Learning C++ primer plus
Hello everyone!现在由我来带大家进入编程语言C++的学习
第一节 进入C++
相信大家有一点C的基础的,以下是一些对初学者困惑的解答和建议:
-
为什么要将头文件写到写到程序里边呢? 因为此时涉及到程序和外面世界的通信,将源代码文件和头文件组合成一个复合文件,编译的下一阶段需要该文件
-
命名空间可以将代码封装到一个单元中,可以通过单元名称去同名代码的不同含义。using编译指令可以使得某个命名空间的所有名称都可以使用,其实这是一种偷懒的做法,在大型项目中会存在潜在的问题。可以通过
using std:: out;来声明所需要的名称,之后就可以直接使用out,而不必加上std::前缀。 -
endl可以去确保程序继续运行前刷新输出,而\n不可以保证。也就是说在有些系统中,可能输入信息后才有提示 -
C++代码风格:
1.每条语句占一行
2.每个函数段需要俩个大花括号包含,这俩花括号各占一行
3.函数中语句都相对花括号进行缩进
4.与函数名称相关的圆括号周围没有空白[1]。 -
为什么必须声明变量?因为不声明会存在潜在问题!如果不声明,错误的拼写了变量名,将在不知情的情况又创建了一个新的变量。
-
函数如果写在
main函数下面则需要在主函数体上面声明。C++不允许函数定义嵌套在另一个函数定义中,每个函数的创建是平等的。大部分情况下,构建程序的过程本质上是对规范调试的过程。
现在的互联网是浮躁的,导致现在的学生是浮躁的,都想一步登天。我建议是大家把那几个学科大课学好,把C语言学好,然后再去选择其他编程语言。一步一步的来,不要急。
最后给大家几个忠告来结束本小节吧:
1.多交流:不管你的技术多么硬,你都不可能一个人做完所有的事情,你要学会与别人合作,与别人交流。交流过程中,要注意交流技巧。学会尊重别人,但要不亢不卑。
2.多动手:熟能生巧,这是万能之理。我们干的是技术活,最能证明自己能力的就是干!不是扯淡!
3.多思考:不要做编码机器。
4.多总结:相同的问题不可能只出现一次,尤其是在我们这个行业。总结是为了你在以后更快的解决类似的问题,提高工作效率。
5.多分享:分享的更多,你会得到的更多,相信我。
6.多阅读:多聆听:不要仅限于技术,你要了解的不只是技术。同样的问题,听一听别人是怎么想的,怎么思考的,你会得到更多。
7.永远不要做拿来主义:没有人有义务帮你搞定问题,不要张口就要,给你你很幸运,不给你也不是别人的错。
第二节 处理数据
简单变量
首先我们要了解变量的属性:
- 信息存在哪里
- 要存储什么值
- 存储何种信息的类型
变量名
命名规则如下:
1.在名称中只能使用字母字符、数字和下划线
2.名称的第一个字符不能是数字
3.区分大小写字符
4.不能将C++关键字作名称
5.以一个下划线开头的名称被保留给实现[2],用作全局标识符;以俩个下划线或者大写字母打头的名称被保留给实现使用。
6.对名称长度没有限制,名称中所有字符都要有意义
驼峰命名法 vs 下划线命名法
驼峰命名法(Camel Case):
- 驼峰命名法分为小驼峰命名法和大驼峰命名法。
- 小驼峰命名法:变量名首字母小写,后续每个单词的首字母大写,不使用下划线。例如:myVariable, totalAmount。
- 大驼峰命名法:所有单词的首字母都大写,不使用下划线。通常用于类名或类型名。例如:MyClass, TotalAmount。
- 优点:可读性较好,易于阅读和理解长名称,特别适合在面向对象的编程中表示类和对象。
- 缺点:名称长度较长,某些情况下可读性可能稍差。
下划线命名法(Snake Case):
- 下划线命名法使用下划线字符作为单词之间的分隔符。
- 所有字母小写,单词间用下划线连接。例如:my_variable, total_amount。
- 优点:较短的名称,可读性较好,适合在函数、变量等场景下使用。
- 缺点:某些情况下可能会显得杂乱,不便于快速阅读长名称。
选择命名风考量:
- 有时候,项目的编码规范或团队约定可能会明确指定使用一种命名风格。
- 不同的编程语言可能对命名风格有偏好或规定。
- 命名的可读性是关键,无论选择驼峰命名法还是下划线命名法,都应确保名称清晰、简洁和易于理解。
- 在整个代码库中保持一致的命名风格非常重要,以提高可维护性和团队协作效率。
选定一种一致的命名风格并坚持使用。
运算符 sizeof
sizeof (数据类型) / sizeof 变量
都可以指出其占用内存大小
初始化
变量初始化的意义在于表达式的值都是已知的。如果不对其进行初始化,变量的值将是他创建之前相应内存单元存放的值
有俩种初始化方法:
int res = 100;
int res (100);
还有一种初始化方法是用 "{}"来初始化,可以忽略等号,这个以后讨论。
这俩种初始化方法执行的结果都是一样的
浮点数的优缺点
| 优点 | 缺点 | |
|---|---|---|
| 浮点数 | 1.表示整数之间的值 2.有缩放因子,表示的范围比整数更大 | 1.运算速度比整数慢 2.结果精度降低 |
const限定符
在数据类型前加const和数据类型后加const是等价的。
const int Month = 12;//在变量定义前加关键字const,修饰该变量为常量,不可修改
const 类型的变量必须在定义时进行初始化,之后不能对const型的变量赋值
也就是将变量当成常量使用,数值不可修改
运算符优先级
这个比较简单可以自行了解 运算符优先级。
数据强制转换
我要介绍的是以{}初始化时进行的转换,和普通强转的区别在于前者对转换的要求更加严格,即初始化时不允许缩窄。比如 将 double 类型转换为 int 。
数据类型auto
auto可以推断变量的类型,是关键字。但是使用场景太过简单可能会让人误入歧途。具体在使用STL库中的类型时,auto 的优势才能显示出来。
复合类型
C-字符串
char dog[8] = {'a','s','d','d','f','g','h','h'} //char 数组
char cat[8] = {'s','t','u','d','e','n','t','\0'} //字符串
char res[ ] = "data structure" //字符串
char name[15] = "Mr.blacksmith" //字符串
在程序cin读取时,不能接受空格,若输入data structure,则在第一次只接收data,同时将structure放入输入队列,作为第二次输入内容。
面向行的输入
- getline()函数
- cin.getline(存储输入行数组的名称,读取的字符数)
- get()函数
- 参数与上面的getline()函数相同
- get不在读取并丢弃换行符,而是将其留在输入队列。若俩次连续调用get函数,第一次调用后换行符留在输入队列,第二次调用时看到第一次字符便是换行符,会认为没有人和可读取的内容
- 若俩次连续调用get函数,则中间可用无参数的get函数即
cin.get(),来接受换行符 - 因为
cin.get(name,Arsize)返回的是cin对象,所以cin.get(name1,Arsize1).get()和cin.getline(name1,Arsize1).getline(name2,Arsize2)的使用方法是允许的
sizeof和strlen
前者返回char数组大小,后者返回数组中字符的数量
string类
string str1 = "Everything will be fine"
string str2 {Everything will be fine}
二者初始化效果相同
string与C-字符串
- 字符串长度
- string————str.size()
- char 数组————strlen.(数组名)
- 字符串拼接
- string
str3 = str1 + str2; - char 数组
strcpy(str3,str1);//拷贝
strcat(str3,str2);//追加
- string
结构体、共用体和枚举
结构体
结构体是一种自定义的复合数据类型,可将不同的数据类型组合成为一个整体,关键字struct。
共用体
共用体也叫联合体,使几个不同类型的变量共占一段内存(相互覆盖),其所占内存是至少能够容纳最大的成员变量所需的空间,关键字union。
枚举
枚举是一种创建符号常量的方式,可以代替const,还允许定义新类型,默认初始值为1~n.若将中间一个元素初始化时赋值为value,前面元素的值不变,后面的元素值++。对于枚举,只定义了赋值运算,算数运算是不允许的,比如
band = blue; //valid
band = 2000; //invalid,2000 not an enumerator
band = orange + red; //not valid,but a little tricky
指针
警告
一定要在指针解引用之前,将指针初始化为一个确定的、适当的地址
(p++)、++p、++p和(p)++的区别
知道你们懒得看代码和推导过程,给你们推荐这个 指针优先级
结构体变量用.去访问成员变量,结构体指针用 ->来访问成员变量
new
分配内存通用格式
typeName * pointer_name = new typeName ;//new返回的是分配好内存后内存的首地址
int* pt = new int ;
int higgens;
int* pn = &higgens;
第一种只能通过该指针访问,第二种还可以通过名称higgens来访问该int。
new创建数组
- 静态创建
const int N = 1000;
int* res = new int [N];
- 动态创建
int size;
cin >> size;
int* res = new int [size];
delete
释放内存
int* p = new int;
···
delete p;
释放数组
int* p = new int [10];
···
delete [] p;
用delete删除new创建的指针内存,不要删除自主设置的指针内存。
数组的替代品
vector
变长数组
创建语法:
vector<typeName> res;
由此设置vector的类型和大小
二维vector
// 初始化一个 二维的matrix, 行M,列N,且值为0
vector<vector<int>> matrix(M,vector<int>(N))
array
静态分配的数组,效率和数组一样且更安全
创建语法:
array<typeName,n_elem>
这里与vector不同的是,n_elem不能是变量。
可以对vector和array使用成员函数at()
vector<int> res;
res[3] = 100;
res.at(3) = 100;
使用成员函数at()的好处是可以捕获非法索引,降低意外越界的概率,代价是运行时间更长。
循环与逻辑运算符
基于范围的for循环
对于数组或者容器类(vector、array)的每个元素执行相同的操作
for(auto x : a) //将a中每个元素单独取出来赋值给x
std::cout << x << endl;
文件尾条件
- while (cin >>a) + 输入ctrl+z
- while((scanf"%d,%d",&m,&n)!=EOF)
- while(~cin.fail())
switch
switch通用格式
switch (integer-expression)
{
case label1 : statement (s)
case label2 : statement (s)
···
default : statement (s)
}
break 和 continue
break直接跳出循环;满足一定条件后continue后的语句在当次循环中不会被执行
逻辑运算符
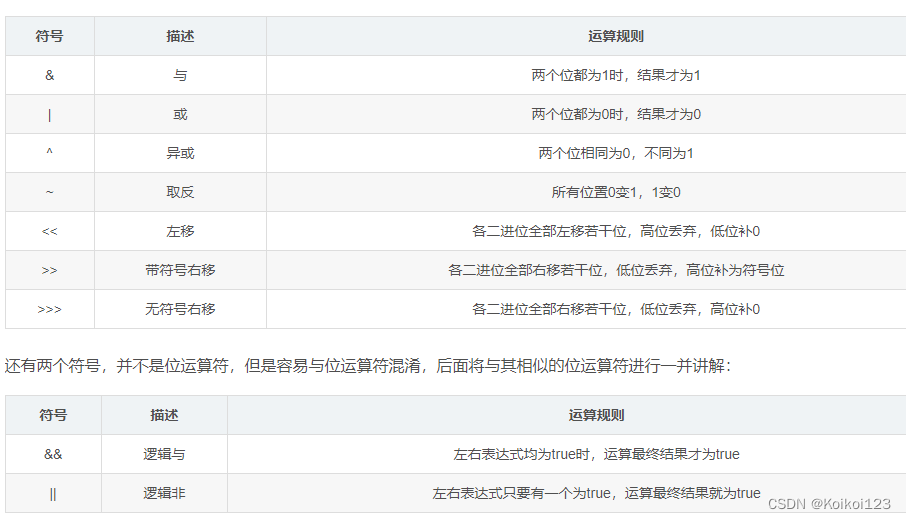
区别一下|、||、&、&&
- | 和 || 都表示'或',但是后者在运算时若满足第一个条件,第二个条件将不再计算,直接返回true
- &和&&都表示'与',但是后者在运算时若不满足第一个条件,第二个条件将不再计算,直接返回false
简单文件I/O
- 包含头文件fstream。
- 创建一个fstream对象。
- 将该fstream对象和某个文件关联起来
- 像使用cin / cout那样使用该对象
以下是一些文件的打开方式和解释
| 打开方式 | 解释 |
|---|---|
| ios::in | 打开文件进行读操作,这种方式可避免删除现存文件的内容 |
| ios::out | 打开文件进行写操作,这是默认模式 |
| ios::ate | 打开一个已有的输入或输出文件并查找到文件尾开始 |
| ios::app | 在文件尾追加方式写文件 |
| ios::binary | 指定文件以二进制方式打开,默认为文本方式 |
| ios::trunc | 如文件存在,将其长度截断为零并清除原有内容,如果文件存在先删除,再创建 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号