
102302114_比山布·努尔兰_作业4
作业1
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
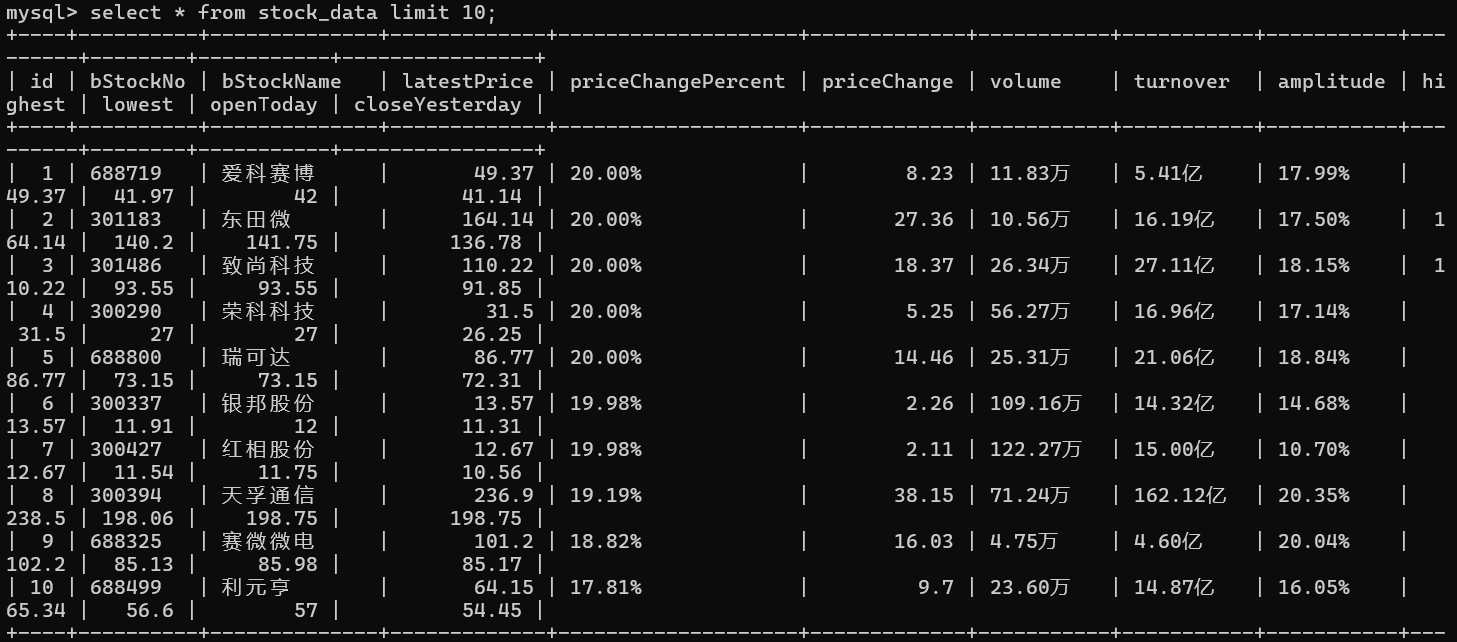
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
作业代码
点击查看代码
import time
import pymysql
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from webdriver_manager.chrome import ChromeDriverManager
# 数据库连接配置
DB_CONFIG = {
"host": "localhost",
"user": "root",
"password": "123456",
"database": "stock_db",
"port": 3306,
"charset": "utf8mb4"
}
# 连接MySQL数据库函数
def get_db_connection():
try:
conn = pymysql.connect(
host=DB_CONFIG["host"],
user=DB_CONFIG["user"],
password=DB_CONFIG["password"],
database=DB_CONFIG["database"],
port=DB_CONFIG["port"],
charset=DB_CONFIG["charset"]
)
print("数据库连接成功!")
return conn
except Exception as e:
print(f"数据库连接失败:{e}")
return None
# 爬取股票数据函数
def crawl_stock_data():
# Chrome配置(我选择的是谷歌浏览器)
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument(
"user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36")
chrome_options.add_argument("--disable-blink-features=AutomationControlled")
# 初始化浏览器
driver = webdriver.Chrome(
service=Service(ChromeDriverManager().install()),
options=chrome_options
)
wait = WebDriverWait(driver, 20) # 延长等待时间
# 目标网址
url = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board"
driver.get(url)
time.sleep(3)
# 板块定位
boards = {
"沪深京A股": '//li[not(ancestor::ul[@class="lsub"])]/a[contains(@href, "#hs_a_board") and contains(text(), "沪深京A股")]',
"上证A股": '//li[not(ancestor::ul[@class="lsub"])]/a[contains(@href, "#sh_a_board") and contains(text(), "上证A股")]',
"深证A股": '//li[not(ancestor::ul[@class="lsub"])]/a[contains(@href, "#sz_a_board") and contains(text(), "深证A股")]'
}
# 连接数据库
conn = get_db_connection()
if not conn:
driver.quit()
return
cursor = conn.cursor()
try:
for board_name, board_xpath in boards.items():
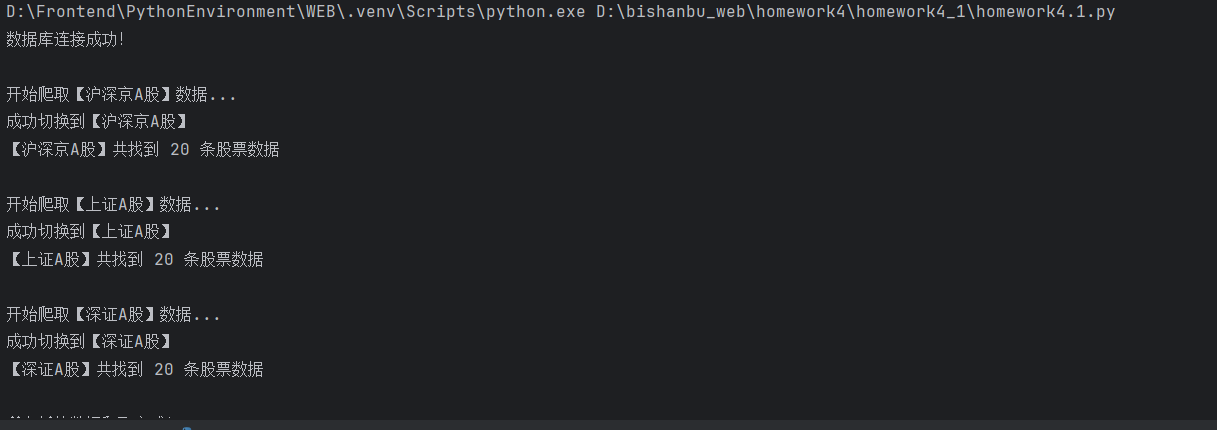
print(f"\n开始爬取【{board_name}】数据...")
# 1. 切换板块
try:
board_btn = wait.until(EC.element_to_be_clickable((By.XPATH, board_xpath)))
driver.execute_script("arguments[0].click();", board_btn)
time.sleep(4)
print(f"成功切换到【{board_name}】")
except Exception as e:
print(f"切换【{board_name}】失败:{str(e)}")
continue
# 2. 提取表格数据
try:
stock_table_xpath = '//tbody[.//a[contains(@href, "quote.eastmoney.com/unify/r/")]]'
# 等待股票表格加载完成
wait.until(EC.presence_of_element_located((By.XPATH, stock_table_xpath)))
table_body = driver.find_element(By.XPATH, stock_table_xpath)
driver.execute_script(
"arguments[0].scrollIntoView({behavior: 'smooth', block: 'end'});",
table_body
)
time.sleep(3) # 等待滚动后加载更多数据
# 获取表格中所有股票行
rows = table_body.find_elements(By.TAG_NAME, "tr")
print(f"【{board_name}】共找到 {len(rows)} 条股票数据")
# 解析每行数据
for row in rows:
cols = row.find_elements(By.TAG_NAME, "td")
if len(cols) < 13: # 这里是为了确保列数完整
continue
stock_data = {
"bStockNo": cols[1].text.strip(),
"bStockName": cols[2].text.strip(),
"latestPrice": cols[4].text.strip(),
"priceChangePercent": cols[5].text.strip(),
"priceChange": cols[6].text.strip(),
"volume": cols[7].text.strip(),
"turnover": cols[8].text.strip(),
"amplitude": cols[9].text.strip(),
"highest": cols[10].text.strip(),
"lowest": cols[11].text.strip(),
"openToday": cols[12].text.strip(),
"closeYesterday": cols[13].text.strip()
}
# 类型转换
for key in stock_data:
if stock_data[key] == "":
stock_data[key] = None
if key in ["latestPrice", "priceChange", "highest", "lowest", "openToday", "closeYesterday"]:
if stock_data[key] is not None:
try:
stock_data[key] = float(stock_data[key])
except ValueError:
stock_data[key] = None
# 插入数据库
sql = """
INSERT INTO stock_data (
bStockNo, bStockName, latestPrice, priceChangePercent, priceChange,
volume, turnover, amplitude, highest, lowest, openToday, closeYesterday
) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
ON DUPLICATE KEY UPDATE
bStockName=%s, latestPrice=%s, priceChangePercent=%s, priceChange=%s,
volume=%s, turnover=%s, amplitude=%s, highest=%s, lowest=%s,
openToday=%s, closeYesterday=%s
"""
sql_params = (
stock_data["bStockNo"], stock_data["bStockName"], stock_data["latestPrice"],
stock_data["priceChangePercent"], stock_data["priceChange"], stock_data["volume"],
stock_data["turnover"], stock_data["amplitude"], stock_data["highest"],
stock_data["lowest"], stock_data["openToday"], stock_data["closeYesterday"],
stock_data["bStockName"], stock_data["latestPrice"], stock_data["priceChangePercent"],
stock_data["priceChange"], stock_data["volume"], stock_data["turnover"],
stock_data["amplitude"], stock_data["highest"], stock_data["lowest"],
stock_data["openToday"], stock_data["closeYesterday"]
)
cursor.execute(sql, sql_params)
conn.commit()
except Exception as e:
print(f"提取【{board_name}】数据失败:{str(e)}")
continue
print("\n所有板块数据爬取完成!")
finally:
cursor.close()
conn.close()
driver.quit()
if __name__ == "__main__":
crawl_stock_data()
运行结果
心得体会
通过这个实验,我大概了解了selenium的工作原理
作业2
要求:
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
作业代码
点击查看代码
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import NoSuchElementException, TimeoutException
import pymysql
import time
import traceback
# 配置MySQL数据库
DB_CONFIG = {
"host": "localhost",
"user": "root",
"password": "123456",
"database": "icourse_db",
"port": 3306,
"charset": "utf8mb4"
}
# 用来操作数据库的函数
def get_mysql_connection():
try:
conn = pymysql.connect(
host=DB_CONFIG["host"],
user=DB_CONFIG["user"],
password=DB_CONFIG["password"],
port=DB_CONFIG["port"],
charset=DB_CONFIG["charset"]
)
cursor = conn.cursor()
# 自动创建数据库
cursor.execute(
f"CREATE DATABASE IF NOT EXISTS {DB_CONFIG['database']} DEFAULT CHARACTER SET {DB_CONFIG['charset']}")
conn.select_db(DB_CONFIG["database"])
print("MySQL数据库连接+创建成功!")
return conn
except Exception as e:
print(f"MySQL连接失败:{e}")
traceback.print_exc()
return None
def init_course_table(conn):
# 初始化课程表
cursor = conn.cursor()
# 核心修复:去掉course_intro的DEFAULT ''
create_table_sql = '''
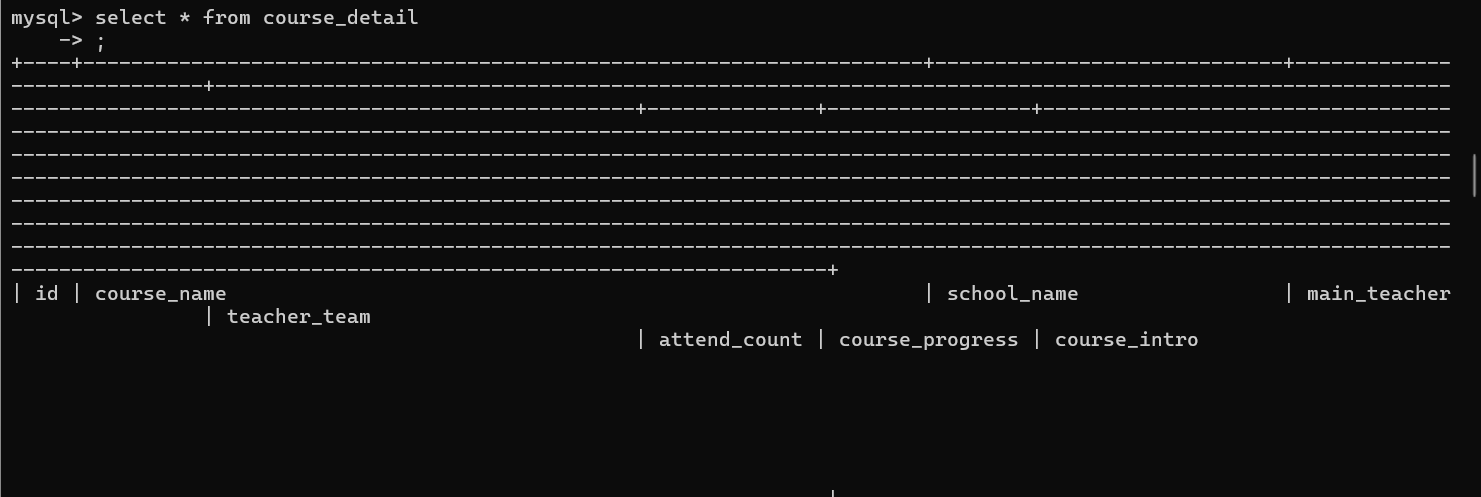
CREATE TABLE IF NOT EXISTS course_detail (
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '自增ID',
course_name VARCHAR(255) NOT NULL COMMENT '课程名称',
school_name VARCHAR(100) DEFAULT '' COMMENT '学校名称',
main_teacher VARCHAR(100) DEFAULT '' COMMENT '主讲教师',
teacher_team VARCHAR(255) DEFAULT '' COMMENT '教师团队',
attend_count VARCHAR(20) DEFAULT '0' COMMENT '参加人数',
course_progress VARCHAR(100) DEFAULT '' COMMENT '课程进度',
course_intro TEXT COMMENT '课程简介' -- 移除DEFAULT ''
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='中国大学MOOC课程表';
'''
cursor.execute(create_table_sql)
conn.commit()
return cursor
def save_course_to_mysql(cursor, conn, course_data):
# 保存课程数据到MySQL
try:
insert_sql = '''
INSERT INTO course_detail (
course_name, school_name, main_teacher, teacher_team,
attend_count, course_progress, course_intro
) VALUES (%s, %s, %s, %s, %s, %s, %s)
'''
sql_params = (
course_data["course_name"],
course_data["school_name"],
course_data["main_teacher"],
course_data["teacher_team"],
course_data["attend_count"],
course_data["course_progress"],
course_data["course_intro"]
)
cursor.execute(insert_sql, sql_params)
conn.commit()
except Exception as e:
conn.rollback()
print(f"保存课程数据失败: {e}")
traceback.print_exc()
# 爬取函数
def init_edge_browser():
#初始化我选择的Edge浏览器
edge_options = webdriver.EdgeOptions()
edge_options.add_experimental_option("excludeSwitches", ["enable-automation"])
edge_options.add_argument("--start-maximized")
driver = webdriver.Edge(options=edge_options)
driver.implicitly_wait(6)
return driver
def mooc_login_operation(driver):
# 登录MOOC
try:
login_trigger_btn = driver.find_element(By.CLASS_NAME, '_3uWA6')
login_trigger_btn.click()
time.sleep(1)
wait = WebDriverWait(driver, 10)
login_iframe_elem = wait.until(
EC.presence_of_element_located((By.XPATH, "//div[@class='ux-login-set-container']//iframe"))
)
driver.switch_to.frame(login_iframe_elem)
mobile_input_box = driver.find_element(By.ID, 'phoneipt')
mobile_input_box.send_keys('18506021680')
pwd_input_box = driver.find_element(By.XPATH, "//input[@placeholder='请输入密码']")
pwd_input_box.send_keys("Nn125513")
login_submit_btn = driver.find_element(By.ID, 'submitBtn')
login_submit_btn.click()
time.sleep(2)
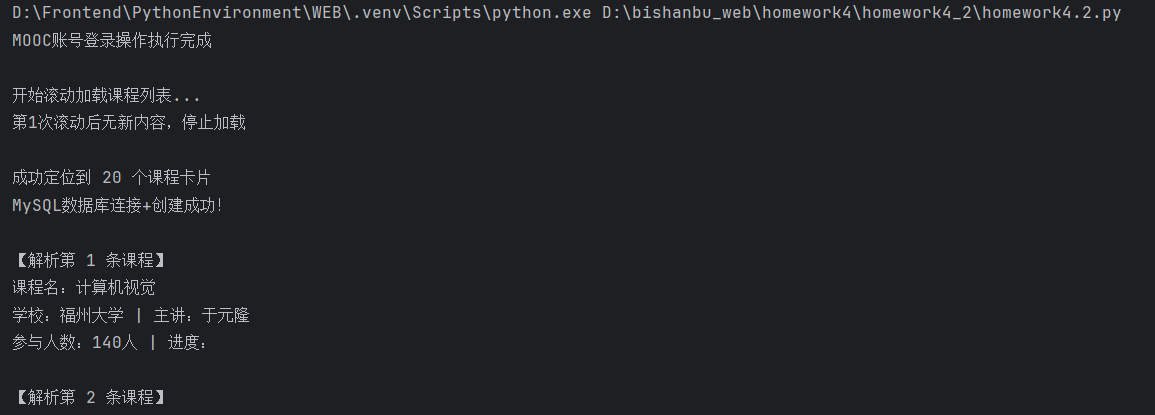
print("MOOC账号登录操作执行完成")
except Exception as e:
print(f"登录流程异常: {e}")
traceback.print_exc()
def scroll_load_more_courses(driver, max_scroll_times=5):
# 滚动加载课程
print("\n开始滚动加载课程列表...")
scroll_times = 0
prev_page_height = driver.execute_script("return document.body.scrollHeight")
while scroll_times < max_scroll_times:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2)
curr_page_height = driver.execute_script("return document.body.scrollHeight")
scroll_times += 1
if curr_page_height == prev_page_height:
print(f"第{scroll_times}次滚动后无新内容,停止加载")
break
prev_page_height = curr_page_height
print(f"第{scroll_times}次滚动完成,当前页面高度: {curr_page_height}")
def parse_single_course_info(course_elem):
# 解析一个个课程
course_info = {
"course_name": "未知课程",
"school_name": "",
"main_teacher": "",
"teacher_team": "",
"attend_count": "0",
"course_progress": "",
"course_intro": ""
}
try:
if course_elem.find_elements(By.CSS_SELECTOR, "div._1vfZ-"):
course_info["course_name"] = course_elem.find_element(By.CSS_SELECTOR, "div._1vfZ-").text
if course_elem.find_elements(By.CSS_SELECTOR, "a._3vJDG"):
course_info["school_name"] = course_elem.find_element(By.CSS_SELECTOR, "a._3vJDG").text
elif course_elem.find_elements(By.CSS_SELECTOR, "a._3t_C8"):
course_info["school_name"] = course_elem.find_element(By.CSS_SELECTOR, "a._3t_C8").text
teacher_elems = course_elem.find_elements(By.CSS_SELECTOR, "a._3t_C8")
if teacher_elems:
course_info["main_teacher"] = teacher_elems[0].text
course_info["teacher_team"] = "、".join([t.text for t in teacher_elems if t.text])
if course_elem.find_elements(By.CSS_SELECTOR, "div._CWjg"):
attend_text = course_elem.find_element(By.CSS_SELECTOR, "div._CWjg").text
course_info["attend_count"] = attend_text.replace('参加', '').strip()
if course_elem.find_elements(By.CSS_SELECTOR, "div._1r-No"):
course_info["course_progress"] = course_elem.find_element(By.CSS_SELECTOR, "div._1r-No").text
if course_elem.find_elements(By.CSS_SELECTOR, "div._3JEMz"):
course_info["course_intro"] = course_elem.find_element(By.CSS_SELECTOR, "div._3JEMz").text
print(f"\n【解析第 {parse_single_course_info.count + 1} 条课程】")
print(f"课程名:{course_info['course_name']}")
print(f"学校:{course_info['school_name']} | 主讲:{course_info['main_teacher']}")
print(f"参与人数:{course_info['attend_count']} | 进度:{course_info['course_progress']}")
parse_single_course_info.count += 1
return course_info
except Exception as e:
print(f"解析单条课程失败: {e}")
traceback.print_exc()
return None
parse_single_course_info.count = 0
# 主执行流程
if __name__ == "__main__":
# 初始化浏览器
driver = init_edge_browser()
driver.get('https://www.icourse163.org/')
time.sleep(1)
# 登录
mooc_login_operation(driver)
# 访问搜索页面
search_url = 'https://www.icourse163.org/search.htm?search=%E8%AE%A1%E7%AE%97%E6%9C%BA#/'
driver.get(search_url)
time.sleep(3)
# 滚动加载课程
scroll_load_more_courses(driver, max_scroll_times=5)
# 获取课程列表
wait = WebDriverWait(driver, 10)
course_list = []
try:
course_list = wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "div._3NYsM"))
)
print(f"\n成功定位到 {len(course_list)} 个课程卡片")
except Exception as e:
print(f"获取课程列表异常: {e}")
traceback.print_exc()
# 连接MySQL并保存数据
if course_list:
# 建立MySQL连接
mysql_conn = get_mysql_connection()
if not mysql_conn:
driver.quit()
exit(1)
# 初始化课程表
mysql_cursor = init_course_table(mysql_conn)
# 遍历解析课程并保存
total_parsed = 0
for course_elem in course_list:
parsed_data = parse_single_course_info(course_elem)
if parsed_data:
save_course_to_mysql(mysql_cursor, mysql_conn, parsed_data)
total_parsed += 1
# 验证MySQL数据
print(f"\n{'*' * 60}")
print(f"数据保存完成,共解析 {total_parsed} 条有效课程")
print(f"存储位置:MySQL -> {DB_CONFIG['database']}.course_detail")
# 查询前3条数据验证
mysql_cursor.execute("SELECT course_name, school_name, attend_count FROM course_detail LIMIT 3")
print("\nMySQL前3条记录预览:")
for idx, record in enumerate(mysql_cursor.fetchall(), 1):
print(f"{idx}. 课程:{record[0]} | 学校:{record[1]} | 人数:{record[2]}")
# 关闭MySQL连接
mysql_cursor.close()
mysql_conn.close()
else:
print("\n未找到任何课程卡片,跳过数据库操作")
# 关闭浏览器
print(f"\n程序执行完成,5秒后自动关闭浏览器...")
time.sleep(5)
driver.quit()
运行结果



心得体会
做完这个实验我是第一次切身感受到了代码的强大,原来代码真的可以像人一样去找到网站搜索框去搜索信息,真的很震撼。
作业3
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
开通MapReduce服务
购买集群

购买弹性公网

配置安全组

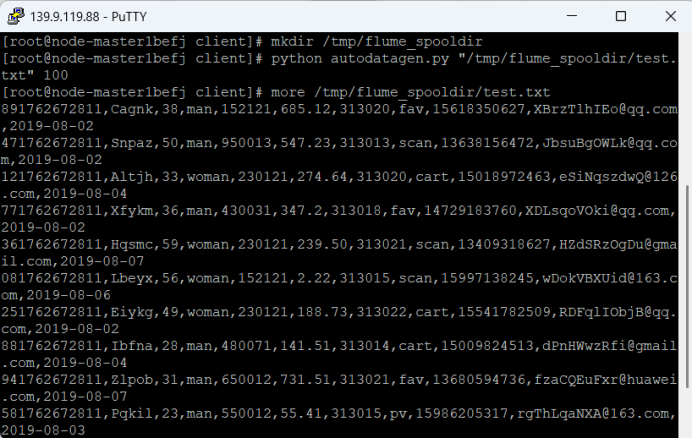
Python脚本生成测试数据
ssh远程连接并Python脚本生成测试数据
配置Kafka
安装Kafka客户端

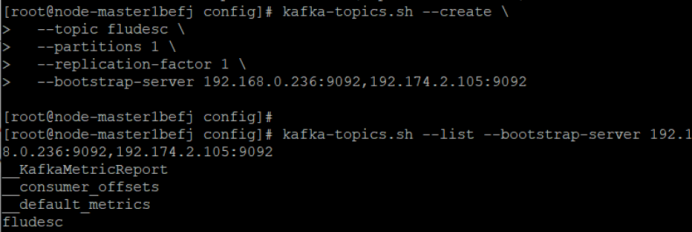
创建并查看topic信息
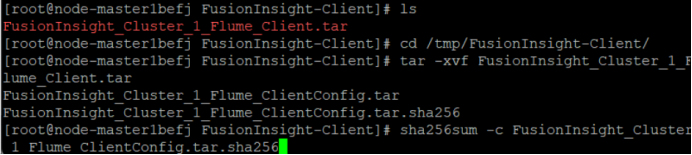
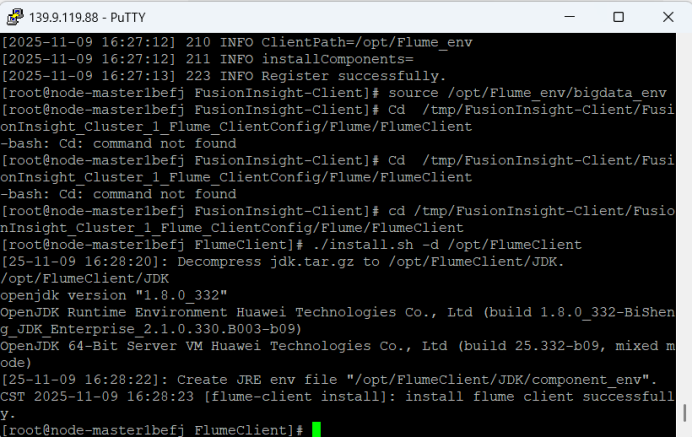
安装Flume客户端
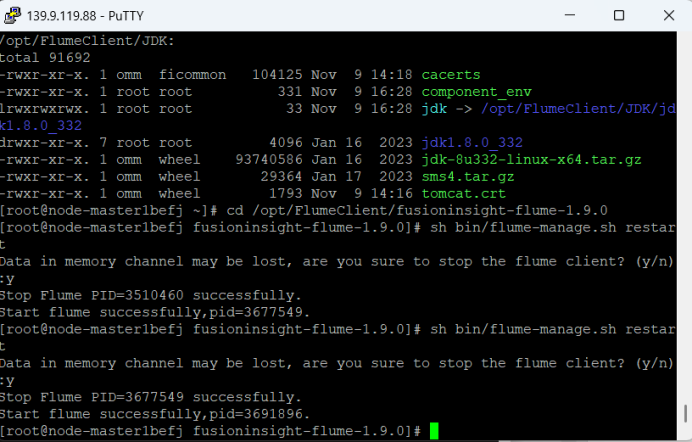
配置Flume采集数据
心得体会
通过这个实验,我学会了怎么使用华为云上的Kafka、Flume等工具帮助我计算一些复杂的案例。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号