SDN网络虚拟化中有效协调的映射算法
来自论文An efficient and coordinated mapping algorithm in virtualized SDN networks,来自期刊《信息与电子工程前沿》
1.Introduction
这篇文章关注于虚拟SDN网络中的映射技术。不同于先前的工作,这篇文章是第一个考虑了控制器放置和VN映射作为结合的vSDN映射问题,并用公式表达它为多目标整形线性规划问题(integer linear programming ILP)来优化控制器到交换机时延和映射的花费。设计了一个新奇的在线vSDN映射算法‘CO-vSDNE’来解决它。这个算法由两步组成(1)节点映射,解决控制器放置及节点映射;(2)连接映射。
这篇论文主要贡献:
1.第一次尝试在线vSDN映射问题
2.制定了这个问题为多目标ILP并设计启发式算法称作CO-vSDNE来最小化控制器到交换机时延和映射花费
3.进行了广泛时延来评估这个算法,从时延,花费和收入,生产力等方面。
2.Related work
VN映射由两个部分组成。虚拟节点映射,映射到底层节点并满足虚拟节点的资源需求;虚拟连接映射,映射到无回路底层路径并满足虚拟连接资源需求。
先前工作大部分对于传统网络。也存在一些针对SDN网络。但既没有考虑控制器放置问题,也没考虑在节点映射时流表项资源分配问题。(Heller采用交换机和控制器间平均和最大时延作为性能度量,并评估上百种已存在网络拓扑,通过广泛模拟来找到SDN网络中控制器最佳位置)。
在这个研究中将控制器放置问题和VN映射结合,来映射在线vSDN请求到物理SDN网路中。特别地,引进了控制器放置、虚拟节点映射、和连接映射间的协调。
3.System model
先介绍SDN虚拟化结构,再提供网络模型
3.1 SDN virtualization architecture
FlowVisor结构介绍
3.2Network model
将底层物理SDN基础设施作为SN,并通过带权无向网络图Gs=(Ns,Ls)来模型化它,Ns指的是底层物理节点集合,|Ns|表示总数,Ls表示连接集合。
这篇研究中将CPU能力和可利用TCAM作为节点属性,将可利用带宽和时延作为连接属性。交换机CPU用来处理信息交流,TCAM用来处理流表。Ps表示无回路底层路径在SN中。
一个vSDN请求指定一个租户的需求,包括VN的拓扑,虚拟节点资源,虚拟连接资源等。类似地模型化一个vSDN请求的VN,Gv=(Nv,Lv)
标注nc为一个vSDN的控制器,虚拟控制连接为集合Lc。对于每个虚拟控制连接lcv∈Lc,我们还考虑到它需要一定量的带宽在lcv映射的底层路径中,来避免流量拥塞。
4.Multi-objective optimization for joint VN embedding and the controller placement problem
解释各个变量和限制,用来进行性能评估(可跳过)
4.1.1虚拟节点映射
CPU(ns)、TCAM(ns):底层节点ns的能力;
CPU(nv)、TCAM(nv):虚拟节点ns的需求量;
![]() :表示是否虚拟节点ni映射到底层节点nj
:表示是否虚拟节点ni映射到底层节点nj
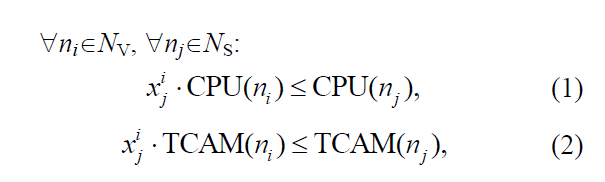
同一个VN中,每个虚拟节点映射到不同物理及节点:
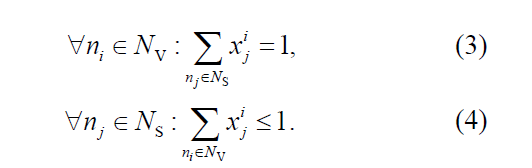
3中保证每个节点都映射;4保证不同
4.1.2虚拟连接映射
Bw(lij):物理连接可以用带宽,lij∈Ls
Bw(luv):所需虚拟带宽
fijuv表示哪条虚拟路径luv经过物理lij
因此有:
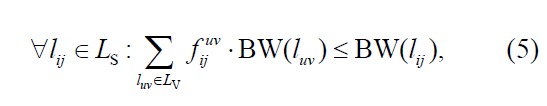
连接限制:保证底层连接可连为一条路径来维护一条虚拟路径:
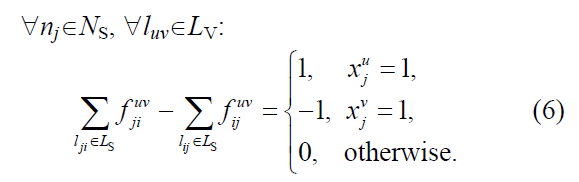
(当j固定的时候,就会出现前面1后面0)
4.1.3目标
考虑几个目标:长期平均回报、长期平均花费、长期回报花费比(R/C)来作为VN的映射目标。
一个VN映射在t时刻的收益为:(需要的资源综合)
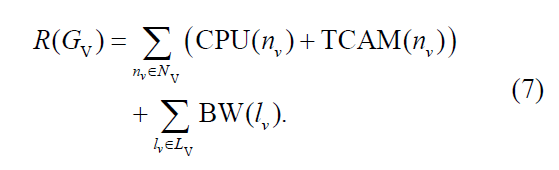
花费:(分配给VN的资源总和)
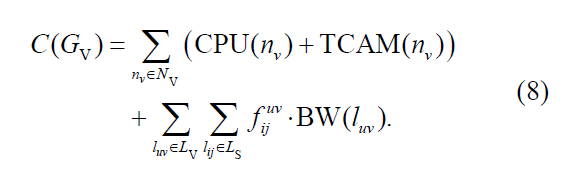
因此长期平均收入为:

长期平均花费:
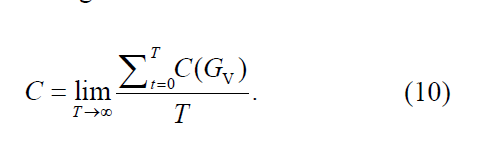
长期R/C比率:

R/C指SN资源利用率
4.2控制器位置
![]() :控制器nc是否放在底层节点nj上
:控制器nc是否放在底层节点nj上

![]() :是否虚拟控制连接lcv穿过底层连接lij
:是否虚拟控制连接lcv穿过底层连接lij
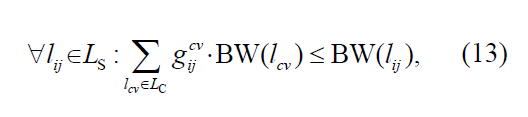
D(lij)表示时延
D:控制器到交换机平均时延,对于一个vSDN请求:
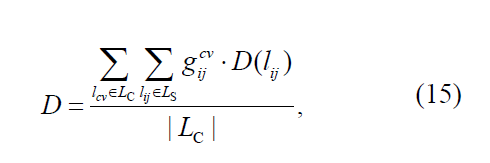
5.Heuristic algorithm design
5.1.1Controller node mapping
controller location selection factor(控制器位置选择因素 CLSF)
将控制器节点附在底层节点上考虑CLSF。
底层节点ni的CLSF定义为:
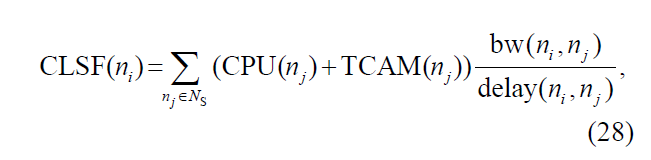
bw(ni,nj)是沿着从ni到nj最短路径上可利用的带宽,表示这条路径上最小带宽;
delay(ni,ji)指从ni到ji的流量时延,由ni到nj最短路径总时延得出。
(时延越低应该越好,所以放在分母,分子表示资源,越大越好)
由于虚拟节点映射还没进行,我们需要将控制器放在底层节点,使其到别的各节点的平均时延最低,这样才能使平均控制器到交换机时延最小。
CLSF考虑了从一个节点到其他所有节点的平均时延,同时还考虑了节点可利用资源以及连接带宽,这使虚拟节点映射和连接映射更加容易。
5.1.2Virtual node mapping
这阶段目标:找到底层节点来维持每个虚拟节点,同时最小化到控制器的时延,并满足CPU、TCAM需求。
需预先考虑连接映射。
首先将虚拟节点更具资源需求的降序排序,一个虚拟节点的需求资源定义为:
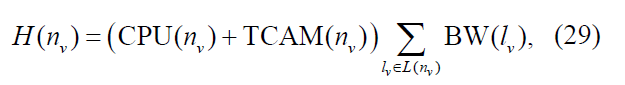
L(nv):直接连接到节点nv的相邻连接;
节点nv的H越大,表示其需求资源越多,因此越难映射。
构造一个虚拟节点映射树(virtual node mapping tree VNMT),能有效减少虚拟连接所映射底层路径的跳数。
VNMT是一颗映射树根据H和VN的拓扑构建。
具体如下:对于给定的VN。先选最大的H值得节点作为根节点。然后与根节点由虚拟连接直接相连的虚拟节点作为其孩子节点根据H值降序从左到右连接。其他虚拟节点相似的递归构造。
在勾走好VNMT之后,CO-vSDNE采用广度优先来映射。对于VNMT根节点,CO-vSDNE用最大H来映射到底层节点,H代表底层节点可利用资源。对于其它虚拟节点CO-vSDNE用最大NR来映射,NR是一个在虚拟节点映射阶段选择底层节点的度量(在公式31中)。当映射nv时,先建立候选底层节点集Ω(nv),由没在相同vSDN中被映射的底层节点,并且可利用资源满足nv需要的节点组成。如:

然后将节点nv映射到候选底层节点ns根据最大NR值:
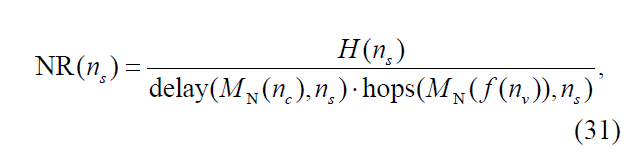
H(ns)代表底层节点ns的可利用资源,由公式29得出。
MN(nc)表示控制器nc所在的底层节点,
delay(MN(nc), ns)表示从MN(nc)到ns的控制信息时延,
f(nv)表示在VNMT树种nv的父节点,
MN(f(nv))表示f(nv)所映射的底层节点
hops(MN(f(nv)), ns)表示在SN中从f(nv)到ns的最短路径跳数
(这公式意思是可利用的资源越多,到前一个节点和到控制器时延越小,就优先选择)
选择的原因:
(1)底层节点由高H,表示底层节点资源丰富,选择高的H有助于平和底层节点的压力
(2)低的delay(MN(nc), ns)可减少控制器到交换机时延
(3)如果hops(MN(f(nv)), ns)太大,nv和f(nv)间虚拟连接花费就会太大,根据公式8,这就会导致SN的低资源利用率。
因此根据VNMT和NR虚拟连接节点映射算法可以保持映射的底层节点连接互相靠近,这有利于接下来的虚拟连接映射
5.2LInk mapping
与先前工作相似,CO-vSDNE采用k最短路径算法来映射。虚拟连接所映射的不同底层路径可能使用相同的底层连接,导致有限带宽资源的竞争,这就使根据大的带宽需求来映射变得很困难。
因此大的带宽需求的连接应优先映射。具体说来,为了映射虚拟控制连接lcv∈LC,连接映射算法搜寻k最短路径通过增加k,如果找到一个路径集合有相同的跳数并满足带宽需求就停止搜索。
然后将lcv映射到这集合中最小时延的底层路径。虚拟连接映射也是如此。

5.3 CO-vSDNE algorithm
现实场景,多个vSDN请求可能同时到达。因此设计算法每个固定时间间隔执行一次。这时间间隔取决于即将到来的vSDN请求的允许等待时间和映射处理时间。
根据收益降序排序vSDN请求
对于所有未映射vSDN请求循环操作
(1)选收益最大
(2)节点映射
(3)连接映射
成功修改状态,失败标记失败继续循环


 浙公网安备 33010602011771号
浙公网安备 33010602011771号