

SQL:增强聚合、数据立方体(Cube、 Grouping SETS 、Rollup)
在数据分析时,有一个概念叫钻取,分为上钻和下钻,其实就是逐层聚合。假如一张表tb,有 a/b/c/d四个字段,其中a/b/c是维度,d是度量。日常中,a/b/c可能是父级和子集的关系,如学校和年级,而更多的可能是交叉的关系,如年级和男女。基于维度之间的关系,在数据分析中经常会做逐层分析或交叉分析。其实即便维度之间是交叉关系,我们也会根据业务习惯,把维度依次分为上下层关系,比如业务特征方面的维度我们会习惯作为上层,而性别年龄之类会作为下层。当然这种分层不是绝对的,总是基于业务需要作调整。也正是这种情况,我们在作数据汇总时,总是体现着上下层的关系,而从上一层往下一层拆分为下钻、反之则为上钻。
正因为上下层的关系,我们在数据聚合时就会涉及到不同层次的聚合,比如 group by a ; group by a,b ; group by a,b,c,而group by 的每次执行都只能基于某一个层级的聚合。因此,有没有可能一个group by 就把所有可能的组合都执行出来呢?显然hive确实提供了这样的功能,那就是cube,所谓的数据立方体了。从宏观上看,数据本身就是多维立体的,当我们基于某个或者某几个维度聚合时,就相当于从某个方向抽取一个点或者一个面进行观察。
with cube:
假如我们以tb表做聚合,那么group by的组合形式有 ( (a, b, c)、 (a, b)、(b, c)、(a, c)、 (a)、(b)、(c)、( ) ),其中()表示不做分组。
hive sql一次性生成这些形式聚合的语法如下:
SELECT a,b,c,count(d) FROM tb GROUP BY a, b, c WITH CUBE;
-- 此语句生成的数据,等同于如下UNION语句: SELECT a,b,c,count(d) FROM tb GROUP BY a,b,c UNION SELECT a,b,null,count(d) FROM tb GROUP BY a,b UNION SELECT null,b,c,count(d) FROM tb GROUP BY b,c UNION SELECT a,null,c,count(d) FROM tb GROUP BY a,c UNION SELECT a,null,null,count(d) FROM tb GROUP BY a UNION SELECT null,b,null,count(d) FROM tb GROUP BY b UNION SELECT null,null,c,count(d) FROM tb GROUP BY c UNION SELECT null,null,null,count(d) FROM tb
GROUPING SETS:
实际需求中,我们并不需要所有的组合形式的group by,而是其中的某些组合,而grouping sets 就是限定哪些是我们需要的组合形式。
SELECT a, b, c, SUM( c ) FROM tab1 GROUP BY a, b, c GROUPING SETS ((a,b,c), a,()) -- 此语句等同于如下UNION语句: SELECT a,b,c,count(d) FROM tb GROUP BY a,b,c UNION SELECT a,null,null,count(d) FROM tb GROUP BY a UNION SELECT null,null,null,count(d) FROM tb
WITH ROLLUP:
实际上,我们在写SQL语句时,习惯性把上层维度排在前面,比如 select a,b,c,count(d) from tb group by a,b,c;默认的层级关系是a-->b-->c依次下沉。因此,我们需要的聚合层级分别是()、(a)、(a,b) 、(a,b,c)。而with rollup 代表着我们默认选择这几种形式聚合。
SELECT a, b, c, count(d) FROM tb GROUP BY a,b,c WITH ROLLUP;
-- 等同于:
SELECT a,b,c,count(d) FROM tb GROUP BY a,b,c
UNION
SELECT a,b,null,count(d) FROM tb GROUP BY a,b
UNION
SELECT a,null,null,count(d) FROM tb GROUP BY a
UNION
SELECT null,null,null,count(d) FROM tb
Grouping__ID:
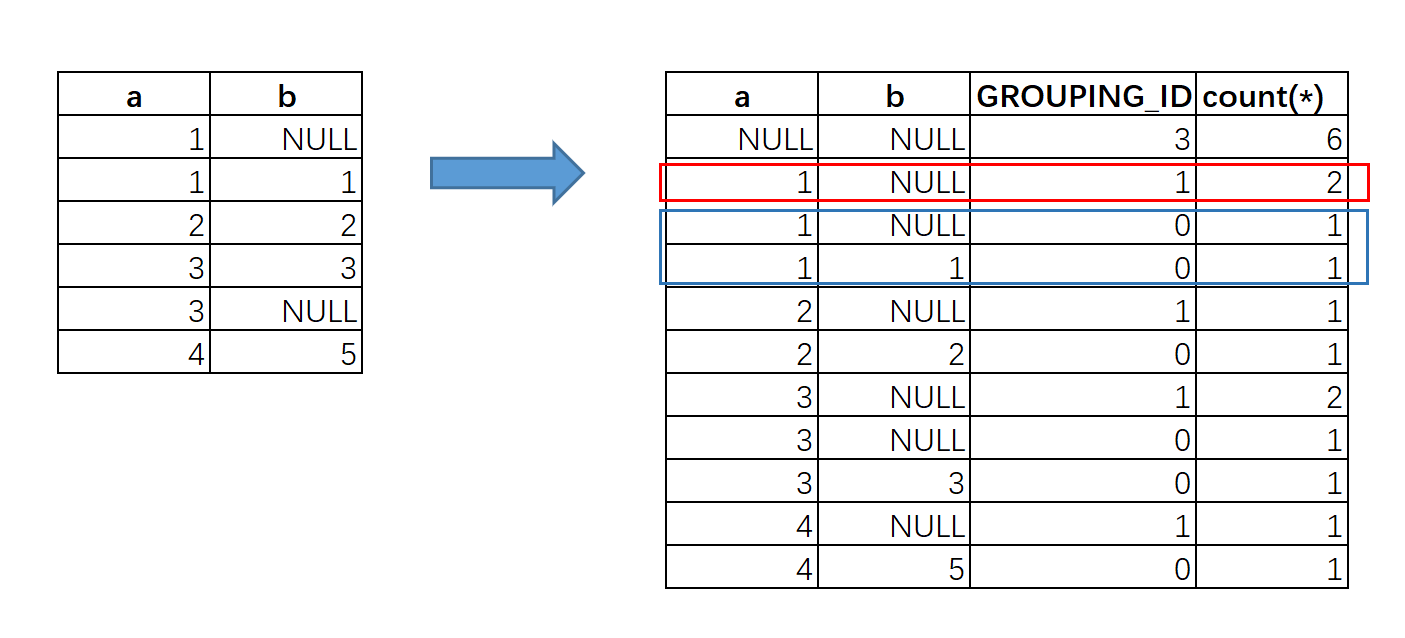
在做数据立方体时,会遇到下层维度中为null的情况,聚合后样式和他的上层形式就一样了(如下数据),为了避免这种情况,可以用grouping_id 来标识。脚本如下:
SELECT a, b,GROUPING__ID, count(*) FROM tb GROUP BY a, b WITH ROLLUP;
其中红框为group by a ;而蓝框 则是group by a, b 。GROUPING_ID的生成逻辑则是二进制转十进制的数值,进入聚合的列为1否则为0。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号