python基础之多线程与多进程(一)


并发编程? 1、为什么要有操作系统? 操作系统,位于底层硬件与应用软件之间 工作方式:向下管理硬件,向上提供接口 2、多道技术? 不断切换程序。 操作系统进程切换: 1、出现IO操作 2、固定时间 进程:程序,数据集,进程控制块三部分组成 切换之前应该保持程序的运行状态(进程控制块保持) 并发:同时处理多个程序 一个进程有一个或多个线程 每个线程共享进程的所有资源 进程:资源管理单位(容器) 线程:最小执行单位(被CPU执行的) PCB切换 python无法实现并行的多线程 有一把锁:全局解释器锁(GIL) Global Interator lock 加在CPython解释器上的,CPython的库比较多。 由于GIL,导致同一时刻,同一进程只能有一个线程在跑 prevents multiple native threads from executing Python bytecodes at once 计算密集型:一直在使用CPU 反而更慢,python的多线程并没有意义 IO:存在大量IO操作 python的多线程是有意义的 python使用多核:开进程,弊端:开销大而且切换复杂 在socket中accept和recieve中可以用到IO密集型 多进程可以并行 同一个进程里两个线程不能并行执行 协程:yield,程序员调度,决定什么时候切换 着重点:协程+多进程 方向:IO多路复用 终极思路:换C模块实现多线程 IO操作,多线程不如协程好 进程能用多核,但是开销太大 线程能用到的时候就是学爬虫 进程与线程会在面试问到 socketserver threading+select实现并发,实现一个服务端和多个客户端通信
进程与线程的概念
前言:
操作系统,位于底层硬件与应用软件之间的一层
工作方式:向下管理硬件,向上提供接口
多道技术补充:http://www.cnblogs.com/linhaifeng/p/6295875.html
进程:
考虑一个场景:浏览器,网易云音乐以及notepad++ 三个软件只能顺序执行是怎样一种场景呢?另外,假如有两个程序A和B,程序A在执行到一半的过程中,需要读取大量的数据输入(I/O操作),而此时CPU只能静静地等待任务A读取完数据才能继续执行,这样就白白浪费了CPU资源。你是不是已经想到在程序A读取数据的过程中,让程序B去执行,当程序A读取完数据之后,让程序B暂停。聪明,这当然没问题,但这里有一个关键词:切换。
既然是切换,那么这就涉及到了状态的保存,状态的恢复,加上程序A与程序B所需要的系统资源(内存,硬盘,键盘等等)是不一样的。自然而然的就需要有一个东西去记录程序A和程序B分别需要什么资源,怎样去识别程序A和程序B等等(比如读书)。
进程定义:
进程就是一个程序在一个数据集上的一次动态执行过程。进程一般由程序、数据集、进程控制块三部分组成。我们编写的程序用来描述进程要完成哪些功能以及如何完成;数据集则是程序在执行过程中所需要使用的资源;进程控制块用来记录进程的外部特征,描述进程的执行变化过程,系统可以利用它来控制和管理进程,它是系统感知进程存在的唯一标志。
举一例说明进程:
想象一位有一手好厨艺的计算机科学家正在为他的女儿烘制生日蛋糕。他有做生日蛋糕的食谱,厨房里有所需的原料:面粉、鸡蛋、糖、香草汁等。在这个比喻中,做蛋糕的食谱就是程序(即用适当形式描述的算法)计算机科学家就是处理器(cpu),而做蛋糕的各种原料就是输入数据。进程就是厨师阅读食谱、取来各种原料以及烘制蛋糕等一系列动作的总和。现在假设计算机科学家的儿子哭着跑了进来,说他的头被一只蜜蜂蛰了。计算机科学家就记录下他照着食谱做到哪儿了(保存进程的当前状态),然后拿出一本急救手册,按照其中的指示处理蛰伤。这里,我们看到处理机从一个进程(做蛋糕)切换到另一个高优先级的进程(实施医疗救治),每个进程拥有各自的程序(食谱和急救手册)。当蜜蜂蛰伤处理完之后,这位计算机科学家又回来做蛋糕,从他
离开时的那一步继续做下去。
注:
进程之间是相互独立得。
操作系统进程切换:1、出现IO操作。2、固定时间
线程:
线程的出现是为了降低上下文切换(with open("a.txt") as f: __enter__和__exit__)的消耗,提高系统的并发性,并突破一个进程只能干一样事的缺陷,使到进程内并发成为可能。
假设,一个文本程序,需要接受键盘输入,将内容显示在屏幕上,还需要保存信息到硬盘中。若只有一个进程,势必造成同一时间只能干一样事的尴尬(当保存时,就不能通过键盘输入内容)。若有多个进程,每个进程负责一个任务,进程A负责接收键盘输入的任务,进程B负责将内容显示在屏幕上的任务,进程C负责保存内容到硬盘中的任务。这里进程A,B,C间的协作涉及到了进程通信问题,而且有共同都需要拥有的东西——-文本内容,不停的切换造成性能上的损失。若有一种机制,可以使任务A,B,C共享资源,这样上下文切换所需要保存和恢复的内容就少了,同时又可以减少通信所带来的性能损耗,那就好了。是的,这种机制就是线程。
线程也叫轻量级进程,它是一个基本的CPU执行单元,也是程序执行过程中的最小单元,由线程ID、程序计数器、寄存器集合和堆栈共同组成。线程的引入减小了程序并发执行时的开销,提高了操作系统的并发性能。线程没有自己的系统资源。
注:1、进程是资源管理单位(容器)。2、线程是最小执行单位(被CPU执行的)。3、一个进程切换到另外一个进程是由一个进程里的PCB切换到另外一个进程的PCB(进程控制块)
进程与线程的关系
进程是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。或者说进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位。
线程则是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。
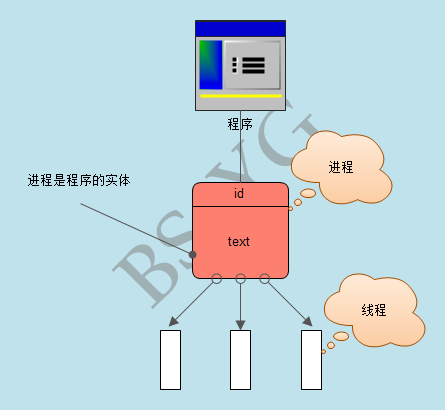
进程和线程的关系:
(1)一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程。
(2)资源分配给进程,同一进程的所有线程共享该进程的所有资源。
(3)CPU分给线程,即真正在CPU上运行的是线程。
并行和并发
并行处理(Parallel Processing)是计算机系统中能同时执行两个或更多个处理的一种计算方法。并行处理可同时工作于同一程序的不同方面。并行处理的主要目的是节省大型和复杂问题的解决时间。并发处理(concurrency Processing):指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机(CPU)上运行,但任一个时刻点上只有一个程序在处理机(CPU)上运行
并发的关键是你有处理多个任务的能力,不一定要同时。并行的关键是你有同时处理多个任务的能力。所以说,并行是并发的子集
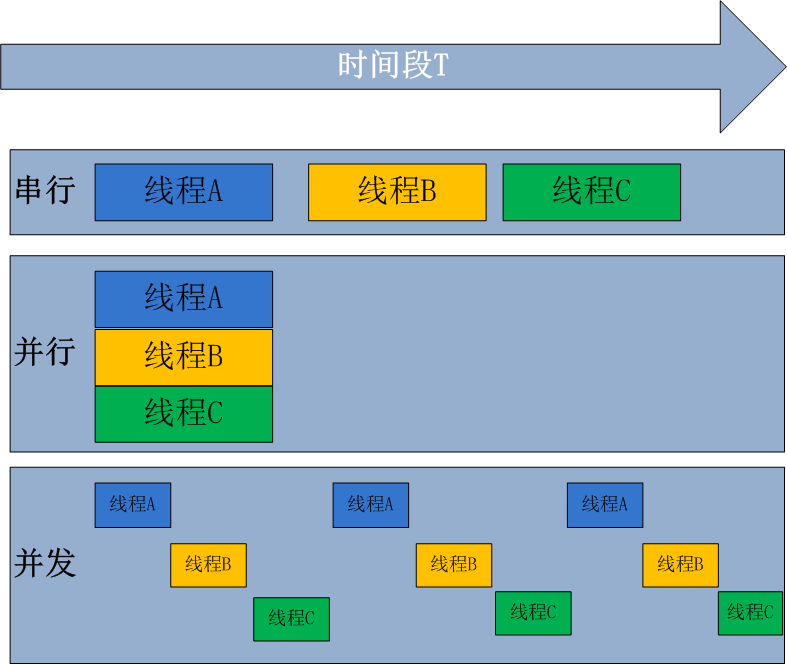
串行执行时一个接一个按顺序地执行(线程A--->线程B----->线程C);
并行是线程A,线程B,线程C同时执行(需要多个CPU);
并发是指线程A执行的瞬间进程B执行,然后进程C执行
同步与异步
在计算机领域,同步就是指一个进程在执行某个请求的时候,若该请求需要一段时间才能返回信息,那么这个进程将会一直等待下去,直到收到返回信息才继续执行下去;异步是指进程不需要一直等下去,而是继续执行下面的操作,不管其他进程的状态。当有消息返回时系统会通知进程进行处理,这样可以提高执行的效率。举个例子,打电话时就是同步通信,发短息时就是异步通信。
进程和线程总结:
1、空间多路复用是什么?
考虑一个场景:浏览器,网易云音乐以及notepad++ 三个软件只能顺序执行是怎样一种场景呢?
另外,假如有两个程序A和B,程序A在执行到一半的过程中,需要读取大量的数据输入(I/O操作),而此时CPU只能静静地等待任务A读取完数据才能继续执行,这样就白白浪费了CPU资源。你是不是已经想到在程序A读取数据的过程中,让程序B去执行,当程序A读取完数据之后,让程序B暂停。聪明,这当然没问题,但这里有一个关键词:切换;
2、进程:
进程就是一个程序在一个数据集上的一次动态执行过程(正在运行的软件就是进程)。进程一般由程序、数据集、进程控制块三部分组成;
程序:执行的内容(要做什么)
数据集:执行过程中用到的数据
进程控制块:操作系统切换该进程时保存的状态
操作系统切换进程的规则:进程出现IO操作、和固定时间
举栗子说明:
举个栗子:
想象一位有一手好厨艺的计算机科学家正在为他的女儿烘制生日蛋糕。他有做生日蛋糕的食谱,厨房里有所需的原料:面粉、鸡蛋、糖、香草汁等。在这个比喻中,做蛋糕的食谱就是程序(即用适当形式描述的算法)计算机科学家就是处理器(cpu),而做蛋糕的各种原料就是输入数据。进程就是厨师阅读食谱、取来各种原料以及烘制蛋糕等一系列动作的总和。现在假设计算机科学家的儿子哭着跑了进来,说他的头被一只蜜蜂蛰了。计算机科学家就记录下他照着食谱做到哪儿了(保存进程的当前状态),然后拿出一本急救手册,按照其中的指示处理蛰伤。这里,我们看到处理机从一个进程(做蛋糕)切换到另一个高优先级的进程(实施医疗救治),每个进程拥有各自的程序(食谱和急救手册)。当蜜蜂蛰伤处理完之后,这位计算机科学家又回来做蛋糕,从他
离开时的那一步继续做下去。
CPU就是这个科学家
食谱就是程序
面粉、鸡蛋、糖、香草汁等就是数据集
被一只蜜蜂蛰了。计算机科学家就记录下他照着食谱做到哪儿了(保存进程的当前状态)就是进程控制块;
3、线程:
上述说到 在60年代之前,操作系统 在CPU执行程序时,可以根据程序出现了IO操作、固定时间,利用进程控制块,从当前进程切换到其他进程;实现了并发现象;
由于CPU的执行速度很快,切换的过程 从程序执行效果,我们无法看到,这实现了并发现象;(看似同时执行多个程序,其实是CPU快速切换制造出的并发现象)
问题出现:
(1)由于多个进程间每次上下文切换存时,都要进程的保存数据集、程序运行状态等大量数据。
(2)上下文切换(在操作系统中,CPU切换到另一个进程需要保存当前进程的状态并恢复另一个进程的状态:当前运行任务转为就绪(或者挂起、删除)状态,另一个被选定的就绪任务成为当前任务。上下文切换包括保存当前任务的运行环境,恢复将要运行任务的运行环境。)
(3)进程间的上下文切换代价比较大 因此需要引入轻型进程-------线程(只保存运行状态,数据集是共享的不需要保存);
这就意味着:要开发1个word就必须需要有3个进程;进程1执行写入 、进程2执行保存写入、进程2执行读取;
由于3个进程的数据集都是相互独立的, 这3个进程之间通信、切换时,都要保存一套相同的数据集;导致切换开销非常大;
解决方法:
(1)把数据集变成公共资源,进程开多个线程(微进程)共享数据集,线程上下文切换只需要加载少量必要的信息;(减少了上下文开销,进程之间数据交换)

4、总结
进程:资源管理单位(包含共享数据集+各个线程)
线程:最小执行单位
(1)一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程。
(2)资源分配给进程,同一进程的所有线程共享该进程的所有资源。
(3)CPU分给线程,即真正在CPU上运行的是线程。
5、串行、并发、并行
串行:1颗CPU 执行程序1------执行2-----执行3 (顺序执行)
并发:1颗CPU 执行程序1一下、执行程序2一下、执行程序2一下 (轮询执行)
并行:假设有3颗CPU:CPU1执行程序1、CPU2执行程序2、CPU3执行程序3(同时进行)
6、同步、异步
同步就像打电话:拨通电话之后,只有对方接听以后,只能等待对方接听之后才会结束;
异步:就像发短信,发完了短信,不用等待,可以去做别的事情;
threading模块
线程对象的创建
Thread类直接创建
# Thread类直接创建 import threading import time def countNum(n): # 定义某个线程要运行的函数 print("running on number:%s" %n) time.sleep(3) if __name__ == '__main__':#这里的情况是把本程序当成一个脚本,所以这一行代码下面的程序会执行 t1 = threading.Thread(target=countNum,args=(23,)) #生成一个线程实例 t2 = threading.Thread(target=countNum,args=(34,)) #生成一个线程实例 t1.start() #启动线程 t2.start()#启动线程 print("ending!")
Thread类继承式创建
#继承Thread式创建 import threading import time class MyThread(threading.Thread): def __init__(self,num): threading.Thread.__init__(self) self.num=num def run(self): print("running on number:%s" %self.num) time.sleep(3) t1=MyThread(56) t2=MyThread(78) t1.start() t2.start() print("ending")
Thread类的实例方法
join()和setDaemon()
Thread类的实例方法
join()--->线程挂起 和setDaemon()---->设置守护进程
# join():在子线程完成运行之前,这个子线程的父线程将一直被阻塞。 # setDaemon(True): ''' 将线程声明为守护线程,必须在start() 方法调用之前设置,如果不设置为守护线程程序会被无限挂起。 当我们在程序运行中,执行一个主线程,如果主线程又创建一个子线程,主线程和子线程 就分兵两路,分别运行,那么当主线程完成 想退出时,会检验子线程是否完成。如果子线程未完成,则主线程会等待子线程完成后再退出。但是有时候我们需要的是只要主线程 完成了,不管子线程是否完成,都要和主线程一起退出,这时就可以 用setDaemon方法啦''' import threading from time import ctime,sleep import time def Music(name): print ("Begin listening to {name}. {time}".format(name=name,time=ctime())) sleep(3) print("end listening {time}".format(time=ctime())) def Blog(title): print ("Begin recording the {title}. {time}".format(title=title,time=ctime())) sleep(5) print('end recording {time}'.format(time=ctime())) threads = [] t1 = threading.Thread(target=Music,args=('FILL ME',)) t2 = threading.Thread(target=Blog,args=('',)) threads.append(t1) threads.append(t2) if __name__ == '__main__': #t2.setDaemon(True) for t in threads: #t.setDaemon(True) #注意:一定在start之前设置 t.start() #t.join() #t1.join() #t2.join() # 考虑这三种join位置下的结果? print ("all over %s" %ctime())
Thread实例对象的方法 # isAlive(): 返回线程是否活动的。 # getName(): 返回线程名。 # setName(): 设置线程名。 threading模块提供的一些方法: # threading.currentThread(): 返回当前的线程变量。 # threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。 # threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
# Auther:bing #_*_coding:utf-8_*_ #!/usr/bin/env python # 多线程并发的socket服务端 import multiprocessing import threading import socket s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) s.bind(('127.0.0.1',8080)) s.listen(5) def action(conn): while True: data=conn.recv(1024) print(data) conn.send(data.upper()) if __name__ == '__main__': while True: conn,addr=s.accept() p=threading.Thread(target=action,args=(conn,)) p.start()
#!/usr/bin/env python import socket s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) s.connect(('127.0.0.1',8080)) while True: msg=input('>>: ').strip() if not msg:continue s.send(msg.encode('utf-8')) data=s.recv(1024) print(data)
#!/usr/bin/env python import socket s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) s.connect(('127.0.0.1',8080)) while True: msg=input('>>: ').strip() if not msg:continue s.send(msg.encode('utf-8')) data=s.recv(1024) print(data)
socket服务端可以和客户端1,客户端2并发通信。
GIL(全局解释器锁)
定义: In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.) 在CPython,全局解释器锁,或GIL,是一个互斥体,防止多 本地线程执行Python字节码一次。这个锁主要是必要的 因为当前的内存管理不是线程安全的。然而,自从GIL 存在,其他功能增长依赖于它执行的保证。
Python中的线程是操作系统的原生线程,Python虚拟机使用一个全局解释器锁(Global Interpreter Lock)来互斥线程对Python虚拟机的使用。为了支持多线程机制,一个基本的要求就是需要实现不同线程对共享资源访问的互斥,所以引入了GIL。
GIL:在一个线程拥有了解释器的访问权之后,其他的所有线程都必须等待它释放解释器的访问权,即使这些线程的下一条指令并不会互相影响。
在调用任何Python C API之前,要先获得GIL
GIL缺点:多处理器退化为单处理器;优点:避免大量的加锁解锁操作
GIL总结:给所有线程都加上一把大锁,这就省去了重复枷锁。
GIL的早期设计
Python支持多线程,而解决多线程之间数据完整性和状态同步的最简单方法自然就是加锁。 于是有了GIL这把超级大锁,而当越来越多的代码库开发者接受了这种设定后,他们开始大量依赖这种特性(即默认python内部对象是thread-safe的,无需在实现时考虑额外的内存锁和同步操作)。慢慢的这种实现方式被发现是蛋疼且低效的。但当大家试图去拆分和去除GIL的时候,发现大量库代码开发者已经重度依赖GIL而非常难以去除了。有多难?做个类比,像MySQL这样的“小项目”为了把Buffer Pool Mutex这把大锁拆分成各个小锁也花了从5.5到5.6再到5.7多个大版为期近5年的时间,并且仍在继续。MySQL这个背后有公司支持且有固定开发团队的产品走的如此艰难,那又更何况Python这样核心开发和代码贡献者高度社区化的团队呢?
GIL的影响
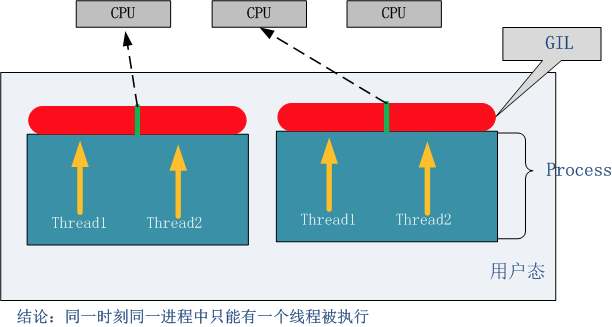
无论你启多少个线程,你有多少个cpu, Python在执行一个进程的时候会淡定的在同一时刻只允许一个线程运行。
所以,python是无法利用多核CPU实现多线程的。
这样,python对于计算密集型的任务开多线程的效率甚至不如串行(没有大量切换),但是,对于IO密集型的任务效率还是有显著提升的。
计算密集型:
#coding:utf8 from threading import Thread import time def counter(): i = 0 for _ in range(50000000): i = i + 1 return True def main(): l=[] start_time = time.time() for i in range(2): t = Thread(target=counter) t.start() l.append(t) t.join() # for t in l: # t.join() end_time = time.time() print("Total time: {}".format(end_time - start_time)) if __name__ == '__main__': main() ''' py2.7: 串行:25.4523348808s 并发:31.4084379673s py3.5: 串行:8.62115597724914s 并发:8.99609899520874s '''
解决方案
用multiprocessing替代Thread multiprocessing库的出现很大程度上是为了弥补thread库因为GIL而低效的缺陷。它完整的复制了一套thread所提供的接口方便迁移。唯一的不同就是它使用了多进程而不是多线程。每个进程有自己的独立的GIL,因此也不会出现进程之间的GIL争抢。
#coding:utf8 from multiprocessing import Process import time def counter(): i = 0 for _ in range(40000000): i = i + 1 return True def main(): l=[] start_time = time.time() for _ in range(2): t=Process(target=counter) t.start() l.append(t) #t.join() for t in l: t.join() end_time = time.time() print("Total time: {}".format(end_time - start_time)) if __name__ == '__main__': main() ''' py2.7: 串行:6.1565990448 s 并行:3.1639978885 s py3.5: 串行:6.556925058364868 s 并发:3.5378448963165283 s '''
当然multiprocessing也不是万能良药。它的引入会增加程序实现时线程间数据通讯和同步的困难。就拿计数器来举例子,如果我们要多个线程累加同一个变量,对于thread来说,申明一个global变量,用thread.Lock的context包裹住三行就搞定了。而multiprocessing由于进程之间无法看到对方的数据,只能通过在主线程申明一个Queue,put再get或者用share memory的方法。这个额外的实现成本使得本来就非常痛苦的多线程程序编码,变得更加痛苦了。
总结:因为GIL的存在,只有IO Bound场景下得多线程会得到较好的性能 - 如果对并行计算性能较高的程序可以考虑把核心部分也成C模块,或者索性用其他语言实现 - GIL在较长一段时间内将会继续存在,但是会不断对其进行改进。
总结:
GIL(全局解释器锁):
加在cpython解释器上;
计算密集型: 一直在使用CPU
IO密集型:存在大量IO操作
总结:
对于计算密集型任务:Python的多线程并没有用
对于IO密集型任务:Python的多线程是有意义的
python使用多核:开进程,弊端:开销大而且切换复杂
着重点:协程+多进程
方向:IO多路复用
终极思路:换C模块实现多线程
所以对于GIL,既然不能反抗,那就学会去享受它吧!
posted on 2017-05-08 18:46 bigdata_devops 阅读(324) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号