我要进大厂之大数据Hadoop HDFS知识点(2)

01 我们一起学大数据
老刘继续分享出Hadoop中的HDFS模块的一些高级知识点,也算是对今天复习的HDFS内容进行一次总结,希望能够给想学大数据的同学一点帮助,也希望能够得到大佬们的批评和指点!
02 知识点
第10点:HDFS机制之心跳机制

根据这个图,咱们说说心跳机制工作原理,首先master启动的时候,会开一个ipc server在那里;接着slave启动后,会向master注册连接,每隔3秒钟向master发送一个心跳,携带状态信息;最后master就会通过这个心跳的返回值,向slave节点传达指令。
说完工作流程,那现在说说心跳机制有什么用?
1、NameNode它周期性地从集群中的每个DataNode接收心跳信号和块状态报告,接收到心跳信号就意味着这个DataNode节点工作正常。块状态报告包含了这个DataNode上所有的数据块列表。
2、DataNode启动后向NameNode注册,然后周期性地向NameNode上报所有的块列表;每3秒向NameNode发一次心跳,返回NameNode给该DataNode的命令。如果NameNode超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。
3、Hadoop集群刚开始启动时,会进入安全模式(99.9%),就用到心跳模式。
老刘看过好几个机构的HDFS课件,大多都一笔带过安全模式。在老刘看来,安全模式至少要知道它的概念!
什么是安全模式?
安全模式是Hadoop的一种保护机制,用于保证集群中数据块的安全性。在这种状态下,文件系统只接受读数据请求,而不接受删除、修改等变更操作。
Hadoop集群刚开始启动进入安全模式,就会检查数据块的完整性。假设我们设置的副本数是5,那DataNode上就应该有5个副本存在。但再次假设目前只有3个,3/5=0.6小于最小副本概率99.9%,那系统就会自动复制副本到其他的DataNode。如果系统中有8个,我们设置的只有5个,那就会删除多余的3个。正常情况下,安全模式会运行一段时间后就会自动退出。
第11点:HDFS的数据读流程
它的基本流程是怎么样的?
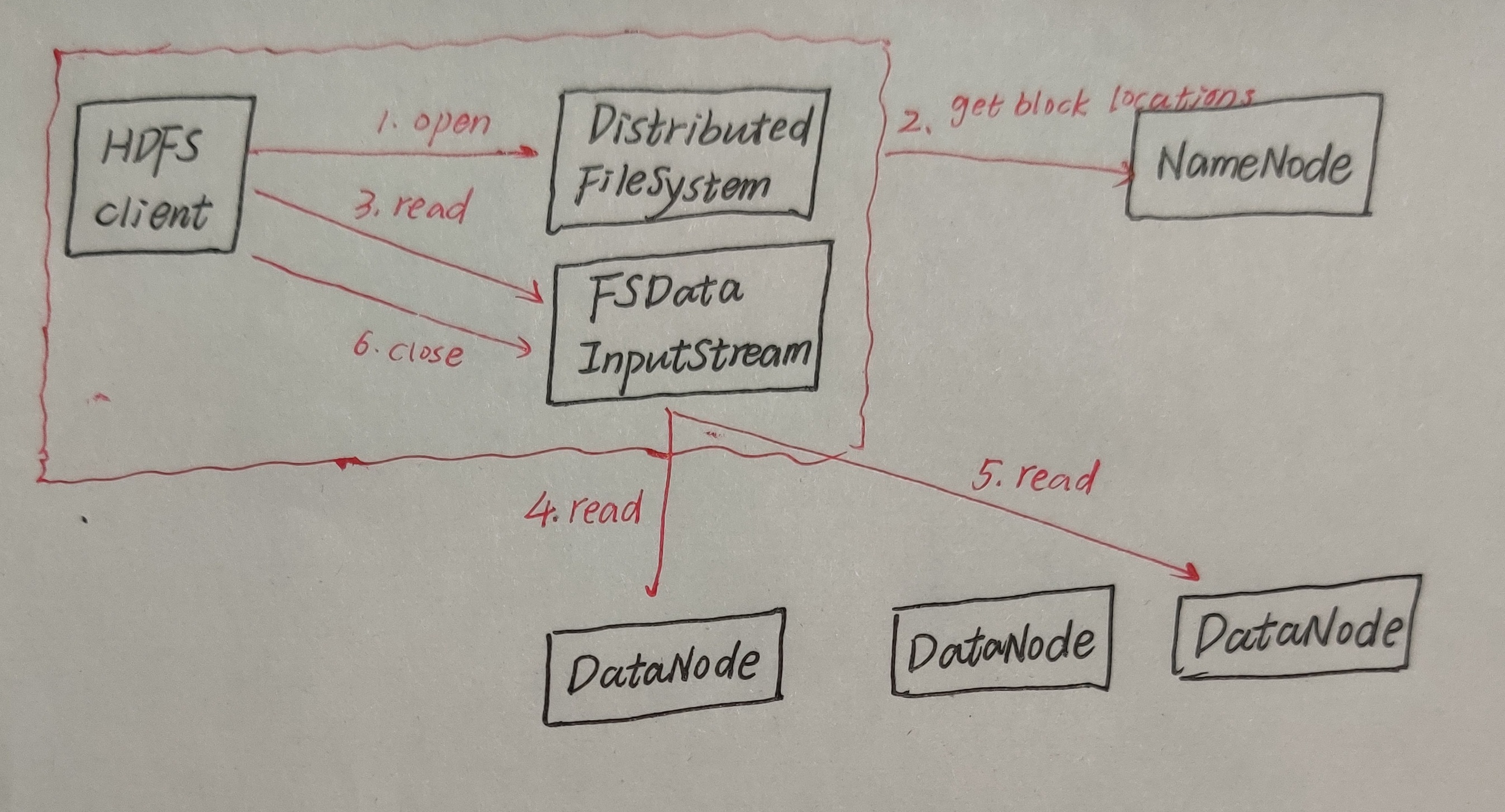
咱们看图说流程,在HDFS的读流程中,客户端调用文件系统的open方法,然后这个文件系统会通过RPC远程调用NameNode里的open方法,得到块位置信息返回。块位置信息返回后NameNode会调用FSDataInputStream的read方法,它会与它最近的DataNode联系(这个最近指的是网络拓扑做排序,离client近的排在前,这个不是很确定,大家可以去百度看看)。如果第一个DataNode无法连接,客户端将自动联系下一个DataNode;如果块数据的校验值出错,则客户端需要向NameNode报告,并自动联系下一个DataNode。
数据读的容错
如果读取block过程中,Client与DataNode通信中断,怎么办?
Client与存储此block的另外DataNode建立连接,读取数据,并且记录此有问题的DataNode,不会再从它上读取数据。
如果Client读取block,发现block数据有问题,怎么办?
我们在存数据的时候,会含有check校验和(CRC32-),读取的时候也会读取checksum,并读取的时候计算一个值,对比两个值是否相等。如果不相等,哪个节点block块有问题,则换一个节点读取,并告诉NameNode哪个节点block有问题,并从其他节点复制一份数据到该节点。
如果Client读取的数据不完整,怎么办?
如果不相等,哪个节点的block块有问题,则换一个节点读取,并告诉NameNode哪个节点block块有问题,并从其他节点复制一份数据到该节点。
第12点:HDFS的数据写流程
它的基本流程是怎么样的?
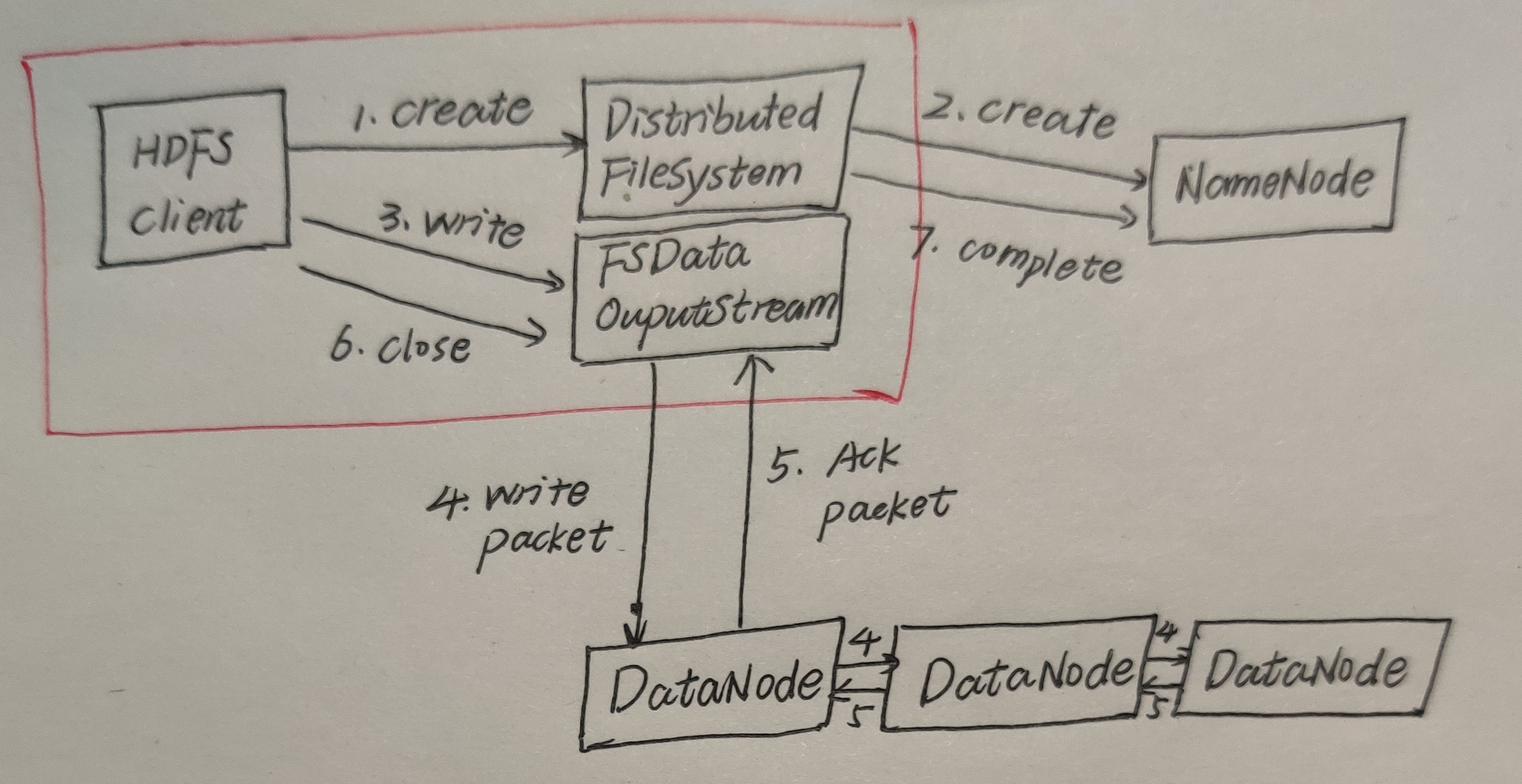
1、客户端调用分布式系统的create方法,此时文件系统也会通过RPC远程调用NameNode的create方法。此时NameNode会进行如下举措:①检测自己是否正常运行②判断要创建的文件是否存在③Client是否有创建文件的权限④对HDFS做状态的更改需要在edits log写日志记录
2、检查通过后,NameNode响应客户端可以上传。
3、客户端根据自己设置的块大小,开始上传第一个块,默认0-128M,NameNode根据客户端上传文件的副本数(默认为3),在根据机架感知策略选取指定数量的DataNode节点返回。
4、客户端根据返回的DataNode节点,请求建立传输通道。客户端向最近的DataNode节点发起通道建立请求,然后由这个DataNode节点依次向通道中的(距离当前DN距离最近)下一个节点发送建立通道请求,各个节点发送响应 ,通道建立成功。
5、客户端每读取64K的数据,封装为一个packet(它是一个数据包,是传输的基本单位),将packet发送到通道的下一个节点,通道中的节点收到packet之后,落盘存储,将packet发送到通道的下一个节点,每个节点在收到packet后,向客户端发送ack确认消息。
6、一个块的数据传输完成之后,通道关闭,DataNode向NameNode上报消息,已经收到某个块7、第一个块传输完成,第二块开始传输,依次重复上述步骤,直到最后一个块传输完成,NameNode向客户端响应传输完成,客户端关闭输出流。
但是如果写过程出现异常,该怎么办?
第1步到第4步和之前一样,直接看上面。
5、客户端每读取64K的数据,封装为一个packet,封装成功的packet,放入到一个队列中,这个队列称为dataQuene(待发送数据包)。
6、在发送时,先将dataQuene中的packet按顺序发送,发送后再放入到ackquene(正在发送的队列)。每个节点在收到packet后,向客户端发送ack确认消息。如果一个packet在发送后,已经收到了所有DN返回的ack确认消息,这个packet会在ackquene中删除。如果一个packet在发送后,在收到DN返回的ack确认消息时超时,传输中止,ackquene中的packet会回滚到dataQuene。重新建立通道,剔除坏的DN节点。建立完成之后,继续传输。只要有一个DN节点收到了数据,DN上报NN已经收完此块,NN就认为当前块已经传输成功。
第13点:Hadoop HA
Hadoop的高可用已经在ZooKeeper中讲过了,直接给出链接,大家可以去看看,https://www.cnblogs.com/bigdatalaoliu/p/13991733.html中的第14点。
第14点:Hadoop联邦
对于一个拥有大量文件的超大集群来说,内存将成为限制系统横向发展的瓶颈,联邦就是为了突破这个瓶颈产生的。
第15点:HDFS为什么不适合存储小文件?
先给出网上搜到的一些答案:
首先NameNode存储着文件系统的元数据,每个文件、目录、块大概有150字节的元数据,因此文件数量的限制也由NameNode内存大小决定,如果过多小文件就会造成NameNode的压力过大。
再给出自己总结的一个看法:
HDFS天生是为了存储大文件而生的,一个块数据大小大概在150字节,存储一个小文件就要占用150字节内存。如果存储大量的小文件,很快就会将内存耗尽,但是整个集群存储的数据量很小,就失去了HDFS的意义。
如何解决存储大量小文件的问题?
用Sequence File方案,其核心是以文件名为key,文件内容为value组织小文件,大量的小文件可以通过编写程序将这些文件一个Sequence File文件,然后以数据流的方式处理这些文件,也可以使用MapReduce进行处理。这样做的优势:①Sequence File可分割,MapReduce可将文件切分成块,每一块独立操作。②Sequence File支持压缩,大多数情况下,以block为单位进行压缩是最好的,因为一个block包含多条记录,利用record间的相似性进行压缩,压缩效率更高。
03 总结
好啦!Hadoop HDFS的知识点总结就弄完了,老刘分享出这些知识点,一是为了复习HDFS的知识点,二是希望能够对想学大数据的同学有帮助,三是希望能够得到大佬的批评和指点。
最后,有事,公众号:努力的老刘,联系;没事,就和老刘一起学大数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号