滤波算法01 . 贝叶斯滤波 —— 咱们先瞎蒙一个再说
1.贝叶斯滤波
1.1 主观概率
假设我们有一枚硬币,现在我们想知道它抛出正面(反面)的概率,我们应该怎么做?
小白说:“那不就是正反各50%嘛,有什么难的?”
小黑说:“你这样不严谨,我们没有假设硬币是公平的,我们需要设计一个实验,先抛100次,统计正面的次数,然后抛1000次,统计正面的次数,然后抛10000次,统计正面的次数,我觉得正面占所有次数的比例随着抛的次数越多,会越趋近于某一个值(收敛),这样我们可以认为这个数值就是抛出正面的概率了。”
大家都觉得小黑说的在理,小白这不就纯粹是瞎蒙嘛,直到他们遇到了这样一个问题:
我们目前有一个测得不是很准的温度计,我们如何通过这个温度计,来尽可能的知道目前的真实气温呢?
小白:“没辄了吧!你这又100次1000次10000次的,你看现在让你测温度,你怎么同一时间测100次?你总不能拿昨天测的当今天的来用吧?切,还不如像我瞎猜。”
小黑:“。。。。”
小白和小黑其实代表了对这类问题的两种求解思想:主观概率派和大数定律派。
小黑的想法很好,他想通过进行假设并通过随机试验来验证它,但是他很难解决这样一个问题:随机过程
(随机试验:在相同条件下,试验可以重复进行,实验结果不确定,试验前结果预先未知,但试验所有可能的结果已知)
我们假设有这样一种情形:
我们用xn来表示某一状态,如果这些状态是相互独立的,那我们可以通过随机试验,来求出它们(对其概率进行赋值),但是如果这些状态之间是不独立的,那么我们很难通过随机试验来求出它们,就像上面我们无法逆转时间,在某一时刻重复测量无数次,来获取那一时刻的温度。
随机过程像是这样的关系,对于任意一个状态xk,都由它之前的(一个或者N个)状态来确定:
它们之间的概率也一样
对于像用不准确的温度计测气温这样的无法做随机试验的情况,我们似乎只能使用主观概率来求解了。
大家:“你这靠瞎蒙的也能叫求解?你让我上我也能蒙啊!”
我:“别急,虽然叫主观概率,但是其实也不是纯粹的瞎蒙,接下来的过程中我们会不断引入新的参考或者新的办法,来让我们‘蒙’出来的概率接近真是概率。”
大家:“另外你说这些状态之间不独立,那只要我们能这样证明——”
“不就可以说他们是独立的,然后做随机试验来求解了嘛!”
我:“可是这样你又要算出P(A)和P(B),想要算出P(A)和P(B),就需要证明它们的独立性,就又要算出P(A)和P(B),也就又需要证明独立性,就又又需要……”
大家:“停停停,禁止套娃!我们听你的行了吧!”
我:“这就对了嘛。”
1.2 随机过程
像上面的互相之间不独立的过程,我们称为随机过程,这个式子最终迭代下去,我们发现我们最需要的是最初的初值P(x0),而不同的初值会导致截然不同的结果,主观概率之所以并非那么“主观”,是因为我们需要做这样一件事:
引入外部观测。就像测量气温一样,假如我们收到天气预报说今天有雪,那今天的温度大概率不会是30℃,通过引入这些外部观测,我们的主观概率就变得相对客观起来。
这个“相对客观的概率”,其实就是我们常说的后验概率(试验/观测后的概率),而主观概率则是先验概率(先于试验/观测的概率)。
我们回到一个具体的问题:测量温度。
假设我们的“测不准”牌温度计,显示目前是10.3(Tm)度,我们根据他猜测目前80%可能是10度,20%可能是11度,那么根据条件概率公式:
我们来分各个部分分析一下,其中:
描述了我们在测得10.3度后,观察到真实值是10度的情况,这部分就是之前说的后验概率,也是我们求解的目标。
是我们主观猜测目前是10度的概率,也就是先验概率。比如我们猜测目前80%可能是10度,20%可能是11度,那么:
我们称为似然概率,它描述了某一原因导致这个结果的概率,或者也可以理解为哪个原因最有可能导致这个结果
比如,目前有两个班级,A班有99名男生,1名女生。B班有1名男生,99名女生。
我现在随机抽一个人,发现是一名女生,那么她最有可能是哪个班级的呢?当然你会说最可能是B班的。
在这个例子里的具体意义,它其实是描述了“测不准”牌温度计测量的准确度,它表示当真实温度是10度时,我们测得10.3度的概率。
假如我们的温度计,其测量精度是±0.1度,那么在真实温度是10度时,我们测得的温度极大概率应该在9.9度到10.1之间浮动,这时候我们可以认为:
而相对的,如果我们的温度计真的准确度很低,这个概率就会变大。所以说,在这里似然概率代表了观测的准确度,它是传感器自身的性质,不会随条件改变。
而最后的:
很朴素的来描述它就是:测量值为10.3的概率。它代表了我们测量结果中的一种,而我们有诸多测量结果的可能,所以我们不应该认为它的值是1,如果我们用全概率公式展开它,我们就能理解它代表的含义了:
它其实表示了在各种各样的真实值下,我们的测得10.3度的概率,它依旧由似然概率和先验概率组成,似然概率我们已经说了它反映了传感器本身性质,是由传感器自身决定的。
而先验概率部分,我们可以发现,这个全概率已经包含了所有真实值的情况,我们可以说P(Tm=10.3),和T的取值无关,而与T的分布规律有关,而先验概率是我们自己主观给定的,那么P(Tm=10.3),应该是一个常数n。
(说这个值和先验无关所以是常数是不准确的)
在温度计的例子中,真实温度T=10是因,而测量结果Tm=10.3是果,后验概率就是这样一个由果寻因的过程,既我们测得温度是10.3度,那么真实温度是10的概率有多大。
而似然概率是一个由因推果的过程,哪个温度最有可能让测量结果Tm=10.3呢?
所以最终,我们的公式可以这样描述:
而这个后验概率,就是我们所说的“相对客观”的概率,如此我们得到了一个方法:
- 给定一个不太准确的先验概率
- 引入外部观测(似然概率)
- 求出相对准确的后验概率
这就是贝叶斯滤波的思想了。
我:“所以你看,所谓的‘主观’,其实也不是纯靠瞎蒙吧!”
1.3 连续随机的贝叶斯公式*
上面我们由温度计的例子,大概说明了贝叶斯滤波的思想,但是这个例子是离散的。
离散随机变量的贝叶斯公式:
然而现实中,比如SLAM中的位姿变换等,都是连续的随机过程,而对于连续过程,贝叶斯公式会变成:
由于连续随机变量某点的概率为0,上式的分母P(Y=y)与先验概率P(X=x)为0,并且似然概率部分也无法计算。
于是我们提出一个想法,来将离散随机变量的贝叶斯公式进行转化。
化积分为求和。
我们先把X<x部分,等价转换为负无穷到x区间内的累加。
那么
然后对于分母部分,我们可以用无穷小区间形式来表达Y=y:
然后就可以写成概率密度的积分形式我们用f(A)来表示:
然后利用中值定理:
这三个区间,两个趋近于y,一个趋近于u,因此:
这时候我们发现,我们的公式又变成了无数无穷小叠加,因此再改写成积分形式:
至此我们得到了连续随机变量的贝叶斯公式:
其中fY(y)也为常数:
只要知道先验概率的密度函数以及似然概率的密度函数,我们就能求得它了。
可以看出形式上和离散随机变量的公式非常相近,真是数学之美呀!
1.4 似然概率的计算 & 贝叶斯滤波的一个小例子
我们回到测温度的例子上,我们设状态为X,观测为Y。
我们先猜测今天温度应该是10度左右,那我们可以给先验概率的概率密度设定为:
既期望为10,方差为1的标准正态分布。
然后我拿出“测不准”牌温度计,温度计上显示9度,接下来我们需要计算似然概率,然后最终求出后验概率。
那么我们的似然概率的概率密度应该如何计算呢?
我们需要知道温度计的测量精度,比如如果我们的温度计精度为±0.2度,那么就意味着,当真实值为x时,我们的测量值Y:
我们不妨假设我们的温度计,只会测量的偏差只会在±0.2之间,即:
也就是说,它的概率密度:
用图来表示,这个概率密度函数应该满足这样的情况,函数曲线与y=x-0.2,y=x+0.2围成的面积等于1.

但是算到这里又无法继续了,很遗憾我们仍然无法求出具体的概率密度函数。
我们需要假设几种似然模型,来模拟这个概率分布,比如我们可以假设它是等可能型:
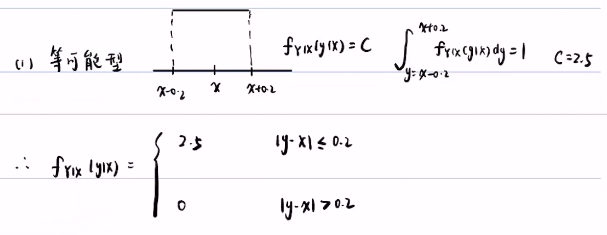
在等可能型中,我们假设在x-0.2到x+0.2中,各个值的概率是相等的,于是我们可以很轻松的求出似然概率的概率密度函数。
又或者我们可以假设它是阶梯型:
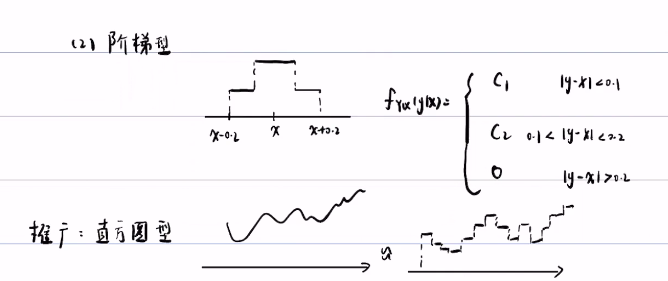
在离期望较近处概率较大,而较远处概率减小,我们也可以像等可能型一样计算出密度函数,我们也可以把它进行推广,就变成了直方图型,这样我们可以把较为复杂的密度函数分成各个阶梯,就能很容易计算出概率密度了(由此发展出非线性卡尔曼滤波的一种:直方图滤波)。
但是在SLAM或者说机器人问题里我们可能更关注这种类型:正态分布型

我们认为似然概率的分布符合正态分布N(x,σ2),那么它的概率密度公式就是:
它的数学期望是真实值x,方差为σ2,σ一般直接取传感器的精度即可。
并且正态分布型还有一个很好的性质:方差不会影响数学期望的值,期望也不会影响方差的值,即期望与方差互相独立,这对于我们后续计算很重要。
回到我们温度计的例子,我们估计一个均值为10,方差为1的先验概率N(10, 1)。
通过用温度计测量,我们得到了测量温度9,温度计的精度为±0.2度,我们的似然函数符合N(9,0.22)。
然后我们就可以计算我们的后验概率的密度函数了:
由此我们算出后验概率N(9.0385,0.0382)。
对比先验概率以及似然概率,可以看出,我们的方差显著减小了,不确定度减小,就像我们过滤了噪声、误差等干扰一样,因此被称为滤波。
我们可以把这个过程总结成公式:
如果先验概率fx(X) ~ N(μ1,σ12),似然概率fY|X(y|x) ~ N(μ2,σ22),那么他们的后验概率:
可以出μ1、μ1前面的系数之和为1,他们的系数类似于权重,如果我们假设的先验概率方差较大,那么似然概率的权重就会提升,如果似然概率的方差较大,那么先验概率的权重就会提升。
后验概率的方差:
由于σ12和σ22均大于0,我们可以知道:
不论先验概率和似然概率的方差多大,后验概率的方差始终小于他们之中最小的那个。(这才是最强的)
由此我们得到了一个先验概率与后验概率互相制约平衡的相对客观的后验概率。
实际上,先验概率是我们给出的对某一状态的预测(方差取决于我们猜的准不准),而似然概率则是我们对某一状态的观测(方差取决于我们测量或者计算的准不准)。
2. 贝叶斯滤波的计算
上面我们已经了解了贝叶斯滤波的基本原理了,现在我们就假设一个情景来进行一次贝叶斯滤波的计算吧!
通过上面的原理我我们知道:
- 提供一个先验 X = x
- 进行观测,获得观测结果 Y = y
- 求出后验 fX|Y(x|y) = n fY|X(y|x)fX(x)
不断的重复这几步,就是通过贝叶斯滤波求解当前状态的完整过程啦!
我们在每一步都需要提供一个先验,然后进行观测,然后计算后验,那么我们如何获得先验呢?前面的温度计例子,是我们随便猜了一个值,而现在我们每一步都需要一个先验,我们还要每个都猜吗?
实际上随机过程的状态变化,应该是有一定规律的,如果我们每步都随便猜一个,那么我们就相当于放弃了这些宝贵的信息,比如以下这两种状态变化(状态转移),就会变得毫无区别:
这样我们就必须非常依赖观测的结果。
而贝叶斯滤波的方法是:只有初始状态X0依靠猜测,而后续状态应该又递推获得。
2.1 基本过程
我们提供一个初始状态X0,然后引入观测Y1,通过初始值得到先验概率的密度函数,然后通过观测得到似然概率的密度函数,最后我们算出后验概率,也就是X1的概率密度函数。
然后我们再将X1作为下一步的先验,引入新的观测Y2,计算新的后验X2……如此往复循环。
如此我们建立了一个模型:他包含状态方程,和观测方程:
状态方程用于描述状态Xk与Xk-1是什么关系,其中的Q代表噪声。
比如当我们处于自由落体运动,那么状态方程就应该是:
观测方程则反映了状态如何引起传感器读取的数据:
比如我们的温度计,我们的读数也是温度,我们再Xk状态下进行一次测量,那么我们的观测方程就是:
或者我们的传感器是一个雷达,我们获取的目标的角度和距离,我们的状态函数是目前的位置,那么我们的观测方程应该是一个函数h(Xk)的形式,来通过观测计算位置。
于是我们有:
如果我们只有状态方程,没有观测方程,并且我们假设状态方程没有噪声,我们猜测一个初值X0~N(0,1),假设状态方程为Xk = 2Xk-1,那么:
可以看出这样我们的方差会越来越大,更何况还会有噪声影响。
所以我们引入观测是非常有必要的,我们需要在每一步引入观测,通过贝叶斯滤波,来降低方差。
我们的过程分为两步:
预测步:使用上一时刻的后验,通过状态方程,得到这一时刻的先验
更新(观测)步:使用这一时刻的先验,通过观测方程,得到这一时刻的后验
如此来保持我们对于每一个状态的估计都有比较小的方差。
2.2 计算
假设我们有初始值X0,其概率密度函数为fX0(x),噪声Qk,其概率密度函数为fQk(x),且我们假设X0, ..., Xk,Q0, ... , Qk相互独立。(我们的假设是正确的,这一点其实是可以证真的)
我们假设状态方程为 Xk = f( Xk-1) + Qk
预测步:我们需要通过状态方程,推出X1。
前面我们提到过,对于连续随机过程的概率P(X1<x)我们先把X<x部分,等价转换为负无穷到x区间内的累加,于是有:
通过全概率公式我们由能知道其中:
也就是(类比 P(X=1|Y=2, z=3) = P(X+Y=3|Y=2, Z=3) ):
我们发现X1 - f(X0)正是噪声Q1,于是有:
因为我们假设X0, ..., Xk,Q0, ... , Qk相互独立,我们可以把似然部分的条件拿掉:
接下来我们用概率密度函数来表示,转换时需要用到之前提到过的方法,用无穷小区间形式来表达等于,避免连续随机变量某点的概率为0:
改写成连续随机过程的概率密度函数形式:
实际上这个式子就是下面的积分:
那么我们最初的P(X<x)就等于:
这时候我们要求的先验概率密度函数fX1(x)就是它的求导:
因为他是X1的先验,我们不妨记作fX1-(x),用负号来表示它是在观测之前的先验概率,根据这个公式,我们就可以算出每一步的先验了。
(注意我们这里只是求出了其概率密度函数,具体新的状态还要另外决定)
更新(观测)步:这一步我们的目的是计算出似然概率,从而求得后验概率。
我们假设我们的观测方程 Yk = h(Xk) + Rk,Rk为观测噪声,其概率密度函数为fRk(x) ,且X1, ..., Xk,R1, ... , Rk相互独立,Y1 = y。
那么似然概率就是:
又因为R与X的相互独立:
那么我们的后验概率fX1+(x)就是:
至此,我们完成了一次预测,一次更新,我们可以这样做,比如求出后验概率的期望:
然后将其作为新一轮中,先验计算里新的初值,然后再次求出先验、似然、后验,就可以继续在预测与更新中循环下去了。
2.3 贝叶斯滤波的问题
在上面的计算里,我们发现,在预测步里,我们需要计算一次无穷积分,在更新步里,又需要计算两次无穷积分,这导致了我们非常难求解,甚至根本不存在解析解,那么就需要其他方法出场啦!
参考资料:
忠厚老实的王大头,https://space.bilibili.com/287989852/video
(宝藏up主,非常推荐)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号