存储器 - 金字塔层次结构:越靠近CPU速度越快,容量越小,价格越贵
存储器 - 金字塔层次结构:越靠近CPU速度越快,容量越小,价格越贵
计算机组成原理目录:https://www.cnblogs.com/binarylei/p/12585607.html
1. 金字塔层次结构
现代计算机的存储设备一般有 Cache、内存、HDD(SSD) 硬盘。这些存储设备越靠近 CPU 速度越快,容量越小,价格越贵。
- 寄存器(Register):寄存器与其说是存储器,其实更像是 CPU 本身的一部分,只能存放极其有限的信息,但是速度非常快,和 CPU 同步。
- 高速缓存(CPU Cache):使用 SRAM(Static Random-Access Memory,静态随机存取存储器)的芯片。
- 内存(DRAM):使用 DRAM(Dynamic Random Access Memory,动态随机存取存储器)的芯片,比起 SRAM 来说,它的密度更高,有更大的容量,而且它也比 SRAM 芯片便宜不少。
- 硬盘:如 SSD(Solid-state drive 或 Solid-state disk,固态硬盘)、HDD(Hard Disk Drive,硬盘)。
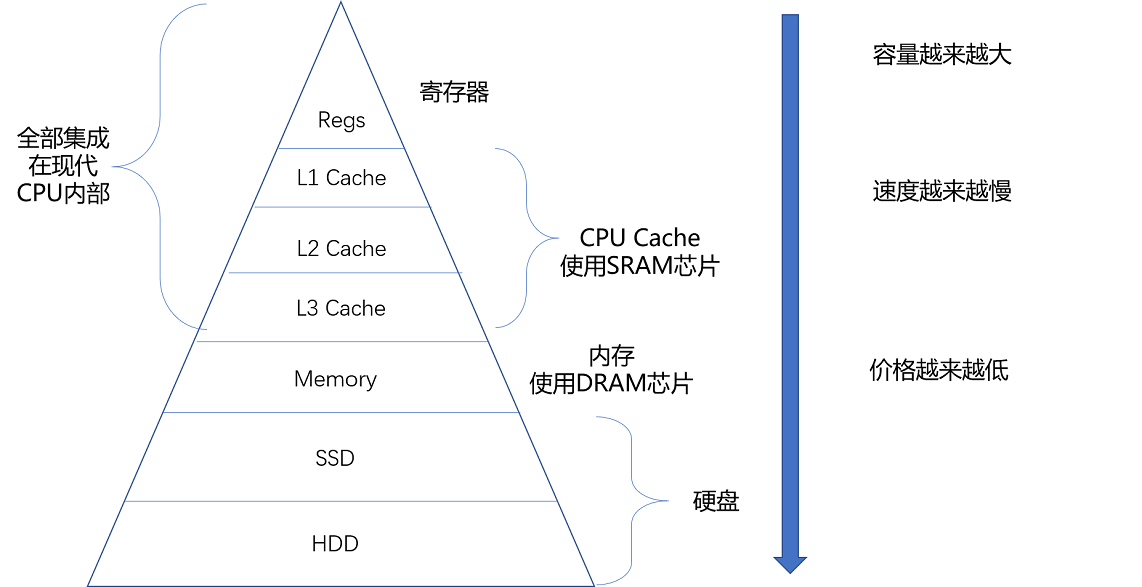
不同层次存储器设备特点:
- 越靠近 CPU 速度越快,容量越小,价格越贵。
- 每一种存储器设备只和它相邻的存储设备打交道。比如,CPU Cache 是从内存里加载而来的,或者需要写回内存,并不会直接写回数据到硬盘,也不会直接从硬盘加载数据到 CPU Cache 中,而是先加载到内存,再从内存加载到 Cache 中。
1.1 高速缓存(SRAM)
高速缓存的 SRAM 的电路简单,所以访问速度非常快,但能够存储的数据有限。在 CPU 里,通常会有 L1、L2、L3 这样三层高速缓存。每个 CPU 核心都有一块属于自己的 L1 高速缓存,通常分成指令缓存和数据缓存,分开存放 CPU 使用的指令和数据。
- L1 Cache:往往就嵌在 CPU 核心的内部。
- L2 Cache:同样是每个 CPU 核心都有的,不过它往往不在 CPU 核心的内部。所以,L2 Cache 的访问速度会比 L1 稍微慢一些。
- L3 Cache,则通常是多个 CPU 核心共用的,尺寸会更大一些,访问速度自然也就更慢一些。
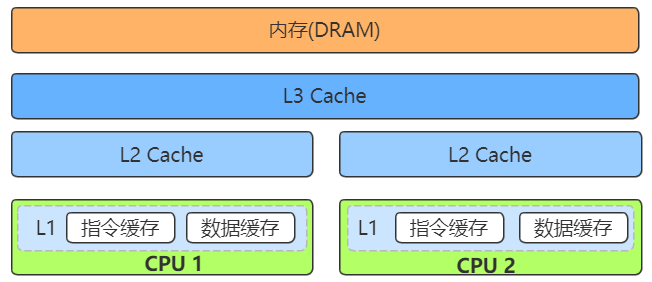
1.2 内存(DRAM)
1.3 硬盘
2. 局部性原理 - 如何选择最优存储
2.1 不同存储器对比
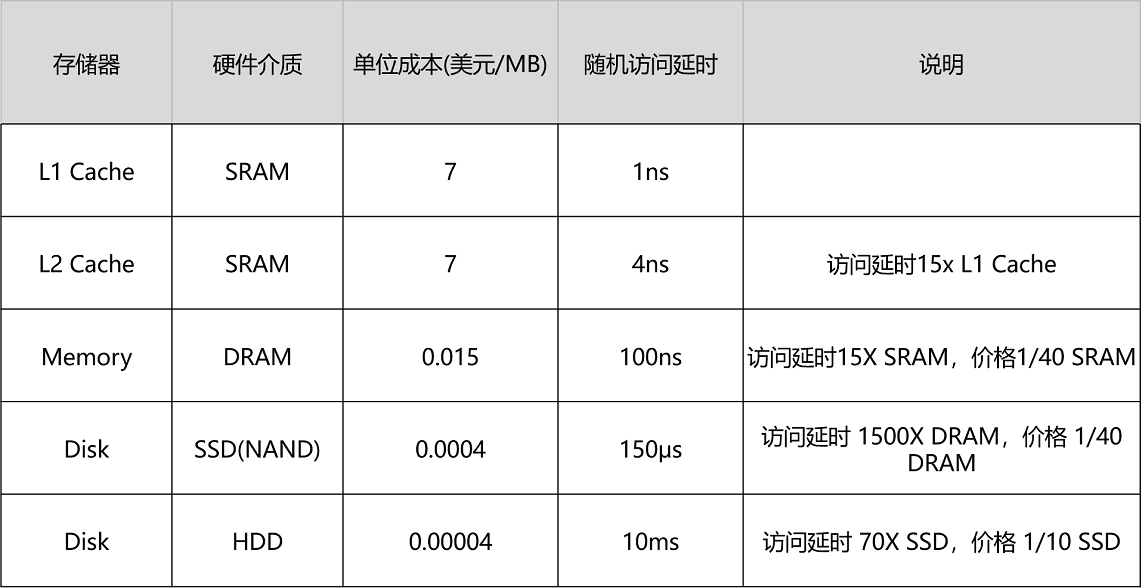
你可以看到,在一台实际的计算机里面,越是速度快的设备,容量就越小。这里一共 10M 的 Cache,成本只是几十美元。而 8GB 的内存、128G 的 SSD 以及 1T 的 HDD,大概零售价格加在一起,也就和我们的高速缓存的价格差不多。
不同存储器的访问延时数据:
- Peter Novig 的 Teach Yourself Programming in Ten Years:不同存储器的访问延时数据,这些数字随着摩尔定律的发展在不断缩小,但是在数量级上仍然有着很强的参考价值。
- Latency Numbers Every Programmer Should Know
2.2 局部性原理
我们能不能既享受 CPU Cache 的速度,又享受内存、硬盘巨大的容量和低廉的价格呢?前辈们已经探索出了答案,那就是,存储器中数据的局部性原理(Principle of Locality)。我们可以利用这个局部性原理,来制定管理和访问数据的策略。
- 时间局部性(temporal locality):如果一个数据被访问了,那么它在短时间内还会被再次访问。如 LRU 缓存机制,将频繁访问的数据保存在内存中。
- 空间局部性(spatial locality):如果一个数据被访问了,那么和它相邻的数据也很快会被访问。如果数组的 CPU 预读功能。
2.3 实战 - 如何花最少的钱,装下亚马逊的所有商品
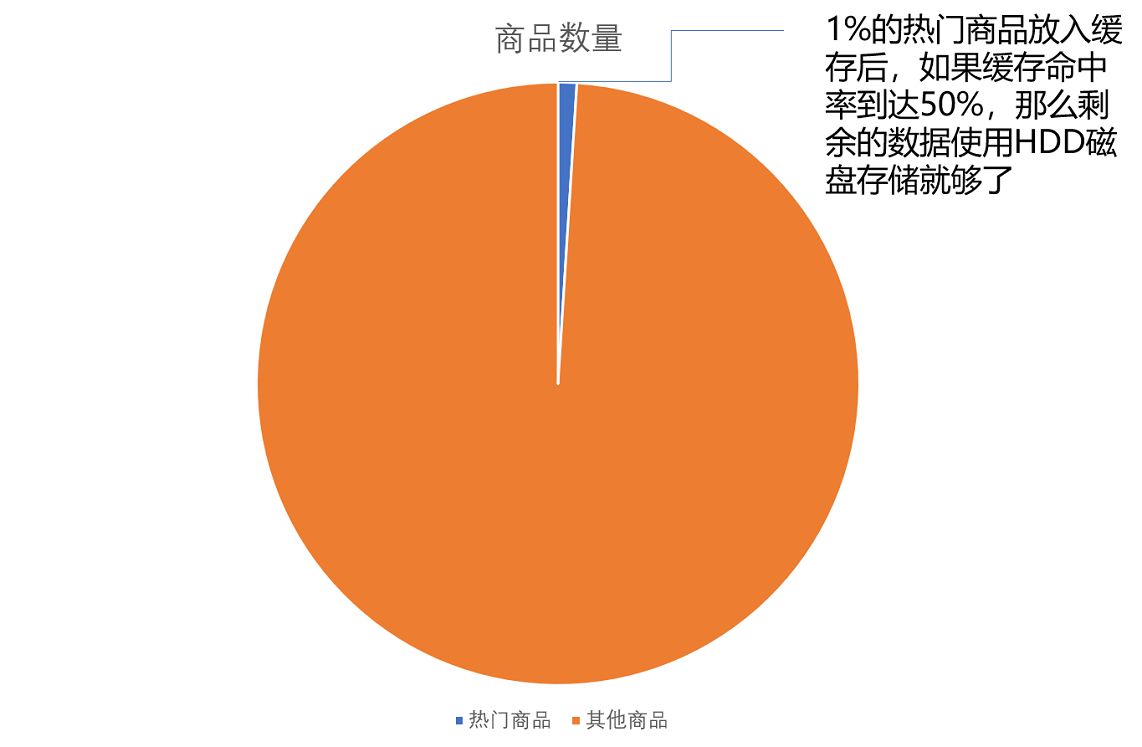
了解了局部性原理,下面我们就来一个实战,来看一看通过局部性原理,利用不同层次存储器的组合,究竟会有什么样的好处。假设亚马逊这样的电商网站有 6 亿件商品,如果每件商品需要 4MB 的存储空间(考虑到商品图片的话,4MB 已经是一个相对较小的估计),那么一共需要 2400TB( = 6 亿 × 4MB)的数据存储。应该选择什么样的存储设备呢?
- 商品全部放在内存中。那就需要 3600 万美元( = 2400TB × 0.015 美元/1MB = 3600 万美元)。但是,这 6 亿件商品中,不是每一件商品都会被经常访问。
- 假设 1% 的热门商品放到内存中。也就是 600 万件热门商品,而剩下的商品放在机械式的 HDD 硬盘上,那么,我们需要的存储成本就下降到 45.6 万美元( = 3600 万美元 × 1% + 2400TB × 0.00004 美元 /1MB )。
说明: 这就是时间局部性,下面两个问题是我们需要主要关注的问题。
-
LRU(Least Recently Used)缓存算法:将用户访问过的数据加载到内存中,一旦内存不足,则将最长时间没有在内存中被访问过的数据从内存中移走。这样,热门商品被访问得多,就会始终被保留在内存里,而冷门商品被访问得少,就只存放在 HDD 硬盘上。越是热门的商品,越容易在内存中找到,也就更好地利用了内存的随机访问性能。
-
缓存命中率(Hit Rate/Hit Ratio):LRU 缓存策略,访问的数据可以在内存中找到的占有比例。
那么,只放 600 万件商品真的可以满足我们实际的线上服务请求吗?以亚马逊 2017 年 3 亿的用户数来看,我们估算每天的活跃用户为 1 亿,这 1 亿用户每人平均会访问 100 个商品,那么平均每秒访问的商品数量,就是 12 万次。
- 内存的随机访问请求需要 100ns,即在极限情况下,内存可以支持 1000 万次(= 1s / 100ns)随机访问。我们用了 24TB 内存,如果 8G 一条的话,意味着有 3000 条内存,可以支持每秒 300 亿次( = 24TB / 8GB × 1s/100ns)访问。
- HDD 硬盘只能支撑每秒 100 次的随机访问。2400TB 的数据,以 4TB 一块磁盘来计算,有 600 块磁盘,也就是能支撑每秒 6 万次( = 2400TB/4TB × 1s/10ms )的随机访问。
- 如果所有的商品访问请求,都直接到了 HDD 磁盘,HDD 磁盘支撑不了这样的压力。我们至少要 50% 的缓存命中率,HDD 磁盘才能支撑对应的访问次数。不然的话,我们要么选择添加更多数量的 HDD 硬盘,做到每秒 12 万次的随机访问,或者将 HDD 替换成 SSD 硬盘,让单个硬盘可以支持更多的随机访问请求。
当然,这里我们只是一个简单的估算。在实际的应用程序中,查看一个商品的数据可能意味着不止一次的随机内存或者随机磁盘的访问。对应的数据存储空间也不止要考虑数据,还需要考虑维护数据结构的空间,而缓存的命中率和访问请求也要考虑均值和峰值的问题。
每天用心记录一点点。内容也许不重要,但习惯很重要!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号