transformer相关模型的embedding方式
Transformer
论文全名:Attention Is All You Need
transformer模型主要解决翻译问题,而且倾向于逐词翻译。由于翻译时需要考虑到至少两方面信息:单词的意思,单词在句子中的位置。所以embedding过程也是针对这两方面信息。

在Transformer里,编码方式是固定的,不含可训练的参数。
这种方式的精妙之处还在于,把单词位置对单词的影响,细化成了单词位置对单词每个维度的信息的影响。
Informer
论文全名:*Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting *
Informer解决时间序列预测的问题,与transformer相比,它是一步到位而不是逐步预测的。为了达到长序列预测的目的,需要让模型知道全局时间戳。而且电力使用计划跟人的生产生活密切相关,从而与人们的计时方式相关:年、月、日、时、节假日等。这部分信息也需要让模型知道。
总之,Informer的embedding过程需要把三方面的信息揉在一起:每个时间点的电力使用情况(电力变压器的负荷、油温数据等),每个时间点在所选取的序列中的位置信息,每个时间点本身的全局时间信息(年、月、日、时、节假日等)。
①通过一维卷积处理7个维度的电力数据
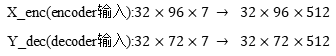
②与transformer的方法相同进行位置编码
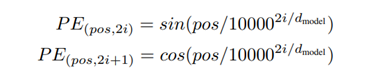
③通过全连接层转换全局时间戳的形状
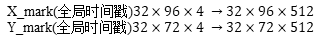
最终的embedding结果是上述三方面之和。
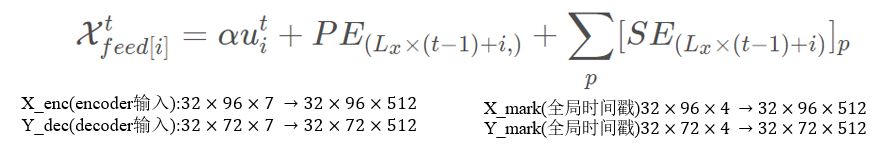
𝛼:是平衡标量投影和局部/全局嵌入之间大小的因子,如果输入序列已经标准化过了,则该值为1。
R-Transformer
论文全名:R-transformer : Recurrent neural network enhanced transformer
这个模型是RNN与attention的结合。解决的问题是从一个序列预测到一个标签(比如从一句话预测下一个词,从一段DNA预测这段DNA的功能)
改变了原来的transformer的位置编码方式。对序列的每个位置,不再用sin/cos这种编码方式,而是取它之前的长度为M的序列,进行RNN,把RNN的最终hidden state结果作为位置信息。由于对每个位置都要进行这种相同却独立的操作,所以可以并行化。
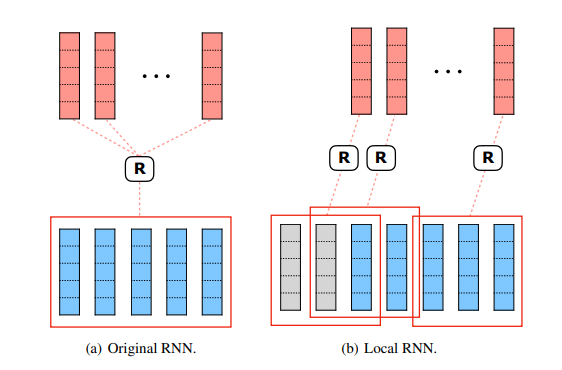
local RNN的结果就是位置编码信息把它和原信息加在一起作为输入。
Relative Position Representation
论文全名:Self-Attention with Relative Position Representations
这个论文是对transformer的魔改,它把相对位置信息表示为一个可训练的向量,添加到自注意力层的计算过程中。

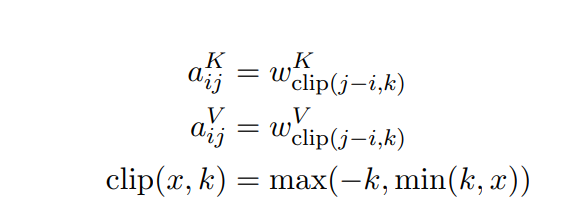
Transformer-XL
论文全名:Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
①
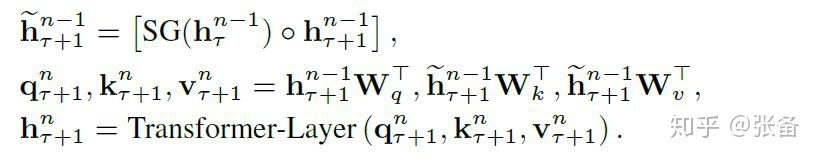
②相对位置关系用一个位置编码矩阵 来表示,第i行表示相对位置间隔为i的位置向量。论文中强调R采用正弦函数生成,而不是通过学习得到的.每一层在计算attention的时候,都要包含相对位置编码。
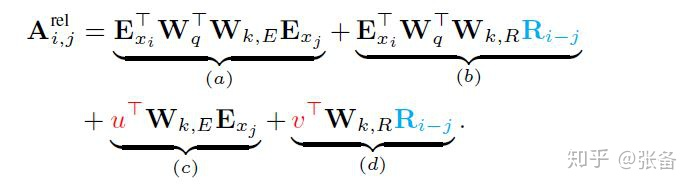
Vanilla Transformer
每一层的输入都要附加上一个位置编码,是可训练的。作者认为它的网络深度太深了,如果只在第一层加入pos embedding,那么经过多层传递,这个信息很容易丢失
编码时间的一般方法
-
提取时间的周期性特点做为特征,此时训练集每条样本为"时间特征->目标值",时间序列的依赖关系被剔除,不需要严格依赖滑窗截取训练样本。常见是将时间用0-1哑变量表达,有以下若干种特征:
-
- 将星期转化为了0-1变量,从周一至周天,独热编码共7个变量
- 将节假日转化为0-1变量,视具体节假日数目,可简单分为两类,"有假日"-"无假日",独热编码共2个变量;或赋予不同编码值,如区分国庆、春节、劳动节等使用1、2、3表示
- 将月初转化为0-1变量,简单分两类表示为"是月初"-"非月初",共2个特征
- 类似的月中、月初可以转化为0-1变量
- 控制时间粒度,区分是weekday or weekend
TENER
论文全名:TENER : Adapting Transformer Encoder for Named Entity Recognition
①对单词的嵌入过程也用到了 Transformer,这是为了提炼单词中的特征,比如“un..ily” in “unhappily” and “uneasily”。
②传统的transformer的位置编码是用正余弦函数实现的,由于正余弦函数的周期性,这种做法会让方向信息和距离信息比较弱。所以在注意力的计算过程中,再引入位置信息。
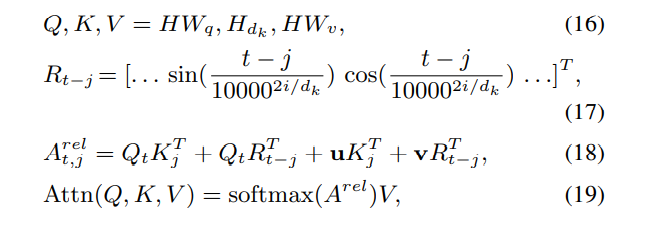
Longformer
论文全名:Longformer: The Long-Document Transformer
采用绝对位置编码,参数可学习。
为了提高训练速度,采用了 RoBERTa的位置编码信息作为初始,可以很快收敛。
Generating Long Sequences with Sparse Transformers
对输入的每个维度分别嵌入,然后再加在一起


BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
处理自然语言问题
输入的表示由三部分构成: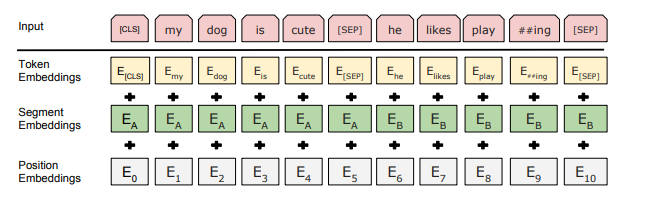

总结
embedding的过程就是把所有有用的信息(需要投喂给模型的信息)数字化,主要体现为位置信息的数字化,这又分为全局位置信息和局部位置信息。从embedding的性质来看,又分为可训练和不可训练两种类型。从embedding的时机来看,有可能只在最开始的输入时附加位置信息,也有可能为了保证位置信息不丢失,每层的输入都要附加位置信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号