
002-k8s核心概念、Pod、网络通讯方式、k8s中Node、Pod、container、service、deployment、rs关系及作用
一、概述
1.1、Pod概念
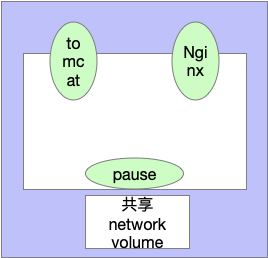
1.1.1、自主式
自己定义管理
1.1.2、控制器管理的Pod
ReplicationController& ReplicaSet &Deployment
ReplicationController用来确保容器应用的副本数始终在用户定义的副本数,即如果有容器异常退出,会自动创建新的Pod来替代;而如果异常多出来的容器也会自动回收。
在新版的k8s中建议使用ReplicaSet来代替ReplicationController。
ReplicaSet跟ReplicationController没有本质不同,只是名称不一样,并且ReplicaSet支持集合式的selector
虽然ReplicaSet可以独立使用,但一般还是建议使用Deployment来自动管理ReplicaSet,这样就无需担心跟其他机制的不兼容问题(比如ReplicaSet不支持rolling-update但Deployment支持)
Deployment 不负责镜像创建
HPA(Horizontal Pod Auto Scale):仅适用于Deployment和ReplicaSet,在V1版本中仅支持根据Pod的cpu利用率缩容,在vlalpha版本中,支持根据内存和用户自定义的metric扩缩容
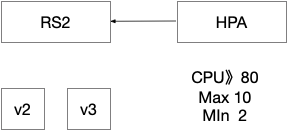
StatefullSet
是为了解决有状态服务的问题(对应Deployments和ReplicaSets是无状态服务而设计),应用场景:
稳定的持久化存储,即Pod重新调度后还是能访问到相同的持久化数据,基于PVC来实现
稳定的网络标志,即Pod重新调度后其PodName和HostName不变,基于Headless Service (即没有ClusterIP的Service)来实现
有序部署,有序扩展,即Pod是有顺序的,在部署或者扩展的时候要依据定义的顺序依次进行(从0-N-1,在下一个Pod运行之前所有的Pod必须是Running和Ready状态),基于init containers来实现
有序收缩,有序删除(即从N-1到0)
DaemonSet
确保全部或者一些Node上运行一个Pod副本。当有Node加入集群时,也会为他们新增一个Pod。当有Node从集群移除时,这些Pod也会被回收。删除DaemonSet将会删除它创建的所有的Pod
使用DaemonSet的一些用法
运行集群存储daemon,例如在每个Node上运行glusterd、ceph
在每个Node上运行日志收集daemon,如fluentd、logstash
在每个Node上运行监控daemon,如Prometheus Node Exporter
Job,Cronjob
Job负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个Pod成功结束
Cron Job管理基于时间的Job,即:1》在给定时间点只运行一次;2》周期性地在给定时间点运行
1.2、服务发现

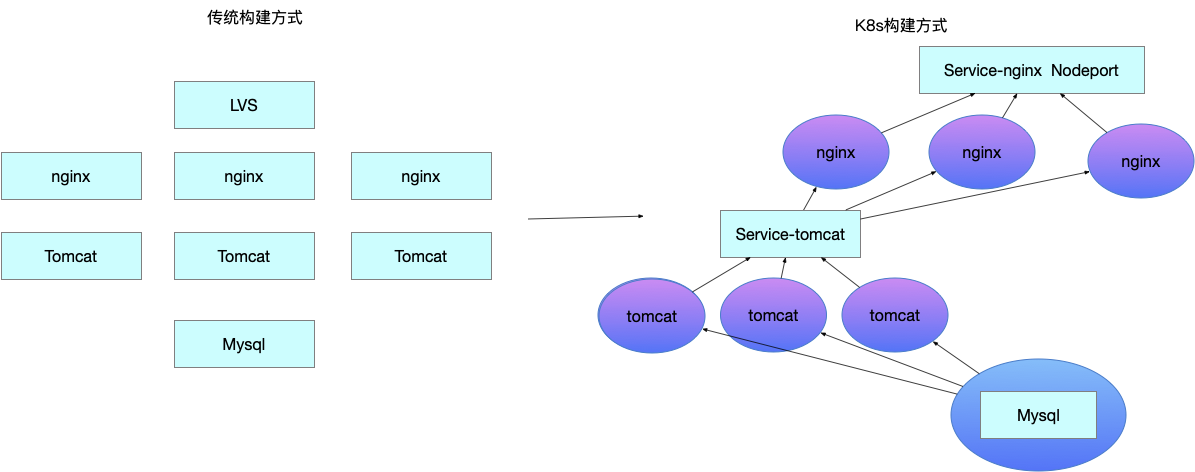
传统方式改造成k8s部署
1.3、网络通讯方式
k8s的网络模型假定了所有Pod都在一个可以直接连通的扁平的网络空间中,这在GCE(Google Compute Engine)里面是现成的网络模型,k8s假定这个网络已经存在。
而在私有云里搭建k8s集群,就不能假定这个网络已经存在,需要自己实现这个网络假设,将不同节点上的docker容器之间的户型访问先打通,然后运行k8s
扁平化:所有的Pod都可以直接访问
1.3.1、同一个Pod内的多个容器之间:localhost
共用容器pause的network,即同一个Pod共享同一个网络命名空间,共享一个linux协议栈
1.3.2、各个Pod之间的通讯,即Pod1至Pod2:overlay network
Flannel是CoreOS团队针对k8s设计的一个网络规划服务,简单来说,他的功能是让集群的不同节点创建的Docker容器都具有全集群唯一的虚拟Ip地址。而且他还能在这些Ip地址之间建立一个覆盖网络(Overlay network),通过这个覆盖网络,将数据包原封不动地传递到目标容器。
1.3.2.1、Flannel方案 整体方案
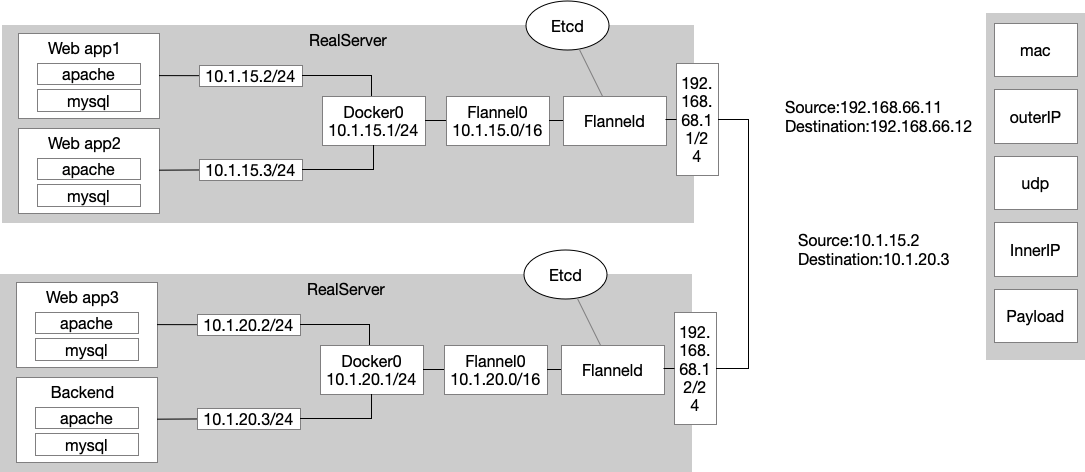
ETCD与Flannel关系:存储管理Flannel可分配的IP地址段资源;监控ECTD中每个Pod的实际地址,并在内存中建立维护Pod节点路由表
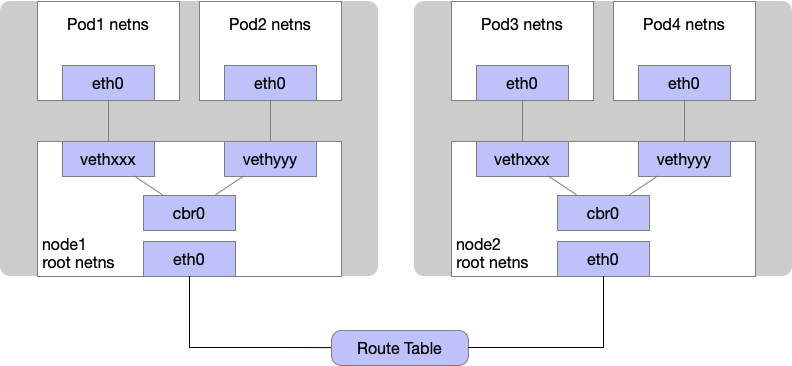
1》Pod1与Pod2不在同一台主机,Pod的地址是与docker0在同一个网段的,但docker0网段与宿主机网卡是两个完全不同的ip网段,并且不同Node之间的通讯只能通过宿主机的物理网卡进行。将Pod的ip和所在Node的ip关联起来,通过这个关联可以让Pod互相访问。
2》Pod1与Pod2在同一台主机,由docker0网桥直接转发请求值Pod2,不需要经过Flannel
示例一、Pod1与Pod2不在同一台主机,跨节点通讯 过程
1.3.3、Pod与Service之间的通讯
各节点的Iptables规则,新版本加入了LVS
1.3.4、Pod到外网
Pod向外网发送请求,查找路由表,转发数据包到宿主机的网卡,宿主网卡完成路由选择后,iptables执行masquerade,把源ip更改为宿主网卡的ip,然后转向外网服务器发送请求
1.3.5、外网访问Pod
通过service访问,NodePort映射
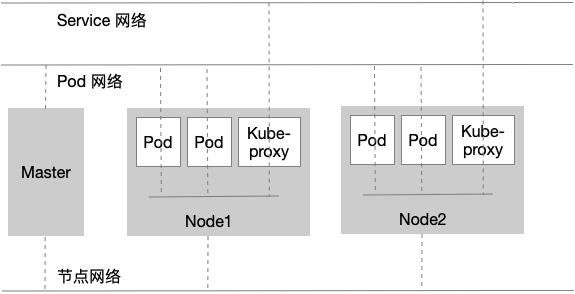
1.4、三层网络
1.5、k8s中Node、Pod、container、service、deployment、rs关系及作用
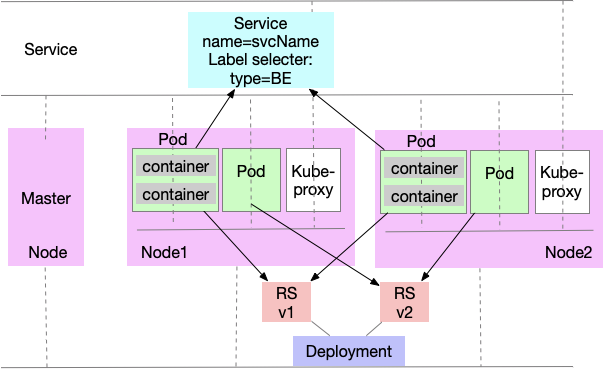
Node:kubectl get node:一台物理机或虚拟机,内部可以有多个Pod
Pod:kubectl get pod -o wide:一个或多个容器的集合
rs:kubectl get rs:管理pod的控制器ReplicaSet
deployment:kubectl get deployment:管理rs,ReplicaSet
Service:kubectl get svc:用于管理不同pod里面的、具有相同label标签的容器(把相同label的归为一类service)
container:具体容器

 浙公网安备 33010602011771号
浙公网安备 33010602011771号