数据采集第三次作业
作业一
- 要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象( http://www.weather.com.cn )。
分别使用单线程和多线程的方式爬取。(限定爬取图片数量为学号后4位) - 输出信息:
将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
实验过程
获取html
def getHTMLText(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
}
resp = requests.get(url=url, headers=headers) #发送请求
resp.encoding = resp.apparent_encoding # 自适应解码
return resp.text
except Exception as err:
print(err)
寻找网页中a标签下的href
使用css选择获取含有href属性的a标签节点
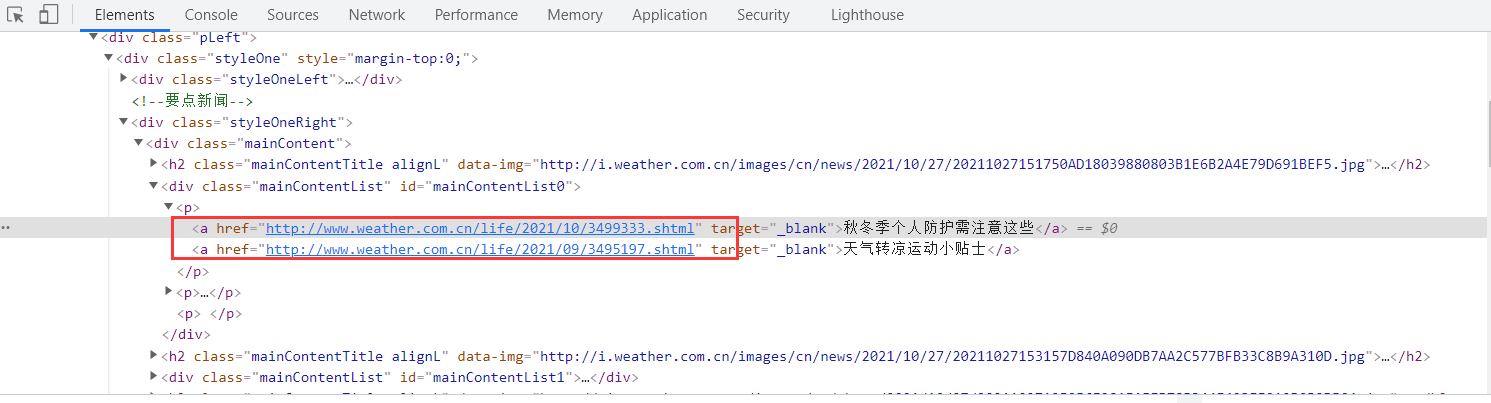
def find_url():
New_url = [] # 存放待爬取的的url
New_url.append(url) #将主页面添加进New_url
# 用bs4去找所有含有href属性的a标签节点
tags = soup.select("a[href]")
for tag in tags:
new_url = tag.get('href')#获得href属性值
New_url.append(new_url)
return New_url
寻找页面中的img(单线程)
通过css选择获取img标签中含有src属性的节点
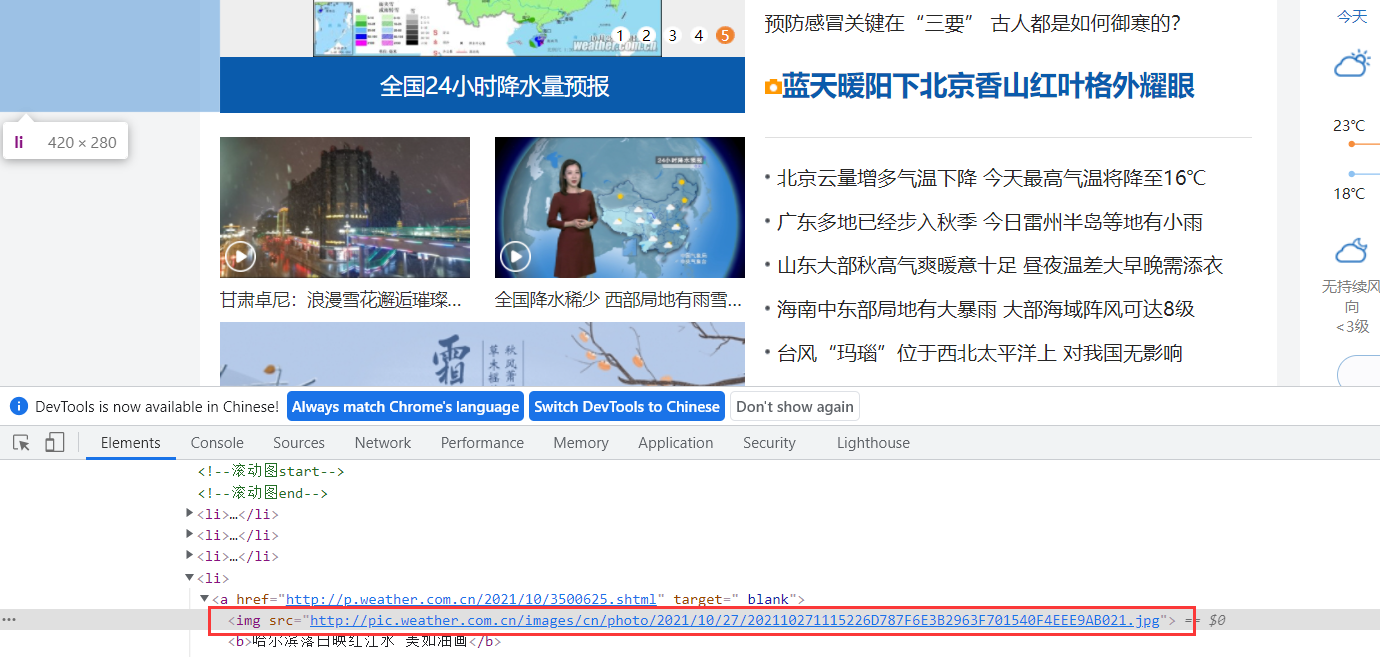
查找img地址并且保存img到本地:
tags = soup.select("img[src]")#获取含有src 的img标签节点
count = 1 #用于计算当前页面下爬取的图片数量
for tag in tags:
if count <= 5: #设置一个页面爬取的数量不会大于5
img_url = tag.get('src') #获得src 的属性值
Save_img(img_url,cnt) #保存图片
cnt += 1
if cnt>113:#当图片的数量大于113时,return
return
else: #一个页面爬取的数量大于5时,break
break
寻找页面中的img(多线程)
tags = soup.select("img[src]")#获取含有src 的img标签节点
count = 1 #用于计算当前页面下爬取的图片数量
for tag in tags:
if count <= 5: #设置一个页面爬取的数量不会大于5
img_url = tag.get('src') #获得src 的属性值
#设置线程,target为Download函数
T = threading.Thread(target=Download, args=(img_url, cnt))
count += 1 #当前页面爬取图片数量+1
cnt +=1 #爬取图片数量+1
T.setDaemon(False) #设置前台线程
T.start() #线程启动
threads.append(T) #将线程添加进threads
if len(threads) > 113: #当线程数量大于113时,return
return
else:
break
主函数部分(多线程)
threads = [] #存放线程
for t in threads:
t.join()
print('图像地址爬取完毕')
保存图片
def Save_img(img_url,cnt):
resp = requests.get(img_url)#requests.get()发送请求
f = open('./imgs/' + str(cnt) + '.jpg', 'wb') # 二进制保存
f.write(resp.content) # 写入
print('存入第' + str(cnt) + '张图片',end=' ')
print(img_url)
cnt += 1
运行结果
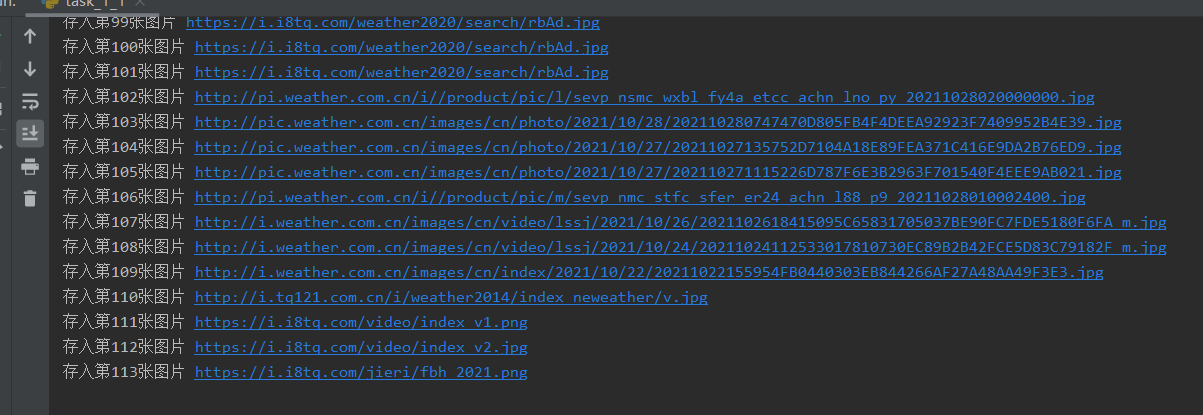
单线程:
干净整洁
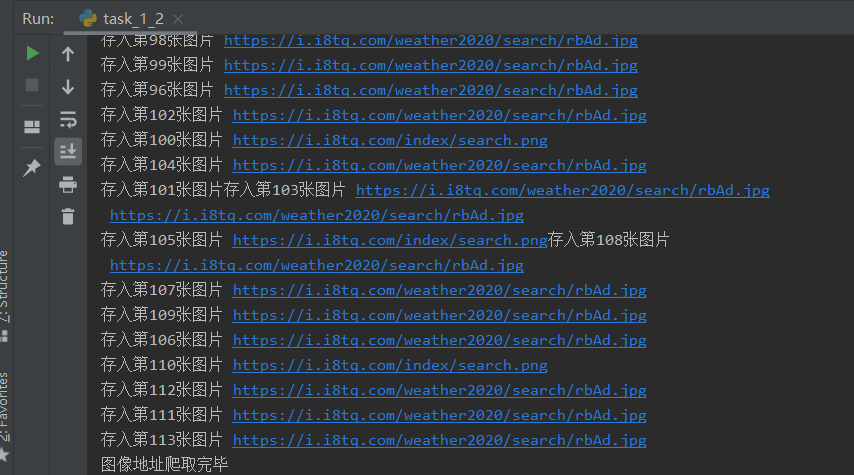
多线程:
看得出来多线程爬取,线程之间无顺序可言。(甚至打断print
心得体会
1.多线程相比与单线程爬取,速度会快上不少,体现了线程的并发性。
2.这边的思路是先将img的地址存储到列表中,再进行多线程爬取图片,相比于直接多线程访问url进行搜索a标签下的链接再进行爬取图片的思路,会更简单一点。
作业二
- 要求:使用scrapy框架复现作业①。
- 输出信息:
将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
实验过程
信息获取
items.py中编写需要爬取的信息
class ImgsItem(scrapy.Item):
img_url = scrapy.Field()#图像的地址
Spider.py中实现数据爬取操作
导入Item,将Scrapy项目设置为 Sources Root
name = "Spider_t2" #Spider name
start_urls = 'http://www.weather.com.cn/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
}
#发送请求
def start_requests(self):
yield scrapy.FormRequest(url=self.start_urls, callback=self.parse, headers=self.headers, method="GET")
callback 实现访问网页后要做的操作
获取页面地址:
def parse(self, response):
try:
data = response.body.decode() # 解码
soup = BeautifulSoup(data, 'lxml')
self.urls.append(Spider_t2.start_urls) # 将起始页面添加到urls中,以便爬取图像
tags = soup.select("a[href]") # css选择 a标签下有href这个属性的节点
for tag in tags:
new_url = tag.get('href') # 遍历节点,获得属性为href的值
# href的值要满足http开头以及不在urls中才能被添加进urls中,前者是为了使链接合法,能被访问;后者是去重,防止重复的网站被添加进urls中
if new_url[0:4] == "http" and new_url not in self.urls:
self.urls.append(new_url)
for i in range(len(self.urls)): #遍历urls,获取页面中的img
#这边的77是经过测试,调整的 若76会不够113张
if i > 77:
return
if self.cnt > 114: #设置当爬取数量大于114时,break
break
#访问的url为urls中的网址
#再次发起请求,callback=self.parse_findimg ,为爬取图片写的parse
yield scrapy.FormRequest(url=self.urls[i], callback=self.parse_findimg, headers=self.headers,
method="GET")
except Exception as err:
print(err)
获取图像地址:
def parse_findimg(self, response, **kwargs):
try:
img_count = 0 #计算当前页面下爬取的图片数量
item = ImgsItem() #设置item类
data = response.body.decode() # 解码
soup = BeautifulSoup(data, 'lxml')
tags = soup.select("img[src]") #通过css选择 获取img标签中含有src的节点
for tag in tags: #遍历节点
new_url = tag.get('src') #获取src的属性值
# src的值要满足http开头以及不在img_urls中才能被添加进urls中,前者是为了使链接合法,能被访问;后者是去重,防止重复的图片地址被添加进img_urls中
if new_url[0:4] == "http" and new_url not in self.img_urls:
item["img_url"] = new_url #写入item
self.img_urls.append(new_url)
self.cnt += 1 #总共爬取的图片数量+1
img_count += 1 #当前页面爬取的图片数量+1
yield item
#如果当前页面爬取的图片数量大于5,直接break
if img_count > 5:
break;
#如果总共爬取的图片数量大于114,break
if self.cnt > 114:
break
except Exception as err:
print(err)
编写Pipelines
数据存储在 pipelines.py 中处理
将图片存储到本地
try:
resp = requests.get(item['img_url'])#通过requests访问图像地址
f = open('./imgs/031904113_' + str(ImgPipeline.count) + '.jpg', 'wb') # 二进制保存
f.write(resp.content) # 写入
f.close() #关闭
# 打印 爬取的图片序号以及地址
print(ImgPipeline.count, end=' ')
print(item['img_url'])
except Exception as err:
print(err)
Settings
设置信息在settings.py中修改
将ROBOTSTXT_OBEY设置为False
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
修改PIPELINES,类名为pipelines中写的类(ImgPipeline)
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'task3_2.pipelines.ImgPipeline': 300,
}
执行函数
run.py 实现能够在编译器运行Scrapy
Spider_t2 为爬虫名,在Spider中设置name
from scrapy import cmdline
cmdline.execute("scrapy crawl Spider_t2 -s LOG_ENABLED=False".split())
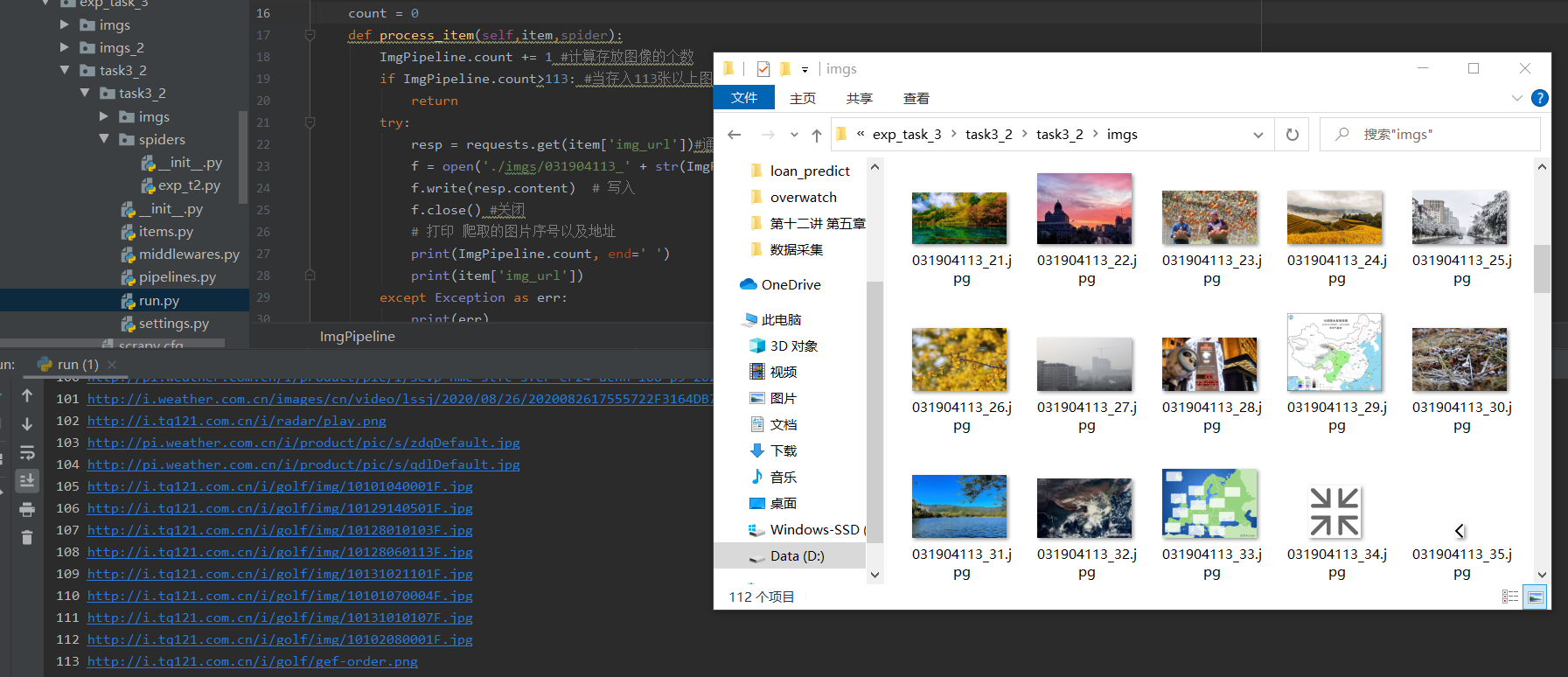
运行结果
心得体会
1.对多线程爬取的控制不够,导致爬取图片会停不下来。后来改写成爬取一定数量页面后,程序可以自然停止。
2.复习了Scrapy框架,加强了对Scrapy的理解,对Scrapy的工作流程有了更深的体会。
3.对Scrapy框架中各py文件(Spider.py,items.py,Pipelines.py...)的作用有了一定的理解。
作业三
-
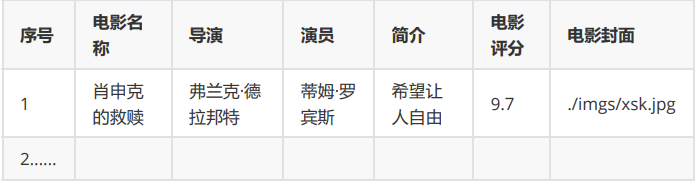
要求:爬取豆瓣电影数据使用scrapy和xpath,并将内容存储到数据库,同时将图片存储在
imgs路径下。 -
输出信息:
实验过程
信息获取
items.py中编写需要爬取的信息
class MovieItem(scrapy.Item):
id = scrapy.Field() #电影排名
name = scrapy.Field() #电影名称
director = scrapy.Field()#导演
actor = scrapy.Field() #主演
introduction = scrapy.Field() #简介
score = scrapy.Field() #评分
img_src = scrapy.Field() #封面(图像地址)
Spider.py中实现数据爬取操作
导入Item,将Scrapy项目设置为 Sources Root
from task3_3.items import MovieItem
翻页查看网页url变化,发现其变化规律是25个电影信息一页



name = "Spider_t3"
start_urls = 'https://movie.douban.com/top250' # 爬取网页的首地址
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
}
params = {
"start": 'temp'} # 页面数,暂时以temp代替
def start_requests(self):
for index in range(4): # 爬取4页 (爬太多很危险
self.params['start'] = str(25 * index) # 页面参数 转换成str
yield scrapy.FormRequest(url=self.start_urls, callback=self.parse, headers=self.headers, method="GET",
formdata=self.params)
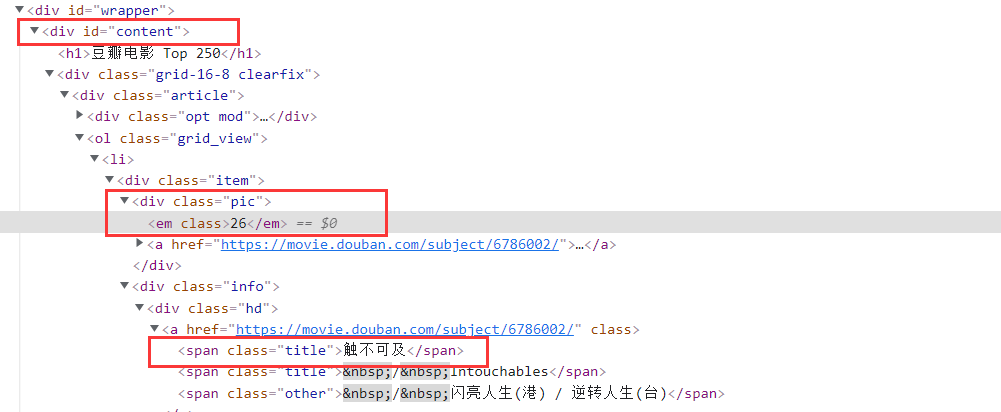
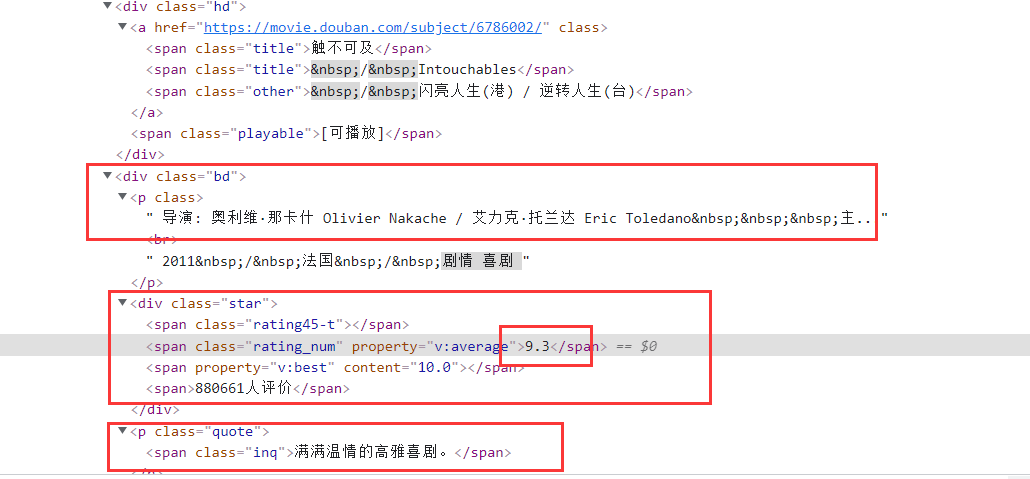
通过分析网页的元素,用Xpath去定位元素位置
获取主要信息以及该影片的主页面地址:
由于有些影片主演字段不全,甚至没有,需要进入该影片的主页面再进行信息提取
data = response.body.decode() # 解码
selector = scrapy.Selector(text=data) # Xpath选择器
id = selector.xpath('//*[@id="content"]/div/div[1]/ol//div/div[1]/em/text()').extract() # 获取序号信息
name = selector.xpath('//*[@id="content"]/div/div[1]/ol//div/div[2]/div[1]/a/span[1]/text()').extract() # 获取名称信息
# 由于主页面演员信息显示不全,获取演员的信息需要进入其主页面,故获取该影片的主页面url
director_url = selector.xpath('//*[@id="content"]/div/div[1]/ol//div/div[2]/div[1]/a/@href').extract()
introduce = selector.xpath('//*[@id="content"]/div/div[1]/ol//div/div[2]/div[2]/p[2]/span/text()').extract() # 获取简介信息
score = selector.xpath('//*[@id="content"]/div/div[1]/ol//div/div[2]/div[2]/div/span[2]/text()').extract() # 获取评分信息
img = selector.xpath('//*[@id="content"]/div/div[1]/ol//div/div[1]/a/img/@src').extract() # 获取图像地址信息
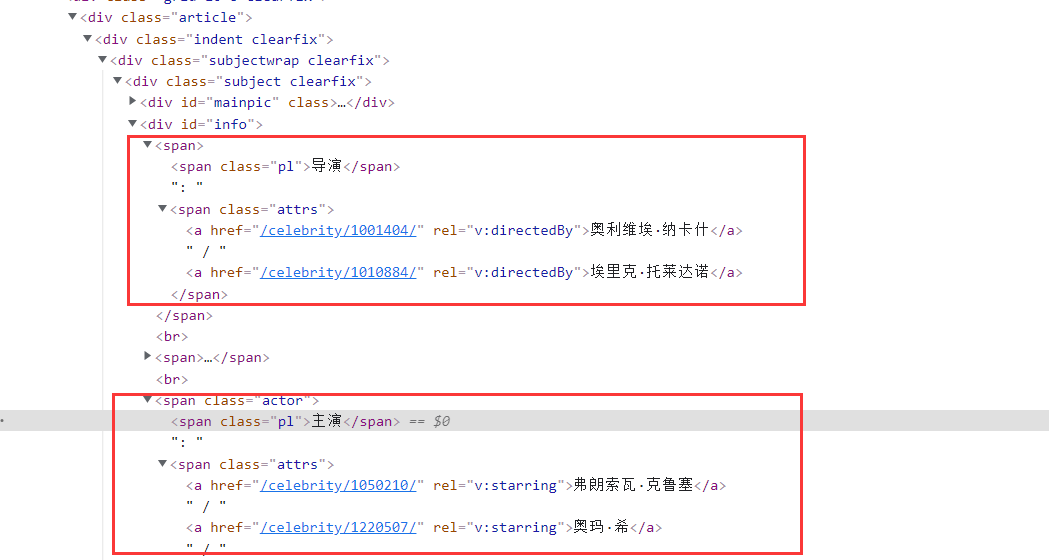
获取各字段信息:
用requests发起请求,这边解码方式要选定utf-8,自适应解码会乱码。
用Xpath定位导演和主演,提取信息
注意:
用extract()提取后是以列表形式返回值的,需要将其转化成字符串。
for i in range(len(id)): # 遍历一页的电影信息
resp = requests.get(director_url[i], headers=self.headers) # 用requests.get()访问各个电影的主页面
resp.encoding = "utf-8" # 这边自适应解码会乱码= =,换成utf-8可以正常浏览
page = resp.text
selector = scrapy.Selector(text=page) # Xpath选择器
director = selector.xpath('//*[@id="info"]/span[1]/span[2]//text()').extract() # 获取导演信息,以列表形式返回
actor = selector.xpath('//*[@id="info"]/span[3]/span[2]//text()').extract() # 获取主演信息,以列表形式返回
director = ''.join(director) # 将导演信息列表拼接
actor = ''.join(actor) # 主演信息列表拼接
存入item的数据类型要字符串类型
# 将各信息存入item
item = MovieItem() # 创建item项
item["id"] = id[i]
item["name"] = name[i]
item["director"] = director
item["actor"] = actor
item["introduction"] = introduce[i]
item["score"] = score[i]
item["img_src"] = img[i]
yield item
编写Pipelines
数据存储在 pipelines.py 中处理
将图片存储到本地以及将爬取信息存入数据库
图片存取和之前一样,以二进制方式写入。
# 存入数据库
conn = pymysql.connect(host="localhost", user="root", password="root", database="task",
charset='utf8') # 连接数据库
cs1 = conn.cursor() # 建立游标
# 表创建 格式定义
sqlcreat = '''
create table if not exists exp3_3(
序号 int(5) not null,
名称 char(20) not null,
导演 char(40) not null,
演员 text(200) not null, #因为演员字符过长,用char会提示 Data too long
简介 char(50) not null,
评分 char(10) not null,
封面 char(80) not null
)
'''
cs1.execute(sqlcreat)
sql = '''INSERT INTO exp3_3(序号,名称,导演,演员,简介,评分,封面) VALUES("%s","%s","%s","%s","%s","%s","%s")'''
arg = (int(item['id']), item['name'], item['director'], item['actor'], item['introduction'], item['score'],
item['img_src']) # 设置存入信息
cs1.execute(sql, arg)
conn.commit()
Settings
设置信息在settings.py中修改
将ROBOTSTXT_OBEY设置为False
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
修改PIPELINES,类名为pipelines中写的类(ImgPipeline)
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'task3_3.pipelines.MoviePipeline': 300,
}
执行函数
run.py 实现能够在编译器运行Scrapy
Spider_t3 为爬虫名,在Spider中设置name
from scrapy import cmdline
cmdline.execute("scrapy crawl Spider_t3 -s LOG_ENABLED=False".split())
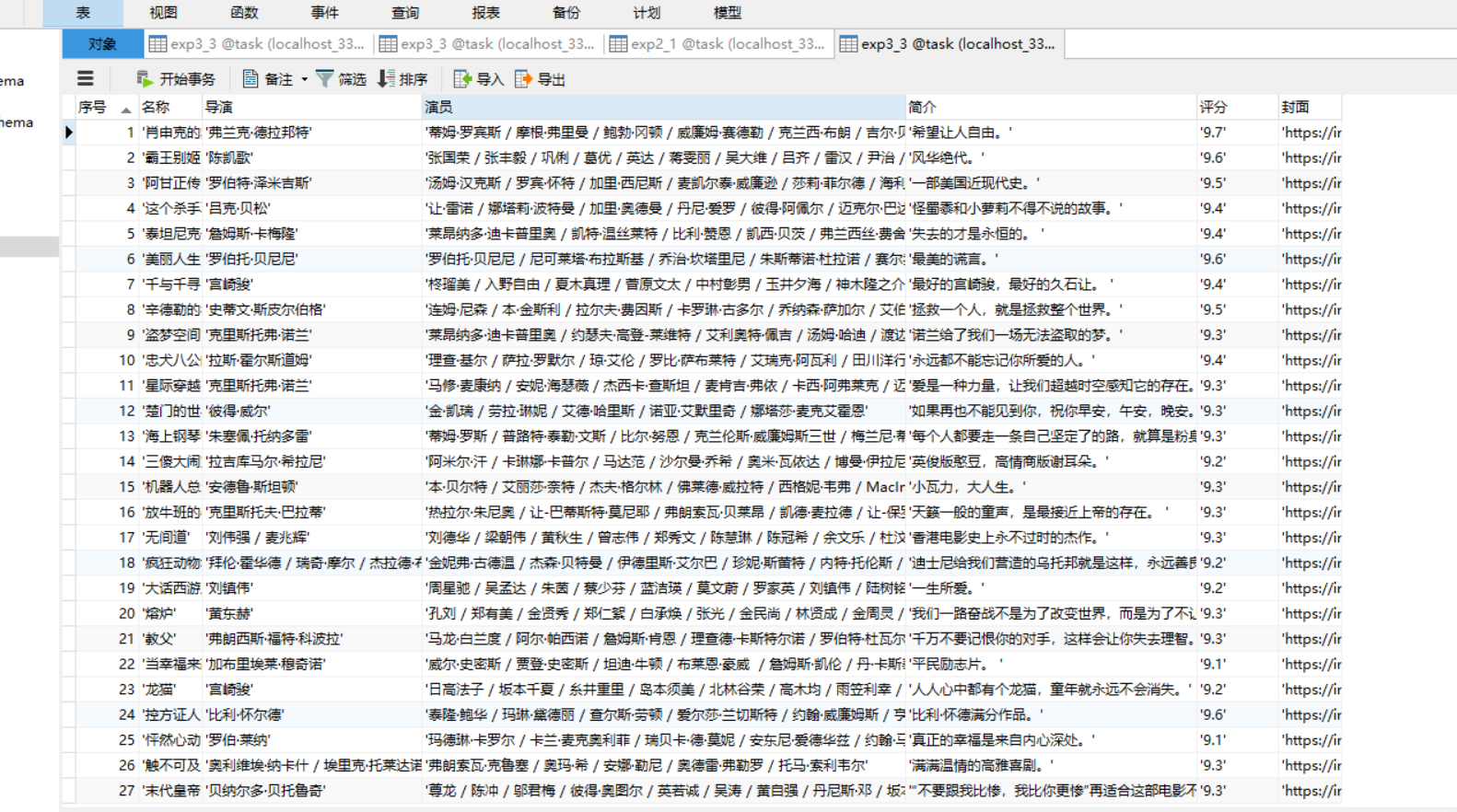
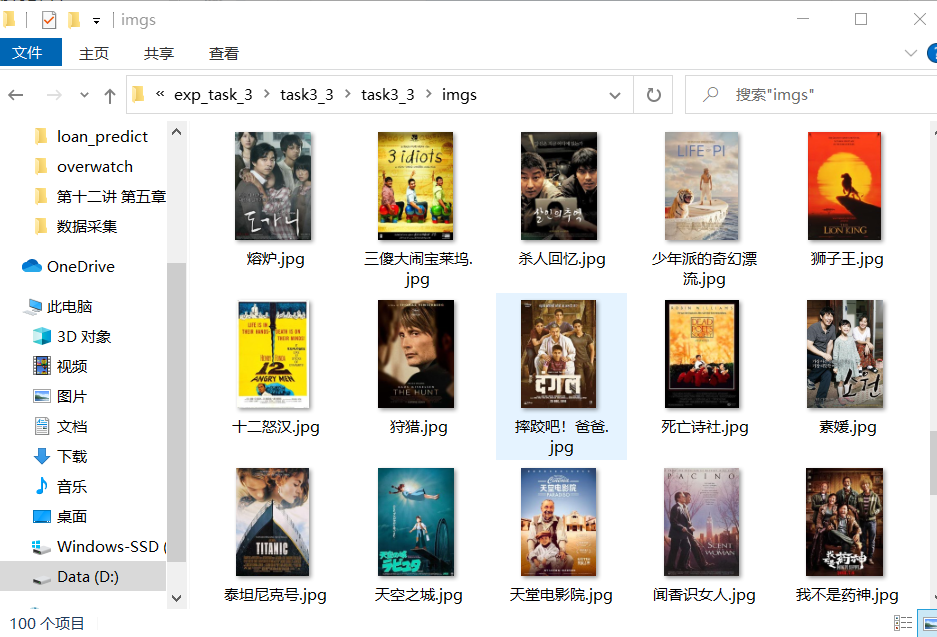
运行结果
按序号字段升序排列
心得体会
1.进行翻页操作时发现以'主演'字段分隔去获取导演和主演的信息会出现数组越界的错误,查清原因后发现有些影片的主演字段在top榜单页面没有显示出来,所以后来将程序改写成进入影片主页面获取导演和主演的信息。
2.将信息存入数据库时,出现报错

演员字段过长,于是将其从char改成text格式,并增加长度上限,解决该问题。
3.意识到自己对数据库的操作不是很熟,需要更多的学习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号