ArrayList、ArrayDeque与LinkedList区别
在之前的两篇文章中主要分析了 Java 栈的缺点 ,为什么不推荐使用 Java 栈 ,以及 为什么不推荐直接使用 ArrayDeque 代替 Java Stack 。更多内容点击下方链接前去查看。
接口 Deque 的子类 ArrayDeque ,作为栈使用时比 Stack 快,因为原来的 Java 的 Stack 继承自 Vector,而 Vector 在每个方法中都加了锁,而 Deque 的子类 ArrayDeque 并没有锁的开销。
接口 Deque 还有另外一个子类 LinkedList。LinkedList 基于双向链表实现的双端队列,ArrayDeque 作为队列使用时可能比 LinkedList 快。
ArrayDeque vs ArrayList
ArrayList 的 add() 方法
public boolean add(E e) {
// 是否越界检查
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
// 确保数组不越界
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
// 计算最小需要容量
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
// 检查是否需要扩容
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
// ArrayList是扩容为1.5倍
grow(minCapacity);
}
一看,挺简单是不?当然不是,虽然赋值只需要一句,但是重头戏在 ensureCapacityInternal(size + 1) 方法上!
这里不具体对这个方法进行展开,因为涉及到扩容相关逻辑,简单来说就是:
当向ArrayList中加入一个值的时候,它首先会进行容量判断,如果当前数组长度不够了,就要先扩容,然后才能添加,这个过程比较耗时间!
ArrayDeque 的 add() 方法
public boolean add(E e) {
addLast(e);
return true;
}
public void addLast(E e) {
if (e == null)
throw new NullPointerException();
elements[tail] = e;
// 判断是否需要扩容,这里是最妙的地方!
if ( (tail = (tail + 1) & (elements.length - 1)) == head)
// 扩容双倍
doubleCapacity();
}
// 扩容方法
private void doubleCapacity() {
assert head == tail;
int p = head;
int n = elements.length;
int r = n - p; // number of elements to the right of p
int newCapacity = n << 1;
if (newCapacity < 0)
throw new IllegalStateException("Sorry, deque too big");
Object[] a = new Object[newCapacity];
System.arraycopy(elements, p, a, 0, r);
System.arraycopy(elements, 0, a, r, p);
elements = a;
head = 0;
tail = n;
}
在 ArrayDeque 中维护了一个 head 和 tail 指针,分别指向元素头(head)和元素尾的下一个位置(tail)
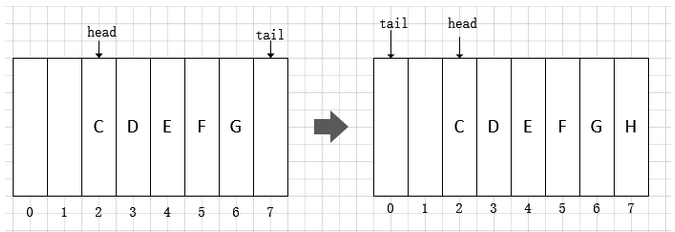
如果当前tai已经到达数组最后,一旦插入后,tail就会指向下标0的位置,这样就形成了一个环状数组结构,之所以这么设计是因为 ArrayDeque 可以同时当栈和队列来使用。
然后讲讲上面方法中的精髓:
if ( (tail = (tail + 1) & (elements.length - 1)) == head)
doubleCapacity();
/**
上面条件判断可以分成两部分来看:
1)tail = (tail + 1) & (elements.length - 1)
- 这里是一个赋值操作,tail的值完全取决于后面的 & 运算
- 首先要交代一个前提就是:ArrayDeque在初始化容量的时候,通过一系列的移位运算保证了数组的长度为2^n(这部分可参考源码)
- 所以这里 (elements.length-1) 就是:01111...11 这样的数
(1) 如果(tail + 1) <= (elements.length - 1): 运算结果就是 (tail + 1)
(2) 如果(tail + 1) == elements.length(比如100...000): 运算结果就是0,即tail指向数组第一个位置(环状数组)
所以这里就可以保证 tail 赋值正确
2)tail == head
这个条件就是判断当前数组是否已满!如果tail指向了head的位置,就代表数组满了,此时就需要进行扩容 doubleCapacity()
*/
所以通过简单的比较,这个进行大量的元素插入的时候,ArrayDeque会相对效率更高。
ArrayList 的 remove() 方法
ArrayList 的删除方法
public E remove(int index) {
// 合法检查
rangeCheck(index);
modCount++;
// 待删除值
E oldValue = elementData(index);
// 确定需要移动的步数
int numMoved = size - index - 1;
// 如果不是删除最后一个元素,就需要整体复制数组(最后一个删除不需要移动,这也很好理解)
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
// 原位置直接复制null,让垃圾收集器工作
elementData[--size] = null; // clear to let GC do its work
// 返回删除值
return oldValue;
}
ArrayDeque 的 remove() 方法
这个方法和ArrayList相比基本相同,只不过ArrayList可以支持删除任意下标元素,而ArrayDeque只能删除头尾元素
public E remove() {
return removeFirst();
}
// 这里就看 removeLast()和 removeFirst()基本一样
public E pollLast() {
// 获取待删除位置下标, tail指向下一个待插入的位置
int t = (tail - 1) & (elements.length - 1);
@SuppressWarnings("unchecked")
// 获取待删除元素
E result = (E) elements[t];
if (result == null)
return null;
// 待删除位置赋值null
elements[t] = null;
// tail指针移到待删除位置
tail = t;
return result;
}
两者查询都支持随机查询,效率差不多。但如果是需要频繁增删头尾元素则使用ArrayDeque,需要支持随机删除则使用ArrayList
接口 Deque
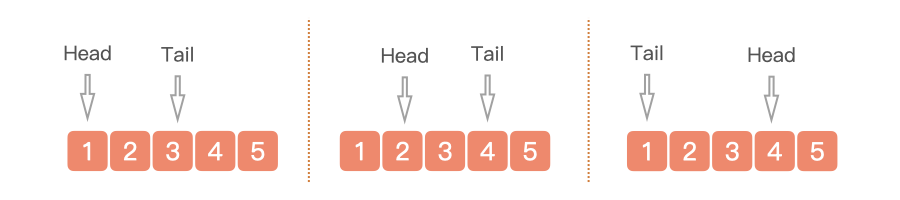
接口 Deque 继承自 Queue 即队列, 在 Java 中队列有两种形式,单向队列( AbstractQueue ) 和 双端队列( Deque ),单向队列效果如下所示,只能从一端进入,另外一端出去。

而今天主要介绍双端队列( Deque ), Deque 是双端队列的线性数据结构, 可以在两端进行插入和删除操作,效果如下所示。

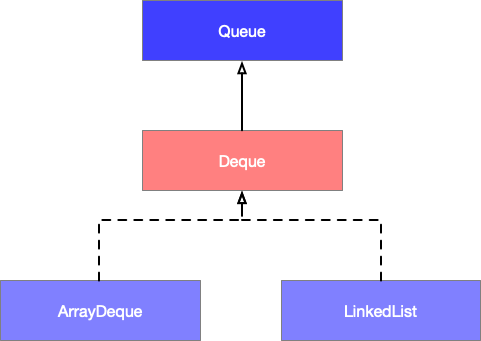
双端队列( Deque )的子类分别是 ArrayDeque 和 LinkedList,ArrayDeque 基于数组实现的双端队列,而 LinkedList 基于双向链表实现的双端队列,它们的继承关系如下图所示。
接口 Deque 和 Queue 提供了两套 API ,存在两种形式,分别为抛出异常,和不抛出异常,返回一个特殊值 null 或者布尔值 ( true | false )。
| 操作类型 | 抛出异常 | 返回特殊值 |
|---|---|---|
| 插入 | addXXX(e) | offerXXX(e) |
| 移除 | removeXXX() | pollXXX() |
| 查找 | element() | peekXXX() |
ArrayDeque
ArrayDeque 是基于(循环)数组的方式实现双端队列,数组初始化容量为 16(JDK 8),结构图如下所示。
ArrayDeque 具有以下特点:
- 因为双端队列只能在头部和尾部插入或者删除元素,所以时间复杂度为
O(1),但是在扩容的时候需要批量移动元素,其时间复杂度为O(n) - 扩容的时候,将数组长度扩容为原来的 2 倍,即
n << 1 - 数组采用连续的内存地址空间,所以查询的时候,时间复杂度为
O(1) - 它是非线程安全的集合
LinkedList
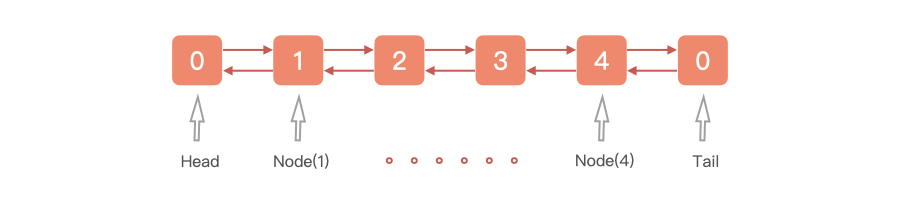
LinkedList 基于双向链表实现的双端队列,它的结构图如下所示。
LinkedList 具有以下特点:
LinkedList是基于双向链表的结构来存储元素,所以长度没有限制,因此不存在扩容机制- 由于链表的内存地址是非连续的,所以只能从头部或者尾部查找元素,查询的时间复杂为
O(n),但是 JDK 对LinkedList做了查找优化,当我们查找某个元素时,若index < (size / 2),则从head往后查找,否则从tail开始往前查找 , 但是我们在计算时间复杂度的时候,常数项可以省略,故时间复杂度O(n)
Node<E> node(int index) {
// size >> 1 等价于 size / 2
if (index < (size >> 1)) {
// form head to tail
} else {
// form tail to head
}
}
- 链表通过指针去访问各个元素,所以插入、删除元素只需要更改指针指向即可,因此插入、删除的时间复杂度
O(1) - 它是非线程安全的集合
最后汇总一下 ArrayDeque 和 LinkedList 的特点如下所示:
| 集合类型 | 数据结构 | 初始化及扩容 | 插入/删除时间复杂度 | 查询时间复杂度 | 是否是线程安全 |
|---|---|---|---|---|---|
| ArrqyDeque | 循环数组 | 初始化:16 扩容:2 倍 | 0(n) | 0(1) | 否 |
| LinkedList | 双向链表 | 无 | 0(1) | 0(n) | 否 |
为什么 ArrayDeque 比 LinkedList 快
了解完数据结构特点之后,接下来我们从两个方面分析为什么 ArrayDeque 作为队列使用时可能比 LinkedList 快。
- 从速度的角度:
ArrayDeque基于数组实现双端队列,而LinkedList基于双向链表实现双端队列,数组采用连续的内存地址空间,通过下标索引访问,链表是非连续的内存地址空间,通过指针访问,所以在寻址方面数组的效率高于链表。 - 从内存的角度:虽然
LinkedList没有扩容的问题,但是插入元素的时候,需要创建一个Node对象, 换句话说每次都要执行new操作,当执行new操作的时候,其过程是非常慢的,会经历两个过程:类加载过程 、对象创建过程。- 类加载过程
- 会先判断这个类是否已经初始化,如果没有初始化,会执行类的加载过程
- 类的加载过程:加载、验证、准备、解析、初始化等等阶段,之后会执行
<clinit>()方法,初始化静态变量,执行静态代码块等等
- 对象创建过程
- 如果类已经初始化了,直接执行对象的创建过程
- 对象的创建过程:在堆内存中开辟一块空间,给开辟空间分配一个地址,之后执行初始化,会执行
<init>()方法,初始化普通变量,调用普通代码块
- 类加载过程
接下来我们通过 算法动画图解 | 被 "废弃" 的 Java 栈,为什么还在用 文章中 LeetCode 算法题:有效的括号,来验证它们的执行速度,以及在内存方面的开销,代码如下所示:
class Solution {
public boolean isValid(String s) {
// LinkedList VS ArrayDeque
// Deque<Character> stack = new LinkedList<Character>();
Deque<Character> stack = new ArrayDeque<Character>();
// 开始遍历字符串
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
// 遇到左括号,则将其对应的右括号压入栈中
if (c == '(') {
stack.push(')');
} else if (c == '[') {
stack.push(']');
} else if (c == '{') {
stack.push('}');
} else {
// 遇到右括号,判断当前元素是否和栈顶元素相等,不相等提前返回,结束循环
if (stack.isEmpty() || stack.poll() != c) {
return false;
}
}
}
// 通过判断栈是否为空,来检查是否是有效的括号
return stack.isEmpty();
}
}
正如你所看到的,核心算法都是一样的,通过接口 Deque 来访问,只是初始化接口 Deque 代码不一样。
// 通过 LinkedList 初始化
Deque<Character> stack = new LinkedList<Character>();
// 通过 ArrayDeque 初始化
Deque<Character> stack = new ArrayDeque<Character>();

结果如上所示,无论是在执行速度、还是在内存开销上 ArrayDeque 的性能都比 LinkedList 要好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号