ElasticSearch
ElasticSearch01
认识ES
认识和安装
ES是基于Lucene开发的 Lucene是搜索引擎库 有高性能和易扩展的优势
ES具有支持分布式 水品扩展和提供Restful接口 可被任何语言调用
elasticSearch结合kibana Logstash Beats 是一套完整的技术栈 叫做ELK 可应用在日志数据分析 实时监控

安装es
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network hmall \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1
安装kibana
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=hmall \
-p 5601:5601 \
kibana:7.12.1
倒排索引
传统数据库采用正向索引 比如MySql 如果按照id查会很快 因为是B+树 但是按照名称查 尤其模糊查询 就会很慢 数据库会一个个遍历 直到遍历完
而ES采用倒排索引
- 文档(document) 每一条数据就是一个文档
- 词条(term) 文档按语义进行分词
区别就是正向索引先根据id查 然后查到文档再做词条匹配 倒排索引是根据词条的索引查 查到之后再根据id查

ES会给id和词条建立索引 保证查询速度
IK分词器
通过IK分词器可以正确对中文进行分词 但是有些词可能无法分 就可以对词典进行扩展
在config-IKAnalyzer.xml中添加词典 比如ext.dic
然后在config目录下创建之后 写入词 即可对这些词进行分词
基础概念
ES中的文档会被序列化为json格式后保存在es中 类型相同的文档就是索引库
索引(index):相同类型的文档的集合
映射(mapping):索引中文档的字段约束信息 类似于表的结构约束

索引库操作
Mapping映射属性
mapping是对索引库中文档的约束 常见的属性包括
-
type 字段数据类型
- 字符串 text(可分词文本) keyword(不分词 精确值 国家 ip地址)
- 数值 byte short integer long float double
- 布尔 boolean
- 日期 data
- 对象 object
-
index 是否创建索引 默认是true
-
analyzer 使用哪种分词器
-
properties 对对象的字段进行属性创建
索引库操作
ES的所有api都是restful的接口 遵循restful规范
创建索引库和mapping

索引库一旦创建 无法修改 但是可以添加新字段

文档操作
文档CRUD
-
新增
![]()
-
删除 查询都是改个请求方式
-
修改
- 全量修改 底层就是先删除文档 再添加回来
![]()
-局部修改
![]()
- 全量修改 底层就是先删除文档 再添加回来



批量处理

JavaRestClient
客户端初始化
- 引依赖
![]()
- 确认依赖版本
<elasticsearch.version>7.12.1</elasticsearch.version> - 初始化RestHighLevelClient
![]()


ElasticSearch02
DSL查询
快速入门
ES提供了DSL(Domain specific language) 以JSON格式来进行查询 主要分为两类
- 叶子查询(Leaf query clauses) 再特定字段里查询特定值
- 符合查询(Compound query clauses) 以逻辑方式组合多个叶子查询或者更改叶子查询的行为方式
查询之后可以对结果进行处理分别是 排序 分页 高亮 聚合(对搜索结果做数据统计以形成报表)
match all查询所有语法

结果响应

叶子查询
常见的叶子查询有
- 全文检索 利用分词器对用户输入内容进行分词 根据词条进行匹配查询
- match查询 对用户输入进行分词 然后用倒排索引查
- multi match 与match类似 但是允许多个字段
- 精确匹配 直接根据用户输入的精确查询 一般都是keyword 日期 id
- term 精确按照字段查
- range 按照范围
- ids 按照多个id
- 地理坐标查询
复合查询
符合查询分两种 一种是基于逻辑运算组合叶子查询 叫布尔查询 第二种是基于某种算法修改文档相关算分 从而改变文档排名 function_score和dis_max
bool查询
是一个或多个查询字句的组合 子查询组合方式有
- must 必须匹配每个子查询 类似与
- should 选择性匹配子查询 或
- must_not 必须不匹配 不参与算分 非
- filter 必须匹配 不参与算分
must和filter的区别就是前者算分匹配 后者不算分匹配 前者适合于直接查询结果 后者适合于查询完之后做排序过滤

排序和分页
ES支持对搜索结果排序 默认是按照相关度算分来排序 也可以指定字段排序

ES默认只返回前十条数据 如果查询更多就要修改分页参数 ES中通过修改from size来控制结果
- from 从第几个文档开始
- size 总共查询几个文档

深度分页问题
ES的分页具体逻辑是数据采用分片存储 吧一个索引中的数据分成N份 存储到不同节点上 查询数据时需要汇总各个分片的数据
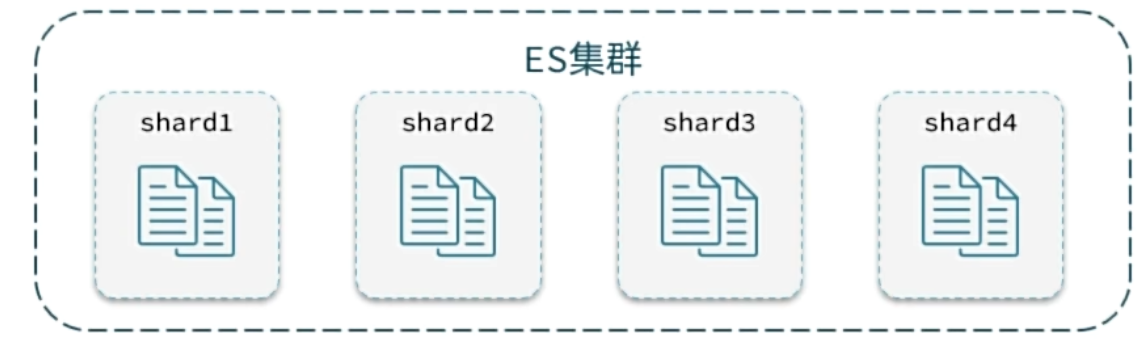
比如查990-1000这个位次 那ES需要对每个集群查出来前一千 然后汇总起来再查汇总的990-1000
那么就会存在深度分页问题 查的页码越深 每个集群查询的数据量就越多 压力越大
针对这个问题 ES提供了search after方案
分页时需要排序 从上一次排序值开始 查询下一页数据
类比mysql就是每一次查询记住最后一个id 然后分页的时候带上where条件 where id = ? limit 10就不存在深度分页问题 因为用where框选了范围
优点 没有查询上限 支持深度分页
缺点 只能向后主页查询 不能跳页
场景 数据迁移 手机滚动查询
高亮显示
在搜索结果中把关键字突出显示

JavaRestClient查询
快速入门
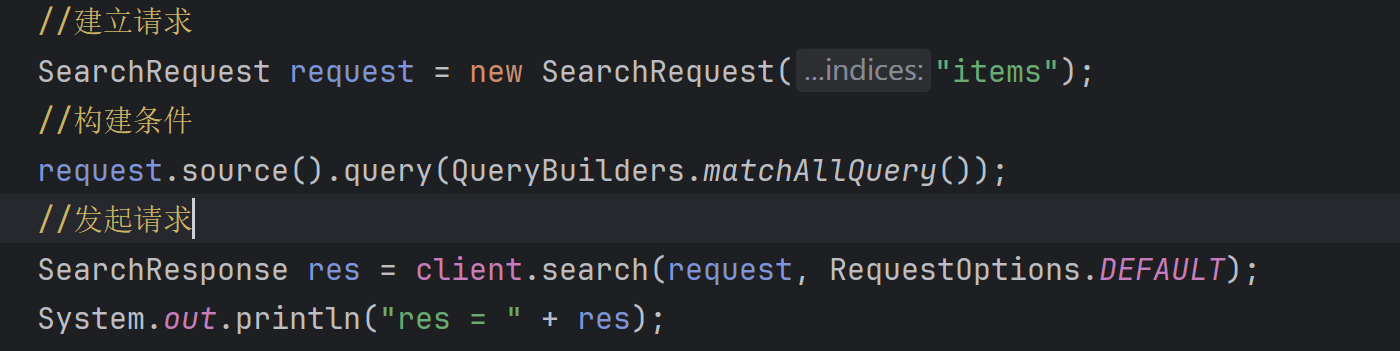
- 发起请求
![]()
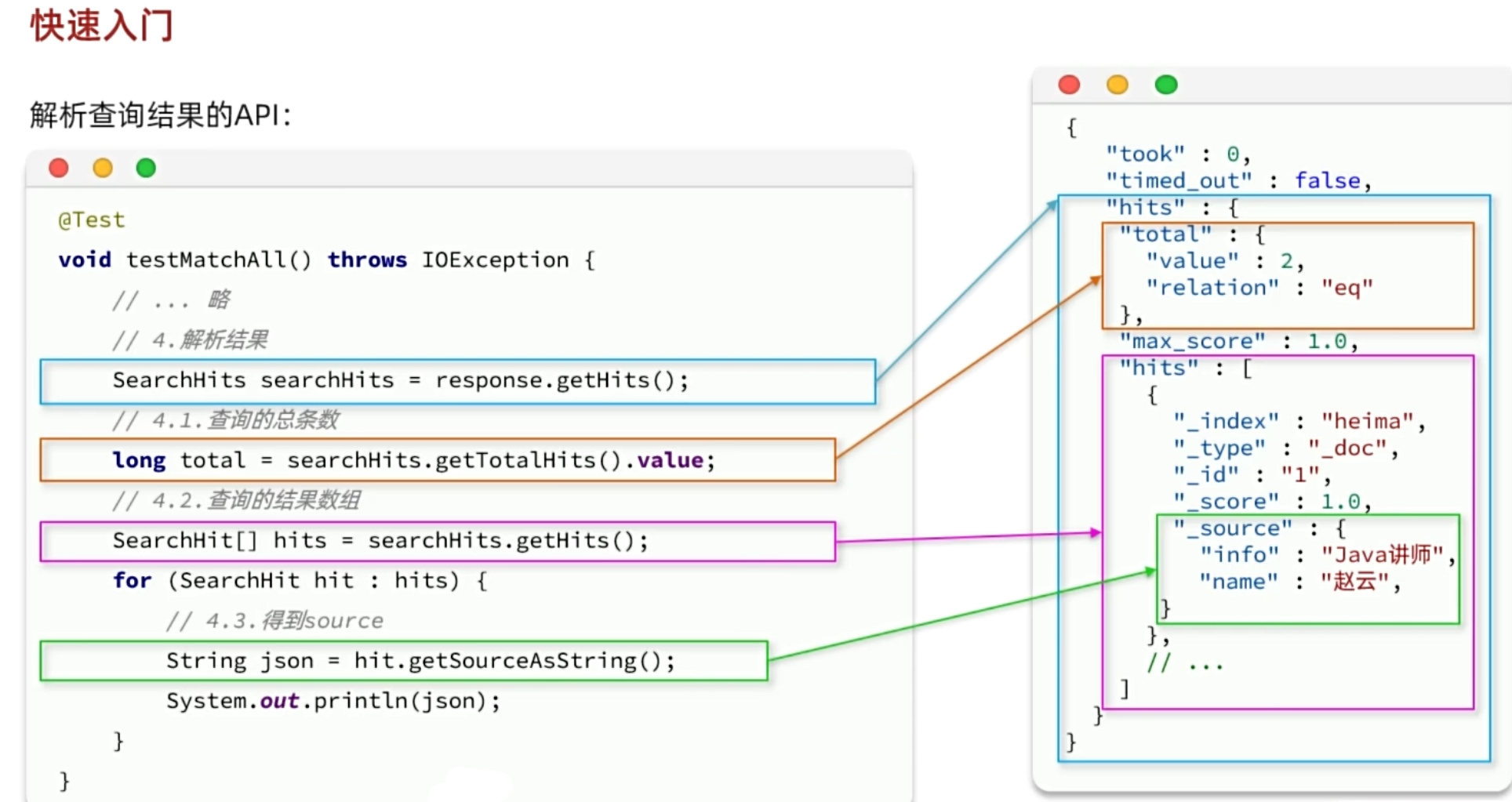
- 解析数据
![]()
数据聚合
聚合(aggregations) 可以实现对文档数据的统计 分析 运算 常见的有三类
-
桶(Bucket)聚合 来对文档进行分组
- TermAggregation 按照文档字段值进行分组
- DateHistogram 按照日期阶梯分组 一周为一组 一月为一组
-
度量(Metric)聚合 来计算最大最小平均值
- Avg 求平均
- max
- min
- Stats 同时求max min avg sum等
-
管道(pipeline)聚合 其他聚合的结果为基础做聚合
参与聚合的字段必须是Keyword 数值 日期 布尔类型的字段
DSL聚合

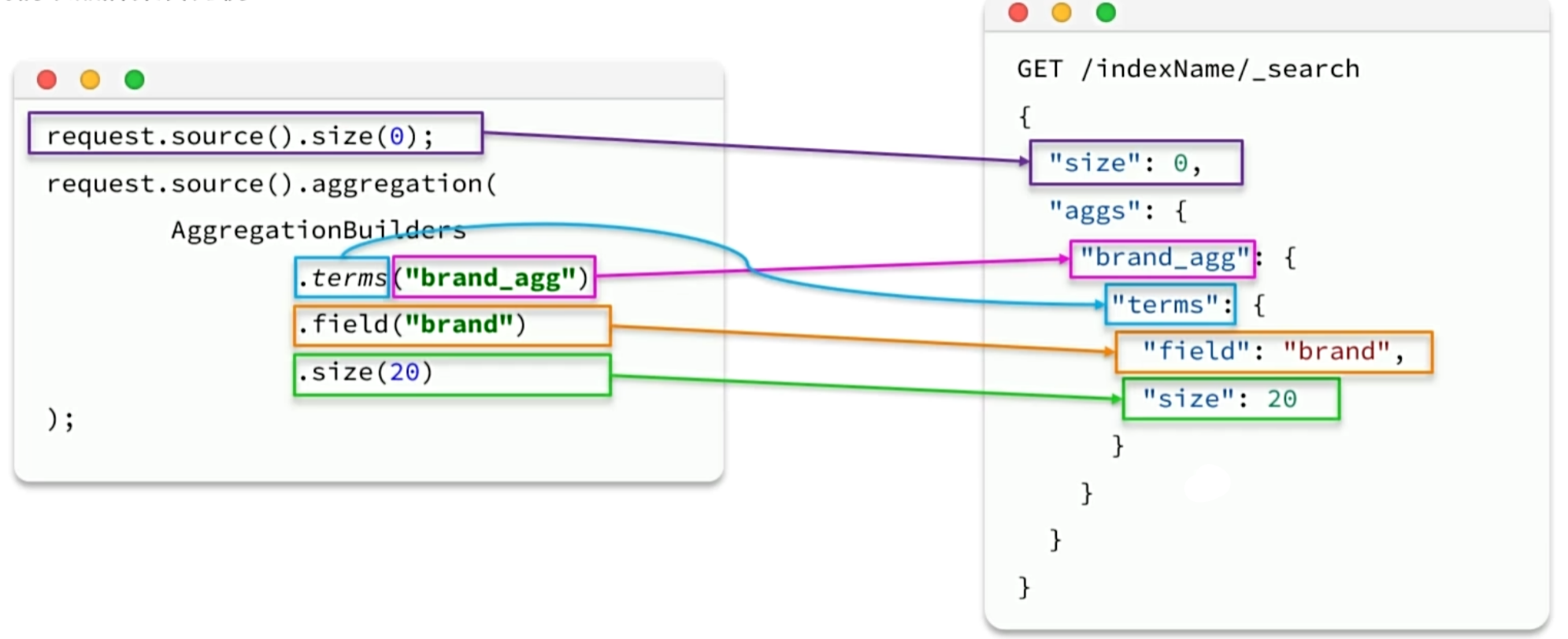
JavaRestClient聚合

 浙公网安备 33010602011771号
浙公网安备 33010602011771号