Java 排序算法 - 为什么插入排序要比冒泡排序更受欢迎呢
Java 排序算法 - 为什么插入排序要比冒泡排序更受欢迎呢
数据结构与算法之美目录(https://www.cnblogs.com/binarylei/p/10115867.html)
对于大多数程序员来说,我们学习的第一个算法,可能就是排序。大部分编程语言中,也都提供了排序函数。在平常的项目中,我们也经常会用到排序。排序算法太多了,有很多可能连名字都没听说过,比如猴子排序、睡眠排序、面条排序等。
这里我们只需要掌握最经典的、最常用的排序算法:冒泡排序、插入排序、选择排序、归并排序、快速排序、计数排序、基数排序、桶排序。我按照时间复杂度把它们分成了三类:
| 排序算法 | 时间复杂度 | 是否基于比较 |
|---|---|---|
| 冒泡、选择、插入 | O(n2) | √ |
| 归并、快排 | O(nlogn) | √ |
| 桶、基数、计数 | O(n) | × |
本文重点分析时间复杂度为 O(n2) 的三种算法:冒泡、选择、插入排序,其中重点需要掌握的是插入排序,其它两种基本的算法在实际软件开发中根本不会使用到。
1. 衡量排序算法的三个指标
1.1 时间复杂度
(1)最好情况、最坏情况、平均情况时间复杂度。
为什么要区分这三种时间复杂度呢?第一,有些排序算法会区分,为了好对比,所以我们最好都做一下区分。第二,对于要排序的数据,有的接近有序,有的完全无序。有序度不同的数据,对于排序的执行时间肯定是有影响的,我们要知道排序算法在不同数据下的性能表现。
(2)时间复杂度的系数、常数 、低阶。
我们知道,时间复杂度反应的是数据规模 n 很大的时候的一个增长趋势,所以它表示的时候会忽略系数、常数、低阶。但是实际的软件开发中,我们排序的可能是 10 个、100 个、1000 个这样规模很小的数据,所以,在对同一阶时间复杂度的排序算法性能对比的时候,我们就要把系数、常数、低阶也考虑进来。
(3)比较次数和交换次数。
基于比较的排序算法的执行过程,会涉及两种操作,一种是元素比较大小,另一种是元素交换或移动。所以,如果我们在分析排序算法的执行效率的时候,应该把比较次数和交换(或移动)次数也考虑进去。
1.2 空间复杂度
针对排序算法的空间复杂度,我们还引入了一个新的概念,原地排序(Sorted in place)。原地排序算法,就是特指空间复杂度是 O(1) 的排序算法。
1.3 稳定性
针对排序算法还有另一个重要指标:稳定性。稳定性是指,排序后相等元素之间原有的先后顺序不变。
比如我们有一组数据 2,9,3,4,8,3,按照大小排序之后就是 2,3,3,4,8,9。这组数据里有两个 3。经过某种排序算法排序之后,如果两个 3 的前后顺序没有改变,那我们就把这种排序算法叫作稳定的排序算法;如果前后顺序发生变化,那对应的排序算法就叫作不稳定的排序算法。
稳定的排序算法会什么用呢?比如我们需要针对订单的金额和时间两个维度排序(order by price, timestamp)。最先想到的方法是:我们先按照金额对订单数据进行排序,然后,再遍历排序之后的订单数据,对于每个金额相同的小区间再按照下单时间排序。这种排序思路理解起来不难,但是实现起来会很复杂。
借助稳定排序算法,可以非常简洁地解决多维度排序。解决思路是这样的:我们先按照下单时间给订单排序,再用稳定排序算法,按照订单金额重新排序。两遍排序之后,我们得到的订单数据就是按照金额从小到大排序,金额相同的订单按照下单时间从早到晚排序的。
1.4 常用排序算法比较
| 排序算法 | 时间复杂度 | 原地算法 | 稳定性 | 备注 |
|---|---|---|---|---|
| 冒泡排序 | O(n2) | √ | √ | |
| 选择排序 | O(n2) | √ | × | |
| 插入排序 | O(n2) | √ | √ | |
| 希尔排序 | O(n1.5) | × | 插入排序的优化 | |
| 归并排序 | O(nlogn) | √ | ||
| 快速排序 | O(nlogn) | × | ||
| 桶排序 | O(n) | |||
| 基数排序 | O(n) | |||
| 计数排序 |
2. 冒泡排序
冒泡排序依次对相邻的元素进行比较并交换,从而实现排序功能。冒泡排序是复杂度为 O(n2) 的原地稳定排序算法。事实上,实际项目中不会使用冒泡排序,冒泡排序仅仅停留在理论阶段。
2.1 冒泡排序原理分析
冒泡排序重复地走访过要排序的元素列,依次比较两个相邻的元素,如果他们的顺序错误就把他们交换过来。走访元素的工作是重复地进行直到没有相邻元素需要交换,也就是说该元素已经排序完成。
| 冒泡次数 | 冒泡结果 |
|---|---|
| 原始数据(n = 6) | 3 8 6 5 2 1 |
| 第一轮第1次冒泡:3 vs 8 | 3 8 6 5 2 1 |
| 第一轮第2次冒泡:8 vs 6 | 3 6 8 5 2 1 |
| 第一轮第3次冒泡:8 vs 5 | 3 6 5 8 2 1 |
| 第一轮第4次冒泡:8 vs 2 | 3 6 5 2 8 1 |
| 第一轮第5次冒泡:8 vs 1 | 3 6 5 2 1 8 |
| 第二轮第1次冒泡:3 vs 6 | 3 6 5 2 1 8 |
| 第二轮第2次冒泡:6 vs 5 | 3 5 6 2 1 8 |
| 第二轮第3次冒泡:6 vs 2 | 3 5 2 6 1 8 |
| 第二轮第4次冒泡:6 vs 1 | 3 5 6 1 6 8 |
| ... | |
| 第 n - 1 轮 | 1 2 3 5 6 8 |
说明: 冒泡比较过程如下:
- 外层轮询,相当于每轮询一次都将最大的元素搬移到最后面。第一轮搬移最大元素到第 n - 1 个位置,第二轮搬移最大元素到第 n - 2 个位置,...,全部搬移完则需要搬移 n - 1 次。
- 内层轮询,比较前后两个元素大小,如果位置顺序错误就交换位置。已经搬移过的最大值,则不再需要比较。
for (int i = 0; i < arr.length; i++) {
boolean swap = false; // 一次都没有交换,说明完全有序,直接return
// 每次轮询依次比较相邻的两个数,将最小的移到前面
for (int j = 0; j < arr.length - i - 1; j++) {
if (arr[j] > arr[j + 1]) {
swap = true;
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
if (!swap) return;
}
2.2 冒泡排序三大指标分析
-
时间复杂度:数据完全有序,最好时间复杂度为 O(n)。数据完全逆序,最坏时间复杂度为 O(n2)。我们再思考一下平均复杂度的计算?这里引入有序度的概念。
- 有序度:数组中有序元素对的个数。如 5, 1, 2 中 (1, 2) 是有序的,有序度为 1。
- 逆序度:数据中无序元素对的个数。如 5, 1, 2 中 (5, 1) 和 (5, 2) 是无序的,逆序度为 2。
- 满有序度:固定为 n(n - 1) / 2,且 满有序度 = 有序度 + 逆序度。
冒泡排序中,一个逆序度就要进行一次交换,最好情况交换 0 次,最坏情况交换 n(n - 1) / 2 次,平均交换 n(n - 1) / 4 次。而比较操作肯定要比交换操作多,而复杂度的上限是 O(n2),所以平均情况下的时间复杂度就是 O(n2)。
-
空间复杂度:使用原来的数组进行排序,是原地排序算法,即 O(1)。
-
稳定性:冒泡排序可以控制相邻元素值相等时不交换位置,也就是元素值相等时顺序不变,因此是稳定算法。
3. 选择排序
选择排序相对于冒泡排序而言,每一轮只交换一次来提高排序效率。选择排序是复杂度为 O(n2) 的原地非稳定排序算法。事实上,同冒泡排序一样,实际项目中不会使用选择排序,选择排序仅仅停留在理论阶段。
3.1 选择排序原理分析
选择排序同样也基于比较算法实现的。和冒泡排序一样,也分为两层循环,外层循环每轮训一次,就排序好一个数,因此外层同样需要循环 n - 1 次。不同的是,外层循环每轮训一次时只交换一次元素位置。
| 选择排序 | 排序结果 |
|---|---|
| 原始数据(n = 6) | 3 8 6 5 2 1 |
| 第一轮交换:8 vs 1 | 3 1 6 5 2 8 |
| 第二轮交换:6 vs 2 | 3 1 2 5 6 8 |
| ... | |
| 第 n - 1 轮 | 1 2 3 5 6 8 |
说明: 选择排序先找出最大值才进行交换,不像冒泡排序都是相邻元素比较后进行交换。但也正是因为选择排序不是相邻元素之间比较后交换,而是非相邻元素间的交换,可能会导致相等的元素在排序后乱序,是非稳定排序。
public void sort(Integer[] arr) {
for (int i = 0; i < arr.length; i++) {
// 1. 比较找到最大值的位置,然后和最后一位进行交换
int maxIndex = 0;
int lastIndex = arr.length - i - 1;
for (int j = 1; j < arr.length - i; j++) {
if (arr[maxIndex] < arr[j]) {
maxIndex = j;
}
}
// 2. 交换
if (maxIndex != lastIndex) {
int tmpValue = arr[maxIndex];
arr[maxIndex] = arr[lastIndex];
arr[lastIndex] = tmpValue;
}
}
}
3.2 选择排序三大指标分析
- 时间复杂度:最好情况时间复杂度、最坏情况和平均情况时间复杂度都为 O(n2)。
- 空间复杂度:使用原来的数组进行排序,是原地排序算法,即 O(1)。
- 稳定性:选择排序是非相邻元素间交换,也就可能导致元素值相等时顺序变化,因此是非稳定算法。
4. 插入排序
插入排序原理在有序数组中插入一个元素仍是有序的。选择排序是复杂度为 O(n2) 的原地稳定排序算法。插入排序是真正在项目中使用的排序算法,需要我们重点学习。
4.1 插入排序原理分析
插入排序将数组分为两部分,有序部分和无序部分,依次遍历无序部分将元素插入到有序数组中,最终达到有序。
| 冒泡次数 | 冒泡结果 |
|---|---|
| 原始数据(n = 6) | 3 8 6 5 2 1 |
| 第一轮插入:将 a[1]=8 插入 a[0] | 3 8 6 5 2 1 |
| 第二轮插入:将 a[2]=6 插入 a[0] ~ a[1] | 3 6 8 5 2 1 |
| ... | |
| 第 n - 1 轮:将 a[n - 1]=1 插入 a[0] ~ a[n - 2] | 1 2 3 5 6 8 |
说明: 插入排序每次都将 将 a[n - 1]=1 插入有序数组 a[0] ~ a[n - 2] 中,保证插入后的数据仍是有序的。
public void sort(Integer[] arr) {
for (int i = 1; i < arr.length; i++) {
int tmp = arr[i];
int j;
for (j = i; j > 0 && arr[j - 1] > tmp; j--) {
arr[j] = arr[j - 1];
}
arr[j] = tmp;
}
}
4.2 插入排序三大指标分析
- 时间复杂度:数据完全有序,最好时间复杂度为 O(n)。数据完全逆序,最坏时间复杂度为 O(n2)。由于往数组中插入一个元素的平均复杂度是 O(n),因此插入排序的平均复杂度也是 O(n2)。
- 空间复杂度:使用原来的数组进行排序,是原地排序算法,即 O(1)。
- 稳定性:插入排序也是相邻元素间交换,也就是元素值相等时顺序不变,,因此是稳定算法。
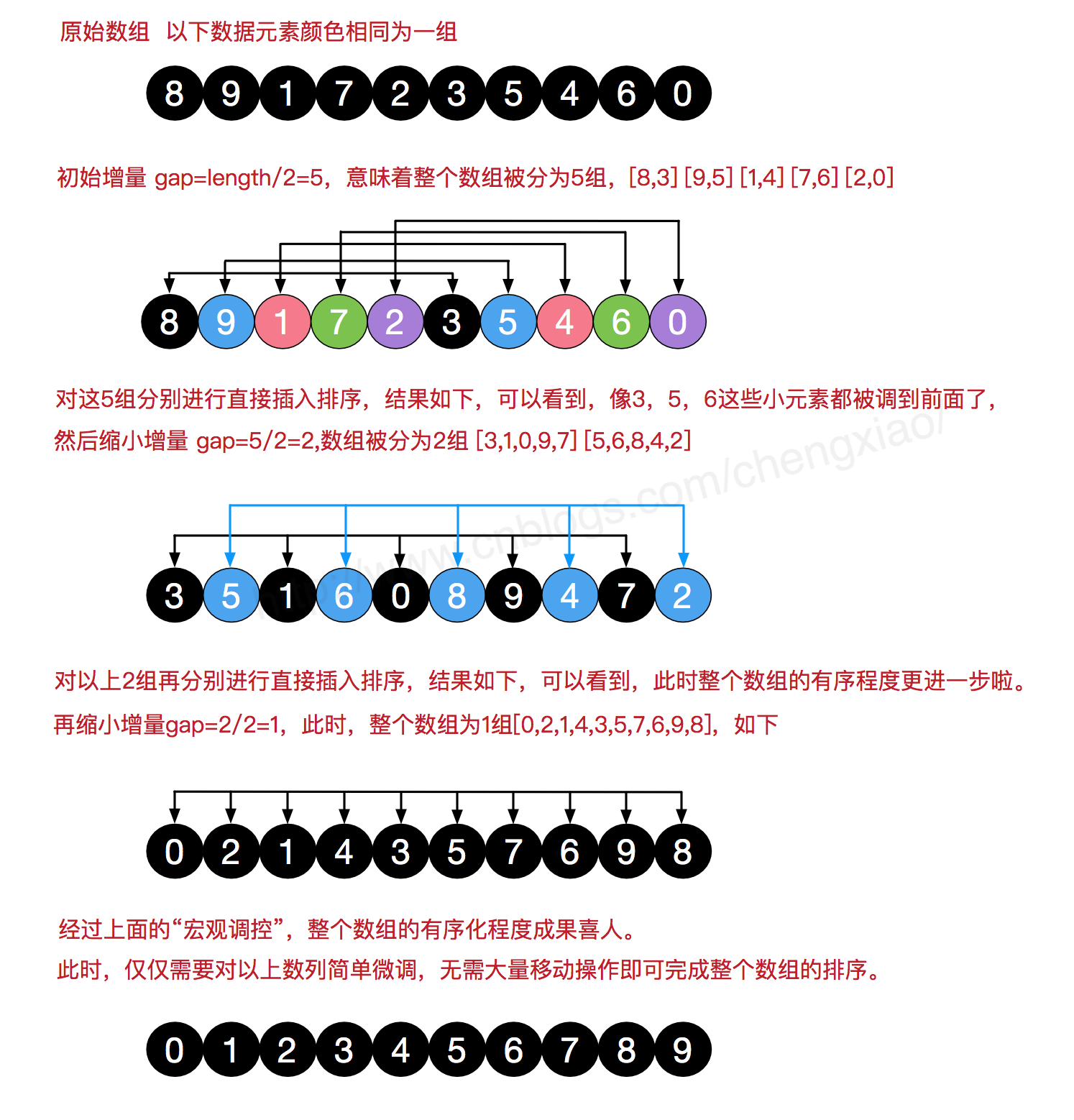
5. 希尔排序
希尔排序是希尔(Donald Shell)于 1959 年提出的一种排序算法。希尔排序也是一种插入排序,它是简单插入排序经过改进之后的一个更高效的版本,也称为缩小增量排序,同时该算法是冲破 O(n2) 的第一批算法之一。
5.1 希尔排序原理分析
希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至 1 时,整个文件恰被分成一组,算法便终止。
当序列很长时,向前插入一次导致的移动操作可能非常大。如果原序列的无序程度较高,则能够缓解这个问题,即小的数大致在前,大的数大致在后。
public void sort(Integer[] arr) {
for (int gap = arr.length / 2; gap > 0; gap /= 2) {
for (int i = gap; i < arr.length; i++) {
int tmp = arr[i];
int j;
for (j = i; j >= gap && arr[j - gap] > tmp; j -= gap) {
arr[j] = arr[j - gap];
}
arr[j] = tmp;
}
}
}
4.2 插入排序三大指标分析
- 时间复杂度:希尔排序时间复杂度分析很复杂,就不具体分析了。希尔排序中对于增量序列的选择十分重要,直接影响到希尔排序的性能。我们上面选择的增量序列 {n/2, (n/4) ... 1}(希尔增量),其最坏时间复杂度依然为 O(n2),一些经过优化的增量序列如 Hibbard 经过复杂证明可使得最坏时间复杂度为 O(n1.5)。
- 空间复杂度:实际使用的是插入排序,也是原地排序算法,即 O(1)。
- 稳定性:希尔排序增加了不同步长之间的排序,也就是非相邻元素之间会交换,这样也导致了元素值相等时顺序会发生变化,,因此是不稳定算法。
6. 总结:为什么插入排序要比冒泡排序更受欢迎呢?
我们前面分析冒泡排序和插入排序的时候讲到,冒泡排序不管怎么优化,元素交换的次数是一个固定值,是原始数据的逆序度。插入排序是同样的,不管怎么优化,元素移动的次数也等于原始数据的逆序度。虽然插入排序和冒泡排序元素交换的最终次数都是一样的,但:
- 冒泡排序元素交换比插入排序要复杂。插入排序只需要一次操作。
- 插入排序的时间复杂度更稳定。冒泡排序只有当数据完全有序时,时间复杂度才是 O(1),只要有一个逆序度则时间复杂度就变成 O(n2)。而插入排序在数据比较有序时更有优势。
参考:
- 排序动画演示:http://www.jsons.cn/sort/
每天用心记录一点点。内容也许不重要,但习惯很重要!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号