SQL Server索引笔记
一、有哪些索引?
✅ 第一维度:按存储方式分类(聚集 vs 非聚集)
| 类型 | 说明 |
|---|---|
| 聚集索引(Clustered Index) | 表的物理数据行按索引顺序排列。每个表只能有一个聚集索引(因为数据只能按一种顺序存)。 |
| 非聚集索引(Nonclustered Index) | 另起一套结构,指向原表或聚集索引的数据行。可以建多个。不改变数据的物理顺序。 |
📌 聚集索引就像书的正文目录
📌 非聚集索引就像关键词索引(附录)
✅ 第二维度:按字段数量分类(单列 vs 复合)
| 类型 | 说明 |
|---|---|
| 单列索引 | 索引只包含一个列。例:CREATE INDEX IX_A ON T(A) |
| 复合索引(又叫组合索引) | 索引包含两个或更多列。例:CREATE INDEX IX_AB ON T(A, B) |
📌 这跟是否聚集没有关系,聚集索引也可以是复合的
📌 非聚集索引可以是单列,也可以是复合的
二、索引语法解读(创建一个非聚集的复合+INCLUDE索引)
| 部分 | 含义 |
|---|---|
CREATE NONCLUSTERED INDEX |
创建一个非聚集索引。数据行顺序不变,只是另建一个索引结构加快查询速度。 |
IX_CustomerBinding_SalesRepNo_BindingDate |
索引的名称(你自己定义的,建议有语义)。 |
ON dbo.CustomerBinding(...) |
指定在哪个表上创建索引,这里是 CustomerBinding 表。 |
(SalesRepNo, BindingDate) |
这是索引键列,用于加速 WHERE 过滤条件。顺序也会影响效率(靠前列优先参与筛选)。 |
INCLUDE (CustomerNo) |
这是包含列(INCLUDE),不是参与索引排序的键列,但会被一并放入索引页中。 |
三、创建索引前与创建索引后SQL查询性能对比
✅ 第一步:前置准备
✅ 第二步:执行查询(索引创建前)
观察输出内容(在 SSMS 下方“Messages”窗口),重点关注:
-
logical reads(页数越少越好) -
CPU time/elapsed time(执行时间)
✅ 第三步:创建非聚集索引
✅ 第四步:再次清缓存 + 执行查询(索引创建后)
✅ 第五步:对比输出结果
你会看到类似这样的对比信息(示例):
🔴 未创建索引前

✅ 创建索引后
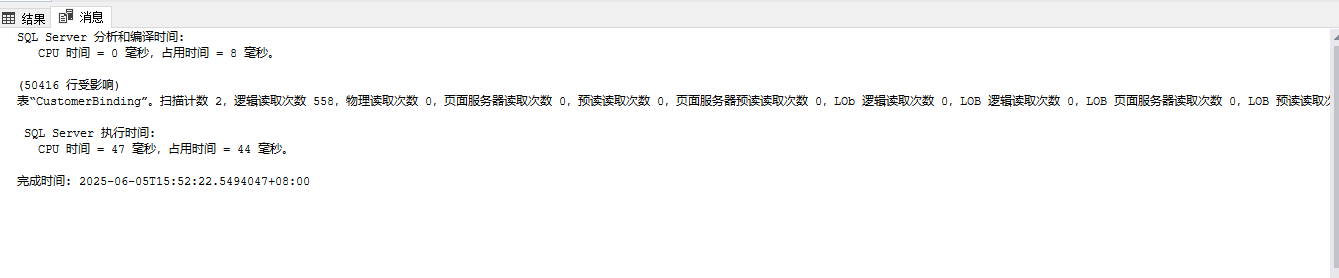
明显可以看出:I/O 降低,执行时间大幅缩短,性能提升显著。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号