
102302114_比山布·努尔兰_作业3
作业1
指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。实现单线程和多线程的方式爬取
作业代码
`import requests
from bs4 import BeautifulSoup
import os
import threading
import time
if not os.path.exists('homework3.1.images'):
os.makedirs('homework3.1.images') # 若不存在images文件夹,则创建
此函数的目的是解析网页的url,生成bs4对象并获取每个img文件的路径
def get_image_urls(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36 Edg/142.0.0.0'
}
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
img_tags = soup.find_all('img')
# print(img_tags)
# 此列表存储网页中每个img元素的绝对路径
image_urls = []
for img in img_tags:
src = img.get('src')
# 这是里为了避免返回相对路径而导致报错
if src and src.startswith('http'):
image_urls.append(src)
return image_urls
此函数是开始下载单线程下的img文件
def download_single_thread(image_urls):
# 记录时间是单纯为了计算出下载完所有图片所需要的总时长
start_time = time.time()
# 这里直接生成元组,记录列表中每个元素的索引,索引是为了每个图片的命名需要
for index, img_url in enumerate(image_urls):
try:
# 设置10秒时为了避免请求时间过长
response = requests.get(img_url, timeout=10)
if response.status_code == 200: # 请求成功
# 直接用jpg格式保存图片
save_path = f'homework3.1.images/single_{index}.jpg'
with open(save_path, 'wb') as f:
f.write(response.content)
print(f'单线程:已下载 {img_url} → 保存至 {save_path}')
else:
# 如果请求失败则要返回状态码,并要寻找错误
print(f'单线程:请求 {img_url} 失败,状态码 {response.status_code}')
except Exception as e:
print(f'单线程:下载 {img_url} 出错 → {e}')
end_time = time.time()
print(f'单线程总耗时:{end_time - start_time:.2f} 秒')
这个是运行多线程时每个函数所要执行的函数
def download_single_image(img_url, index):
try:
response = requests.get(img_url, timeout=10)
if response.status_code == 200:
save_path = f'homework3.1.images/multi_{index}.jpg'
with open(save_path, 'wb') as f:
f.write(response.content)
print(f'多线程:已下载 {img_url} → 保存至 {save_path}')
else:
print(f'多线程:请求 {img_url} 失败,状态码 {response.status_code}')
except Exception as e:
print(f'多线程:下载 {img_url} 出错 → {e}')
此函数是开始下载多线程下的img文件
def download_multi_thread(image_urls):
start_time = time.time()
# 此列表存储每个子线程
threads = []
# 创建并启动线程
for index, img_url in enumerate(image_urls):
t = threading.Thread(target=download_single_image, args=(img_url, index))
threads.append(t)
t.start()
# 让主线程等待所有已启动的子线程执行完毕
for t in threads:
t.join()
end_time = time.time()
print(f'多线程总耗时:{end_time - start_time:.2f} 秒')
if name == 'main':
url = 'http://www.weather.com.cn/index.shtml'
image_urls = get_image_urls(url)
print(f'共提取到 {len(image_urls)} 个图片URL\n')
print('===== 开始单线程下载 =====')
download_single_thread(image_urls)
print('\n===== 开始多线程下载 =====')
download_multi_thread(image_urls)`
心得体会
感觉多线程代码执行的时间更加短一些。
作业2
爬取新浪股票中的股票信息
作业代码
stock_spider.py
`import scrapy
import json
from ..items import StockItem
class StockSpider(scrapy.Spider):
name = 'stock_spider'
allowed_domains = ['vip.stock.finance.sina.com.cn']
start_urls = [
'https://vip.stock.finance.sina.com.cn/quotes_service/api/json_v2.php/Market_Center.getHQNodeData?page=1&num=40&sort=changepercent&asc=0&node=hs_a&symbol=&_s_r_a=init'
]
def parse(self, response):
try:
stock_list = json.loads(response.text)
self.logger.info(f"从API获取到 {len(stock_list)} 条股票数据")
except json.JSONDecodeError as e:
self.logger.error(f"JSON解析失败:{e}")
return
for stock in stock_list:
item = StockItem()
item['bStockNo'] = stock.get('code', '').strip()
item['bStockName'] = stock.get('name', '').strip()
item['latestPrice'] = float(stock.get('trade', 0)) if stock.get('trade') else None
item['priceChange'] = float(stock.get('pricechange', 0)) if stock.get('pricechange') else None
item['priceChangePercent'] = f"{stock.get('changepercent', 0)}%" if stock.get('changepercent') else None
volume_value = stock.get('volume')
item['volume'] = str(volume_value).strip() if volume_value is not None else ''
turnover_value = stock.get('turnover')
item['turnover'] = str(turnover_value).strip() if turnover_value is not None else ''
item['amplitude'] = f"{stock.get('amplitude', 0)}%" if stock.get('amplitude') else None
item['highest'] = float(stock.get('high', 0)) if stock.get('high') else None
item['lowest'] = float(stock.get('low', 0)) if stock.get('low') else None
item['openToday'] = float(stock.get('open', 0)) if stock.get('open') else None
item['closeYesterday'] = float(stock.get('preclose', 0)) if stock.get('preclose') else None
if item['bStockNo'] and item['bStockName']:
yield item`
pipelines.py
`# sina_stock_crawler/pipelines.py
import pymysql
from itemadapter import ItemAdapter
class SinaStockCrawlerPipeline:
def __init__(self, host, user, password, db):
self.host = host
self.user = user
self.password = password
self.db = db
@classmethod
def from_crawler(cls, crawler):
return cls(
host=crawler.settings.get('MYSQL_HOST'),
user=crawler.settings.get('MYSQL_USER'),
password=crawler.settings.get('MYSQL_PASSWORD'),
db=crawler.settings.get('MYSQL_DATABASE')
)
def open_spider(self, spider):
self.conn = pymysql.connect(
host=self.host,
user=self.user,
password=self.password,
database=self.db,
charset='utf8mb4'
)
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
# 定义SQL插入语句
sql = """
INSERT INTO stock_info (
bStockNo, bStockName, latestPrice, priceChangePercent, priceChange,
volume, turnover, amplitude, highest, lowest, openToday, closeYesterday
) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
# 提取Item中的数据,并处理可能的空值
adapter = ItemAdapter(item)
values = (
adapter.get('bStockNo'),
adapter.get('bStockName'),
float(adapter.get('latestPrice')) if adapter.get('latestPrice') else None,
adapter.get('priceChangePercent'),
float(adapter.get('priceChange')) if adapter.get('priceChange') else None,
adapter.get('volume'),
adapter.get('turnover'),
adapter.get('amplitude'),
float(adapter.get('highest')) if adapter.get('highest') else None,
float(adapter.get('lowest')) if adapter.get('lowest') else None,
float(adapter.get('openToday')) if adapter.get('openToday') else None,
float(adapter.get('closeYesterday')) if adapter.get('closeYesterday') else None,
)
try:
self.cursor.execute(sql, values)
self.conn.commit()
except Exception as e:
self.conn.rollback()
self.logger.error(f"Database error: {e}")
return item
def close_spider(self, spider):
self.cursor.close()
self.conn.close()`
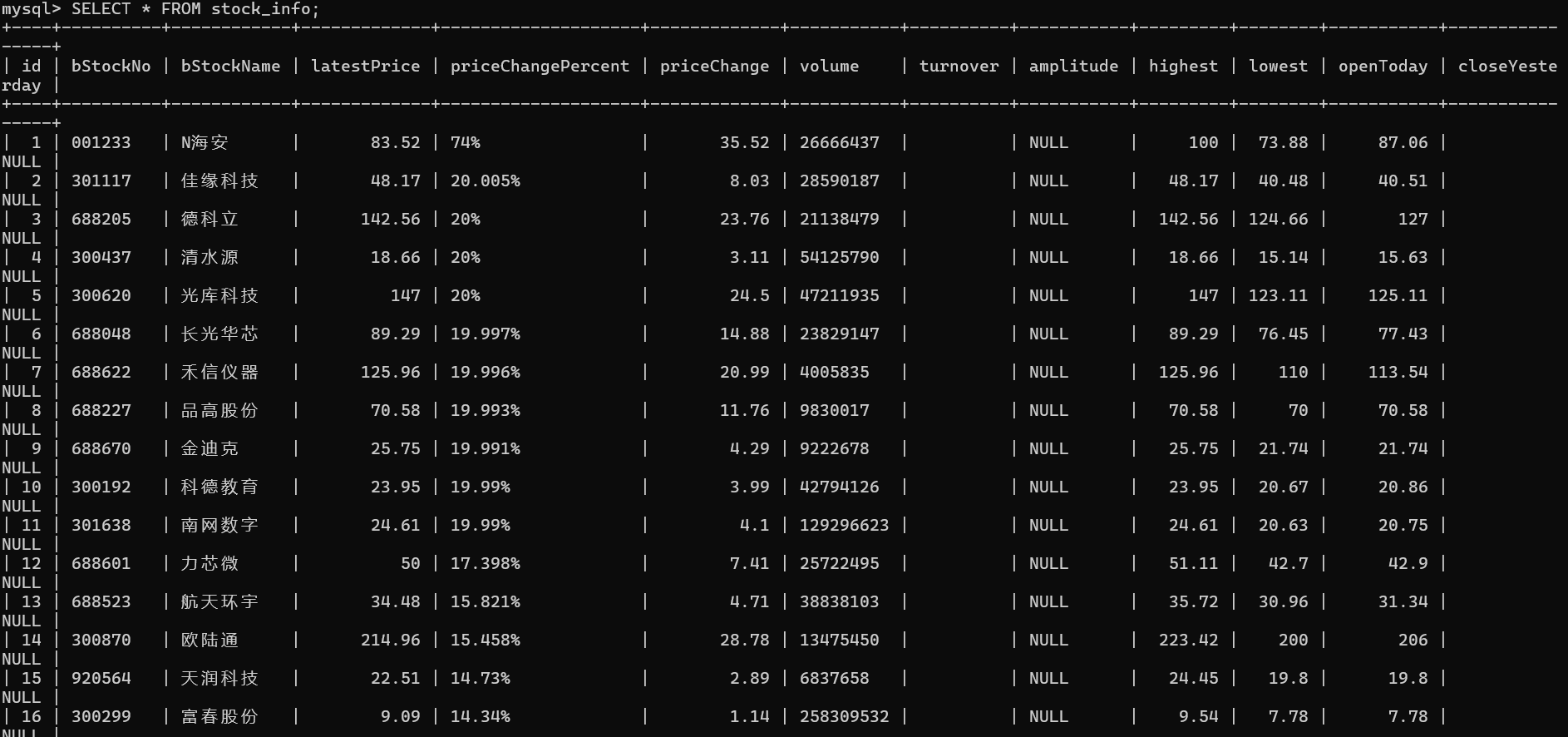
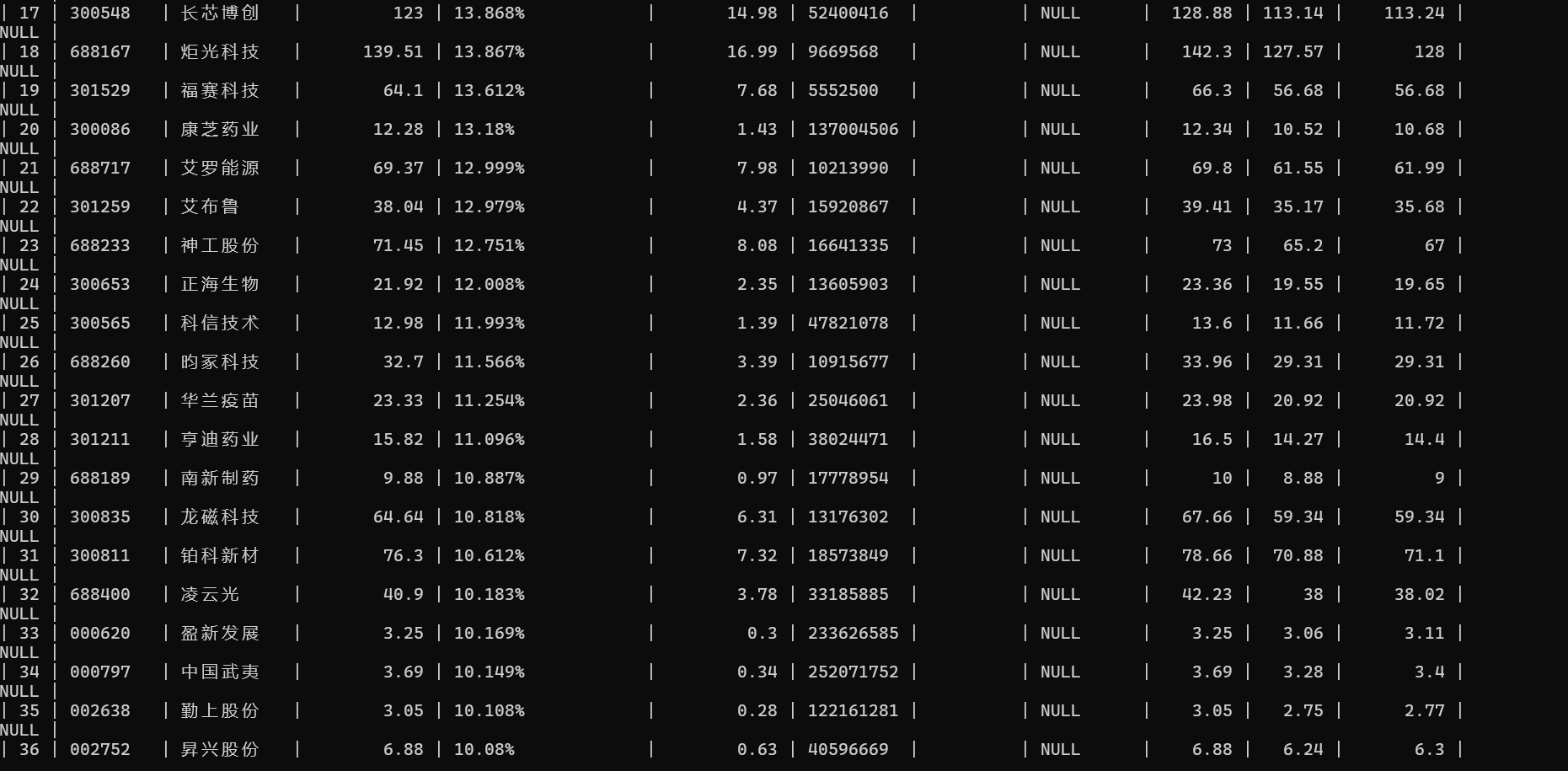
运行结果
心得体会
刚开始以为页面是静态的一直爬不下来,后面才发现是动态加载的,这才成功爬取。
作业3
爬取外汇网站数据
作业代码
boc_spider.py
`import scrapy
from ..items import BocExchangeItem
class BocSpider(scrapy.Spider):
name = 'boc_spider'
allowed_domains = ['boc.cn']
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
def parse(self, response):
data_rows = response.xpath('//div[@class="publish"]//table//tr[position()>1]')
for row in data_rows:
item = BocExchangeItem()
item['Currency'] = row.xpath('./td[1]/text()').get('').strip()
item['TBP'] = row.xpath('./td[2]/text()').get('').strip()
item['CBP'] = row.xpath('./td[3]/text()').get('').strip()
item['TSP'] = row.xpath('./td[4]/text()').get('').strip()
item['CSP'] = row.xpath('./td[5]/text()').get('').strip()
item['Time'] = row.xpath('./td[6]/text()').get('').strip()
if item['Currency']:
yield item`
pipelines.py
`# Define your item pipelines here
Don't forget to add your pipeline to the ITEM_PIPELINES setting
See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import pymysql
class MySQLPipeline:
def init(self, host, user, password, db):
self.host = host
self.user = user
self.password = password
self.db = db
@classmethod
def from_crawler(cls, crawler):
return cls(
host=crawler.settings.get('MYSQL_HOST'),
user=crawler.settings.get('MYSQL_USER'),
password=crawler.settings.get('MYSQL_PASSWORD'),
db=crawler.settings.get('MYSQL_DATABASE')
)
def open_spider(self, spider):
self.conn = pymysql.connect(
host=self.host,
user=self.user,
password=self.password,
database=self.db,
charset='utf8mb4'
)
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
sql = """
INSERT INTO boc_exchange (Currency, TBP, CBP, TSP, CSP, Time)
VALUES (%s, %s, %s, %s, %s, %s)
"""
self.cursor.execute(sql, (
item['Currency'], item['TBP'], item['CBP'],
item['TSP'], item['CSP'], item['Time']
))
self.conn.commit()
return item
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
class BocExchangePipeline:
def process_item(self, item, spider):
return item`
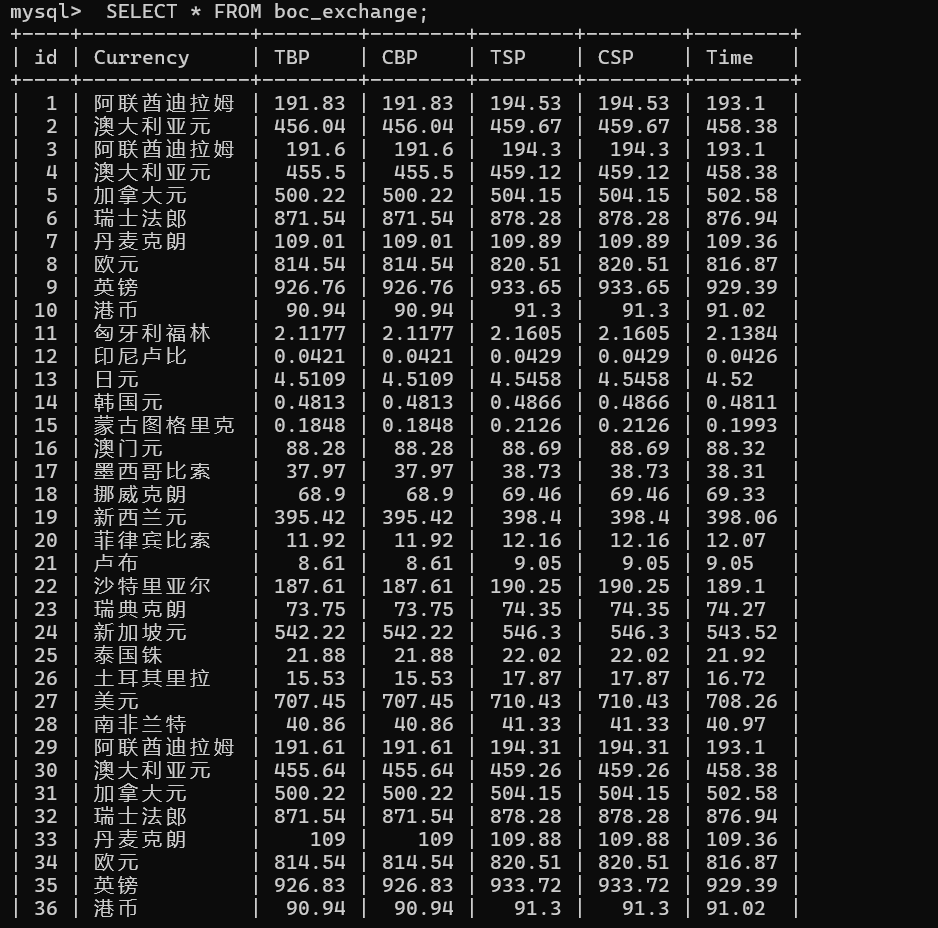
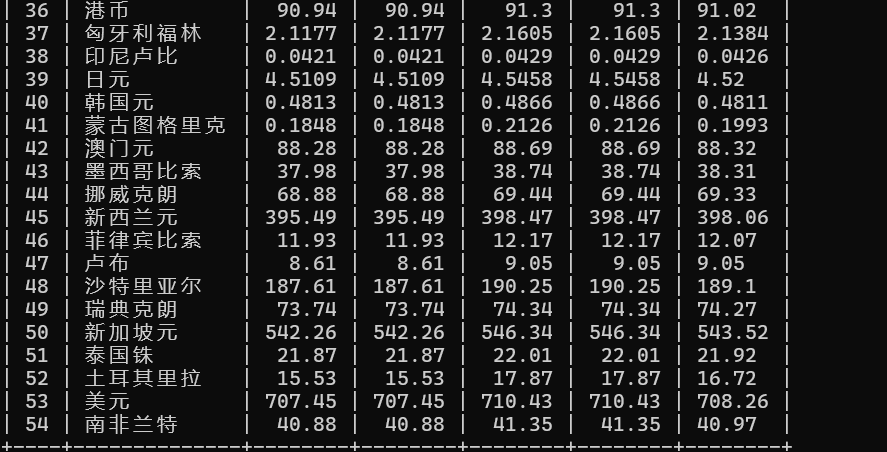
运行结果

心得体会
通过实验2和实验3,我学会了scrapy爬取网站信息的流程和用法,也学会了怎么数据存储到Mysql这样的数据库中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号