数据采集第二次作业
作业1
- 要求: 在中国气象网( http://www.weather.com.cn )给定城市集的7日天气预报,并保存在数据库。
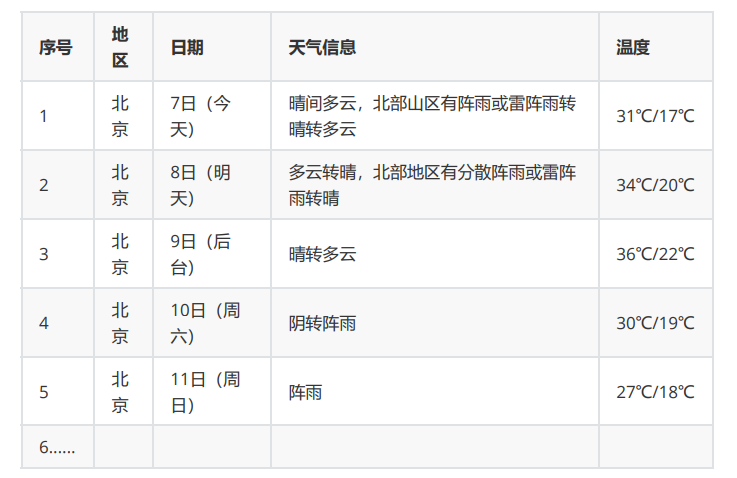
实验过程
获取html
def getHTMLText(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
}
resp = requests.get(url=url, headers=headers)
resp.encoding = resp.apparent_encoding # 自适应解码
return resp.text
except:
return 'error'
通过正则寻找相关信息
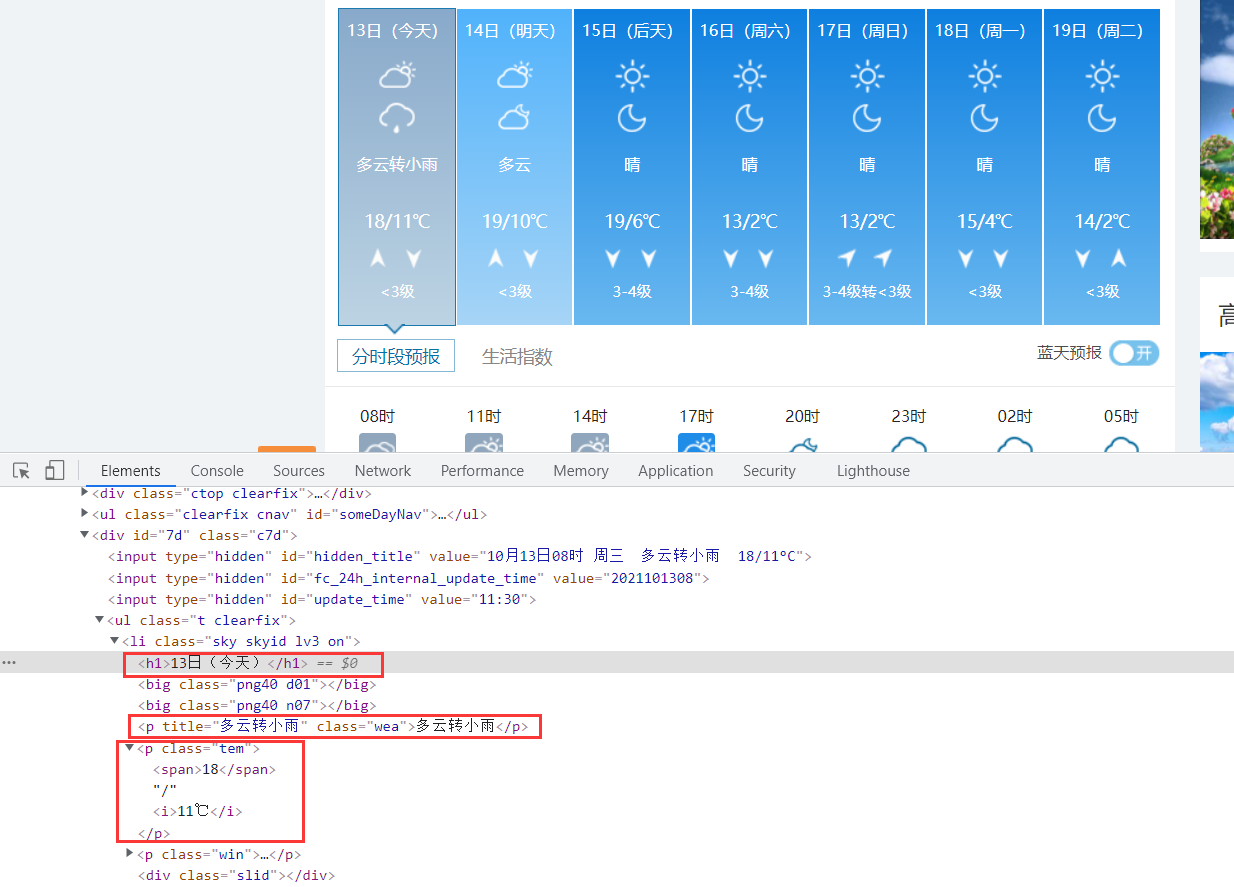
通过页面源码分析,发现日期,天气信息,最高温与最低温分别在h1,p,p标签中,则可以通过正则匹配对应信息
def find_data(data):
date = [] # 存储日期
mes = [] # 存储天气信息
tmp = [] # 存储温度
# 查找日期
reg_date = r'<h1>(.*?)</h1>'
res_date = re.findall(reg_date, data, re.S) # 设置re.S模式
# 查找天气信息
reg_mes = r'<p title="(.*?)" class="wea">.*?</p>'
res_mes = re.findall(reg_mes, data, re.S)
# 查找最高温度以及最低温度
reg_tem = r'<p class="tem">(.*?)</i>.*?</p>'
res_tem = re.findall(reg_tem, data, re.S)
for i in range(7):
date.append(res_date[i])#添加日期
mes.append(res_mes[i])#添加天气信息
res_tem[i] = re.sub('<.*?>', '', res_tem[i])#正则替换包括在< >中所有的字符串成空
res_tem[i] = re.sub('\n', '', res_tem[i])#把换行换成空
tmp.append(res_tem[i])#添加温度信息
return date, mes, tmp #返回日期,天气信息,温度
数据保存
数据保存到数据库中,调用pymysql:
def Save_mysql():
conn = pymysql.connect(host="localhost", user="root", password="123", database="task", charset='utf8') #连接,其中database为数据库名称
cs1 = conn.cursor() #创建游标对象
sqlcreate = '''
create table if not exists exp2_1(
序号 char(20) not null,
日期 char(20) not null,
地区 char(20) not null,
天气信息 char(50) not null,
温度 char(20) not null)
'''
cs1.execute(sqlcreate)
sql = '''INSERT INTO exp2_1(序号, 日期, 地区, 天气信息, 温度) VALUES("%s","%s","%s","%s","%s")'''
for i in range(7):
arg = (i + 1, '北京', date[i], mes[i], tmp[i]) #设置存入信息
cs1.execute(sql, arg)
conn.commit()
用数据库可视化工具(Navicat)查看数据
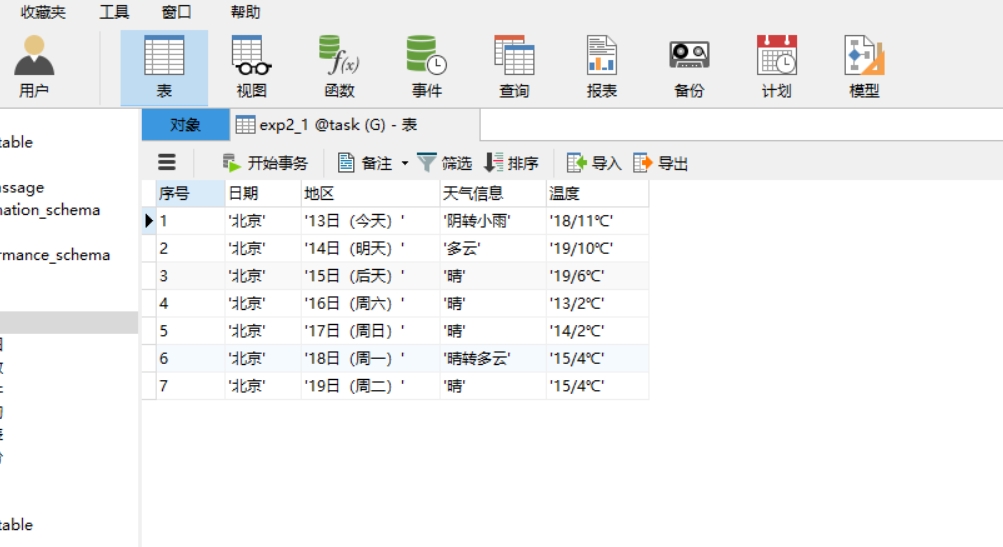
实验心得
1.通过正则匹配中查找对应元素位置时要设置re.S模式,否则会有看不见的符号导致匹配失败。
2.使用pymysql时使用以前写的模板方便了自己,提醒了自己的代码的模块化,方便自己以后使用。
作业二
- 要求: 用requests和自选提取信息方法定向爬取股票相关信息,并存储在数据库中。
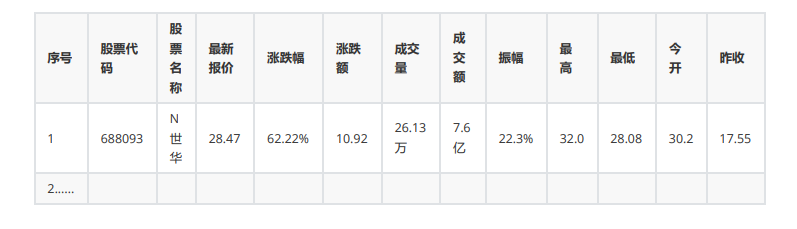
- 候选网站:
东方财富网:https://www.eastmoney.com/
新浪股票:http://finance.sina.com.cn/stock/ - 技巧:
在谷歌浏览器中进入F12调试模式进行抓包,查找股票列表加载使用的url,并分析api
返回的值,并根据所要求的参数可适当更改api的请求参数。根据URL可观察请求的参数f1、
f2可获取不同的数值,根据情况可删减请求的参数。
参考链接:https://zhuanlan.zhihu.com/p/50099084
实验过程
寻找js请求
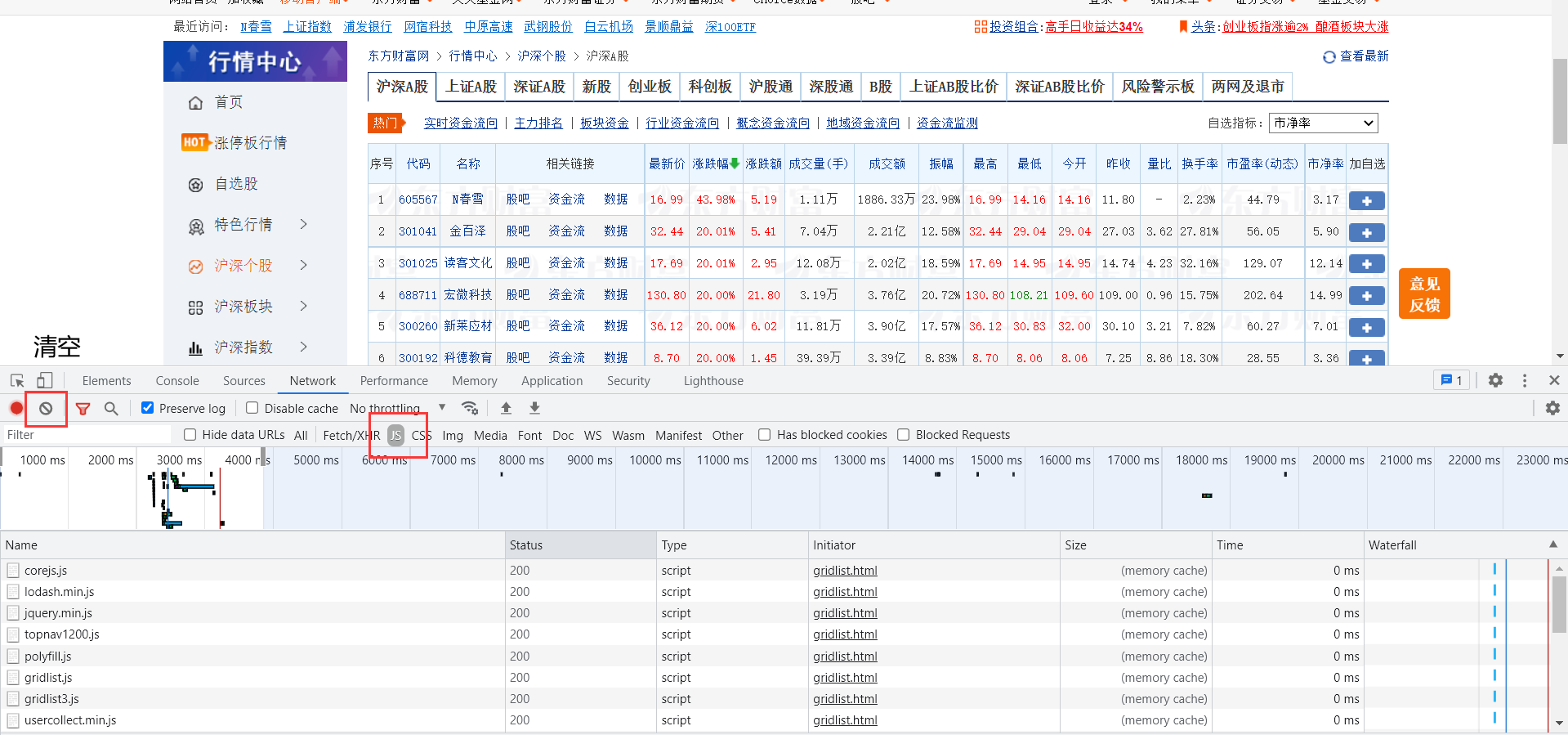
先选中js文件,然后清空,在清空后刷新一下页面(方便观察)。
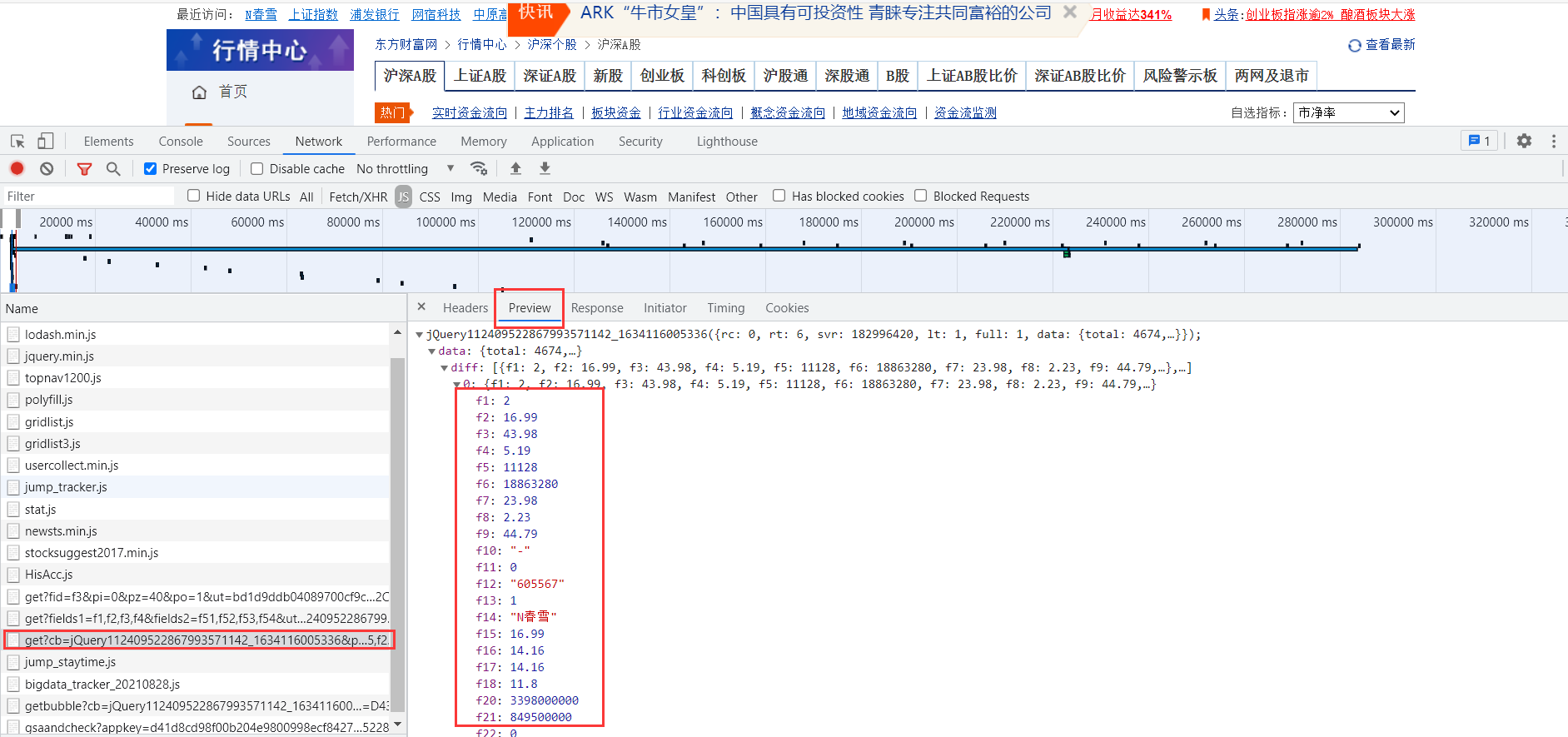
在Preview中可查看数据,找到对应的js包后,点击Headers
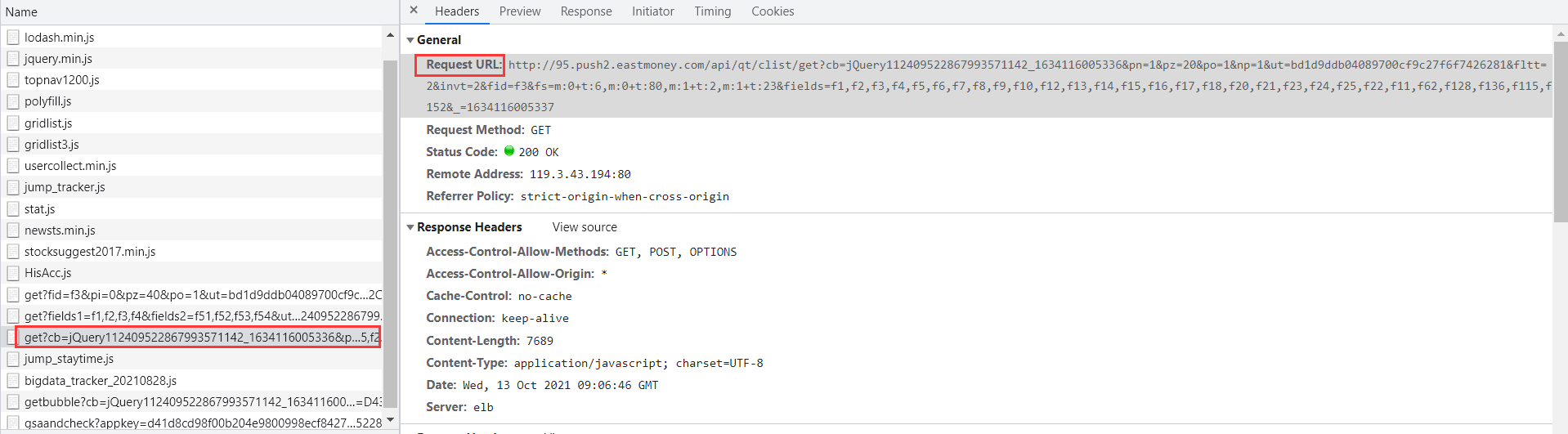
上图的Request URL便是我们要找的。
通过浏览器直接访问:
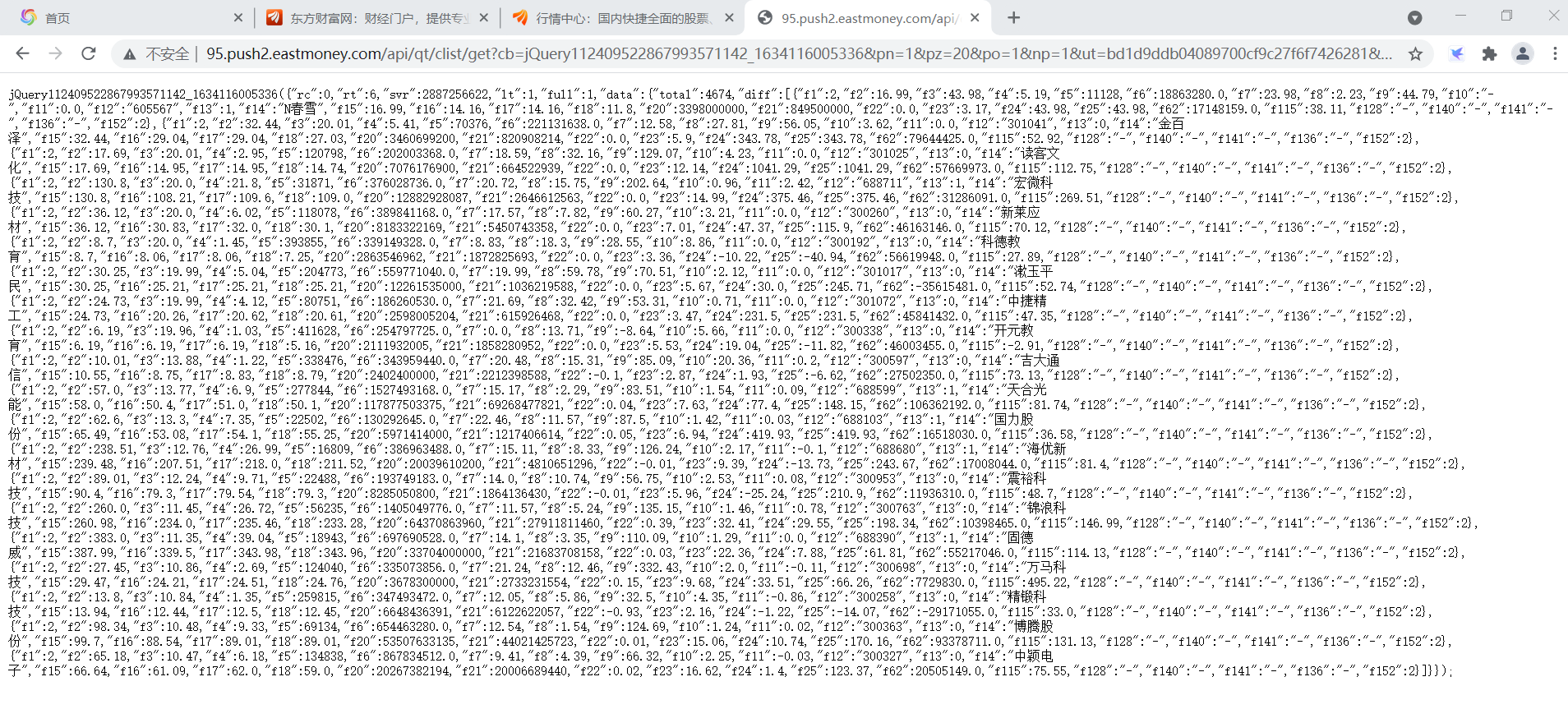
构造请求头,用requests.get()方法访问该ur获取html文本,与前面方法一致。
def getHTMLText(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
}
resp = requests.get(url=url, headers=headers)
resp.encoding = resp.apparent_encoding # 解码
return resp.text
except:
return 'error'
正则匹配对应信息
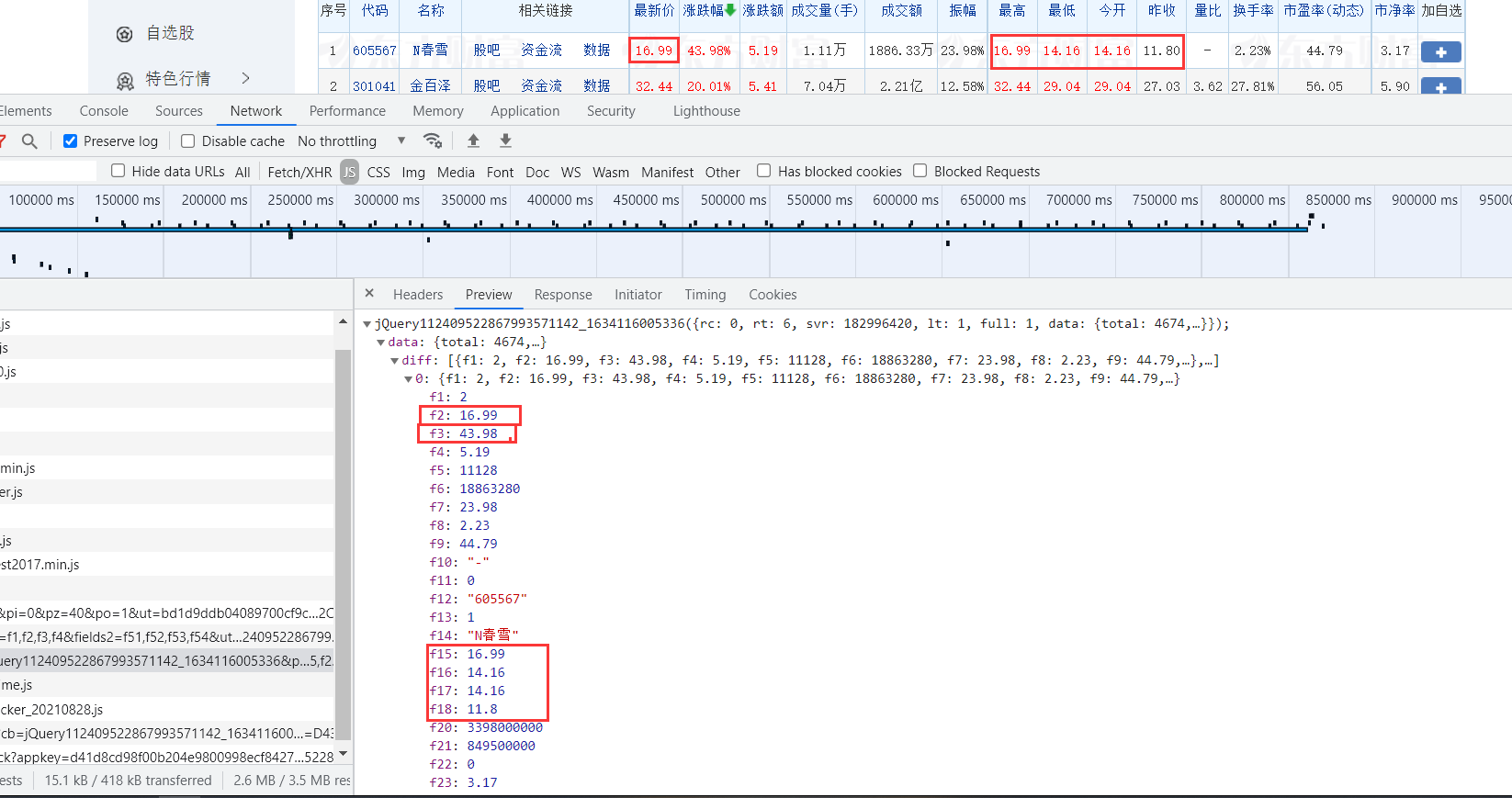
在diff中的都是相关数据,我们要寻找的也就在其中
处理好参数与各个值的对应关系,通过正则匹配将数据爬取出来。举个例子:
code = re.findall(r'"f12":"(.*?)"',data,re.S) #股票代码
name = re.findall(r'"f14":"(.*?)"',data,re.S) #股票名称
last_price = re.findall(r'"f2":(.*?),',data,re.S) #最新报价
chg = re.findall(r'"f3":(.*?),',data,re.S) #涨跌幅
......
数据保存
与题一的方法一致,调用pymysql保存数据。
用数据库可视化工具(Navicat)查看数据
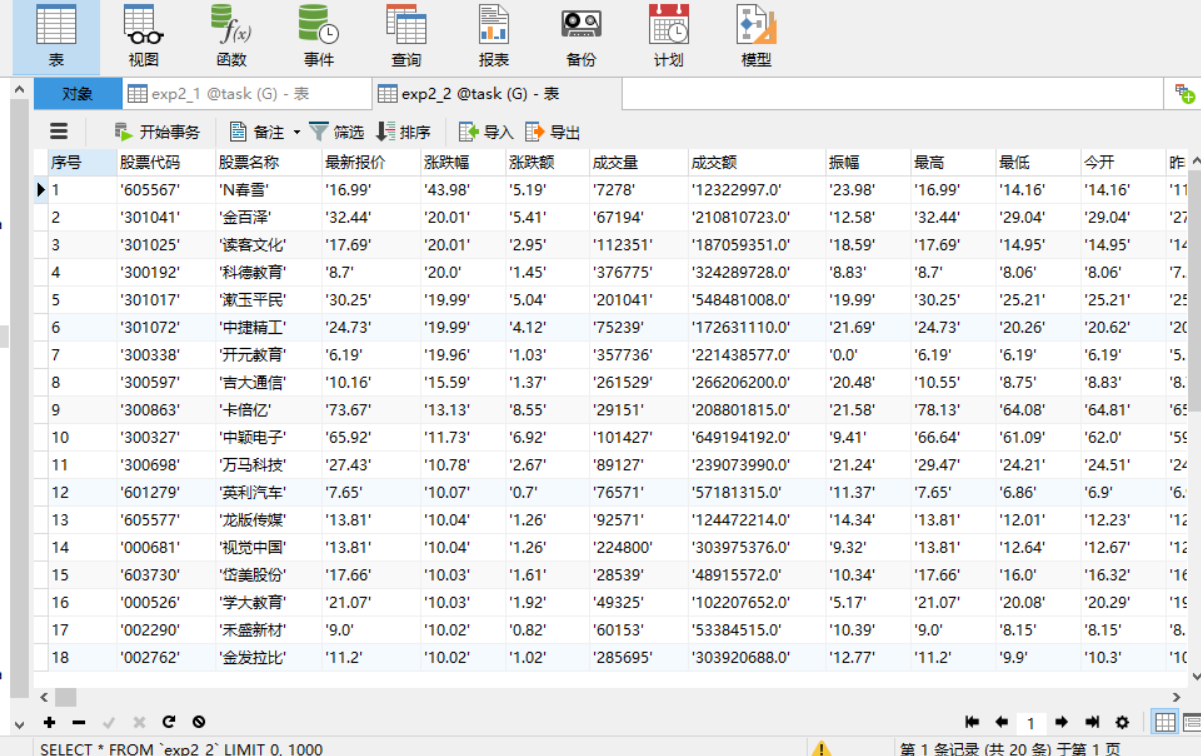
实验心得
1.获取的HTML与我们看到的不一样,里面不含有数据,这时候应该知道审查中看到的可能是经过js渲染过的,故要寻找js包请求。
2.这和以前碰到的找js请求然后通过post传参访问url有一点区别,这种可以直接访问url。
作业三
- 要求: 爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)
所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。

实验步骤
寻找js请求
打开url只有第一页的学校信息,翻页过程url也没有发生变化,故考虑是附在js文件中生成的。
进行抓包:首先清空页面的js请求,然后刷新,再到js请求中去寻找相应的数据。
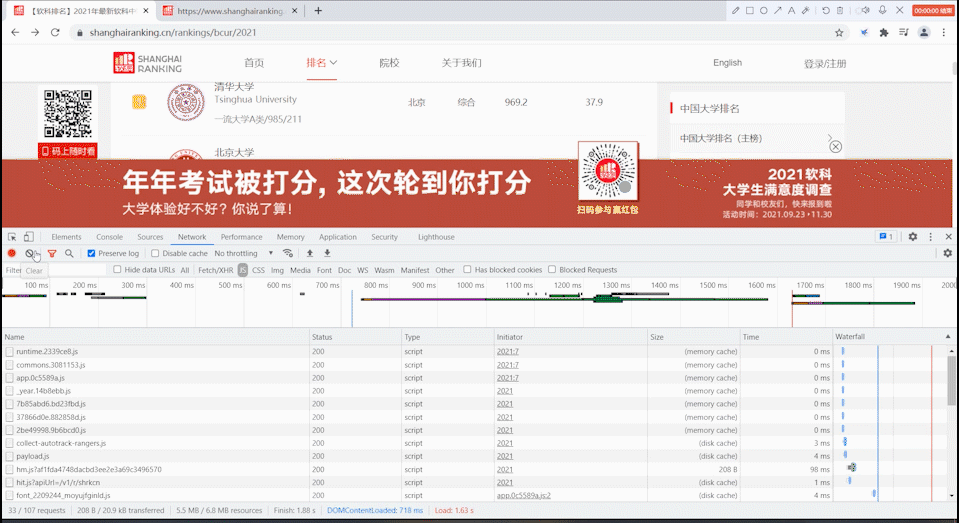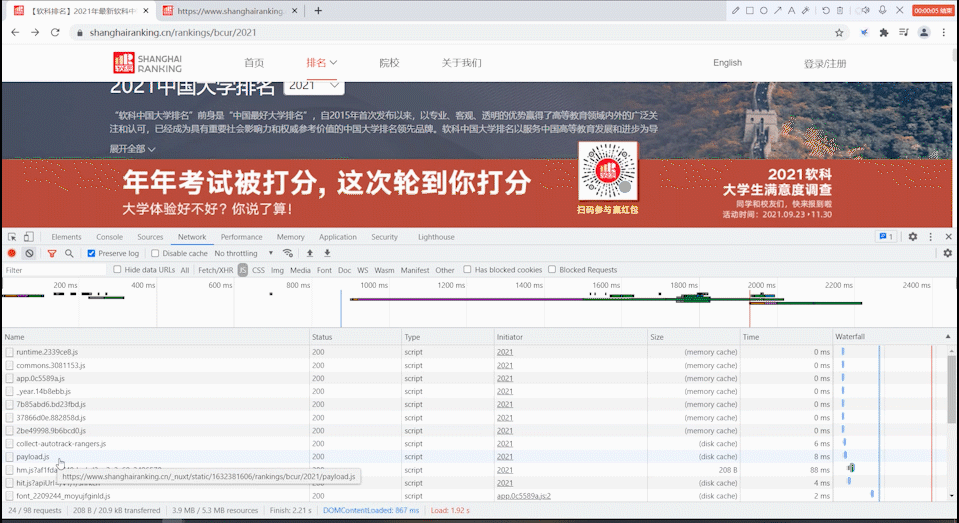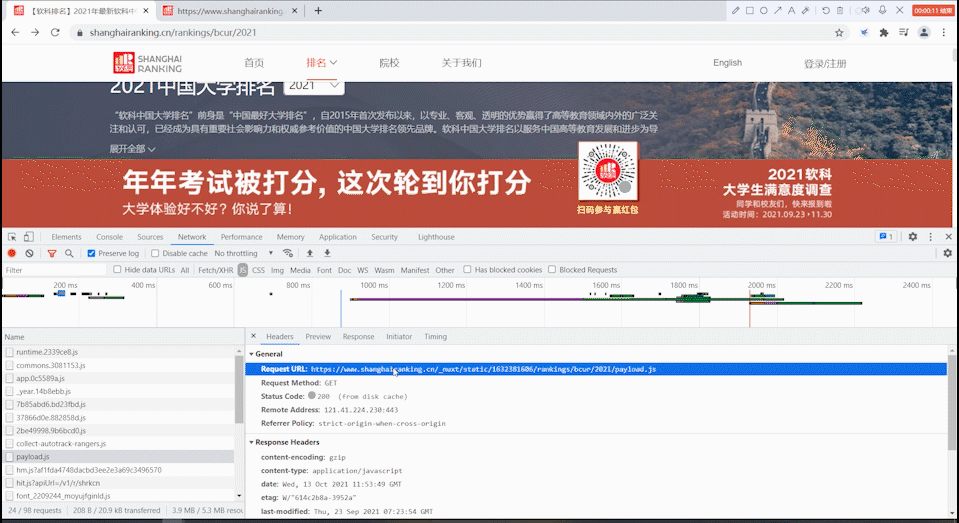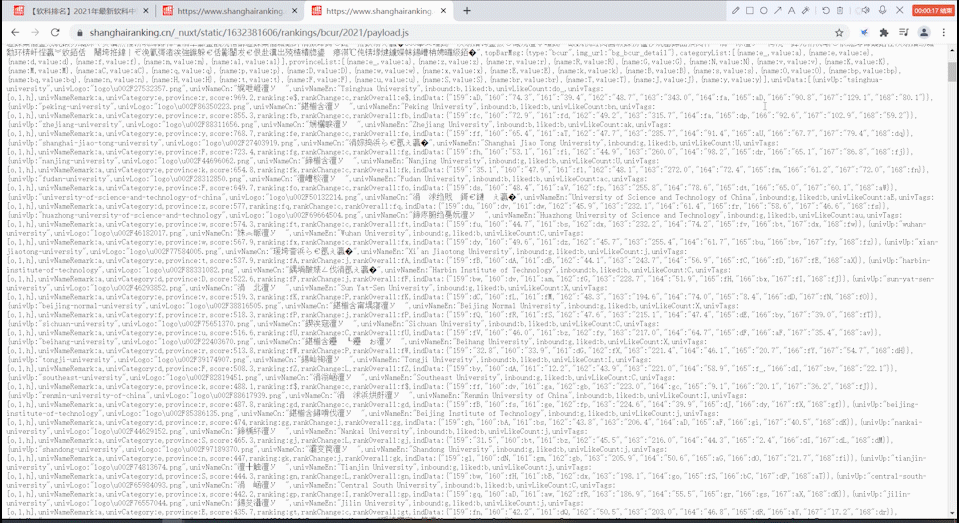
找到相应的url后,用requests.get()方法访问该ur获取html文本。与前面方法一致。
正则匹配信息
由于网页打开是乱码,故将其转码后输出,保存到txt文件中分析:
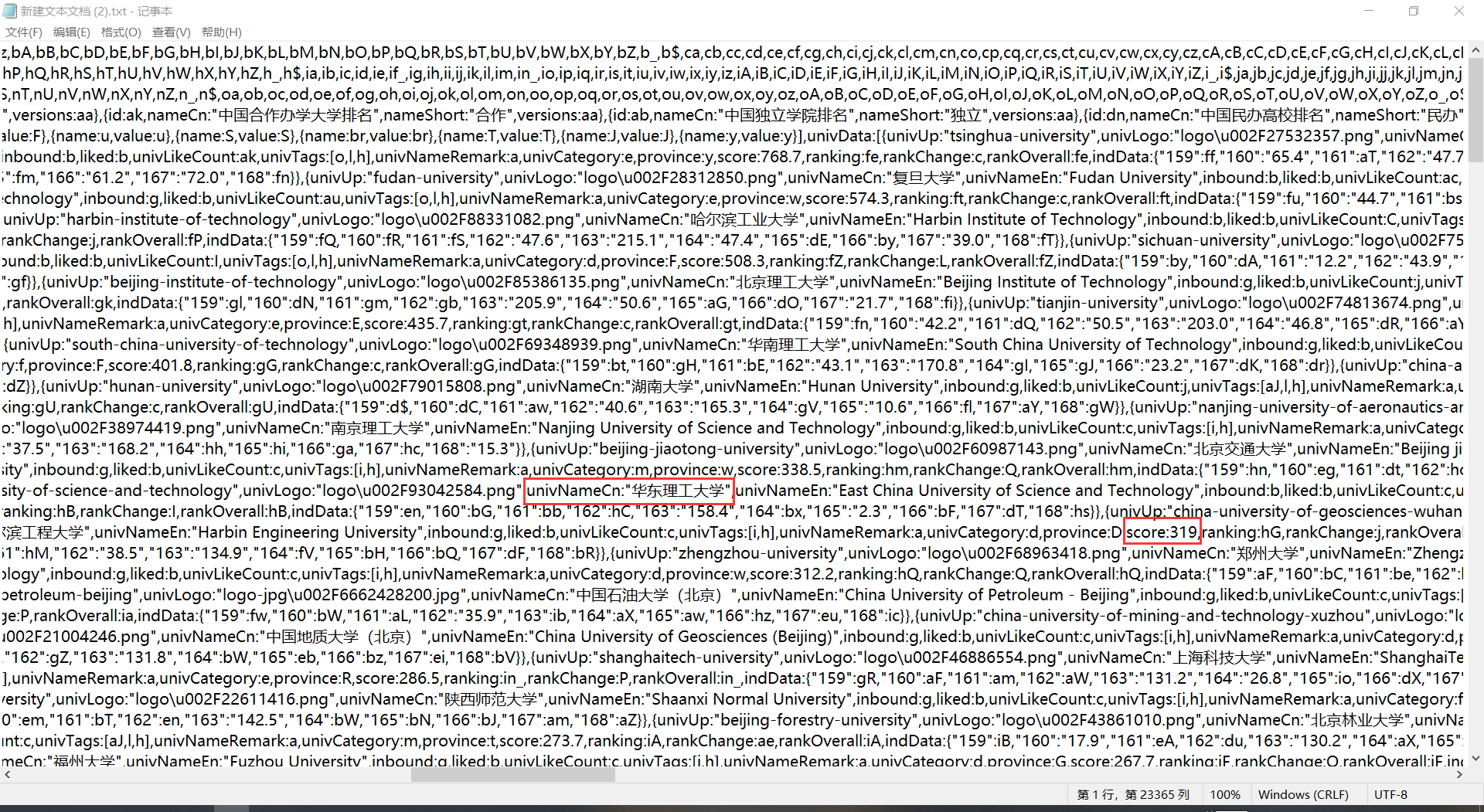
找到对应信息的结构,用正则匹配将其找到。
def find_data():
# 正则匹配相关信息
name = re.findall(r'univNameCn:"(.*?)"', data, re.S)
score = re.findall(r'score:(.*?),', data, re.S)
return name, score
数据保存
打印过程中发现其中有些学校并没有实际得分,是以字符串代替,便以null替换。
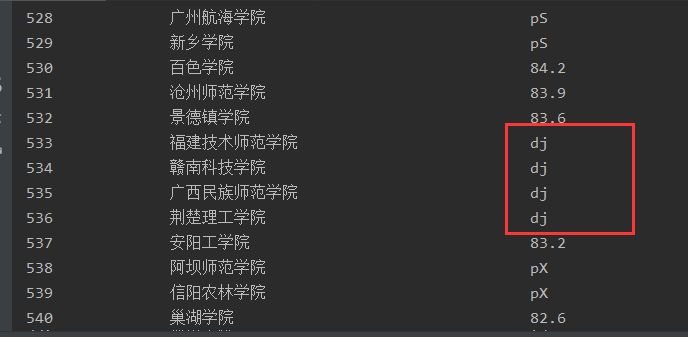
def print_data():
print("{0:{ocp}<8}\t{1:{ocp}<20}\t{2:{ocp}<8}".format("排名", "名称", "总分", ocp=chr(12288)))
for i in range(len(name)):
# 如果score中的字符串无法强制转换为float,则用null代替
try:
float(score[i])
except:
score[i] = 'null'
print("{0:{ocp}<8}\t{1:{ocp}<20}\t{2:{ocp}<8}".format(i + 1, name[i], score[i], ocp=chr(12288)))
转换后效果图:
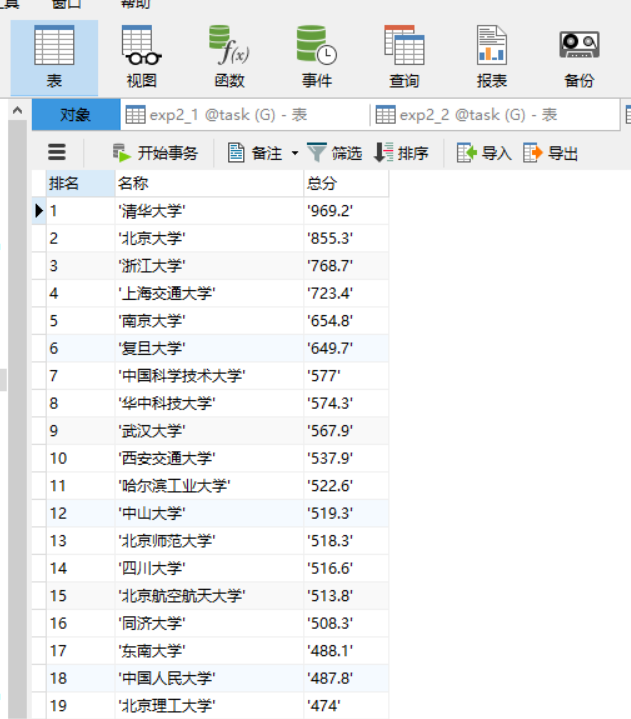
存入数据库方法与前边作业一致,调用pymysql。
实验心得
1.页面解析还是不太懂,需要多多学习css,JavaScript等相关知识,这样能更好的了解页面渲染以及爬取相关数据。
2.通过F12抓包获取所有学校的信息,再用正则匹配寻找相关数据。让我对页面渲染和正则匹配有了更多的理解和体会。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号