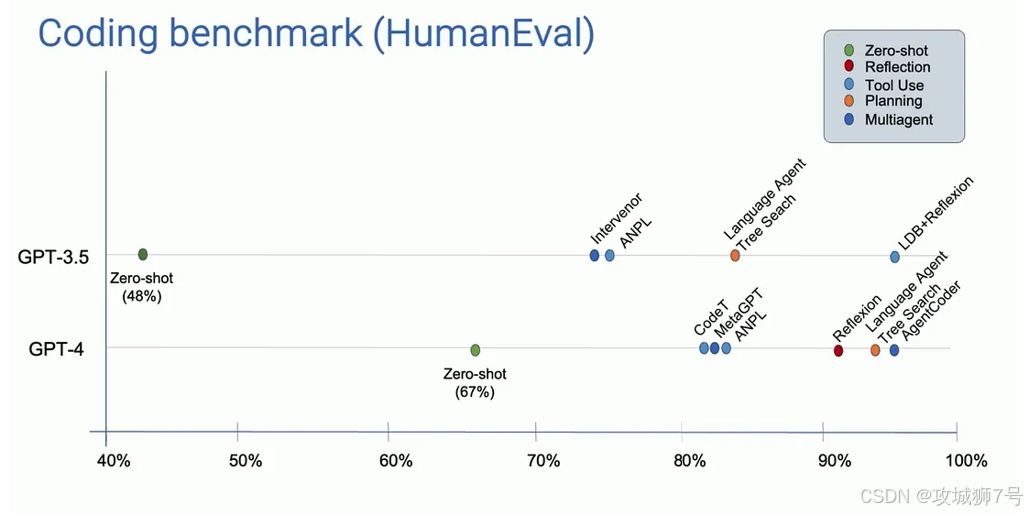
这个模式告诉我们,一个设计良好的工作流,其影响力甚至可能超过模型本身的迭代升级。
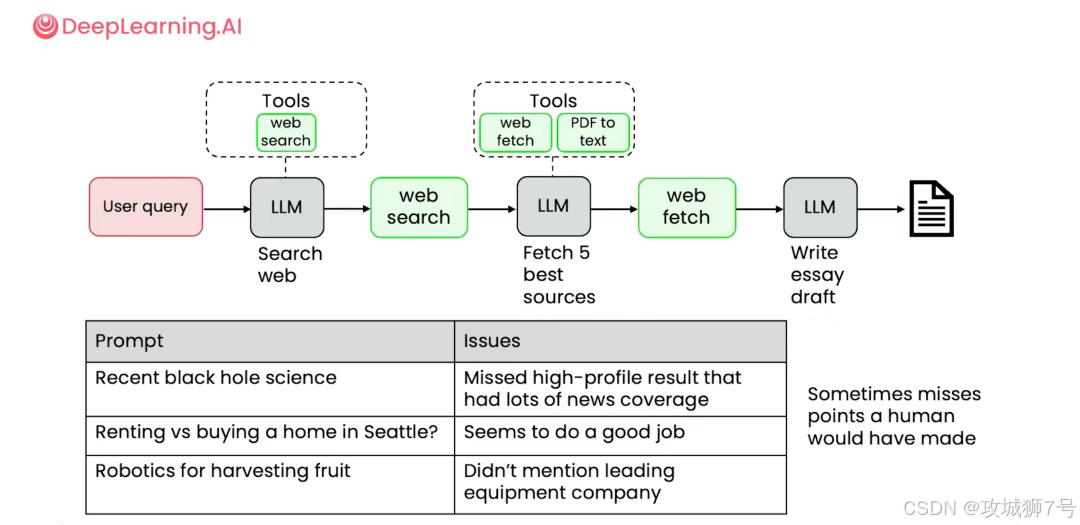
2.2 工具使用(Tool Use):为AI接上“手和脚”
大语言模型本身再强大,也只是一个“大脑”,它的知识被锁定在训练数据截止的那一刻,也无法与真实世界进行交互。而“工具使用”模式,就是为这个大脑接上“手和脚”。
这里的“设备”,可以是任何外部功能或API,比如:
(1)搜索引擎:让AI可以获取最新的实时信息。
(2)代码解释器:让AI可以运行代码,进行复杂的计算。
(3)数据库接口:让AI允许查询你公司的内部数据。
(4)邮件/日历API:通过让AI能够帮你发送邮件、安排会议。
通过这个模式,AI的能力被极大地扩展了。开发者可以预先定义好一系列工具,然后让AI在面对用户请求时,自主判断应该调用哪个软件来完成任务,从而实现“查资料-写报告-发通知”这样的全自动化流程。当然,课程也强调了安全性,比如应该在沙盒环境(如Docker)中执行AI生成的代码,防止潜在的风险。
2.3 规划(Planning):把“天大的问题”拆解成“一堆小任务”
面对一个相当宏大和模糊的任务,比如“分析某项国家政策对我们行业未来五年的影响”,若是直接丢给AI,它很可能会不知所措,或者给出一个非常空泛的答案。
“规划”模式的作用,就是引导AI先把这个“天大的问题”,拆解成一个结构化的、可执行的行动计划(To-do List)。
例如,AI可能会自主规划出如下步骤:
(1)【任务一】调用搜索应用,查找并下载与该政策相关的官方文件PDF。
(2)【任务二】调用PDF解析工具,提取文件中的关键条款。
(3)【任务三】调用数据分析工具,分析过去三年行业内容,建立增长模型。
(4)【任务四】结合关键条款和数据模型,预测未来五年的趋势。
(5)【任务五】生成最终的分析报告。
...等等。
经过这种方式,一个不可控的复杂任务,变成了一系列清晰、可管理、可追踪的子任务。整个流程“看得见、管得住”,AI的执行也变得更加可靠。
2.4 多智能体协作(Multi-agent Collaboration)
该模式的思想是,与其试图训练一个无所不能的“通才”AI,不如构建一个由多个“专才”AI组成的团队,让它们各司其职、协同工作。
课程中模拟了一个“投资决策小组”的场景:
数据分析员Agent:专门负责调用爬虫软件,搜集上市公司的财务报表和新闻。
金融分析师Agent:专门负责对搜集来的数据进行建模分析,预测公司估值。
风险控制员Agent:专门负责评估投资组合的风险,并提出预警。
投资经理Agent(总负责人):整合所有信息,并做出最终的投资决策报告。
通过通过定义清晰的角色分工和沟通协议,该“AI团队”能够完成远比单个智能体更复杂、更专业的任务。这种模式也更符合现实世界中公司的组织架构,为解决高度复杂的问题提供了新的可能性。
“评估”就是三、成功的秘诀:一切优化的基础
否建立了一套严格的就是介绍了四大设计模式,似乎大家已经掌握了构建强大智能体的蓝图。但吴恩达在课程中反复强调,以上这些都还只是“术”,真正决定一个团队能否成功的“道”,在于“评估(Evaluation)与错误分析”体系。
他发现,绝大多数陷入瓶颈的团队,都在凭感觉进行优化。而顶尖团队早已在用数据驱动迭代。这个流程可以概括为一个循环:
(1)构建/采样(Build/Sampling):先搭建一个初始版本的工作流,接着让它去处理一批真实的测试任务,并收集所有输出结果和中间过程的日志(Traces)。
(2)评估/分析(Evaluation/Analyze):对收集到的结果进行分析。这里的分析分为两种:
* 端到端评估:看最终的结果好不好。(比如,报告写得通不通顺?)
* 组件级评估:垃圾信息?第二步提取的内容准不准确?)就是检查中间每一步的输出是否正确。(比如,第一步搜索到的网页是不
(3)改进(Improvement):根据分析结果,精准地对出问题的那种组件进行优化。可能是修改某一步的提示词,可能是更换一个更可靠的软件,也可能是增加一个“反思”步骤来做校验。
完毕改进后,再回到第一步,进行新一轮的测试和评估。通过这样持续、量化的循环,智能体的性能才能得到稳步、可靠的提升。这才是真正的“AI工程”,而不是“AI炼丹”。
工程的胜利就是结语:智能体开发的未来,
一次深刻的“思想拨乱反正”。就是吴恩达的《Agentic AI》课程,与其说是一门技术教程,不如说它告诉所有AI开发者和期望应用AI的企业:
构建能解决实际难题的AI智能体,其核心竞争力正在从“拥有更强的模型”转向“拥有更规范的研发流程”。
通往这一未来的坚实桥梁。它标志着AI智能体开发,正在告别野蛮生长的炒作期,正式迈入严谨、高效的工程化时代。就是未来,AI的下半场,属于那些能将“AI的潜力”通过扎实的“工程实践”转化为“可靠生产力”的团队。这门课程所传授的四大设计模式和以评估为核心的开发循环,正
课程链接:https://deeplearning.ai/courses/agentic-ai/
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
❤️
再次感谢大家的帮助!
你们的点赞就是博主更新最大的动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号