[初赛前置顶]NOIP提高组初赛难题总结
NOIP提高组初赛难题总结
注:笔者开始写本文章时noip初赛新题型还未公布,故会含有一些比较老的内容,敬请谅解.
约定:
- 若无特殊说明,本文中未知数均为整数
- [表达式] 表示:在表达式成立时它的值为1,否则值为0
- x!表示x的阶乘
- 整数除法无特殊说明,默认下取整

阅读程序
#include <cstdio>
using namespace std;
const int N = 110;
bool isUse[N];
int n, t;
int a[N], b[N];
bool isSmall(){
for (int i = 1; i <= n; ++i)
if (a[i] != b[i]) return a[i] < b[i];
return false;
}
bool getPermutation(int pos){
if (pos > n){
return isSmall();
}
for (int i = 1; i <= n; ++i){
if (!isUse[i]){
b[pos] = i; isUse[i] = true;
if (getPermutation(pos + 1)){
return true;
}
isUse[i] = false;
}
}
return false;
}
void getNext(){
for (int i = 1; i <= n; ++i){
isUse[i] = false;
}
getPermutation(1);
for (int i = 1; i <= n; ++i){
a[i] = b[i];
}
}
int main(){
scanf("%d%d", &n, &t);
for (int i = 1; i <= n; ++i){
scanf("%d", &a[i]);
}
for (int i = 1; i <= t; ++i){
getNext();
}
for (int i = 1; i <= n; ++i){
printf("%d", a[i]);
if (i == n) putchar('\n'); else putchar(' ');
}
return 0;
}
输入1:6 10 1 6 4 5 3 2
输入2:6 200 1 5 3 4 2 6
答案:
输出1:2 1 3 5 6 4
输出2:3 2 5 6 1 4
分析:
首先我们看出,这是求
第一问可以直接模拟,第二问直接模拟循环次数太多,可以用康托展开求解。先介绍一下康托展开:
知识点补充:康托展开
康托展开:把全排列按字典序排序,给出一个长度为n的全排列,求它是第几个长度为n的全排列。
我们以1 5 3 4 2 6 为例,先求字典序比它小的全排列有多少个
- 第1位是1,没有第一位比它小的全排列
- 第2位是5,后面的位里比它小的有2,3,4,那么以2,3,4作为第二位的全排列一定比它的字典序小。又因为第1位就小的全排列已经算过了,我们只需要算第1位为1,第2位为2,3,4的全排列数量。第1位固定,第2位3面4位可以任意排,有4!种。故答案为3*4!
- 第3位是3,后面比它小的有2,根据上一问的结论,答案为1*3!
- 第4位是4,后面比它小的有2,同理答案为1*2!
- 第5位是2,后面没有比它小的数,答案为0*1!
- 由于前5位已经确定,可以直接推出第6位,所以这一位不用考虑,为0
- 比它小的排列有\(0*5!+3*4!+1*3!+1*2!+0*1!=104\)个,所以它是第105个排列
综上,我们可以给出康托展开的公式.给出一个长度为n的序列\(a\),\(a\)在排列中的个数为
逆康托展开:把全排列按字典序排序,求长度为n的全排列中,第k个全排列
我们以k=281,n=6为例。
- 我们求小于它的排列的个数,即281-1=280.设S表示当前还未确定位置的数的集合。初始时S=
- \(280/5!=2\cdots\cdots40\),S={1,2,3,4,5,6}那么我们要找S集合中小于它的数有2个的数,即S集合中的第3个数3. 那么排列的第1位为3,把3移出S
- \(40/4!=1\cdots\cdots16\),S={1,2,4,5,6},同理,排列的第2位为S集合中的第1+1个数2,
- \(16/3!=2 \dots \dots 4\),S={1,4,5,6},排列的第3位为5
- \(4/2!=2 \cdots \cdots 0\),S={1,4,6},排列的第4位为6
- \(0/1!=1 \cdots \cdots 0\),S={1,4} 排列的第5为为1
- 最后一位就是S集合中剩下的那个数,为4
- 综上,排列为3 2 5 6 1 4
那么对于这道题,我们只需要先对1 5 3 4 2 6做康托展开,加上200,再逆康托展开即可
#include<iostream>
using namespacestd;
int main() {
int n, m;
cin >> n >> m;
int x = 1;
int y = 1;
int dx = 1;
int dy = 1;
int cnt = 0;
while (cnt != 2) {
cnt = 0;
x = x + dx;
y = y + dy;
if (x == 1 || x == n) {
++cnt;
dx = -dx;
}
if (y == 1 || y == m) {
++cnt;
dy = -dy;
}
}
cout << x << " " << y<< endl;
return 0;
}
输入1: 4 3
输入2: 2017 1014
答案:
输出1: 1 3
输出2: 2017 1
分析:
同样也是第1问模拟,第二问找规律。
发现\(x,y\)坐标的移动可以分离来考虑。x相当于长度为n-1的线段上的一个动点,从坐标1出发到坐标n不停往返。y相当于长度为m-1的线段上的一个动点,从1出发到m不停往返。两动点的速度相等.当某个时刻,两动点同时到达边界(坐标1或n,m)的时候结束.
容易发现,相遇的时候走的距离为为\(s=\mathrm{lcm} (n-1,m-1)\)
以从1到n或从n到1为走了一次,那么x走了\(\frac{s}{n-1}\)次,y走了\(\frac{s}{m-1}\)次。当\(\frac{s}{m-1}\)为偶数时恰好回到起点,输出1.否则输出n(或m).
以\(n=2017,m=1014\)为例,\(n-1=2016,m-1=1013,s=2016\),\(s/(n-1)=1\),为奇数,因此输出2017.\(s/(m-1)=2\)为偶数,因此输出1
#include <iostream>
using namespace std;
const int SIZE = 20;
int data[SIZE];
int n, i, h, ans;
void merge(){
data[h-1] = data[h-1] + data[h];
h--;
ans++;
}
int main(){
cin>>n; h = 1; data[h] = 1; ans = 0;
for (i = 2; i <= n; i++){
h++;
data[h] = 1;
while (h > 1 && data[h] == data[h-1])
merge();
}
cout<<ans<<endl;
}
(1)
输入:8
输出: d【错误 正确答案为:7】
(2)
输入:2012
输出: ds【错误 正确答案为:2004】
#include<iostream>
#include<cstring>
#include<string>
using namespace std;
const int SIZE=10000;
const int LENGTH=10;
int n,m,a[SIZE][LENGTH];
int h(int u,int v){
int ans,i;
ans=0;
for(i=1;i<=n;i++)
if( a[u][i]!=a[v][i])
ans++;
return ans;
}
int main(){
int sum,i,j;
cin>>n;
memset(a,0,sizeof(a));
m=1;
while(1){
i=1;
while( (i<=n) && (a[m][i]==1) )i++;
if(i>n)break;
m++;
a[m][i]=1;
for(j=i+1;j<=n;j++)
a[m][j]=a[m-1][j];
}
sum=0;
for(i=1;i<=m;i++)
for(j=1;j<=m;j++)
sum+=h(i,j);
cout<<sum<<endl;
return 0;
}
输入:7
输出:dsf【错误 正确答案为:57344】
程序填空
有 n 个木块排成一行,从左到右依次编号为 1~n。你有 k 种颜色的油漆,其中第 i 种颜色的油漆足够涂 ci 个木块。所有油漆刚好足够 涂满所有木块,即 c1+c2+...+ck=n。相邻两个木块涂相同色显得很难看,所以你希望统计任意两个相邻木块颜色不同的着色方案。(1 <= k <= 15, 1 <= ci <= 5)
输入:第一行为一个正整数 k,第二行包含 k 个整数 c1, c2, ... , ck。
输出:输出一个整数,即方案总数模 1,000,000,007 的结果。
#include<iostream>
#include<cstdio>
#define ll long long
#define mod 1000000007
using namespace std;
ll f[16][16][16][16][16][6];
int x[6],n;
bool mark[16][16][16][16][16][6];
ll dp(int a,int b,int c,int d,int e,int k){
ll t=0;
if( (1) )return f[a][b][c][d][e][k];
if(a+b+c+d+e==0)return 1;
if(a) (2);
if(b) (3) ;
if(c) (4);
if(d) (5);
if(e)t+=e*dp(a,b,c,d+1,e-1,5);
mark[a][b][c][d][e][k]=1;
return f[a][b][c][d][e][k]=(t%mod);
}
int main(){
scanf("%d",&n);
for(int i=1;i<=n;i++) {
int t;
scanf("%d",&t);
x[t]++;
}
printf("%lld",dp(x[1],x[2],x[3],x[4],x[5],0));
return 0;
}
答案:
(1) mark[a][b][c][d][e][k]
(2) (a-(k==2))*dp(a-1,b,c,d,e,1)
(3) (b-(k==3))*dp(a+1,b-1,c,d,e,2)
(4) (c-(k==4))*dp(a,b+1,c-1,d,e,3)
(5) (d-(k==5))*dp(a,b,c+1,d-1,e,4)
解析:
如果直接记录每种油漆剩余的个数的话,状态数是\(5^{15}\)无法存储。考虑到剩余个数相同的油漆是等价的,可以压缩处理。那么题目中的a,b,c,d,e就是剩余个数1,2,3,4,5的油漆个数。例如取了剩余2个的某种油漆之后,剩余1个的油漆增加了1个,因此变成a+1和b-1.k记录上一个选的颜色,减去1是防止和上一个选的某种油漆一样。
序列重排)全局数组变量 a 定义如下:
const int SIZE = 100;
int a[SIZE], n;
它记录着一个长度为 n 的序列 a[1], a[2], …, a[n]。现在需要一个函数,以整数 p (1 ≤ p ≤ n)为参数,实现如下功能:将序列 a 的前 p 个数与后 n – p 个数对调,且不改变这 p 个数(或 n – p 个数)之间的相对位置。例如, 长度为 5 的序列 1, 2, 3, 4, 5,当 p = 2 时重排结果为 3, 4, 5, 1, 2。有一种朴素的算法可以实现这一需求,其时间复杂度为 O(n)、空间复杂度为 O(n):
void swap1(int p){
int i, j, b[SIZE];
for (i = 1; i <= p; i++)
b[ (1) ] = a[i]; //(2 分)
for (i = p + 1; i <= n; i++)
b[i - p] = a[i];
for (i = 1; i <= n; i++)
a[i] = b[i];
}
我们也可以用时间换空间,使用时间复杂度为 O(n2)、空间复杂度为 O(1)的算法:
void swap2(int p){
int i, j, temp;
for (i = p + 1; i <= n; i++) {
temp = a[i];
for (j = i; j >= (2) ; j--) //(2 分)
a[j] = a[j - 1];
(3) = temp; //(2 分)
}
}
事实上,还有一种更好的算法,时间复杂度为 O(n)、空间复杂度为 O(1):
void swap3(int p){
int start1, end1, start2, end2, i, j, temp;
start1 = 1;
end1 = p;
start2 = p + 1;
end2 = n;
while (true) {
i = start1; j = start2;
while ((i <= end1) && (j <= end2)) {
temp = a[i]; a[i] = a[j]; a[j] = temp; i++;
j++;
}
if (i <= end1)
start1 = i;
else if ( (4) ) { //(3 分)
start1 = (5) ; //(3 分)
end1 = (6) ; //(3 分)
start2 = j;
}else break;
}
}
(1) p-i
(2) n-p+1
(3) a[i-p]
(4) j <=end2
(5) i
(6) j-1
最后两空由于涉及到边界易错。
一只小猪要买N件物品(N不超过1000)。它要买的所有商品在两家商店里都有卖。第i件物品在第一家商店的价格是a[i],在第二家商店的价格是b[i],两个价格都不小于0且不超过10000。如果在第一家商店买的物品的总额不少于50000,那么在第一家店买的物品都可以打95折(价格变为原来的0.95倍)。求小猪买齐所有物品所需最小的总额。
输入:第一行一个数N。接下来N行,每行两个数。第i行的两个数分别代表a[i],b[i]。
输出:输出一行一个数,表示最少需要的总额,保留两位小数。
试补全程序。
#include <cstdio>
#include <algorithm>
using namespace std;
const int Inf = 1000000000;
const int threshold = 50000;
const int maxn = 1000;
int n, a[maxn], b[maxn];
bool put_a[maxn];
int total_a, total_b;
double ans;
int f[threshold];
int main(){
scanf("%d", &n);
total_a = total_b = 0;
for (int i = 0; i < n; ++i){
scanf("%d%d", a + i, b + i);
if (a[i] <= b[i]) total_a += a[i];
else total_b += b[i];
}
ans = total_a + total_b;
total_a = total_b = 0;
for (int i = 0; i < n; ++i){
if ( (1) ){
put_a[i] = true;
total_a += a[i];
}else{
put_a[i] = false;
total_b += b[i];
}
}
if ( (2) ){
printf("%.2f", total_a * 0.95 + total_b);
return 0;
}
f[0] = 0;
for (int i = 1; i < threshold; ++i)f[i] = Inf;
int total_b_prefix = 0;
for (int i = 0; i < n; ++i){
if (!put_a[i]){
total_b_prefix += b[i];
for (int j = threshold - 1; j >= 0; --j){
if ( (3))
ans = min(ans, (total_a + j + a[i]) * 0.95 + (4) );
f[j] = min(f[j] + b[i], j >= a[i] ? :(5) : Inf);
}
}
}
printf("%.2f", ans);
return 0;
}
(1) b[i] >=a[i]* 0.95
(2) total_a >=50000
(3) total_a+j+a[i] >= threshold && f[j] != Inf
(4) f[j]+total_b-total_b_prefix
(5) f[j-a[i]]
感觉是做过的最有水平的一道程序填空。(1)(2)是先贪心,如果A中打折后更便宜,就先选上。但只选这些不一定能达到打折标准,为了能打折,可能要选择一些贵的A来达到标准。只考虑没被贪心选中的商品,设\(f_j\)表示A中选的总价为\(j\)时,B中选的最小价格.因此(total_a + j + a[i])就表示目前
已经选的A中商品总价。f[j]+total_b-total_b_prefix表示目前已经选的B中商品总价,后面的差分是\(i\)之后B中选的商品。对于\(f_j\)显然有递推式\(f_j=\min(f_{j}+b_i,f_{j-a_i})\),分别表示选B第\(i\)个和选A第\(i\)个。
(烽火传递)烽火台又称烽燧,是重要的军事防御设施,一般建在险要处或交通要道上。一旦有敌情发生,白天燃烧柴草,通过浓烟表达信息;夜晚燃烧干柴,以火光传递军情。在某两座城市之间有n个烽火台,每个烽火台发出信号都有一定的代价。为了使情报准确地传递,在连续m个烽火台中至少要有一个发出信号。现输入n、m和每个烽火台发出信号的代价,请计算总共最少花费多少代价,才能使敌军来袭之时,情报能在这两座城市之间准确传递。
例如,有5个烽火台,它们发出信号的代价依次为1、2、5、6、2,且m为3,则总共最少花费的代价为4,即由第2个和第5个烽火台发出信号。
#include <stdio.h>
#define SIZE 100
int
n, m, r, value[SIZE], heap[SIZE],
pos[SIZE], home[SIZE], opt[SIZE];
//heap[i]表示用顺序数组存储的堆heap中第i个元素的值
//pos[i]表示opt[i]在堆heap中的位置,即heap[pos[i]]=opt[i]
//home[i]表示heap[i]在序列opt中的位置,即opt[home[i]]=heap[i]
void swap(int i, int j){
//交换堆中的第i个和第j个元素
int tmp;
pos[home[i]] = j;
pos[home[j]] = i;
tmp = heap[i];
heap[i] = heap[j];
heap[j] = tmp;
tmp = home[i];
home[i] = home[j];
home[j] = tmp;
}
void add(int k){
//在堆中插入opt[k]
int i;
r++;
(1) ;
pos[k] = r;
home[r]= (2) ;
i = r;
while ((i > 1) && (heap[i] < heap[i / 2])) {
swap(i, i / 2);
i /= 2;
}
}
void remove(int k){
//在堆中删除opt[k]
int i, j;
i = pos[k];
swap(i, r);
r--;
if (i == r + 1)
return;
while ((i > 1) && (heap[i] < heap[i / 2])) {
swap(i, i / 2);
i /= 2;
}
while (i + i <= r) {
if ((i + i + 1 <= r) && (heap[i + i + 1] < heap[i + i]))
j = i + i + 1;
else
(3) ;
if (heap[i] > heap[j]) {
(4) ;
i = j;
}else break;
}
}
int main(){
int i;
scanf("%d %d", &n, &m);
for (i = 1; i <= n; i++)
scanf("%d", &value[i]);
r = 0;
for (i = 1; i <= m; i++) {
opt[i] = value[i];
add(i);
}
for (i = m + 1; i <= n; i++) {
opt[i] =(5) ;
remove( (6) );
add(i);
}
printf("%d\n", heap[1]);
return 0;
}
(1) heap[r] =opt[k]
(2) k
(3) j=i+i
(4) swap(i,j)
(5) value[i]+heap[1]
(6) i-m
堆的维护部分按照定义去做就可以了。维护一个小根堆,堆顶就是最优答案。先把前m个数插入入。然后依次处理剩下的数,每次先取堆顶得到之前的最优答案heap[1],然后加上第i个发出信号的代价value[i],那么一个可行解就是value[i]+heap[1]插入堆中,取堆顶就相当于取min操作。注意我们转移过来的距离不能超过\(m\),所以要及时弹出之前的答案。
其实看成DP更好理解,\(f_i\)表示覆盖前\(i\)个且第\(i\)个发出信号的最小代价,\(f_i=\min_{i-m<j<i}(f_{j}+a_i)\),不知道为什么不用单调队列而是用堆去维护。
问题求解
知识点总结
全排列\(n!=\prod_{i=1}^n i\)
排列数\(\begin{bmatrix}n \\ m \end{bmatrix}=\frac{n!}{(n-m)}\)
组合数\(\binom{n}{m}=\frac{n!}{m!(n-m)!}\)
可重复排列数:设元素\(i\)有\(a_i\)个:\(\frac{(\sum a_i)!}{i!}\)
圆排列数:\((n-1)!\) (因为环可以旋转)
卡特兰数
组合意义:\(n\)个点的无标号二叉树数量。
递推式:\(c_n=\sum_{i=0}^{n-1}c_ic_{n-1-i},c_0=c_1=1\)
通项公式:\(c_n=\frac{\binom{2n}{n}}{n+1}\)
第一类斯特林数
组合意义:\(n\)个不同的数(有标号)分成\(m\)个圆排列的方案数
递推式:\(s_{n,m}=s_{n-1,m-1}+(n-1)s_{n-1,m}\)
前一项表示\(n\)单独组成一个圆排列,后一项表示插入之前的\(m\)个圆排列,在每个圆排列的每个数后插入都构成一种方案,故乘\((n-1)\)。
关于斯特林数的许多性质超出了初赛范围(如果有的话),详情可查阅《具体数学》
第二类斯特林数
组合意义:\(n\)个不同的数分成\(m\)个集合的方案数
递推式:\(s_{n,m}=s_{n-1,m-1}+ms_{n-1,m},s_{n,1}=s_{n,n}=1\) 前一项表示\(n\)单独组成一个集合,后一项表示插入之前的集合,从\(m\)个中选一个,故乘\(m\)。
插板法
插板法:
非降路径
不接触路径:
例题
小陈现有2个任务A,B要完成,每个任务分别有若干步骤如下:A=a1->a2->a3,B=b1->b2->b3->b4->b5.在任何时候,小陈只能专心做某个任务的一个步骤.但是如果愿意,他可以在做完手中任务的当前步骤后,切换至另一个任务,从上次此任务第一个未做的步骤继续.每个任务的步骤顺序不能打乱,例如……a2->b2->a3->b3……是合法的,而……a2->b3->a3->b2……是不合法的.小陈从B任务的b1步骤开始做,当恰做完某个任务的某个步骤后,就停工回家吃饭了.当他回来时,只记得自己已经完成了整个任务A,其他的都忘了.试计算小陈饭前已做的可能的任务步骤序列共有多少种.
答案:70
首先因为第一个做b1,完成了a.我们先构建原始的序列b1->a1->a2->a3,然后再从b2->b3->b4->b5中选一些插进去,保证这几个顺序递增。可以插在b1后的4个空里。
因为必须要按顺序插进去,我们可以把b2,b3,b4看成无标号的来求方案数。相当于把m个球放到n个位置上,每个位置的球数>=0.根据插板法,答案是\(\binom{n+m-1}{n-1}=\binom{n+m-1}{m}\),
最终答案是\(\sum_{m=1}^4 \binom{m+3}{m}=70\)
现有一只青蛙,初始时在 n 号荷叶上。当它某一时刻在 k 号荷叶上时,下一时刻将等概 率地随机跳到 1, 2, …, k 号荷叶之一上,直至跳到 1 号荷叶为止。当 n = 2 时,平均一共跳 2 次;当 n = 3 时,平均一共跳 2.5 次。则当 n = 5 时,平均一共跳几次。
答案:\(\frac{37}{12}\)
其实就是期望跳的次数.设\(f_i\)表示已经跳到i号荷叶,期望跳到1号荷叶的次数。
那么\(f_1=0\)
\(f_2=\frac{1}{2}(f_1+f_2)+1\).因为在2号荷叶,下一步跳到1和2的概率均为1/2,根据期望的线性性。答案就是1和2荷叶跳到终点的期望次数之和乘1/2,再加上1步。因为\(f_1\)已知,可以解出\(f_2=2\)
同理有
\(f_3=\frac{1}{3}{(f_1+f_2+f_3)}+1\)
\(f_4=\frac{1}{4}{(f_1+f_2+f_3+f_4)}+1\)
\(f_5=\frac{1}{5}{(f_1+f_2+f_3+f_4+f_5)}+1\)
最终可以解出\(f_5=\frac{37}{12}\)
将2006 个人分成若干不相交的子集,每个子集至少有 3 个人,并且:
(1)在每个子集中,没有人认识该子集的所有人.
(2)同一子集的任何 3 个人中,至少有 2 个人互不认识.
(3)对同一子集中任何 2 个不相识的人,在该子集中恰好只有 1 个人认识这两个人.则满足上述条件的子集最多能有___________个
答案:401
转化成图论。每个人看成点,每个相识关系看作一条边。那么条件就变成了。
- 没有一个结点与其他所有点相连
- 每个子集中,任何三个结点中,至少两个不直接相连
- 同一子集中的任意不直接相连的两点,彼此之间有只通过一个结点的路径
然后尝试从小到大枚举每个子集的点数和边数。发现5个点时,连成一个五边形恰好满足条件。那么每5个人分一组,答案就是401.
从 1 到 2018 这 2018 个数中,共有__个包含数字8的数
答案:544
因为可能包含多个数字8,容易算重。考虑补集转化,求不包含数字8的数字个数。
一位数:8个
两位数:$8 \times 9 $个
三位数:\(8 \times 9 \times 9\)个
四位数,[1000,1999]之内的:\(1\times 8 \times 9 \times 9\)个
四位数,[2000,2018]内的,2008,2018两个
以上一共是1474个。答案为:2018-1474=544个
本题中,我们约定布尔表达式只能包含p,q,r三个布尔变量,以及“与”(∧)、“或”(∨)、“非”(¬)三种布尔运算。如果无论p,q,r如何取值,两个布尔表达式的值总是相同,则称它们等价。例如(p∨q)∨r和p∨(q∨r)等价,p∨¬p和q∨¬q也等价;而p∨q和p∧q不等价。那么两两不等价的布尔表达式最多有()个
答案:
每个布尔表达式可以看成\((p,q,r)\)到\(\{0,1\}\)的映射. 考虑\((p,q,r)\)的取值共有8种,而由每个三元组的值共有2种。不同的表达式共有\(2^8=256\)种.
某个国家的钱币面值有1,7,72,73共计四种,如果要用现金付清10015元的货物,假设买卖双方各种钱币的数量无限且允许找零,那么交易过程中至少需要流通______张钱币。
答案:35
首先我们应该优先用面值尽量大的
\(10015/343=29 \dots \dots 68\),所以用29张7^3的
\(68 /49 =1 \dots 19\),所以用1张7^2的
19可以用2张7元+5张1元凑出,但是这样不如给对方3张7元再找回2张1元,只需要5张货币。
总共29+1+5=35
书架上有21本书,编号从1 到 21 从中选4 本,其中每两本的编号都不相邻的选法一共有__种
答案:3060
反着考虑,先放好另外17本书,再把4本插进去.18个空选4个,答案是\(\binom{18}{4}=3060\)
一个人站在坐标(0, 0)处,面朝x轴正方向。第一轮,他向前走1单位距离,然后右转;第二轮,他向前走2单位距离,然后右转;第三轮,他向前走3单位距离,然后右转......他一直这么走下去。请问第2017轮后,他的坐标是__
答案:(1009,1008)
找规律:第1步,X轴+1,第2步,Y轴-2,第3步X轴-3,第4步,Y轴+4,第5步,X轴+5,...,(x轴每变化4次都为0)
假设走的步数为n, \(n \ \mathrm{mod}\ 4\) 余1是X轴+n,余2是Y轴-n,余3是X轴-n,余0是Y轴+n,2017%4=1,2016%4=0,
所以x轴是1-3+5-7+9...+2017=1-3+5-7+9...-2015+2017=1009,*
y轴是-2+4-6+8-10...+2016=1008。所以最终坐标是(1009,1008)
由5个不同的节点构成的树有()种
答案:125
知识点补充:Prufer序列
Prufer序列,可以用来求解无根树计数的问题。
(1)无根树转化为 Prufer 序列。
找到编号最小的叶子节点(度数为1)并删除,序列中添加与之相连的节点编号,重复执行直到只剩下2个节点。
如下图的树对应的 Prufer序列就是3,5,1,3。
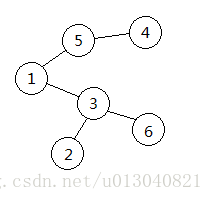
(2)Prufer序列转化为无根树。
设点集 S={1,2,3,...,n},每次取出 Prufer 序列中最前面的元素u,在S中找到编号最小的没有在 Prufer 序列中出现的元素v,连边(u,v),并在Prufer序列中删掉u,v,最后在 S 中剩下两个节点,给它们连边。最终得到的就是无根树。
常用结论:
(1)一个n个点的有标号无根树唯一对应一个长度为n-2的Prufer序列
(2)\(n\)个点的有标号无根树有\(n^{n-2}\)个
根据第1个结论,第2个结论显然成立
(3) Prufer 序列中某个编号出现的次数就等于这个编号的节点在无根树中的度数-1
每个非叶子节点编号的出现次数就是它的儿子个数,即度数-1
(4)\(n\)个节点的度依次为\(d_1,d_2,d_3 \dots d_n\)的有标号无根树的个数为: $$\begin{aligned} \frac{(n-2)!}{(d_1-1)(d_2-1)(d_3-1) \cdots (d_n-1)} \end{aligned}$$
根据第3个结论,此时prufer序列中编号i出现了\(d_i-1\)次,那么就是一个长度为n-2的可重排列
回到上述题目
由五个不同的节点构成的树有()种
\(n=5,n^{n-2}=125\)
7 个同学围坐一圈,要选 2 个不相邻的作为代表,有多少种选法
选第一个人7种,再选一个4种.答案为\(\frac{7 \times 4}{2}=14\)
假设 h(n) 代表一串由 a、b、c 组成的文字的长度位 n 的字符串方案数,并且保证没有连续的 a,求 h(10)
答案:29460
没有什么太好的组合方法,只能DP然后手动模拟.
取火柴游戏的规则如下:一堆火柴有N根,A、B两人轮流取出。每人每次可以取1 根或2 根,最先没有火柴可取的人为败方,另一方为胜方。如果先取者有必胜策略则记为1,先取者没有必胜策略记为0。当N 分别为100,200,300,400,500 时,先取者有无必胜策略的标记顺序为
答案:11010
可以推广到\(n\)根火柴,每个人可以取\(1\)~\(m\)根.\(n \bmod (m+1) \equiv 0\)时先手必败,否则先手必胜.因为先手可以先取到模\(m+1\)为0的情况,然后后手取\(x\)个,他就取\(m+1-x\)个.这样只有300的情况是必败的
如下图,有一个无穷大的的栈S,在栈的右边排列着1,2,3,4,5共五个车厢。其中每个车厢可以向左行走,也可以进入栈S让后面的车厢通过。现已知第一个到达出口的是3号车厢,请写出所有可能的到达出口的车厢排列总数
答案:8
答案有误?应该是9
将数组{32, 74, 25, 53, 28, 43, 86, 47}中的元素按从小到大的顺序排列,每次可以交换任意两个元素,最少需要交换()次
答案:5
交换任意两个元素求最小交换次数,用选择排序,直接模拟可以做。另外,也可以用置换的思想考虑。离散化后从\(i\)向\(a_i\)连边,那么交换两个元素只有两个元素在一个环(轮换)上才有意义,且一个\(k\)个点的环至少需要交换\(k-1\)次才能排好序。因此答案是n-轮换个数
交换相邻两个元素求最小交换次数,用冒泡排序,答案就是逆序对个数
一个有 2^5 个元素的集合有 25个不同子集(包含空集),现在要在这 2^5个集合中取出若干集合(至少一个),使得它们的交集的元素个数为 2,求取法的方案数
答案:2180
二项式反演,交集大小恰好为2不好求,考虑求交集大小至少为2的方案数。设\(f_n\)表示交集大小恰好为\(n\)的方案数,\(g_n\)表示交集大小至少为\(n\)的方案数。那么有\(g_n=\sum_{i=n}^5\binom{i}{n}f_i\),根据二项式反演,\(f_n=\sum_{i=n}^5(-1)^{i-n}\binom{i}{n}g_i\). 那么只需要求出\(g_i\)就好了。我们先选\(i\)个数作为最小的交集,剩下的数组成\(2^{5-i}\)个集合,从这些集合中任选一些集合(至少1个)
并上这\(i\)个数,它们的交集大小一定不小于\(i\).因此 \(g_i=\binom{5}{i} 2^{2^{5-i}}-1\)
算出\(g_2\dots g_5\),再套公式就可以求出\(f_5\)
选择题
知识点补充:特征根方程
给出一个数列\(f\)满足递推式\(f_n=pf_{n-1}+qf_{n-2},f_1=a,f_2=b\),求它的通项公式.
递推式的通项不好求,但是等比数列的通项很好求.假如等比数列\(\{g_n\}\)满足递推式,就可以快速求出通项了。
另外我们还可以得到一个结论:
已知等比数列\(\{a_n\},\{b_n\},\{c_n\} \cdots\),那么它们的线性组合\(\{\alpha \cdot a_n + \beta \cdot b_n + \gamma \cdot c_n\cdots\}\)也满足递推式。
那么考虑如何构造这个等比数列\({g_n}\).
设\(g_n=x^{n-1}\)(设的是n-1还是n要看数列是从0开始还是从1开始,从1开始的话设n-1比较方便),带入原递推式,那么\(x^{n-1}=px^{n-2}+qx^{n-3}\),
该方程就是特征根方程
那么\({g_{1}}_{n}=x_1^{n-1},{g_{2}}_{n} =x_2^{n-1}\)都满足递推式,根据前面的结论,\(f_n=\alpha x_1^n+\beta x_2^n\)就是\(f\)的通项公式
\(\alpha,\beta\)如何确定?因为\(f_1=a,f_2=b\),代入可知$$\begin{cases} \alpha+\beta=a \ \alpha x_1+ \beta x_2=b \end{cases}$$
解这个方程组,就可以确定\(\alpha,\beta\)
\(f_0=0,f_1=1,f_{n+1}=\frac{f_{n}+f_{n-1}}{2}\),则随着\(i\)的增大,\(f_i\)将接近于()。
A.\(\frac{1}{2}\) B.\(\frac{2}{3}\) C.\(\frac{\sqrt{5}-1}{2}\) D.\(1\)
答案:B
把方程改成标准形式,\(f_n=\frac{1}{2}f_{n-1}+\frac{1}{2}f_{n-2}\)
特征根方程为\(x^2-\frac{1}{2}x-\frac{1}{2}=0\)
\(x_1=1,x_2=-\frac{1}{2}\)
因为\(f_0=0\),数列从0开始,设\(f_n=\alpha x_1^n+\beta x_2^n\)
那么有\(\begin{cases}\alpha+\beta=0 \\ \alpha-\frac{1}{2} \beta =0 \end{cases}\)
解得\(\alpha=\frac{2}{3},\beta=-\frac{2}{3}\)
所以\(f_n=\frac{2}{3}+\frac{2}{3}(-\frac{1}{2})^n\)
当\(n \to + \infty\)时\(f_n \to \frac{2}{3}\)
知识点补充:时间复杂度分析
这个的孙题比较多,还是讲一下比较好
渐进记号
\(O,\Theta,\Omega\)记号表示的是一类函数的集合,不仅仅可以用于描述时间复杂度. 在分析时间复杂度时,我们先定义一些基本运算,再将\(T(n)\)定义为基本运算次数关于数据规模\(n\)的函数。但是\(T(n)\)往往比较复杂,我们不关心它的系数,只关心它的次数。此时就可以引入渐进记号来描述。
\(O(f(n))=\{g(n)| \exists n_0,c, \forall n>n_0,cf(n) \geq g(n) \}\),表示上界为\(f(n)\)
\(\Theta(f(n)) = \{g(n)|\exist n_0,c_1,c_2,\forall n>n_0,c_1f(n) \geq g(n) \geq c_2f(n)\}\),表示与\(f(n)\)同阶
\(\Omega(f(n))=\{ g(n)| \exist n_0,c, \forall n>n_0,g(n) \geq cf(n)\}\),表示下界为\(f(n)\)
比如,对于\(T(n)=n^2+2n\),我们可以得到\(T(n) \in O(n^2), T(n) \in O(n^3) , T(n) \in \Theta(n^2), T(n) \in \Omega(n^2),T(n)\in \Omega(n)\).值得注意的是,很多地方我们并不会用\(\in\),而是用\(=\)来表示相同的意思,如\(T(n)=O(n^2)\)
主定理
设\(T(n)=aT(\frac{n}{b})+f(n),a>1,b>1\)
(1) 当\(\exists \varepsilon > 0,f(n) = O({n^{{{\log }_b}a - \varepsilon }})\) , \(T(n)=\Theta ({n^{{{\log }_b}a}})\)
(2) 当\(\exist k \geq 0,f(n) = \Theta ({n^{{{\log }_b}a}\log^k_n})\),\(T(n)={n^{{{\log }_b}a}}\log^{k+1}\)
(3) 当\(\exist \epsilon>0, \text { 有 } f(n)=\Omega\left(n^{\log_{b}a+\epsilon}\right),\) 同时存在常数 \(c<1\) 以及充分大的 \(n\) 满足\(a f\left(\frac{n}{b}\right) \leq c f(n) , T(n)=\Theta(f(n))\)
举例:
\(T(n) = 9T(\frac{n}{3}) + n\),满足情况(1),\(T(n)=\Theta(n^2)\)
\(T(n) = 2T(\frac{n}{2})+ n\log n\),满足情况(2),\(T(n)=\Theta(n\log^2 n)\)
\(T(n) = T(\frac{n}{2})+n\log n\),满足情况(3),存在\(\varepsilon=1\),使得\(f(n)=\Omega(n^{\log_b a+\varepsilon})=\Omega(n)\),\(T(n)=\Theta(n\log n)\)
值得注意的是,主定理并不能处理所有形如\(T(n)=aT(\frac{n}{b})+f(n)\)的递归式.如\(T(n)=2T(\frac{n}{2})+n\log n\),\(n^{\log_b a}=n\),不存在\(\varepsilon>0\)使得\(n^{\log_b a+\varepsilon}\)在渐进意义下小于\(f(n)\).
关于平均,最好,最坏时间复杂度
引入"平均,最好,最坏"这三个词,是因为有一些算法的复杂度并不仅仅和数据规模\(n\)有关,而和数据的一些其他性质有关.如快速排序在数据有序的情况下会变成\(O(n^2)\). 那么我们可以对于所有可能的输入数据,把其复杂度做平均,就得到了平均复杂度。对于使得复杂度最小,就定义其为最好复杂度。最坏同理。平均,最好,最坏时间复杂度都可以用\(O,\Theta,\Omega\)来描述. 我们既可以说快速排序最坏复杂度是\(O(n^2)\),也可以说是\(\Theta(n^2)\)

祝学弟学妹们初赛加油!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号