学习爬虫知识,拿电影天堂练习一下,新手代码写的不够优雅,也还没有优化,请看官大佬们见谅
爬虫会对目标站点造成一定的压力,请不要滥用!
1、分析网页的 URL 的组成结构,主要关注两方面,一是如何切换选择的电影类型,二是网页如何翻页的。
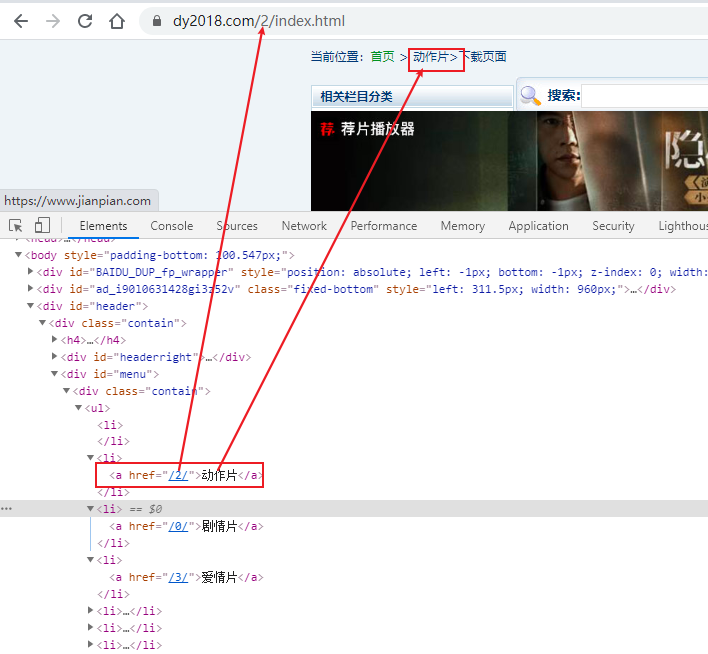
url上的数值和类别是对应的 ,对应关系为:
self.movie_label={"0":"剧情片","1":"喜剧片","2":"动作片","3":"爱情片","4":"科幻片","5":"动画片","6":"悬疑片","7":"惊悚","8":"怖片","9":"录片","10":"同性题材电影","11":"音乐歌舞题材电影","12":"传记片","13":"历史片","14":"战争片","15":"犯罪片","16":"奇幻电影","17":"冒险电影","18":"灾难片","19":"武侠片","20":"古装片"}
写为字典形式以方便调用。
随便打开一个分类,我们滚动到页面的最下面,发现这里有翻页的按钮,点击按钮翻页的同时,观察 url 的变化。
除了第一页是 「index」外,其余页码均是 「index_页码」的形式。
| 页码 | URL |
| 第一页 | https://www.dy2018.com/2/index.html |
| 第二页 | https://www.dy2018.com/2/index_2.html |
| 第三页 | https://www.dy2018.com/2/index_3.html |
| 第四页 | https://www.dy2018.com/2/index_4.html |
代码中如下处理url构成:
for ks in self.movie_label.keys(): # 从影片类别 字典key值 获取 路径
urii = 'https://www.dy2018.com/{}/index_{}.html'
for jj in range(1,len(lsls)+1): # 通过最大页码,进行遍历该影片类别
# for jj in range(151, 152):
if jj == 1:
neww_url = 'https://www.dy2018.com/{}/index.html'.format(ks)
else:
neww_url = urii.format(ks, jj)
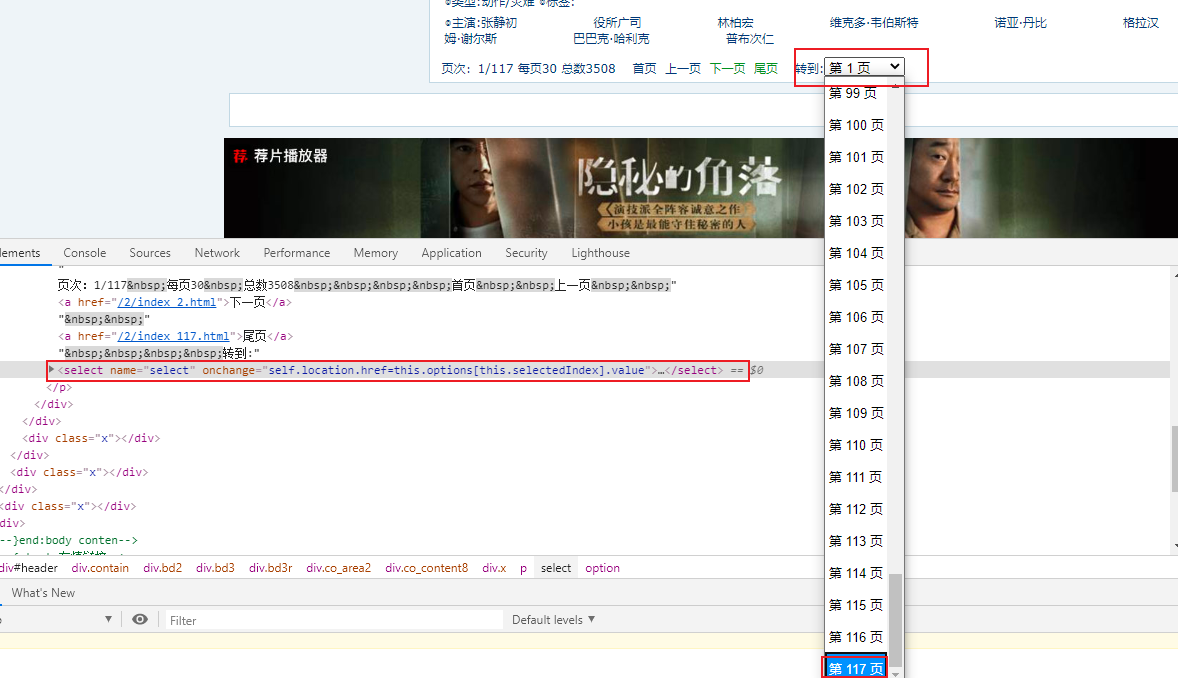
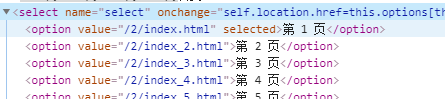
2、获取类别下最大页码数
使用BeautifulSoup findAll 通过select 标签的下的option标签获取到一个列表,通过列表的长度len(),判断页码总数,然后用for循环
textz = (self.get_page_text(urlll, header=self.heard, loc='class="co_content8"', isindex=False)) dd_soup = textz.findAll("select") for sele in dd_soup: lsls = (str(sele).split("</option><option")) # 最大页码为页码标签列表的长度len u_l = [] for jj in range(1,len(lsls)+1): # 通过最大页码,进行遍历该影片类别 # for jj in range(151, 152): if jj == 1: neww_url = 'https://www.dy2018.com/{}/index.html'.format(ks)
3 ,提取页面上当前类别下的影片信息,获得movie_title, movie_url ,然后发起请求,进一步处理
4、获取影片的下载地址:
页面所有的下载链接 bgcolor="#fdfddf" ,根据这个,使用BeautifulSoup findAll 获得一个列表,然后再用正则就容易多了

for j in one_soup.findAll(bgcolor="#fdfddf"): # 获取下载链接, if len(self.get_downURL(str(j))) == 0: for jj in one_soup.find_all("u"): u_l.append(self.get_downURL(str(jj))) u_l.append(self.get_downURL(str(j)))
def get_downURL(self,str_text): """ 获取下载地址 :param str: :return: """ down_mag= '(magnet:).*?.*(\.mp4|\.mkv)&' down_ftp = '(ftp://).*?"' down_ftp2 ="(ftp://).*?<" url_ls =[] if re.search(down_mag, str_text): url = re.search(down_mag, str_text) url = url.group() url = url.replace('amp',"").strip("&") url_ls.append(url) if re.search(down_ftp, str_text): urll = re.search(down_ftp, str_text) urll = urll.group() urll = urll.replace('"',"") url_ls.append(urll) if re.search(down_ftp2, str_text): urll = re.search(down_ftp2, str_text) urll = urll.group() urll = urll.replace('<',"") url_ls.append(urll) return url_ls
5、写入MySQL
先上mysql部分的代码:handl_sql.py
# -*- coding: utf-8 -*- # @Time : 2020/6/23 # @Author : 小小蜗牛 # @Email : ***_@outlook.com import pymysql,time,re,logging class HandelMysql(): def __init__(self): f = {"host": "127.0.0.1", "port": 3306, "user": "root", "passwd": "123456", "db": "getting_movie_info", "charset": "utf8", "cursorclass": "pymysql.cursors.DictCursor"} self.conn = pymysql.connect(host=f['host'],port=f['port'], user=f['user'],passwd=f['passwd'], db=f['db'],charset=f['charset'], cursorclass=pymysql.cursors.DictCursor) self.cursor = self.conn.cursor() self.time_now = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time.time())) # 实例化时间 def run(self, sql, args=None, is_more=False): # try: self.cursor.execute(sql, args=args) self.conn.commit() if is_more: return self.cursor.fetchall() else: return self.cursor.fetchone() def re_info(self,param,info_str): """ 封装正则取值 :param param: :param info_str: :return: """ if re.search(param,info_str): info_str =re.search(param,info_str) info_str = info_str.group() return info_str def in_movie_info(self,movie_name,movie_type,download_link,movie_info,movie_lab): """ sql写入操作 :param : :return: """ movie_name_re = '《.*》' old_name = pymysql.escape_string(movie_name) movie_name_new = pymysql.escape_string(self.re_info(movie_name_re, movie_name)) get_movie = 'SELECT * FROM movie_info WHERE movie_name like "%{}%";'.format(movie_name_new) movie_type = pymysql.escape_string(movie_type) download_link = pymysql.escape_string(download_link) movie_info = pymysql.escape_string(movie_info) movie_lab = pymysql.escape_string(movie_lab) if do_mysql.run(sql=get_movie): logging.info("存在同名影片不写入!") else: sql = f"INSERT INTO `movie_info`(`movie_name`,`movie_type`,`download_link`,`movie_info`,`movie_lable`) VALUES ('{old_name}','{movie_type}', '{download_link}', '{movie_info}','{movie_lab}');" self.run(sql=sql) def close(self): """ 关闭 :return: """ self.cursor.close() self.conn.close() do_mysql = HandelMysql() if __name__ == '__main__': pass
写入数据库时,代码中对影片去重处理了,防止不同类别下有相同名称的影片

然后是页面请求处理的代码,代码比较长折叠处理了


# -*- coding: utf-8 -*- # @Time : 2020/6/29 # @Author : 小小蜗牛 # @Email : *****@outlook.com import requests,time,re,logging,datetime from urllib import parse from bs4 import BeautifulSoup as bs from openpyxl import load_workbook from contextlib import closing from handle_sql import do_mysql class GetDYTT: def __init__(self): self.heard = {"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36"} self.info_ress = '(◎影片评价.*◎影片截图)|【影片原名】.*【影片截图】|【中文译名】.*【影片截图】|(◎剧情简介).*(◎影片截图)|' \ '(译.*名).*(◎影片截图)|(译.*名).*(◎获奖情况)|((◎年.*代).*(<br/><br/><img ))|((译.*名).*(<br/><br/><img ))|' \ '((◎影片原名).*(<p style))|(【内容简介】.*【影片截图】)|(中文译名).*(影片截图)|【.*译.*名】.*【影片截图】|' \ '【片.*名】.*【影片截图】|(◎片.*名).*站长点评|(@译.*名).*(◎获奖情况)' self.movie_type_re = '((◎类.*别).*◎语)|(【类.*别】.*【语)|(◎类.*别).*(◎语.*言)|(◎类.*型).*(◎语.*言)|' \ '【影片类型】.*【影|(【类.*别】.*【对白)|(【类.*型】.*【出品公司】)' self.dl_type_text=['别',r" ","\t",'<br/>', '<p>', '◎类 别', '<span style="font-size: 14px;">', '【出品公司】', '【影', "<spanstyle='font-size:14px;'>", ' (voice)', '类', '◎', '</p>', '【类 别】', '【语', ' ', '</span>', '【对白', '◎语 言',"【","】"," ","</div>","<div>","语"] self.dl_info_text =["【影","【对白","◎影片截图","【影片截图】"," ",'<spanstyle="font-size:14px;">', "【语","类","别",r'<br/>', ' (voice)', r'</span>', r'</p>', r'<p>', r'<span style="font-size: 14px;">', " ","【出品公司】"] self.movie_type_re2 = r'(◎类.*别).*(◎语.*言)|(◎类.*型).*(◎语.*言)' self.dl_down_link = r'<tdb.*-word,' self.download_link_re = ['a href="','a href=',", []","[]","[['","']","']]",'</td>','</a>','amp;',r"'",'/a>/td>'," ",'tdbgcolor="#fdfddf"style="WORD-WRAP:break-word">','[<','ahref='] self.movie_label={"0":"剧情片","1":"喜剧片","2":"动作片","3":"爱情片","4":"科幻片","5":"动画片","6":"悬疑片","7":"惊悚","8":"怖片","9":"录片","10":"同性题材电影","11":"音乐歌舞题材电影","12":"传记片","13":"历史片","14":"战争片","15":"犯罪片","16":"奇幻电影","17":"冒险电影","18":"灾难片","19":"武侠片","20":"古装片"} self.titlt_re ='<font.*' # logging 模块调用 self.logger = logging.getLogger() self.logger.setLevel(logging.INFO) ph = logging.StreamHandler() formatter = logging.Formatter("%(asctime)s - %(levelname)s: %(message)s") # 日志格式 ph.setFormatter(formatter) # 将配置内容添加到创建的容器里 self.logger.addHandler(ph) self.base_url = "https://www.dy2018.com" def reparser_str(self,Dle_list, html_text): """ replace 删除多余的文本 :param Dle_list: :param html_text: :return: """ for i in Dle_list: if i == '<br/>': html_text = str(html_text).replace(f'{i}', "\n") else: html_text = str(html_text).replace(f'{i}', "") return html_text def re_sub_text(self,sub_re,html_text): """ re sub 删除多余的文本 :param sub_re: :param html_text: :return: """ if re.search(sub_re,html_text): html_text_op = re.sub(sub_re, "", html_text) return html_text_op else: return html_text def str_re(self,str_str,type): """ 清理 类别、详情中的冗余、html标签 :param str_str: :param type: :return: """ str_str=str(str_str) re_re = r'from.*users' re_html = '<.*>' re_yuyan = '◎语.*言.*' re_yan = '言.*' re_nian = '出品年代.*' re_guo = '国.*家.*' try: str_str = self.re_sub_text(re_re,str_str) # 清理 影片详情 if type =="info": info_str = self.reparser_str(Dle_list=self.dl_info_text, html_text=str_str) # info_str = self.re_sub_text(re_html, str_str) return info_str elif type == "type": # 清理 类别 type_str = self.re_sub_text(re_html,str_str) type_str = self.re_sub_text(re_yuyan,type_str) type_str = self.re_sub_text(re_yan,type_str) type_str = self.re_sub_text(re_nian,type_str) type_str = self.re_sub_text(re_guo,type_str) type_end = self.reparser_str(Dle_list=self.dl_type_text, html_text=type_str) return type_end except Exception as e: print(e) return str_str def re_info(self,param,info_str): """ 封装正则取值 :param param: :param info_str: :return: """ if re.search(param,info_str): info_str =re.search(param,info_str) info_str = info_str.group() return info_str def get_movie_type(self,strr): """ 获取影片类型 :param strr: :return: """ try: # 影片类别 movie_type = self.re_info(self.movie_type_re, strr) movie_type = self.str_re(str(movie_type), type="type") type_end = '../../..' movie_type_end = self.re_info(type_end, str(movie_type)) return movie_type_end except Exception: movie_type_end = "NULL" return movie_type_end def get_movie_info(self,strr): """ 获取影片信息 :param strr: :return: """ try: # 简介 movie_info = self.re_info(self.info_ress,strr) movie_info_end = self.str_re(str(movie_info), type="info") return movie_info_end except Exception: movie_info_end = "NULL" return movie_info_end def get_page_text(self,new_url, header, loc,isindex=True): try: res = requests.get(url=new_url, headers=header, timeout=10) res.encoding = "gbk" code = res.status_code # ISO-8859-1 # print(res.text) dy_soup = bs(res.text, "html.parser") self.logger.info(f"打开链接{new_url},响应码:{code}") if isindex: return bs(str(dy_soup.find_all(loc)), "html.parser") elif isindex == False: return dy_soup #dy_soup.find("div",loc).ul.text except Exception as e: if res.status_code != 200: self.logger(f"请求异常,状态码{res.status_code}") def get_uri_title(self,str_text): """ 获取 标题和URL 获取uri,title :param str: :return: """ re_str = 'title="(.*)"' re_u = "/.*.html" if re.search(re_str, str_text): title = re.search(re_str, str_text) uri = re.search(re_u, str_text) uri = parse.urljoin(self.base_url,uri.group()) # self.logger.info(f"拼接分页URL:{uri}") title = title.group() title = title.replace('title="',"").replace('"',"") return title, uri def get_downURL(self,str_text): """ 获取下载地址 :param str: :return: """ down_mag= '(magnet:).*?.*(\.mp4|\.mkv)&' down_ftp = '(ftp://).*?"' down_ftp2 ="(ftp://).*?<" url_ls =[] url = self.re_info(down_mag, str_text) url = url.replace('amp',"").strip("&") url_ls.append(url) urll = self.re_info(down_ftp, str_text) urll = urll.replace('"', "") url_ls.append(urll) urll = self.re_info(down_ftp2, str_text) urll = urll.replace('<', "") url_ls.append(urll) return url_ls def oper_index(self,new_url): """ return 标题和页面url 字典类型 :return: """ all_uri = self.get_page_text(new_url=new_url,header=self.heard,loc="ul").find_all("a") dict_index = {} for i in all_uri : if "class=" in str(i) : a,b = self.get_uri_title(str(i)) dict_index[f"{a}"]= b return dict_index def oper_data(self, new_url,yema_num,movie_lab='经典电影'): exls_name = "电影天堂-经典电影_爬取.xlsx" wb = load_workbook(exls_name) sheetnames = wb.get_sheet_names() table = wb.get_sheet_by_name(sheetnames[0]) table = wb.active table["A1"] = "id" table["B1"] = "movie_name" table["C1"] = "movie_type" table["D1"] = "download_link" table["E1"] = "movie_info" table["F1"] = "movie_label" page_u = [] dict_index = self.oper_index(new_url=new_url) # 获取当前页所有影片链接 u_l = [] # 获取 下载链接 for max_row1, row in enumerate(table): # excel 按序写入 if all(c.value is None for c in row): break for movie_name in dict_index.keys(): # 遍历当前页所有影片标题 url_fen = dict_index[movie_name] # 从字典获取影片链接 if url_fen in page_u: break page_u.append(url_fen) max_row = max_row1 with closing(requests.get(url_fen, headers=self.heard)) as res_one: # 单个影片页面 res_one.encoding = "gbk" one_soup = bs(res_one.text, "html.parser") # bs 对象 strr = str(pa_dytt.get_page_text(url_fen, header=pa_dytt.heard, loc='class="co_content8"', isindex=False)) fff=str() for i in strr.splitlines(): fff += str(i) strr = fff.replace("\n", "").replace("\r", "") movie_info = self.get_movie_info(strr) movie_type = self.get_movie_type(strr) res_one.close() for j in one_soup.findAll(bgcolor="#fdfddf"): # 获取下载链接, if len(self.get_downURL(str(j))) == 0: for jj in one_soup.find_all("u"): u_l.append(self.get_downURL(str(jj))) u_l.append(self.get_downURL(str(j))) # 格式化下载链接 u_l_str = str(u_l).replace('',"").replace("mkv]", "mkv").replace("mp4]", "mp4").replace("mkv']","mkv").replace( "mp4']", "mp4").replace("rmvb']", "rmvb") u_l_str = self.reparser_str(self.download_link_re, u_l_str) u_l_str= u_l_str.replace(">",",").replace("mkv]","mkv").replace('<tdbgcolor=#fdfddfstyle=WORD-WRAP:break-word>','').replace('">',',') u_l_str= self.re_sub_text(self.dl_down_link,u_l_str).replace('"',",").replace('<tdbgcolor=#fdfddfstyle=WORD-WRAP:break-word','').replace(',,',',').replace('<magnet:?','magnet:?').replace('.mp4]','.mp4') max_row += 1 # 写入xlsx table.cell(row=max_row, column=1).value = max_row - 1 table.cell(row=max_row, column=2).value = movie_name table.cell(row=max_row, column=3).value = movie_type table.cell(row=max_row, column=4).value = u_l_str table.cell(row=max_row, column=5).value = movie_info table.cell(row=max_row, column=6).value = movie_lab # 写入mysql do_mysql.in_movie_info(movie_name=movie_name, movie_type=movie_type, download_link=u_l_str, movie_info=movie_info,movie_lab=str(movie_lab)) u_l = [] wb.save(exls_name) self.logger.info(f"第{yema_num}页,写入完成。") # def oper_all_movie(self): """ 获取所有种类影片 :param new_url: :return: """ starttime = datetime.datetime.now() urii = 'https://www.dy2018.com/{}/index_{}.html' for ks in self.movie_label.keys(): # 从影片类别 字典key值 获取 路径 # for ks in range(0, 1): movie_lab = self.movie_label[ks] # 影片标签 urlll = "https://www.dy2018.com/{}/index.html".format(ks) # 获取类别下最大页码 textz = (self.get_page_text(urlll, header=self.heard, loc='class="co_content8"', isindex=False)) dd_soup = textz.findAll("select") for sele in dd_soup: lsls = (str(sele).split("</option><option")) # 最大页码为页码标签列表的长度len u_l = [] for jj in range(1,len(lsls)+1): # 通过最大页码,进行遍历该影片类别 # for jj in range(151, 152): if jj == 1: neww_url = 'https://www.dy2018.com/{}/index.html'.format(ks) else: neww_url = urii.format(ks, jj) all_uri = self.get_page_text(new_url=neww_url, header=self.heard, loc="ul").find_all("a") all_uri = str(all_uri).split(',') # find_all 文本处理为列表 try: for uuuuuu in all_uri: if 'class="ulink"' in uuuuuu and 'title="' in uuuuuu: # 筛选页面文本,提取区域内的影片信息 try: movie_title, movie_url = self.get_uri_title(uuuuuu) movie_name = self.re_sub_text(self.titlt_re, movie_title) with closing(requests.get(movie_url, headers=self.heard)) as res_one: # 单个影片页面 res_one.encoding = "gbk" one_soup = bs(res_one.text, "html.parser") # bs 对象 strr = str( self.get_page_text(movie_url, header=self.heard, loc='class="co_content8"', isindex=False)) fff = str() for i in strr.splitlines(): fff += str(i) strr = fff.replace("\n", "").replace("\r", "") movie_info = self.get_movie_info(strr) movie_type = self.get_movie_type(strr) res_one.close() for j in one_soup.findAll(bgcolor="#fdfddf"): # 获取下载链接, if len(self.get_downURL(str(j))) == 0: for jj in one_soup.find_all("u"): u_l.append(self.get_downURL(str(jj))) u_l.append(self.get_downURL(str(j))) # 格式化下载链接 u_l_str = str(u_l).replace('', "").replace("mkv]", "mkv").replace("mp4]", "mp4").replace( "mkv']", "mkv").replace("mp4']", "mp4").replace("rmvb']", "rmvb") u_l_str = self.reparser_str(self.download_link_re, u_l_str) u_l_str = u_l_str.replace(">", ",").replace("mkv]", "mkv").replace( '<tdbgcolor=#fdfddfstyle=WORD-WRAP:break-word>', '').replace('">', ',') u_l_str = self.re_sub_text(self.dl_down_link, u_l_str).replace('"', ",").replace( '<tdbgcolor=#fdfddfstyle=WORD-WRAP:break-word', '').replace(',,', ',').\ replace('<magnet:?','magnet:?').replace('.mp4]','.mp4') self.logger.info(f"{movie_name}下载链接为:{u_l_str}") # # 写入mysql do_mysql.in_movie_info(movie_name=movie_name, movie_type=movie_type, download_link=u_l_str, movie_info=movie_info,movie_lab=str(movie_lab)) u_l = [] except TypeError: continue except Exception as e: print(e) endtime = datetime.datetime.now() pa_dytt.logger.info(f"全部种类影片 爬取完成。耗时:{endtime - starttime}") def oper_jingdian_movie(self): """ 爬取经典模块的影片 :return: """ starttime = datetime.datetime.now() url = "https://www.dy2018.com/html/gndy/jddyy/index{}.html" # 循环拼接链接地址 for nn in range(1, 43): # 经典影片模块共42页 url_new_nn = url.format(f"_{nn}") if url_new_nn == "https://www.dy2018.com/html/gndy/jddyy/index_1.html": url_new_nn = "https://www.dy2018.com/html/gndy/jddyy/index.html" else: url_new_nn = url_new_nn self.oper_data(new_url=url_new_nn,yema_num=nn, movie_lab="经典大片") # ,sheet_name="Sheet1" endtime = datetime.datetime.now() self.logger.info(f"经典影片1000部 爬取完成。耗时:{endtime - starttime}") pa_dytt = GetDYTT() if __name__ == '__main__': pa_dytt.oper_jingdian_movie() pa_dytt.oper_all_movie()
对于关键字的提取使用了较长的正则表达式,没有优化,写得可能会有点冗余
写得代码是mysql+xlsx双向写入的,但是xlsx写入好像不太稳定,爬取经典系列电影的片段中保留了这部分的代码,
在全类别影片抓取中取消了xlsx相关的代码
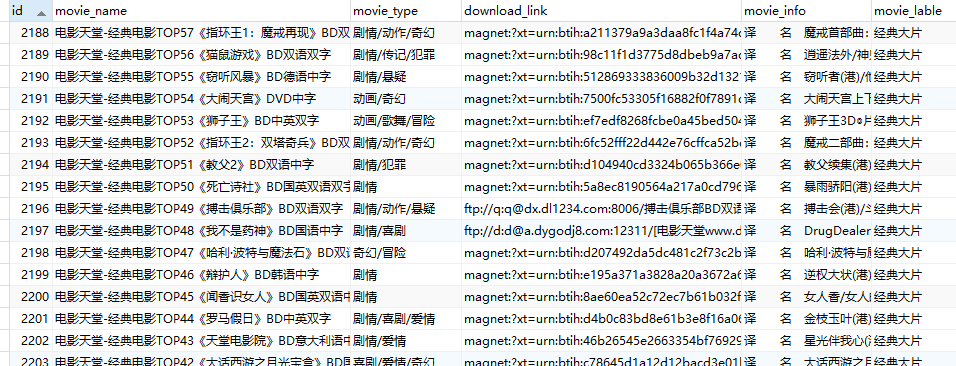
贴上数据库的截图和sql:
CREATE TABLE `getting_movie_info`.`movie_info` ( `id` int(8) NOT NULL AUTO_INCREMENT, `movie_name` varchar(255) CHARACTER SET utf8 NOT NULL COMMENT '影片名称', `movie_type` varchar(50) CHARACTER SET utf8 NULL COMMENT '影片种类', `download_link` varchar(1024) CHARACTER SET utf8 NULL COMMENT '下载地址', `movie_info` varchar(1024) CHARACTER SET utf8 NULL COMMENT '影片信息', `movie_lable` varchar(255) CHARACTER SET utf8 NULL COMMENT '影片标签', PRIMARY KEY (`id`) );
创建完执行下面的sql,防止插入的字段过长:
SET @@global.sql_mode='';

 浙公网安备 33010602011771号
浙公网安备 33010602011771号