TokuDB的特点验证
随着数据量越来越大,越来越频繁的遇到需要进行结构拆分的情况,每一次拆分都耗时很久,并且需要多方配合,非常的不想搞这个事情。于是在@zolker的提醒下想到了13年开源tokuDB,来解决我们迫在眉睫的容量问题。
坊间流传tokuDB有如下几个看着令人垂涎欲滴的特点,正好符合我们实际环境的需求,故针对每个特点进行了针对性测试:
1、高压缩比,官方宣称可以达到1:12。
2、高insert性能,官方称至少比innodb高9倍。
3、可以在线添加索引和字段,速度快。
(前提:由于是为了解决线上的实际问题,故本次验证并不会按照严格的测试规范进行,所得数据也不是tokuDB的极限数据,只是在实际业务上的表现)
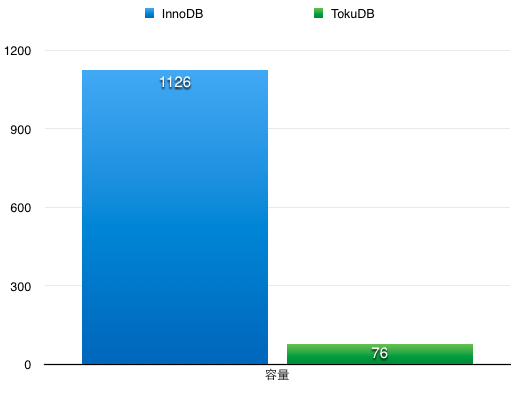
高压缩比:
原有数据库容量1126G,使用tokudb之后,压缩到76G,压缩比达到惊人的14倍。
高insert性能:
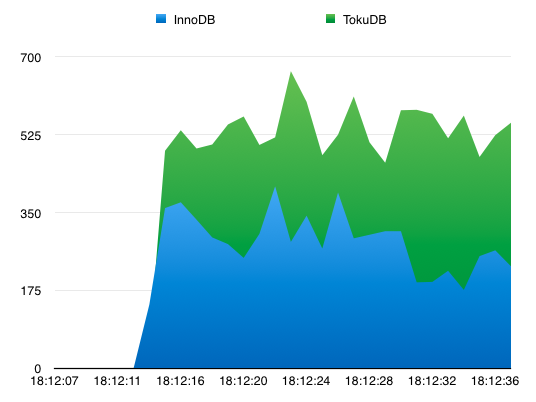
简单比较追同步的性能,同时在innodb和tokudb上阻塞同步3分钟,然后观察追同步的性能(不代表最大性能,因为会受限于mysql单线程追同步的瓶颈。io不会被充分利用到)
基本环境为SAS服务器,12*300G 15000转SAS盘,BP size相同。
可以明显看到在不改变基本配置,不增加多线程复制的情况下,tokudb的追同步性能高于innodb,大概在1.9倍。
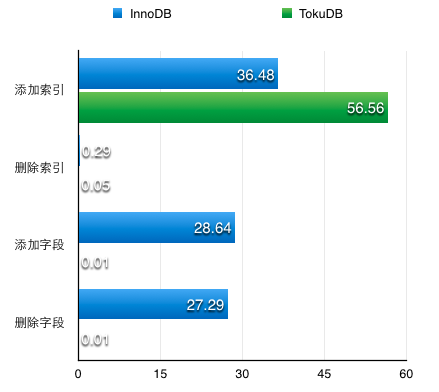
在线添加字段和索引:
测试目标表为425MB,所在服务器均为10块盘做RAID5的SSD服务器。
从下图可以看出
- 添加索引,innodb快,tokudb慢
- 删除索引,innodb快,tokudb超快
- 增加字段,innodb慢,tokudb超快
- 删除字段,innodb慢,tokudb超快
TokuDB在在线DDL操作的时候相对InnoDB有较大的优势。在索引方面,删除索引基本瞬间完成。在字段方案,添加/删除字段基本都是瞬间完成。
具体我们可以看下面的操作记录。
CREATE TABLE `timeline_1009` ( `uid` bigint(16) unsigned NOT NULL, `vflag` tinyint(4) unsigned NOT NULL DEFAULT '0', `status_id` bigint(16) unsigned NOT NULL, `source` int(6) unsigned NOT NULL DEFAULT '0', `fflag` int(6) unsigned NOT NULL DEFAULT '0', `mflag` tinyint(4) NOT NULL DEFAULT '0', PRIMARY KEY (`uid`) ) ENGINE=TokuDB DEFAULT CHARSET=utf8 ROW_FORMAT=TOKUDB_LZMA;
InnoDB操作记录:
>create index idx_flag on timeline_1009 (mflag); Query OK, 0 rows affected (36.48 sec) >drop index idx_flag on timeline_1009; Query OK, 0 rows affected (0.29 sec) >alter table timeline_1009 add column test_flag tinyint; Query OK, 4549087 rows affected (28.64 sec) >alter table timeline_1009 drop column test_flag; Query OK, 4549087 rows affected (27.29 sec)
TokuDB操作记录:
>create index idx_flag on timeline_1009(mflag); Query OK, 0 rows affected (56.56 sec) >drop index idx_flag on timeline_1009; Query OK, 0 rows affected (0.05 sec) >alter table timeline_1009 add column test_flag tinyint; Query OK, 0 rows affected (0.01 sec) >alter table timeline_1009 drop column test_flag; Query OK, 0 rows affected (0.00 sec)
innodb添加字段的时候会建立一个temp table,修改表结构后,会删除原表,并将临时表rename回原名字,所以就相当于对表进行了一次optimization,清理各种碎片,这也就是为什么add column的时候会有百万级别的rows affected。但是可以很明显的看到tokudb的rows affected为0,推测是tokudb在添加字段的时候,并不会采用innodb的方法。从官网的文档中获得的信息是,TokuDB会将添加字段的工作放在后台执行,而其快速的原因是将B-tree改为了Fractal-tree,其将随机IO替换为了顺序IO。领用Fractal-tree的特性,将HCAD命令广播到所有行上,而不是想InnoDB那样,需要open table并消耗很多的内存资源。
以上都是TokuDB的特点,接下来我们看看其对CPU、IOPS和RT的影响。以上3点是影响服务器负载和对外提供服务质量的关键数据。
测试背景,相同的slave,只不过引擎不通,在同一个时间点抓取数据,理论上认为承担的服务量相等。
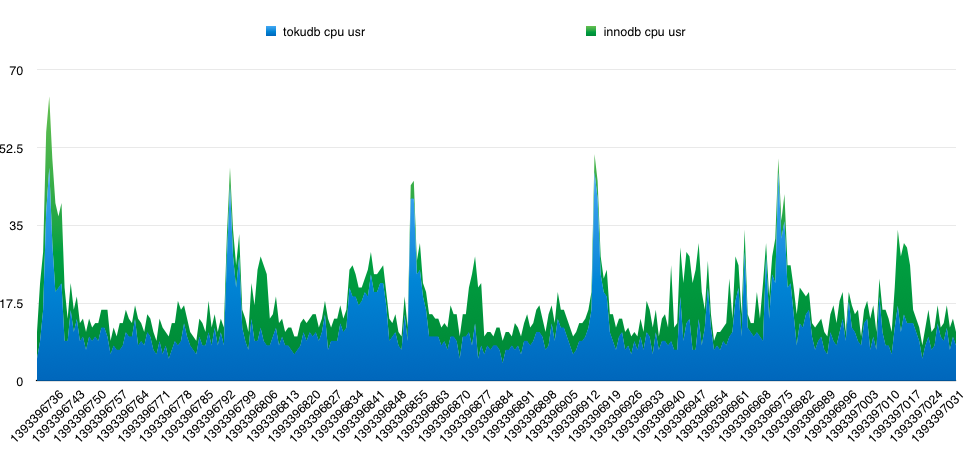
CPU消耗:
理论上经过大压缩比的数据库一定会比较消耗cpu的usr态,果然从下图中我们可以看出,tokudb比innodb对usr态的cpu消耗要多,平均在2倍左右。
IOPS消耗:
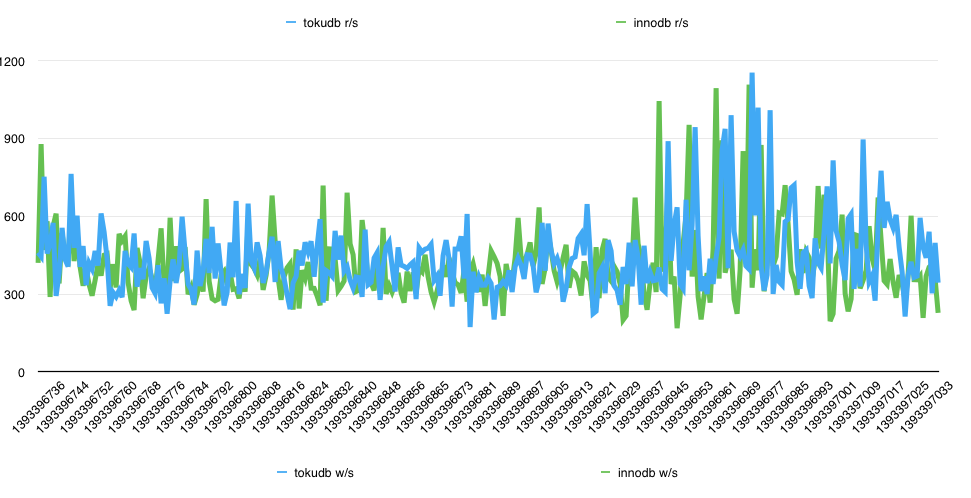
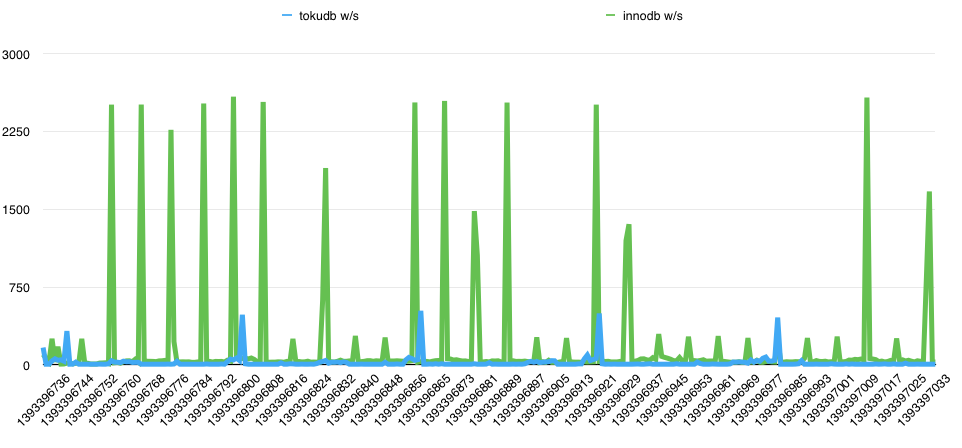
根据官方文档的说明,相同QPS的情况下,tokudb应该比innodb消耗更少的iops。我们从下面两个图可以看出,读的IOPS并没有太大的差别,但是写的IOPS innodb比tokudb平均多消耗了5.5倍。
RT响应时间:
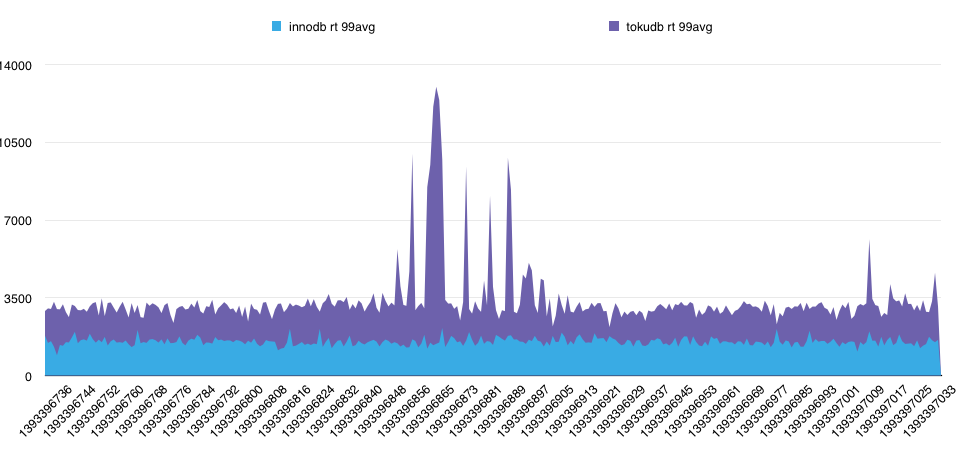
在响应时间上,由于整体数据库的size变小了,测试目标库innodb版本743G,tokudb版本61G。相对于BP=30G来说,明显tokudb更占优势。但是由于tokkudb的数据是经过高压缩的,在响应时间上应该还会多一部分解压的时间消耗,所以最终结果不好确认。
从测试结果看,tokudb的响应时间明显高于innodb的,其平均值大概高2.2倍。看来如果上了tokudb,响应时间是需要付出的代价。
总结:
TokuDB的优点:1、高压缩比 2、高insert性能 3、增删字段秒级。
TokuDB的缺点:1、cpu usr态消耗高 2、响应时间变长。
总体来说,TokuDB的特性非常的吸引人,能解决我们很棘手的问题。但是,看上去很美的东西,一定会有坑存在,排雷将是我们下一步的重点工作,这也是决定TokuDB到底能不能真正在线上使用的关键。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号