Django请求的生命周期、路由匹配、分组分发、反向解析、名称空间
 学习内容总结
学习内容总结
今日学习内容总结
Django请求生命周期
概述
首先我们知道HTTP请求及服务端响应中传输的所有数据都是字符串。
在Django中,当我们访问一个的url时,会通过路由匹配进入相应的html网页中。
Django的请求生命周期是指当用户在浏览器上输入url到用户看到网页的这个时间段内,Django后台所发生的事情。
而Django的生命周期内到底发生了什么呢?
1. 当用户在浏览器中输入url时,浏览器会生成请求头和请求体发给服务端,请求头和请求体中会包含浏览器的动作(action),这个动作通常为get或者post,体现在url之中。
2. url经过Django中的wsgi,再经过Django的中间件,最后url到过路由映射表,在路由中一条一条进行匹配,一旦其中一条匹配成功就执行对应的视图函数,后面的路由就不再继续匹配了。
3. 视图函数根据客户端的请求查询相应的数据.返回给Django,然后Django把客户端想要的数据做为一个字符串返回给客户端。
4. 客户端浏览器接收到返回的数据,经过渲染后显示给用户。
整体流程可为下图:
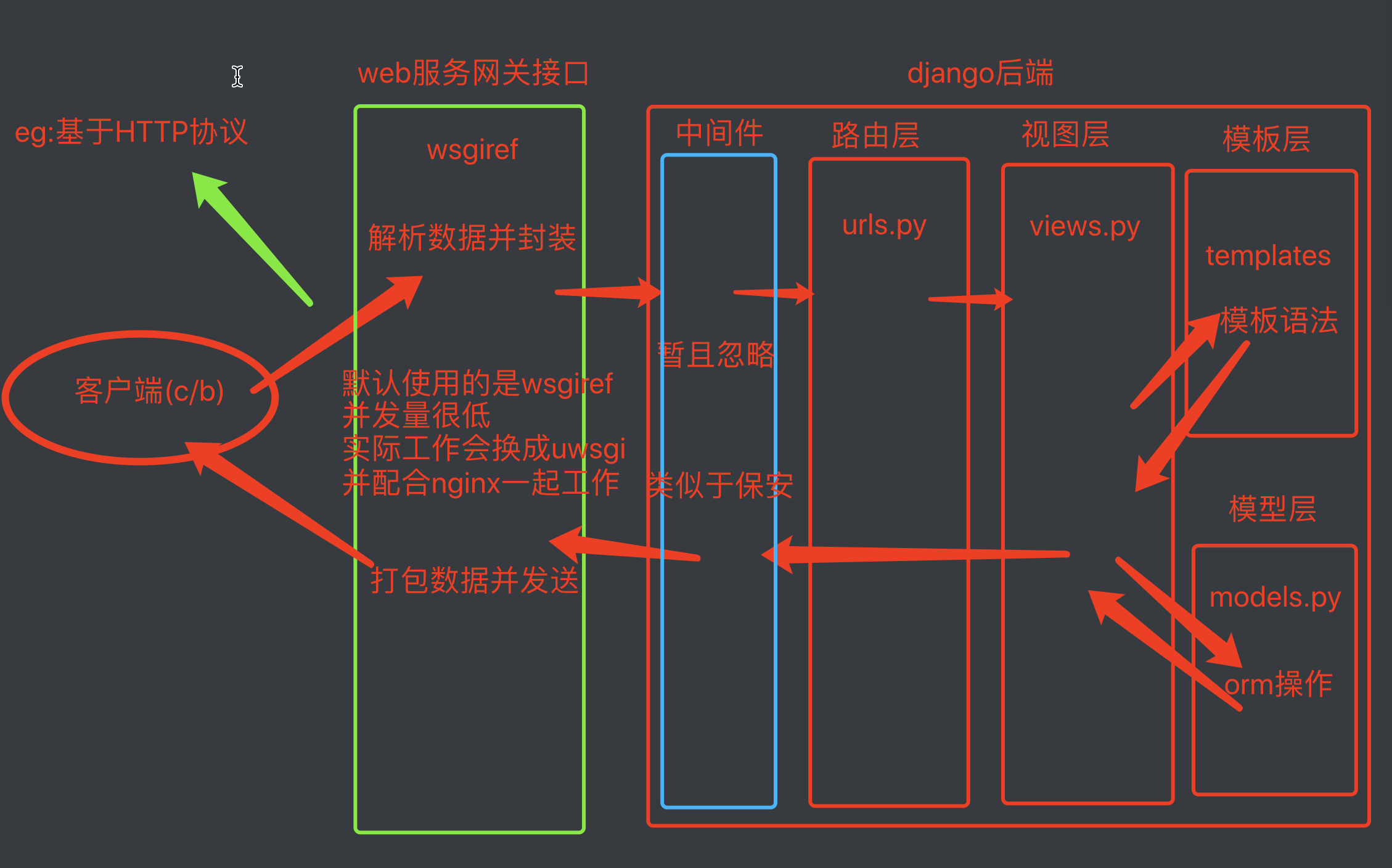
后续学习内容也就是按照这个流程学习。
路由层之路由匹配
路由匹配的特点
1.只要匹配上了就会立刻结束执行对应的视图函数。
2.url方法的第一个参数其实是一个正则表达式,只要正则表达式能够从用户输入的后缀中匹配到内容就算匹配上了。
路由匹配
# 路由匹配
url(r'test',views.test),
url(r'testadd',views.testadd)
"""
url方法第一个参数是正则表达式
只要第一个参数正则表达式能够匹配到内容 那么就会立刻停止往下匹配
直接执行对应的视图函数
你在输入url的时候会默认加斜杠
django内部帮你做到重定向
一次匹配不行
url后面加斜杠再来一次
"""
urlpatterns = [
url(r'^admin/', admin.site.urls),
# 首页
url(r'^$',views.home),
# 路由匹配
url(r'^test/$',views.test),
url(r'^testadd/$',views.testadd),
# 尾页(了解)
url(r'',views.error),
]
演变分析
1.
正则是test 内容是test 那么可以匹配出test文本
正则是test 内容是testadd 那么还可以匹配出test文本
都算匹配上了
2.
正则是test/ 内容是test 那么首次无法匹配 这时候就会触发django二次追加斜杠机制
首次匹配不上 那么django还会让浏览器默认加斜杠再次发送请求
# 取消自动添加斜杠 "/"
1. 经过测试了路由后面不添加"/"一共匹配了两次
2. 而自动添加斜杠这种操作是可以取消的
# setting.py 文件
APPEND_SLASH = False # 默认 True 自动添加斜杠
3. 设置之后如果不添加斜杠就无法访问资源
3.
正则是test/ 内容是abcdefgtest/ 那么可以匹配出文本test/
可以在正则的最前面加上上箭头来限制,解决路由前面可以随意乱写的问题
4.
正则是^test/ 内容是test/abc/edf/acd/ 那么可以匹配出文本test/
可以在正则的最后面加上$来限制,解决路由后面可以随意乱写的问题
拓展
由于第一个参数是正则,所以当项目特别大,对应关系特别多的时候要格外的注意是否会出现路由顶替的现象。
1.可以定制一个主页面,用户不携带后缀可以直接访问
url(r'^$',views.home)
2.也可定义一个尾页,用户输入一个没有对应关系的直接返回
url(r'.*',views.error)
无名有名分组
无名分组
url(r'^login/$', views.login_func)
# 无名分组
url(r'^login/(\d+)/$', views.login_func)
# 视图函数
def login_func(request,*args):
print(args)
return Httpresponse(args)
url( ) 方法中第一个参数正则表达式分组 : 给正则表达式前后加一个小括号
会将括号内正则表达式匹配到的内容当做位置参数传递给后边的视图函数传递一个request位置参数。
如果路由匹配中使用括号对正则表达式进行了分组,那么在调用视图函数的时候,会将括号内匹配到的内容当做位置参数传递给视图函数。
有名分组
url(r'^login/$', views.login_func)
# 有名分组
url(r'^login/(?P<id>\d+)/$', views.login_func)
# 视图函数
def login_func(request,**kwargs):
print(kwargs)
return Httpresponse(args)
给括号内的正则表达式起别名之后,匹配成功则会讲括号内匹配到的内容按照关键字参数传递给视图函数。
有名无名能否结合使用
无名有名分组不能不能结合使用。
url(r'^login/(\d+)/(?P<id>\d+)/$', views.login_func)
# 官方说不能混着用, 混着用只能取到有名分组捕获的值
# 只要不混着用,有名分组和无名分组支持多个相同类型的传参
但是可以单个复用。
url(r'^login/(\d+)/(\d+)/$', views.login_func)
url(r'^login/(?P<id>\d+)/(?P<id>\d+)/$', views.login_func)
反向解析
概念
反向解析就是通过一些方法得到一个结果, 该结果可以直接访问对应的 url 并触发视图函数。
作用
1.在使用一个 Django 项目时, 我们经常需要将一个 url 嵌入到生成的内容中去, 如果将这些 url 固定写死, 那么可扩展性很差, 并且一定程度上会产生过期的 url。
2.使用反向解析就是当路由频繁变化的时候, 让 html 界面上的连接地址做到动态解析。
反向解析的使用
1.给路由与视图函数对应关系添加一个别名 (名字由自己指定, 只要不冲突即可)
# 路由层
url(r'^func666/',views.func,name='func_view')
2.根据该别名可动态解析出一个结果, 该结果可以直接访问到对应的路由。
# 前端中使用(模板层)
<a href="{% url 'func_view' %}">登入</a> # func666/ 结果可以访问路由
# 后端中使用(视图层)
from django.shortcuts import reverse
url = reverse('func_view') # func666/ 结果可以访问路由
无名分组反向解析
1. 给对应关系起别名
url(r'^func666/(\d+)/',views.func,name='func_view')
2. 使用反向解析获取结果
前端:
{% url 'func_view' 123 %} # func666/123/
后端:
from django.shortcuts import reverse
reverse('func_view',args=(666,)) # func666/666/
有名分组反向解析
1.给对应关系起别名
url(r'^func666/(?P<id>\d+)/',views.func,name='func_view')
2.使用反向解析获取结果
前端:
{% url 'func_view' 123 %} # func666/123/
{% url 'func_view' id=123 %} # func666/123/
后端:
from django.shortcuts import reverse
reverse('func_view',args=(666,)) # func666/666/
reverse('func_view',kwargs={'id':1}) # func666/1/
路由层中分组匹配得到的数字并不是我们这样写死的, 一般情况下放的是数据的主键值, 我们可以通过获取到数据的主键.进而定位到数据对象, 从而可以对数据进行编辑和删除。
路由分发
简介
django是专注于开发应用的,当一个django项目特别庞大的时候, 所有的路由与视图函数映射关系全部写在一个 urls.py 里面很明显太冗余并且不便于管理。
其实django中的每一个应用都可以有自己的 urls.py、static文件夹、templates文件夹, 基于上述特点, 使用django做分组开发非常的简便。
每个人只需要写自己的应用即可, 最后由组长统一汇总到一个空的django项目中然后使用路由分发将多个应用关联到一起。
利用路由分发之后, 总路由不再干路由与视图函数的直接对应关系, 而是做一个分发处理, 进而识别当前url所属的应用, 最后直接分发给对应的应用去处理就行了, 并且应用路由重名也无关要紧。
路由分发设置
1.创建多个应用 并去配置文件中注册。
INSTALLED_APPS = [
'app01',
'app02'
]
2.在多个应用中编写相同的路由。
urlpatterns = [
url(r'^index/',views.index111)
]
urlpatterns = [
url(r'^index/',views.index)
]
3.路由分发
from django.conf.urls import url, include
# 方式一 : 复杂写法
from app01 import urls as app01_ulrs
from app02 import urls as app02_ulrs
urlpatterns = [
path('admin/', admin.site.urls),
re_path(r'^app01/', include(app01_ulrs)),
re_path(r'^app02/', include(app02_ulrs)),
re_path(r'^app03/', include(app03_ulrs))
]
# 方式二 : 高级写法
urlpatterns = [
path('admin/', admin.site.urls),
re_path(r'^app01/', include('app01.ulrs')),
re_path(r'^app02/', include('app02.ulrs')),
re_path(r'^app03/', include('app03.ulrs'))
]
名称空间
当多个应用设置了相同的别名, 在反向解析的时候前面路由会被后面的路由覆盖, 那么就无法触发前面路由对应的视图函数, 正常情况下, 反向解析是无法自动识别前缀的, 为了避免这种错误, 引入了名称空间
验证发现默认情况下是不会自动识别应用前缀的,如何解决反向解析问题。
方式1:名称空间
总路由添加名称空间
url(r'^app01/',include('app01.urls',namespace='app01')),
url(r'^app02/',include('app02.urls',namespace='app02'))
应用反向解析自动提示
reverse('app01:index_view')
reverse('app02:index_view')
{% url 'app01:index_view' %}
{% url 'app02:index_view' %}
方式2:只需要确保反向解析的别名在整个项目中不重复即可,可以在别名的前面加上应用名的前缀
url(r'^index/',views.index,name='app01_index_view')
url(r'^index/',views.index,name='app02_index_view')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号