Spring-Cloud 学习笔记-(5)熔断器Hystrix
Spring-Cloud 学习笔记-(5)熔断器Hystrix
1、前言
-
上个章节我们做了什么?
上个章节我们使用了
Ribbon实现了服务之间调用的负载均衡,具体可以分为三个步骤- 引ribbon依赖
- 在启动类中的RestTemplate 加注解@LoadBalanced
- 把serviceId直接写在RestTemplate 请求的url中调用
并且我们针对ribbon底层实现原理,走了一遍源码。
-
这个章节我们会做什么?
熔断器Hystrix
2、Hystrix介绍
2.1、简介
Hystrix,英文翻译是豪猪,是一种保护机制,Netflix公司的一款组件。
主页:https://github.com/Netflix/Hystrix/

Hystix是Netflix开源的一个延迟和容错库,用于隔离访问远程服务、第三方库,防止出现级联失败。

2.2、雪崩问题
上一章我们服务的调用方(order-service)调用了服务的提供方(user-serivce)查询用户的方法,我们可以称order-service依赖于user-service,一旦我们user-service不可用,也会导致了order-service也不可用,类似这种级联的失败,我们可以称作雪崩。
2.2.1、雪崩效应产生原因
- 服务的级联失败:就是刚刚说的A服务依赖B服务,B服务失败了,倒是A服务也挂了,如果还有服务依赖A服务,这样它也会挂了,就这样一直延伸下去导致整个项目的不可用。
- 服务连接数被耗尽:失败的服务占用了连接数,倒是正常的服务依旧访问不了。
描述的详细一点可以这么理解(图片来自于:https://github.com/Netflix/Hystrix/wiki)
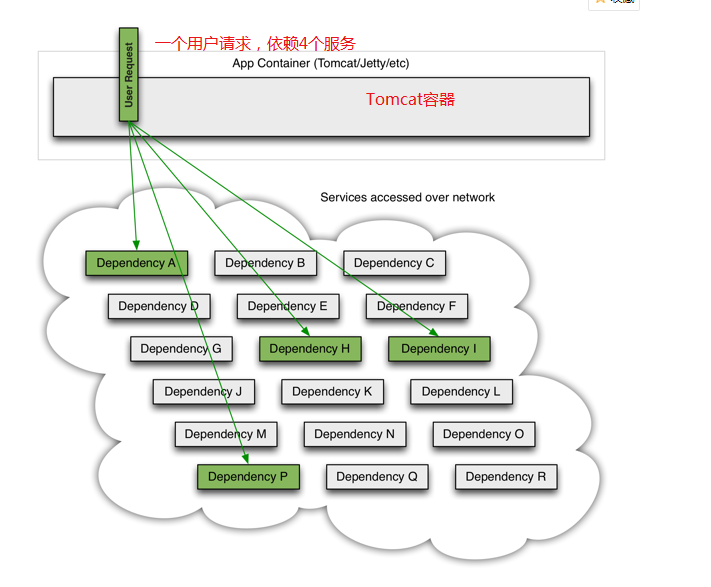
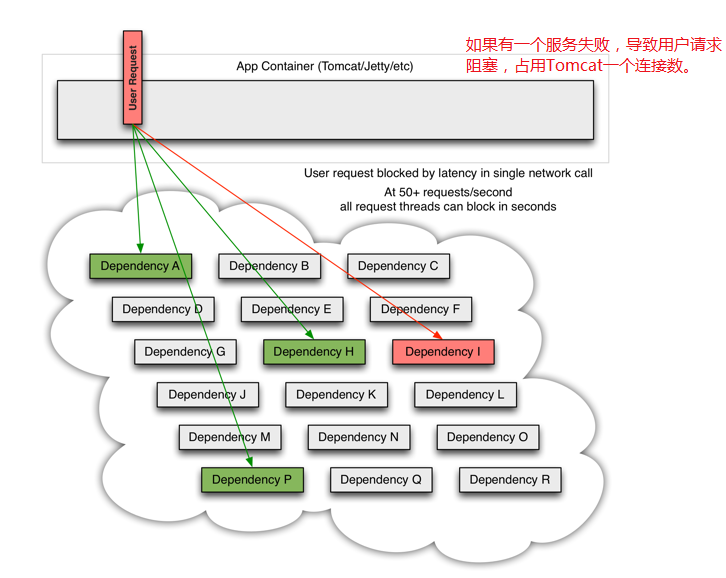
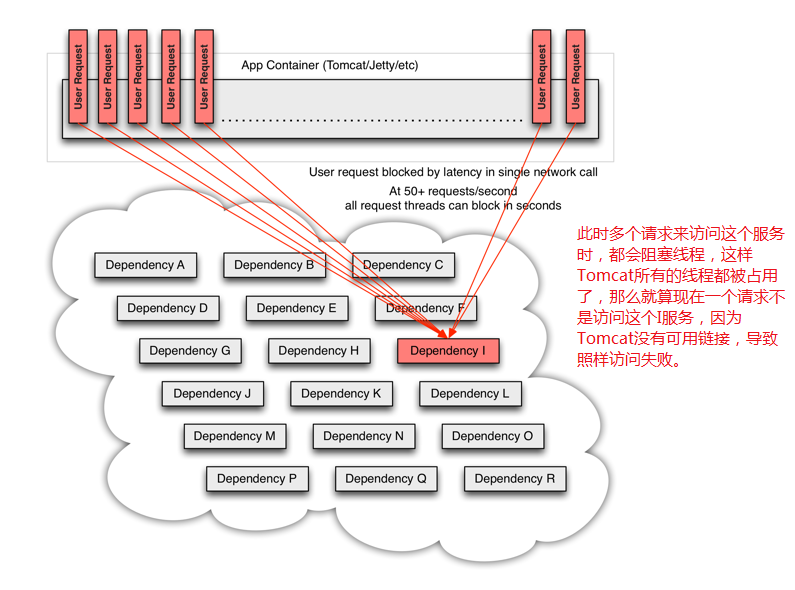
2.2.2、Hystrix如何解决雪崩问题
-
服务的熔断和降级:
熔断:当用户的请求调用一个服务,这个服务挂了,阻塞了,我们设置一个超时时常,如果超过这个时间,我们会快速的返回一个失败的友好提示给客户端。
降级:以前访问一个功能,我们可以提供所有的服务,但是现在我们有个地方有点问题,我们只能给你提供核心服务,不重要的暂时就访问不了了。
-
线程的隔离:
比如我们Tomcat线程有500个,一个用户的请求来了调用5个服务,我们分一个线程给他,让这个线程去调用服务,调用成功返回结果,也就是说以前所有的服务都可以用这500个线程,这样500个线程用完了,这个项目就挂了,现在的做法是什么呢,我们有针对性的给这些服务分配线程,比如一个服务分配100个线程,这样就算有一个服务挂了, 就算服务I不可用,那只会阻塞这个100个线程,其余的400个线程还是正常,依旧可以调用其他正常的服务,我们把这种把不同的服务请求,用不同的线程池去隔离,就算你资源耗尽,仅仅会消耗当前线程池的连接数叫做线程的隔离。
官网对线程的隔离图解

当服务繁忙时,如果服务出现异常,不是粗暴的直接报错,而是返回一个友好的提示,虽然拒绝了用户的访问,但是会返回一个结果。
这就好比去买鱼,平常超市买鱼会额外赠送杀鱼的服务。等到逢年过节,超时繁忙时,可能就不提供杀鱼服务了,这就是服务的降级。
系统特别繁忙时,一些次要服务暂时中断,优先保证主要服务的畅通,一切资源优先让给主要服务来使用,在双十一、618时,京东天猫都会采用这样的策略。
3、服务的降级和线程隔离
3.1、代码:
在服务的调用方(order-service)
3.1.1、引依赖:
<!-- hystrix -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
3.1.2、加注解
@SpringBootApplication
@EnableCircuitBreaker//开启服务的熔断
public class OrderApplication {
public static void main(String[] args) {
SpringApplication.run(OrderApplication.class);
}
/**
* 把RestTemplate注入到Spring容器中
*/
@Bean
@LoadBalanced //让RestTemplate内置一个负载均衡器
public RestTemplate restTemplate(){
return new RestTemplate();
}
}
其实我们作为Eureka的服务端需要加注解@EnableEurekaServer,同样我们作为eureka的客户端也需要加一个注解
@EnableDiscoveryClient,只是我们Eureka比较智能,如果你有spring-cloud-starter-netflix-eureka-client
这个依赖,eureka就会默认你是一个eureka客户端,所以@EnableDiscoveryClient可以不用加。所以一个正常的springcloud微服务,基本上都会有三个注解,@SpringBootApplication、@EnableDiscoveryClient、@EnableCircuitBreaker,所以springcloud很人性化的把这三个注解合成一个注解SpringCloudApplication,所以大家嫌麻烦可以直接加一个SpringCloudApplication注解就可以了。
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@SpringBootApplication//启动类
@EnableDiscoveryClient//eureka客户端
@EnableCircuitBreaker//熔断
public @interface SpringCloudApplication {
}
3.1.2、修改代码:
上面说过,如果服务失败,我们快速返回一个失败信息,所以现在我们要做的是写一个快速失败的处理。
在OrderController中
//OrderController类
@RequestMapping("{user_id}")
//开启服务的线程合理和降级处理,并指定失败后调用的方法↓
@HystrixCommand(fallbackMethod = "findUserByIdFallbace")
public BaseData findUserById(@PathVariable("user_id")int id){
Order order = orderService.findById(id);
return new BaseData(order);
}
/** findUserById失败后调用的方法
* 方法参数和返回值要和上面的完全一样
*/
public BaseData findUserByIdFallbace(int id){
return new BaseData("服务器拥挤,请稍后再试!",null);
}
3.1.4、模拟服务调用异常
UserServiceImpl中
//UserServiceImpl类
/**
* 根据id查询用户基本信息
* @param id 用户id
* @return 用户对象
*/
@Override
public User findById(int id) {
//模拟服务器延迟
try {
//休眠两秒
TimeUnit.SECONDS.sleep(2L);
} catch (InterruptedException e) {
e.printStackTrace();
}
User user = userMap.get(id);
user.setPort(port);
return user;
}
3.1.5、测试
启动服务,访问 http://localhost:8781/api/v1/order/2

3.2、升级版
刚刚我们是针对某一个类写了一个降级方法,但是如果Controller中有很多方法我们就要写很多的降级方法。所以我们可以针对一个类所有方法降级
3.1、代码
3.1.1、注解修改
@RestController
@RequestMapping("api/v1/order")
@DefaultProperties(defaultFallback = "defaultFallback") //为整个类开启服务的熔断
public class OrderController {
//....
@RequestMapping("{user_id}")
//开启服务的线程合理和降级处理
@HystrixCommand
public BaseData findUserById(@PathVariable("user_id")int id){
Order order = orderService.findById(id);
return new BaseData(order);
}
3.1.2、降级方法修改:
/**
* 方法参数为空
*/
public BaseData defaultFallback(){
return new BaseData("服务器拥挤,请稍后再试!",null);
}
3.1.3、测试

3.3、配置修改

3.3.1、单一方法Hystrix配置
打开控制台(F12),这里我们看的出来,虽然user-service我们设置了睡眠时间是2秒,但是每次一秒就返回结果了,说明Hytrix默认的超时时长是1秒,但是由于业务逻辑需要,比如发送邮件、银行转账、等我们超时时长都可以稍微设置长一点,一些简单查询可以超时时长可以设置稍微短一点。
3.3.1.1、注解修改
//OrderController类
@RequestMapping("{user_id}")
/**
*commandProperties,中我们可以配置一些属性,可以配置多个。
*但是这些配置的nama 和value 是什么呢...我们看源码,这些配置都在HystrixCommandProperties类中
*/
@HystrixCommand(commandProperties = {
@HystrixProperty(name = "",value = "")
})
public BaseData findUserById(@PathVariable("user_id")int id){
Order order = orderService.findById(id);
return new BaseData(order);
}
//HystrixCommandProperties类
//执行 超时时长 单位毫秒 我们ctrl+f 搜索一下default_executionTimeoutInMilliseconds,看看这个配置的key是什么...
private static final Integer default_executionTimeoutInMilliseconds = 1000;
//找到配置 key:execution.isolation.thread.timeoutInMilliseconds
this.executionTimeoutInMilliseconds = getProperty(propertyPrefix, key, "execution.isolation.thread.timeoutInMilliseconds", builder.getExecutionIsolationThreadTimeoutInMilliseconds(), default_executionTimeoutInMilliseconds);
所以我们要修改某一个方法熔断配置,可以在@HystrixProperty中配置对于的name和value,比如我们配置超时时长为3秒,我们就可以
//OrderController类
@RequestMapping("{user_id}")
//开启服务的线程合理和降级处理,并指定失败后调用的方法
@HystrixCommand(commandProperties = {
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds",value = "3000")
})
public BaseData findUserById(@PathVariable("user_id")int id){
Order order = orderService.findById(id);
return new BaseData(order);
}
3.3.1.2、测试

返回成功
3.3.2、全局配置
修改配置文件application.yml文件
#hystrix超时时长配置
hystrix:
command:
default:
execution.isolation.thread.timeoutInMilliseconds: 3000
我们删除之前的方法上的超时配置,重启一下order-service测试一下

依旧没有问题。
4、服务的熔断
4.1、熔断的原理
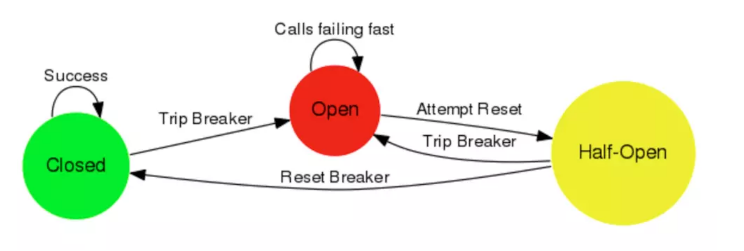
-
一个请求过来,如果是关闭状态,那请求继续。
-
如果请求失败超过一定的
阈值(默认最近的20次请求有50%以上的请求失败)则熔断器打开。 -
后续请求发现熔断器是开启状态,将直接返回错误信息,不会等待。
-
从熔断器打开时候开始计时,熔断器会经过一个
休眠时间窗(默认5秒),超过5秒后熔断器会进入半开状态。 -
半开状态的熔断器会放一定量的请求通过进行尝试,如果依旧超时,熔断器继续进入关闭状态,然后在经历休眠,如此反复,直到半开状态的熔断器放过去的请求成功了,熔断器会继续进入关闭状态。
这些默认值也是在
//HystrixCommandProperties类 //打开熔断器的最小请求次数 private static final Integer default_circuitBreakerRequestVolumeThreshold = 20; //休眠时间窗 private static final Integer default_circuitBreakerSleepWindowInMilliseconds = 5000; //设置打开熔断并启动回退逻辑的错误比率 private static final Integer default_circuitBreakerErrorThresholdPercentage = 50;
4.2、测试
修改代码便于测试
- 把user-service中的睡眠时间删除
- 修改OrderController代码
//OrderController类
@RequestMapping("{user_id}")
//开启服务的线程合理和降级处理
@HystrixCommand(
commandProperties = {
@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold",value = "10"),
@HystrixProperty(name = "circuitBreaker.sleepWindowInMilliseconds",value = "5000"),
@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage",value = "60")
}
)
public BaseData findUserById(@PathVariable("user_id")int id){
//手动控制请求成功失败 技术
if(id%2==0){
throw new RuntimeException("");
}
Order order = orderService.findById(id);
return new BaseData(order);
}
-
测试
访问:http://localhost:8781/api/v1/order/1 成功
访问:http://localhost:8781/api/v1/order/2 失败
如果我们一直访问http://localhost:8781/api/v1/order/2 一直失败
根据上面我们的配置在最近的10次请求中,如果失败超过60%,这个时候熔断器就会开启,就算我们访问http://localhost:8781/api/v1/order/1 成功的请求也会立即返回失败信息,这个时候会经历休眠时间窗5秒,超过5秒熔断器进入半开状态,我们访问http://localhost:8781/api/v1/order/1,成功。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号