

黑马点评心得
心得
短信部分
自动注入相关
当使用的类不是spring容器内的话 这时候就不能自动注入 而如何使用就需要用构造函数来添加进来

因为这是拦截器 然后在配置类里就可以自动注入StringRedisTemplate达到拿到这个类的操作

这里这样做是因为这个配置类是spring的组件 就可以通过注入来拿到 使用@Resource和@Autowired无明显差别 前者是jdk的 后者是spring的
类型转换序列化
由于StringRedisTemplate中的哈希数据类型都要求是String类型 因此存储的时候有可能有些普通类不是以String类型存储的 有可能id就是其他类型 因此这时候进行存储的时候就要对这个Map进行一个自定义转换规则 把所有的字段值都进行String处理 这样就不会出现问题了
原代码是
Map<String, Object> userMap = BeanUtil.beanToMap(userDTO);
修改之后是
Map<String, Object> userMap = BeanUtil.beanToMap(userDTO,new HashMap<>(),
CopyOptions.create().
setIgnoreNullValue(true).
setFieldValueEditor((fieldName,fieldValue)->fieldValue.toString()));
其实思路就是定制了规则 先忽略空的字段值 然后根据lambda表达式来表示匿名函数 具体逻辑就是Map中的字段值全部toString 这样就可以做到序列化正常了
缓存问题
任何层面都有缓存 对于Web应用来说 浏览器缓存 tomcat缓存 数据库缓存 CPU缓存 磁盘读写缓存
List存储
有一个接口为/shop-type/list这个接口主要就是查询店铺分类的接口 要给这个做缓存处理 然后思路很简单 就是从redis中查 没查到查数据库 查到返回
但是由于这个返回值是list类型 所以存取考虑使用List进行redis存储 但是使用的又是StringRedisTemplate类 这个是以List
具体思路是把List
存
- 查询数据库
List<ShopType> shopTypeList = typeService.query().orderByAsc("sort").list(); - 通过stream流进行转化成JSON字符串
List<String> collect = shopTypeList.stream() .map(shopType -> JSONUtil.toJsonStr(shopType)) .collect(Collectors.toList()); - 再进行存储
stringRedisTemplate.opsForList().rightPushAll(SHOP_TYPE_KEY, collect);
取
- 拿到以JSON字符串存取的对象
List<String> shopStr = stringRedisTemplate.opsForList().range(SHOP_TYPE_KEY, 0, -1); - 把JSON的List转换成ShopType的List
List<ShopType> shopTypeList = shopStr.stream() .map(str -> JSONUtil.toBean(str, ShopType.class)) .collect(Collectors.toList());
缓存更新策略

最佳实践
- 低一致性需求:使用redis自带的内存淘汰机制
- 高一致性需求:主动更新 并以超时剔除作为兜底方案(也就是设置超时时间)
- 读操作
缓存命中 直接返回
未命中 查询数据库 写入缓存 设置超时时间 - 写操作
先写数据库 再删除缓存
确保数据库和缓存操作的原子性
- 读操作
为什么先写数据库再删缓存
因为先删缓存后写数据库 因为如果两个线程 A线程是删缓存 写数据库操作 B线程查询操作 如果A线程删缓存 还没写数据库 此时B线程进来查询 缓存未命中 由于缓存读写速度远高于数据库读写 然后查数据库 数据库还没改 所以查到是之前的值 并且会把这个值写到缓存里 此时数据库再写 所以就会导致数据库与缓存不一致性但是我这有个问题 如果先删缓存 再写数据库 写完之后再写缓存 答这样操作每次写之后都要写缓存 缓存未命中也要写缓存 代码量过大 效率低
而先写数据库后删缓存 这个的特殊情况是 缓存过期 然后缓存未命中 拿到的是之前的值 要写入缓存 此时改数据库 数据库更改成功 但是缓存写的是之前的 这个的概率远低于上面 所以采用这个方案
注意
因为更新缓存是同时操作数据库和缓存 所以如果操作数据库或者操作缓存出现了问题 需要回滚 给当前方法加上事务
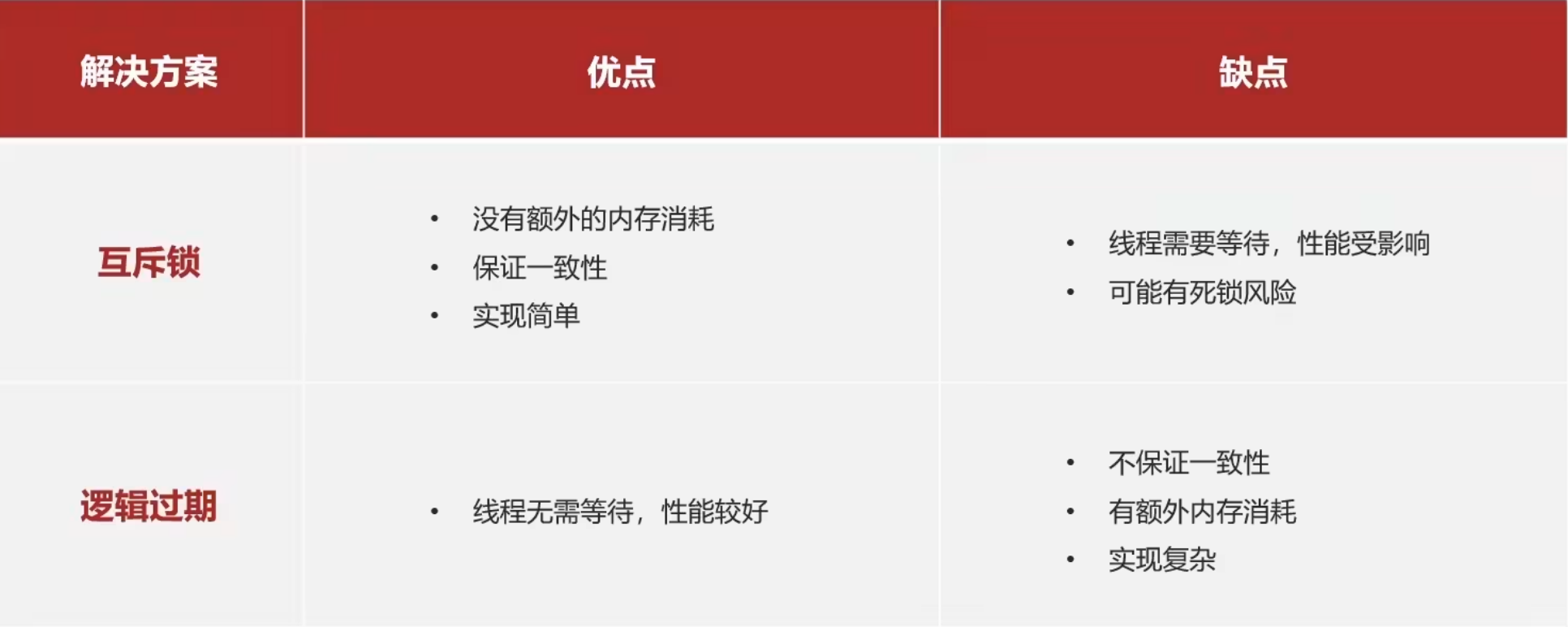
缓存穿透
指客户端请求的数据在缓存和数据库中都不存在 这样缓存永远不会生效 这些请求都会打到数据库 如果请求过大 就会出现问题
两种实际解决方案
- 缓存空对象
优点:实现简单 维护方便
缺点:1.额外的内存消耗 2.可能造成短期不一致 - 布隆过滤器
优点:内存占用小 没有多余的KEY
缺点:实现复杂 存在误判可能
实际黑马点评开发采用缓存空对象解决
真正解决方案
- 缓存null值
- 布隆过滤
- 增强id复杂度 避免id被猜测id规律
- 做好数据基础校验格式
- 做好响应权限
- 做好热点参数限流
缓存雪崩
指同一时间段内大量的缓存key失效或者redis服务器宕机 造成大量请求达到数据库 引起数据库压力过大
解决方案
- 给不同的key设置随机的TTL
- 利用redis集群提高服务的可用性
- 给缓存业务添加降级限流策略(面对大量请求 某些请求快速响应失败 保证整个数据库健康)
- 给服务添加多级缓存策略
缓存击穿
缓存击穿也叫热点Key问题 就是一个被高并发并且缓存重建业务比较复杂的Key突然失效 无数请求就会对数据库造成巨大压力

常用解决方案有两种
- 互斥锁
- 逻辑过期
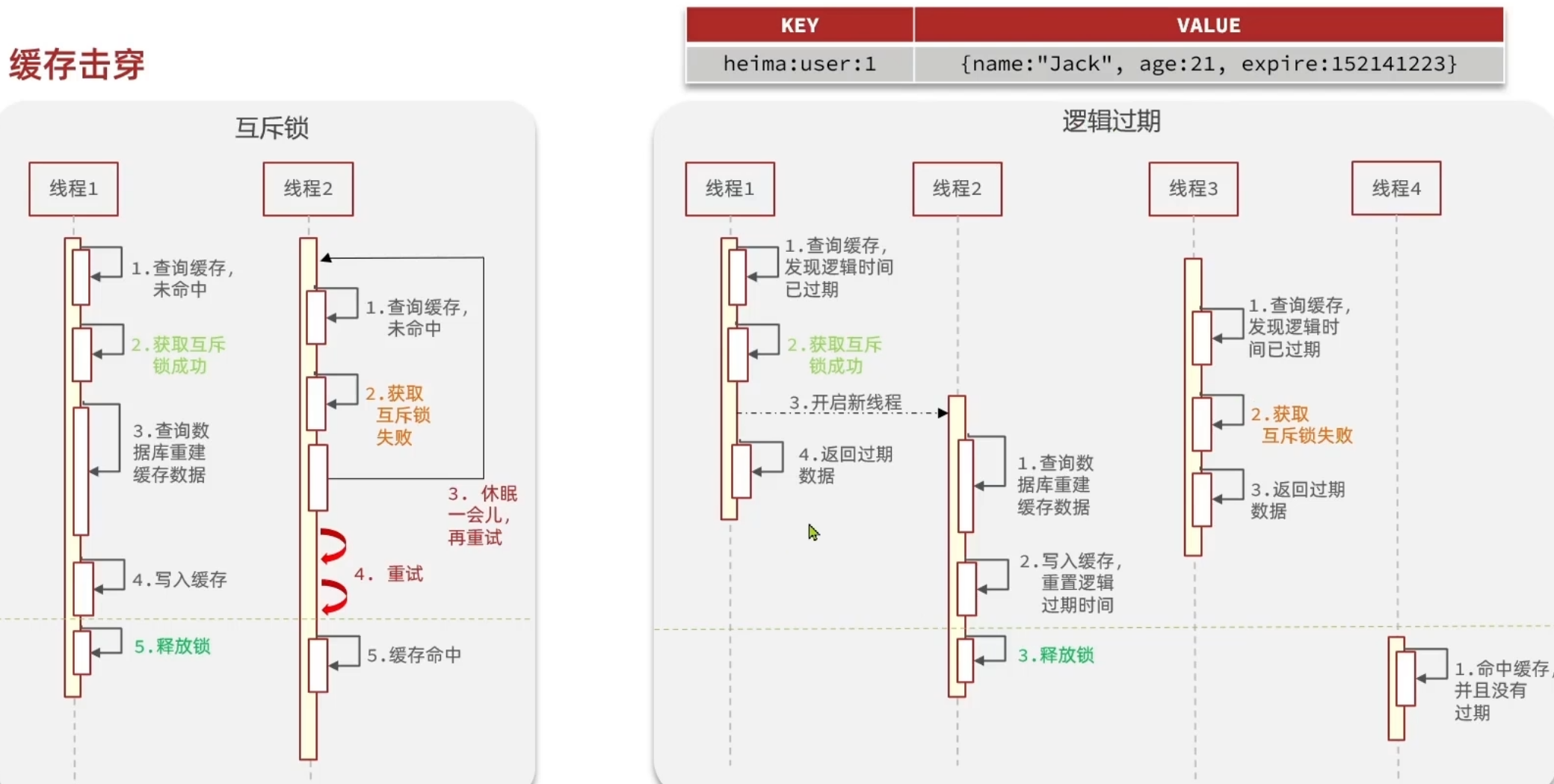
互斥锁就是 如果失效 加一个锁 然后去重建热点key 但是这个过程中会有其他线程等待 等待时间过长 大量线程发生阻塞
逻辑过期就是不设置TTL 而在存储的时候逻辑上给一个时间值 当发现这个逻辑上过期的时候 查询出来的就是旧数据 这时候获取锁 新开一个线程 重建热点key 自己和其他的线程都返回旧数据
优惠券
点击优惠券就会产生订单 而订单存在一些特点一个就是数据量大 一个订单应该唯一 所以就需要用到全局唯一ID生成器
全局ID生成器
是一种在分布式系统下用来生成全局唯一ID的生成器 一般具有以下特征
- 唯一性
- 高性能
- 安全性
- 高可用
- 递增性
为了安全性 不适用redis自带的递增值 而是拼接一些其他信息

优化问题
超卖问题
多线程超卖可能会引起优惠券库存为负数 所以需要对优惠券相关代码加锁 锁有两种
- 悲观锁 认为线程安全问题一定会发生 只要执行代码 就获取锁 执行完 放开 确保线程都是单线程执行 如synchronized lock都属于悲观锁 还有数据库相关锁也是悲观锁
- 乐观锁 认为线程安全问题不一定发生 发生概率低 只需要在更新数据时判断有没有其他线程对数据做了修改即可 因此 效率高 如果没有修改 说明没问题 已经修改 就重试或者抛异常
乐观锁解决
-
版本号法
就是对数据加一个版本 然后核验数据的时候带上版本号 如果相同 才会操作 如果不同 就不会操作
![]()
-
CAS法
就是对版本号法的更新 利用数据本身作为版本号
![]()


乐观锁可以进一步修改 让版本号和自身大于0 因为库存比较特殊
一人一单
这个要实现其实就是查询 保证用户id和优惠券id只有一个 因此这个是没有更新操作的 所以只能用线程串行执行的方式 也就是悲观锁synchronized 锁的范围也需要规定 如果加到方法上 就是对this进行上锁 锁的范围过大 如果抽取方法 加在执行一人一单的逻辑内 那样锁的范围就会过小 因为当锁释放了之后 还并没有写入到数据库中 所以正确的锁是把一人一单的逻辑包起来 就是包括起来事务 让事务先提交 再释放锁 保证数据库操作完之后 锁释放 详情观看redis第五十四集
需要注意的是

由于这个方法是调用的方法 而调用的方法上加了事务 但是调用方法时this来进行调用的 而spring事务的生效是依靠的代理对象进行事务的管理 所以这样操作事务会失效 因此就需要获得当前对象的代理对象 然后通过代理对象来调用这个方法 让spring进行管理 所以就能正确的管理事务操作
- 还有问题
在并发集群模式下 还是会有并发安全问题 也就是集群模式下 会有多个jvm 然后里面的堆栈都是不同的 因此可能是多个进程在多个jvm里并行执行 在这个情况下 synchronized就会失效 因为这个锁只能锁住同一个jvm下
分布式锁
满足分布式系统或者集群模式下多进程可见并互斥的锁

基于redis实现的分布式锁
- 获取锁
setnx lock thread1 - 设置超时时间
expire lock 10 - 释放锁
del lock - 超时释放
但是同时又出现问题 有可能在获取锁之后 设置超时时间之间服务器就炸了 所以还是会出问题 所以就汇聚到一条命令里 set lock thread1 nx ex 10
并且采用非阻塞式的 只尝试一次 成功返回true 失败返回false

获取锁
由于java中封装的stringRedisTemplate封装的setnx是Boolean 然后定义的函数是boolean 拿到的结果需要拆箱 所以如果结果是一个空指针 可能会出现空指针错误
所以需要进行true和false的判断Boolean.TRUE.equals(success)来对结果进行判断
如此设计 就会出现一个问题
误删问题
由于获取锁之后删除锁是直接删除 所以如果因为进程阻塞然后超过TTL导致锁自动释放 然后其他进程拿到锁 但是此时却给其他进程的锁删掉了 又会引起高并发问题

因此 释放锁的时候需要判断value是不是自己线程所有的value 如果是自己的 再删除
从而可以解决误删问题 但是还是可能会有误删 因为判断锁标识和删除锁并不是原子性操作 还有可能会阻塞 然后继续导致高并发问题

lua脚本解决误删问题
lua脚本是一种编程语言 在一个脚本中包括多个redis命令 确保多条命令执行时的原子性 可以理解为redis的事务
redis中有调用函数 使用语法redis.call('set','name','jack'),redis.call('get','name')
然后写好脚本之后可以使用EVAL命令来调用脚本 如EVAL "return redis.call('set','name','jack')" 0
0是key类型的数量
然后也可以不写死 EVAL "return redis.call('set',KEYS[1],ARGS[1])" 1 name jack
由此可以使用lua脚本实现redis语句的原子性操作 比如要获取锁id和判断锁id以及删除这三个为一起执行
if(redis.call('get',KEYS[1])==ARGV[1]) then
return redis.call('del','KEYS[1])
end
return 0
基于redis实现分布式锁的思路
- 利用setnx设置锁 保证锁的互斥性 设置过期时间 保存线程标识
- 删除锁时验证锁标识是否和自己一致 一致删除 不一致不删
特性:
- 高并发和高可用性
- 基于lua脚本实现的操作原子性
- 利用set nx满足互斥性
- 利用set ex保证故障时依然可以删除锁
Redisson
基于setnx实现的分布式锁存在下面四个问题
- 不可重入性
同一个线程无法多次获得一把锁 也就是同一个线程中有两个方法 a调用b b调用a 但是两个方法都需要获得锁 setnx就不可以 - 不可重试性
获取锁之后只尝试一次就返回false 没有重试机制 - 超时释放
超时释放虽然可以避免死锁 但如果业务执行耗时较长 也会导致锁释放 存在安全隐患 - 主从一致性
如果redis提供的主从集群 主从同步存在延迟 当主节点宕机时 从节点还没有同步数据 那么就会数据不一致
因此为了解决这些问题 就引入了Redisson
Redisson入门
- 引入依赖
redisson的依赖 版本无所谓 视频版本为3.13.6 - 配置
新建一个RedissonConfig类 然后配置RedissonClient并放入组件中
@Bean
public RedissonClient redissonClient(){
//配置
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.88.130:6379").setPassword("123456");
//创建对象
return Redisson.create(config);
}
- 使用
自动注入RedissonClient然后通过getLock得到锁对象 然后lock.tryLock得到互斥锁
Redisson可重入锁原理
重入锁就是同一个线程多次调用一把锁

底层实现不再是setnx了 因为要有多次获取的操作 所以需要记录次数 还需要记录线程id 还有key 所以使用的是哈希结构存储实现
然后每当获取锁的时候 先判断是不是自己来获取 如果是自己获取 那么就获取次数自增 并更新TTL然后实现可重入锁 当释放锁的时候 判断获取次数是不是0 如果不是0 代表还没走到最外层 因此只需要自减1然后更新TTL即可 只有当判断出来获取次数是0 才直接删除锁
注意:添加锁 设置有效期 这种逻辑 都应该使用lua脚本来实现 保证原子性操作
Redisson分布式锁流程
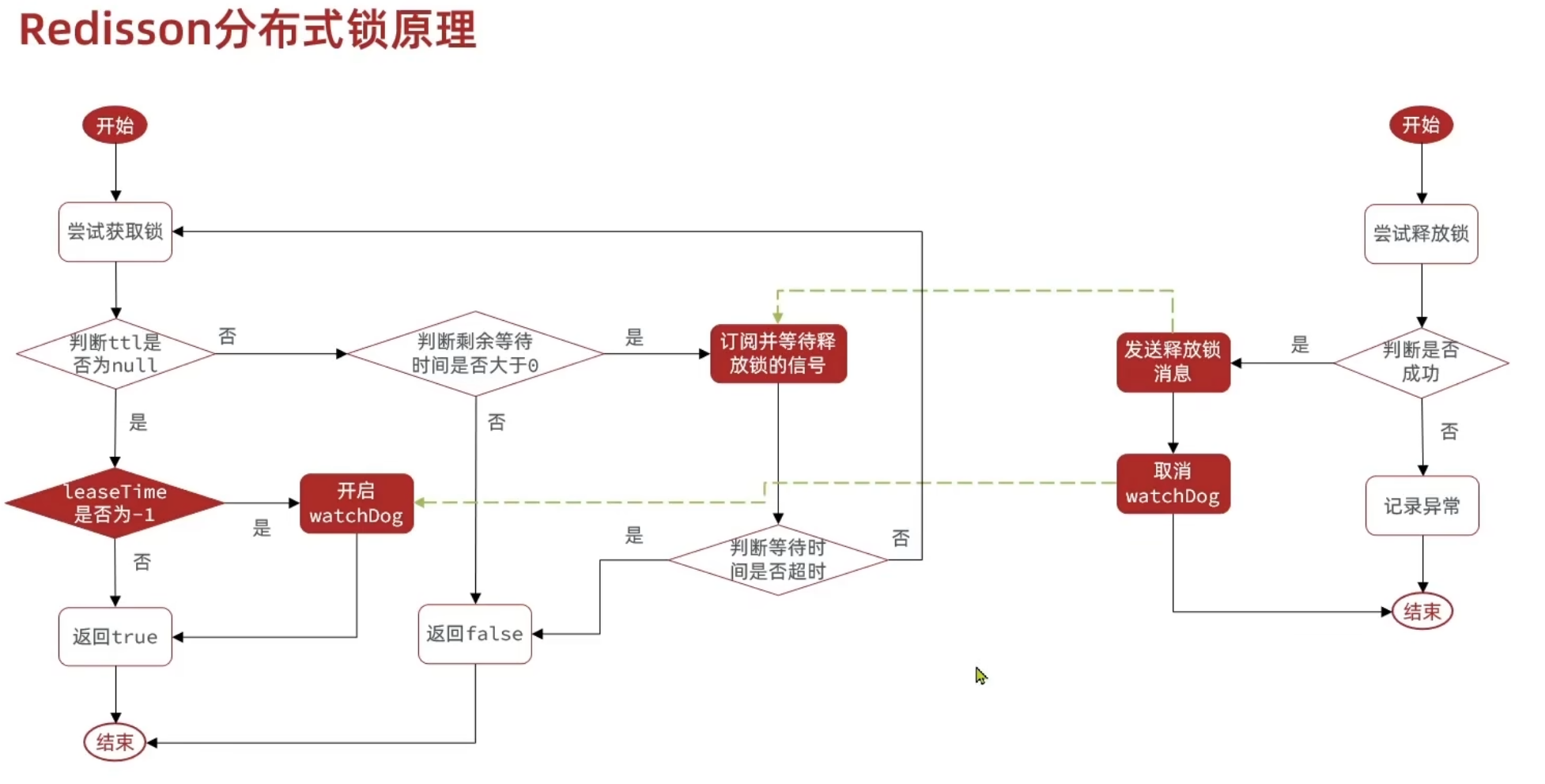
redisson分布式锁原理解决setnx带来的问题
- 可重入 利用hash结构记录线程id和重入次数
- 可重试 利用信号量和publish subscribe功能来实现等待唤醒 也就是当获取锁失败的时候 并不会立即失败 而是会等待 等有的线程成功之后 会发布消息 然后订阅消息达到重试功能 每一次都需要计算时间 如果没有时间了 直接失败即可
- 超时续约 利用watchDog机制 每隔一段时间来重置超时时间
Redisson主从一致性问题
利用RedisMultiLock类来实现联锁
利用多个独立的redis节点 必须所有节点都获取成功之后 才会成功获取锁 每一个流程都是循环获取 然后获取成功就刷新有效期 但是缺点就是运维成本高 实现复杂
秒杀业务优化
秒杀流程
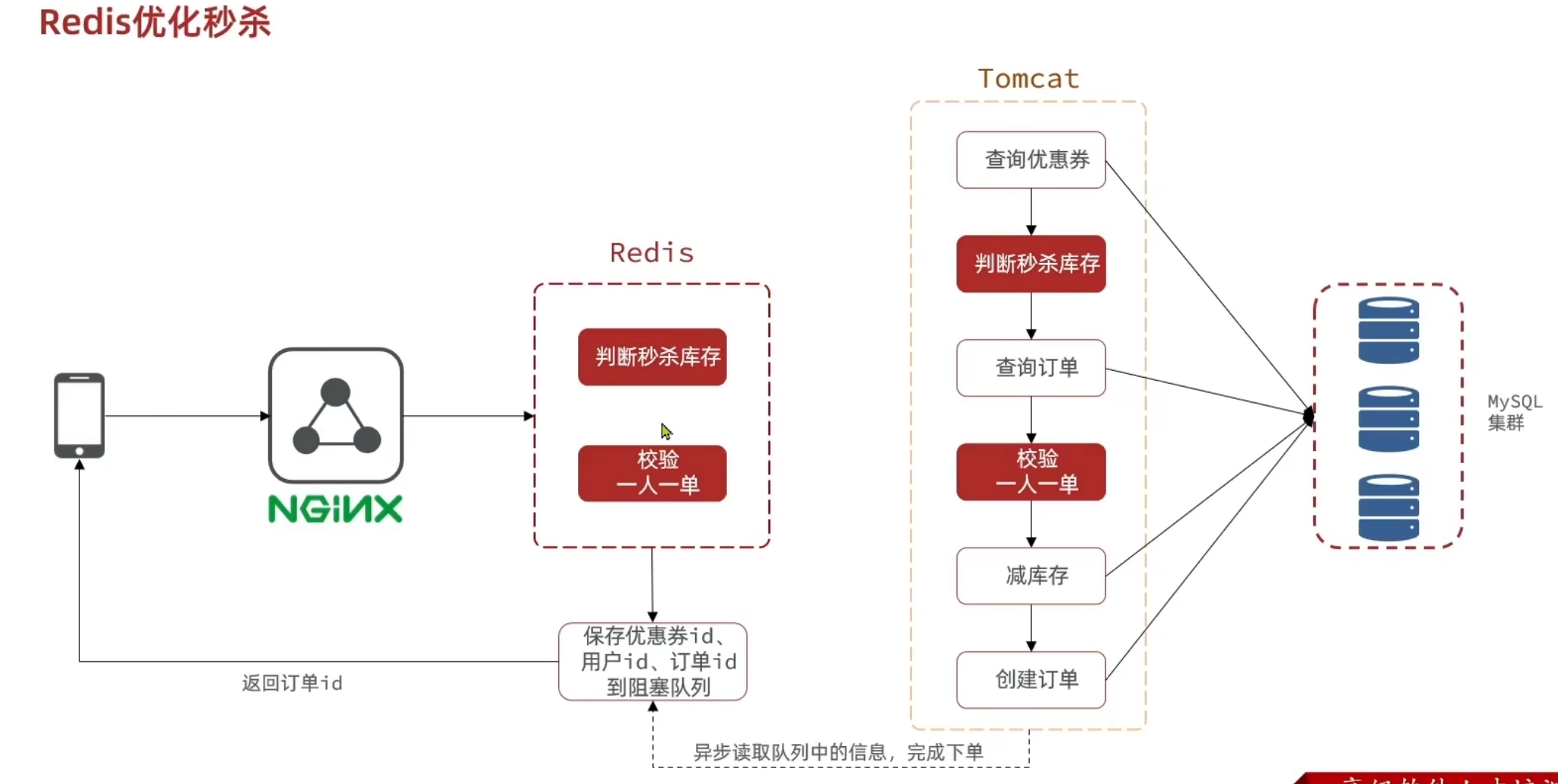
之前的请求是全部打到了数据库 而且还有不断的写操作 现在进行优化就是将写操作交给数据库 然后核验资格给到redis redis做完判断直接返回给用户 并把所有的信息给到阻塞队列 这是第一个线程做的事 第二个线程从队列里拿到东西 再开始访问数据库 开始执行耗时的写操作 此时其实早就完成业务了 相当于是另一个线程在后台慢慢执行
主要流程就是
- 将操作redis的所有操作写为lua脚本 保证原子性 通过set来设置解决一人一单和超卖问题
- 生成订单对象之后直接放入阻塞队列中 在阻塞队列中去通过另一个子线程 异步执行操作数据库的部分 大大提高速度
但是其中有很多问题
-
由于是子线程 所以ThreadLocal不能用了 这个用不了 userId不能获取 proxy代理对象不能获取
解决问题就是userId通过阻塞队列里穿过来的订单获取 然后proxy可以定义为成员变量 在主线程中先获取 然后在子线程中使用 异步执行 是不需要返回值的 -
定义的单线程来执行操作数据库 因此需要定义一个匿名类来执行数据库逻辑 匿名类继承Runnable 写完之后保证这个子线程从一开始就在等待获取 只要阻塞队列里有东西 第一时间就能拿到 确保这个实现 所以需要将init方法重写一下 然后在该方法中提交这个匿名类执行 并且
@PostConstruct通过后置处理器来确保这个对象刚初始化完 就可以操作这个子线程
如此 秒杀才算优化完成
但是还有一些问题没有解决
- 内存限额问题 比如当订单量过大 单线程内存吃满了之后就没办法了
- 数据安全问题 由于订单全在redis中 如果此时数据崩溃就没办法了
redis消息队列实现异步秒杀
消息队列(Message Queue) 存放消息的队列 分为三个部分
- 生产者:发送消息到消息队列
- 消息队列:存储和管理消息 也称消息代理
- 消费者:从消息队列中获取消息和处理消息
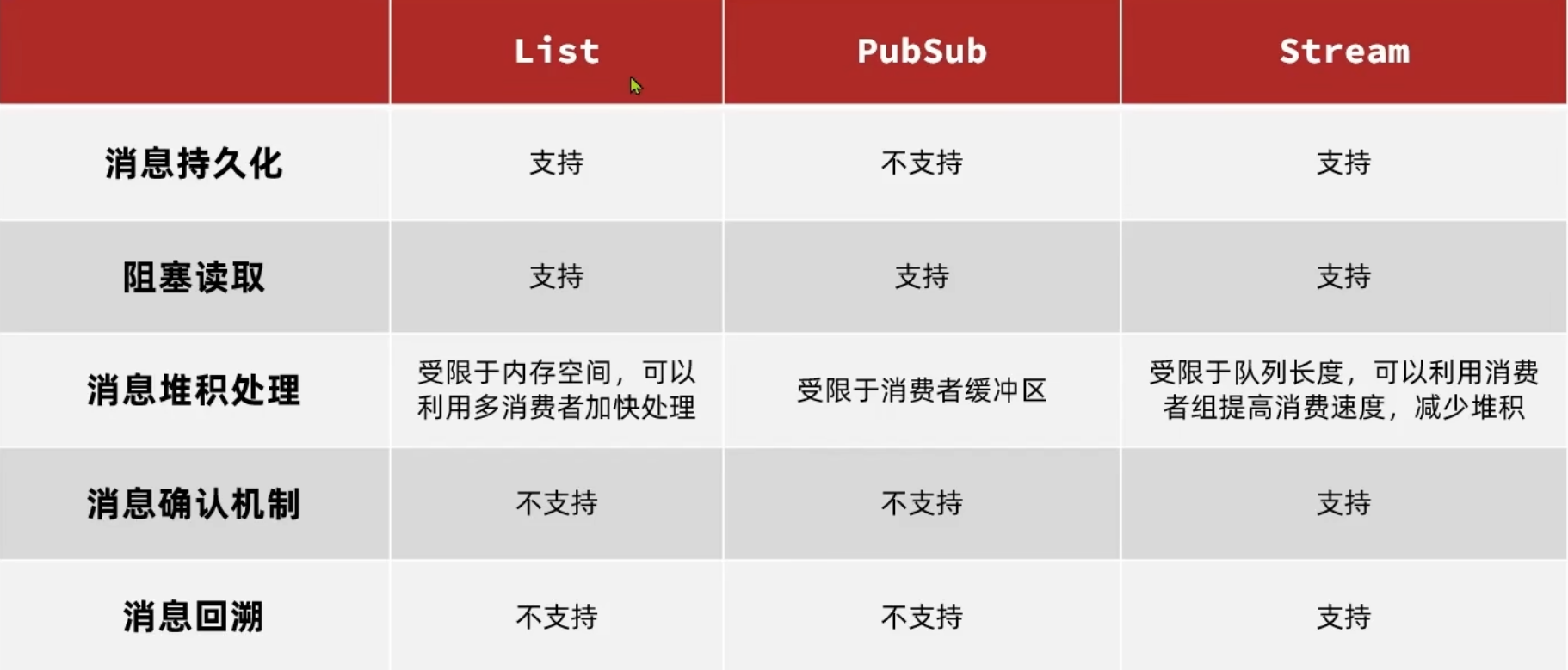
Redis提供了三种消息队列实现
- List 基于list结构模拟消息队列
- pubsub 发布订阅的消息队列 但是不够完善
- Stream 比较完善的消息队列
基于List实现
Redis中的List是一个双向链表 因此需要用双向链表模拟队列实现 很简单 队列是出口入口不在同一个口 所以需要RPUSH和LPOP实现 或者相反 但是简单的RPUSH和LPOP并没有阻塞的效果
因此需要用BLPUSH和BRPOP来实现阻塞的效果
优点
- 利用redis存储 不依赖JVM内存上限
- 基于Redis的持久化机制 数据安全性有保证
- 可以满足消息有序性
缺点
- 无法避免消息丢失
- 只支持单消费者
基于pubsub的消息队列
消费者可以订阅一个或多个channel 生产者发送消息之后 所有订阅者都可以收到消息
SUBSCRIBE channel [channel]
PUBLISH channel msg
PSUBSCRIBE pattern[pattern]订阅与pattern格式匹配的所有频道
优点
多生产多消费
缺点
- 不支持数据持久化
- 无法避免消息丢失
- 消息堆积有上限 超出时数据丢失
Stream实现
是一种数据类型 可以做持久化 专门为消息队列设计

因此最简消息命令应该是XADD users * name jack age 21
就是创建名为users的队列 自动生成id 内容是{name=jack,age=21}

优点
- 消息可回溯
- 一个消息可以被多个消费者读取
- 可以阻塞读取
缺点 - 有消息漏读的风险
基于Stream的消息队列--消费者组
消费者组:将多个消费者划分到同一个组里 监听同一个队列

语法:XGROUP create key groupName ID [MKSTREAM]
- key 队列名称
- groupName 组名称
- ID 标识 $代表最新的消息 0代表从第一条获取
- MKSTREAM 队列不存在自动创建
其他语法如下
#删除指定的消费者组
XGROUP DESTORY key groupName
#给指定的消费者组添加消费者
XGROUP CREATECONSUMER key groupname consumername
#删除消费者组中的指定消费者
XGROUP DELCONSUMER key groupname consumername
从消费者组读取信息
语法:XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...]
- group 消费组名称
- consumer 消费者名称 不存在自动创建
- count 查询的最大数量
- BLOCK milliseconds 最长等待时间
- NOACK 无需手动ACK 收到消息后自动确认
- STREAMS key 指定队列名称
- ID 获取消息的起始ID
- '>' 从下一个未消费的消息开始
- 其他 根据指定id从pending-list中获取已消费但是未确认的消息
特点
- 消息可回溯
- 多消费者争抢消息 加快消费速度
- 可以阻塞读取
- 没有消息漏读的风险
- 有消息确认机制 保证消息至少消费一次
基于Stream实现消息队列解决异步秒杀问题
和阻塞队列区别就是在lua脚本中增加一个orderId 然后直接使用strea消息队列添加进去这个消息
---3.6 发送消息到队列中 XADD stream.orders * k1 v1 k2 v2
redis.call('xadd','stream.orders','*','userId',userId,'voucherId',voucherId,'id',orderId)
然后原本主线程流程就会减少 因为不需要放到阻塞队列 拿到lua脚本返回信息直接校验结果返回即可 增加的东西都在子线程异步处理中 反而效率提升了
在子线程异步处理中先获取订单信息
//获取消息队列中的订单信息 XREADGROUP GROUP g1 c1 COUNT 1 BLOCK 2000 STREAMS stream.orders >
List<MapRecord<String, Object, Object>> list = stringRedisTemplate.opsForStream().read(
Consumer.from("g1", "c1"),
StreamReadOptions.empty().count(1).block(Duration.ofSeconds(2)),
StreamOffset.create(queueName, ReadOffset.lastConsumed())
);
获取完之后验证该订单信息中是否有东西 如果没有就continue 一直等待循环 不会很快循环 因为有阻塞2s
拿到之后解析订单信息 通过get(0)拿到结果record 而record.getValue()就是消息中的内容 是一个map对象 再通过BeanUtil.fillWithMap(value, new VoucherOrder(), true)填充voucherOrder类 拿到voucherOrder 然后让代理对象根据该voucherOrder执行
后续流程
点赞
点赞过程中出现多用户 先点赞的排前面 但是显示效果却是在后面 传数据也是 根本问题就出在数据库的IN语句上 并不会按给定的顺序传 而是会按数据库的id返回

解决办法就是使用order by语句 order by field(id,5,1)保证根据排序的顺序和传过来的顺序是一致的
Feed流投喂
常见有两种
-
TimeLine 不做内容筛选 简单的按照内容发布时间排序 用于好友或者关注 例如朋友圈
- 优点 信息全面 不会有缺失 实现相对简单
- 缺点 信息噪音较多 用户不一定感兴趣 内容获取效率低
-
智能排序 利用智能算法屏蔽掉违规的 用户不感兴趣的内容 推送用户感兴趣信息来吸引用户
- 优点 投喂用户感兴趣信息 用户黏度较高 太容易沉迷
- 缺点 如果算法不精准 可能会起到反作用
feed流实现
-
拉模式 也叫读扩散
![]()
-
推模式 也叫写扩散
![]()
-
推拉混合 读写结合
![]()



排序
排序使用Zset来排序 然后使用降序ZREV 还需要根据score值来排序 要做滚动分页查询 保证不会因为数据的更新导致角标混乱 因此就是ZREVRANGESCORE
难点就是一个小算法 需要不断更新最小值 然后来判断当前time和最小time是不是相同 如果相同 os加1 当前时间比最小时间小 就重置最小时间 并且重置os
//ZREVRANGEWITHSCORES key max min offset count
Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet()
.reverseRangeByScoreWithScores(key, max, 0, offset, 2);
if(typedTuples == null || typedTuples.isEmpty()) {
return Result.ok();
}
//解析数据 blogId minTime(时间戳) offset
List<Long> ids = new ArrayList<>(typedTuples.size());
long minTime = 0;
int os = 1;
for (ZSetOperations.TypedTuple<String> tuple : typedTuples) {
ids.add(Long.valueOf(tuple.getValue()));
long time = tuple.getScore().longValue();
if(time == minTime) {
os ++;
}else {
minTime = time;
os = 1;
}
}
BitMap

UV/PV
- UV unique vistor 也叫独立访客量 通过互联网访问这个网站的人 一个人一天多次访问该网站 只记录一次
- PV page vistor 叫页面访问量/点击量 同一个人多次打开 记录多次
采用HyperLog来实现UV统计


 浙公网安备 33010602011771号
浙公网安备 33010602011771号