

浅谈关于代码中变量命名的规范
一、为什么命名如此重要?
1.1 变量命名是外人对已写好代码的第一印象
第一印象决定了他人对你能力的初步印象,假如随便命名,很大概率导致他人对你代码的印象极差,进而对代码的质量产生严重怀疑,这可能导致严重推迟协作效率,导致不可挽回的损失,他人对你的工作能力也会产生非常大的怀疑。
虽然咱们在变量命名时会花费一定的时间去构思和编写组合单词来构建变量或方法名,但是这对于后续代码的可读性和通用性的提升是十分巨大的。笔者之前也特别不喜欢对方法命名,经常使用什么1,2,123这种“容易挨揍”的方式对方法进行命名,但是虽然当时写的时候爽了,当笔者第二天想要去读之前写的代码时,头真的超级超级大,完全记不清昨天写的是啥来着。所以笔者想说的是,尽管在命名时会花费一定的精力和时间去寻思和构建,可能时间比例是10:1的比例(写代码:构建命名),但是多花的这点时间成本完全完全是值得的,不然后续真的是一步一个火坑,完全没法看,可能花费20倍的时间(相对于之前的时间单位)去研究之前写的代码是啥意思。
这里笔者可以给大家提一个小建议,我现在用Quicker(是一个快捷小工具)下面的变量命名工具来直接一键生成变量或方法名字(还挺好用的,大家可以尝试一下,这个工具也有很多为爱发电的其他功能,超级好用)
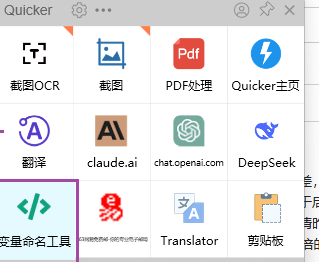
把中文输入编译器中,然后点击就可以生成你想要的命名方式了(大驼峰、小驼峰等等)
1.2 维护成本
其次,一个糟糕的命名会带来很多隐形的债务,当你不负责这个项目时,可能对于后续接手的维护人员来说是一个很大的打击。试想一下当你接手一个其他人的项目时,打开后里面全都是奇葩的命名方式,比如广为流传的 import numpy as pd(地狱笑话)这种,真的有杀人的心都有了。试想一下你也不想背后有人骂你吧哈哈哈,所以可能你不经意之间的一个命名规则,会给后续的维护人员带来难以忍受的灾难。
1.3 在当下AI时代的弊端
最后,我也觉得是最重要的一点,在当下AI时代的冲击下,传统的开发方式正在没落和变革,随之而来的是新型开发方式的登场(80%左右由AI完成,20%左右由程序员完成(主要负责框架搭建,业务逻辑完善)),在这种开发方式下,AI替代了传统程序员的大部分工作,那么接踵而来的是如何让AI能够理解你的指令。要知道当下AI助手的token是有限的,任何一次提问都需要携带着一些关键的问题。所以规范的命名是让AI成功理解的关键,在规范命名下,真的能够达到事半功倍的效果,笔者亲自体会过。
二、命名规范的核心原则
说了这么多,那么我们应该怎么做呢?
2.1 清晰性高于简洁性
之前写代码的时候见过很多人为了省事,简写了变量名字,比如:
反例:dt vs deliveryTime 正例:calculateInvoiceTotal() vs calc()
要知道有些东西可以省略,有些东西真的不能省略,可能你写的时候爽了,但是后续你再看一遍的话,我觉得可能除了老天爷外没人能看得懂。
2.2 一致性原则,统一概念使用相同词汇
如果你不是一个独立开发者的话,那么相信你一定是和团队合作来完成项目的,那么笔者觉得很重要的一件事就是提前约定的统一命名规范,虽然可能存在“完美规则”,但是团队统一约定比所谓的完美重要的多。
不仅是开发时能够统一规范,在git最后合并时也会减少很多很多的麻烦。
2.3 语境适配
在领域驱动方面,笔者建议大家尽量使用业务术语而非技术术语,业务术语能让大家更加快速了解你所写的内容,减少知识壁垒。
同样,在代码层级方面,局部变量与公共API的命名差异也要把握好尺度,避免将二者的范围混淆。
三、典型命名模式与案例分析
下面直接看下具体的案例吧!
3.1 工具/辅助类命名
点击查看代码
// 标准模式
StringUtils.isEmpty() // Apache Commons
DateFormatter.format() // 职责明确
FileValidator.validate()
// 应避免
StringHelper.doSomething() // 过于模糊
CommonUtils.process() // “Common”是万恶之源
3.2 布尔变量与方法命名
点击查看代码
// 推荐 - 使用is/has/can/should等前缀
isActiveUser() // ✔ 可读性强
hasPermission() // ✔ 表达状态
canEditPost() // ✔ 表示能力
// 避免模糊命名
flag // ✘ 含义不明,什么标识?
checkUser() // ✘ 返回布尔值吗?
3.3 集合与数组命名
点击查看代码
# 使用复数形式或显式说明
user_list = [] # ✔ 清晰
active_users = [] # ✔ 更好
# 反例
user = [] # ✘ 单数名表示复数内容
data = {} # ✘ 过于泛化
3.4 方法命名:动词+宾语模式
点击查看代码
// 明确的动宾结构
calculateTotalPrice() // ✔
sendEmailNotification() // ✔
// 模糊的命名
processData() // ✘ 做什么处理?
handleRequest() // ✘ 如何处理?
3.5 临时变量与循环变量
点击查看代码
// 适当的简写
for (let i = 0; i < length; i++) // ✔ 约定俗成
const temp = computeTemporaryValue() // ✘ 尽量避免“temp”,虽然笔者之前也特别喜欢用temp,但是为了代码的长久可读性和后期维护性必须改掉这个毛病。
// 有意义的循环变量
for (const user of activeUsers) // ✔ 明确
users.forEach(item => {...}) // ✘ item太模糊
四、常见“不恰当”命名及改进
4.1 信息不够
点击查看代码
// 坏味道
void process() { /* 处理什么?如何处理? */ }
int data; // 什么数据?
// 改进
void processOrderPayment() { /* ... */ }
int customerAge;
4.2 过度缩写
点击查看代码
# 难以理解
cust_ord_cnt = 0 # 客户订单计数?
usr_pref_svc = None # 用户偏好服务?
# 清晰表达
customer_order_count = 0
user_preference_service = None
4.3 误导性命名
点击查看代码
// 具有欺骗性
getUsers() // 实际上还更新了缓存?
isValid() // 有副作用吗?
// 诚实命名
getUsersAndRefreshCache()
isValidAndLogValidation()
五、结语
当我们审视代码命名这个看似微小的实践时,实际上触及了软件工程的核心矛盾:在机器执行的精确性与人类理解的模糊性之间架设桥梁,供人类高效通过。优秀的命名规范不是编码的装饰品,而是支撑可维护性、可协作性的“看不见的基础设施”。
命名本质上是编码中成本最低、回报最高的文档形式。每一次为变量或方法深思熟虑的命名,都是在为未来的自己、为团队伙伴、甚至为六个月后完全陌生的你预存理解力。这种投入带来的复利效应极为显著:减少代码审查时的困惑循环,缩短新成员的上手时间,降低重构时的恐惧心理。当calculateMonthlyRevenue取代了calc,当isEligibleForDiscount替代了checkFlag,代码就从隐晦的符号集合转变为了自解释的业务叙述。
这种转变带来的最深刻影响是认知负担的转移——从理解“这段代码在做什么”转移到思考“这段代码如何更好地解决问题”,这节省的脑力和时间是难以估量的。清晰的命名将开发者的心智资源释放到真正的创造性工作上,而不是耗费在破解命名谜题上。
在技术债务日益成为项目重负的今天,良好的命名习惯是最具性价比的预防措施。它像代码的“免疫系统”,防止模糊性、歧义性和误导性名称如“技术病毒”般扩散。一个用data、temp、process充斥的代码库,其维护成本往往指数级增长,因为每个改动都需要考古学家般的耐心去追溯真实意图。
最重要也是笔者最想说的是,命名规范体现了程序员对职业的尊重——尊重接手代码的同行,尊重未来的自己,最终尊重创造的价值本身,如果一个程序员连对自己的职业都难以尊重,那么读到他写的代码的大家又应该以何种理由去相信他写的代码的质量呢?
第一次写博客,如有不足,还望指出和包涵,笔者也向往和致力于营造一个氛围良好的技术交流环境,希望大家能够一起进步、一起学习、一起成长。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号