
再看Scrapy(1) 基本概念
再看Scrapy(1) 基本概念
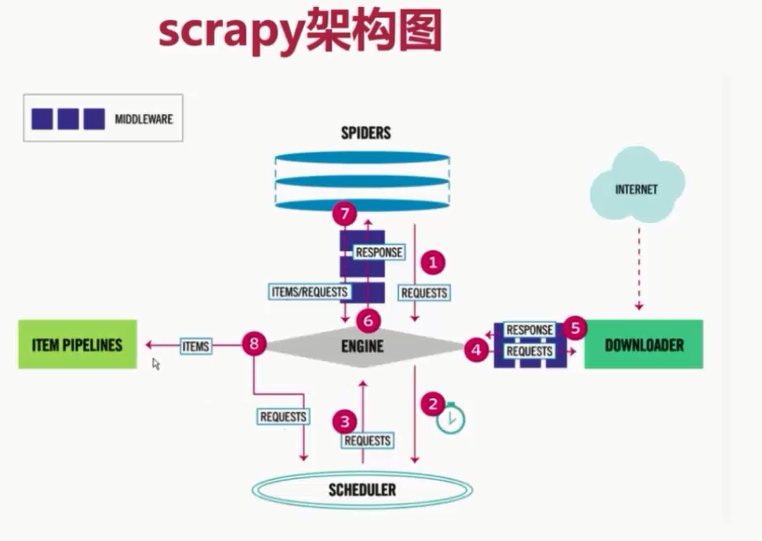
1 准备
安装scrapy:
国内镜像源(官方的pypi不稳定)安装
pip3 install -i https://pypi.douban.com/simple/ scrapy
安装virtualenvwrapper:
下载
pip3 install virtualenvwrapper
创建目录存放虚拟环境
mkdir ~/.virtualenvs
配置环境变量
export WORKON_HOME=~/.virtualenvs
source /usr/local/python3/bin/virtualenvwrapper.sh
source ~/.bashrc
2 技术选择与实现(scrapy vs reqeust + beautifulsoup)
不是一个层级的使用
requests + beautifulsoup 是库
scrapy 是框架
性能
在网络请求方面:
scrapy 基于twisted实现,具有高性能优势 --- 异步IO ;
在数据处理方面:
scrapy方便扩展,很多内置功能;内置 css,xpath选择器selector非常方便;lxml是c写的 所以更快
而beautifulsoup 是 python写的,会慢一点
3 爬虫的应用
1 .搜索引擎 --- 百度,goole(所有互联网的信息) ,垂直领域的搜索引擎(汽车,娱乐信息)
2 推荐引擎 --- 今日头条,数据推送
3 机器学习的样本
4 数据分析 ---金融,舆情分析
4 网页分类
静态网页 --- 类似静态博客系统,没有数据库操作
动态网页 --- 淘宝,信息更新(动态加载)
webservice(restapi) ajax + rest api
5 爬虫的常用策略
网站的 url 连接一般是 树形的结构(分层结构,不同的路由),而且网站的url 可能是环路,需要去重
(1)深度优先算法 和 实现 (scrapy默认使用)
递归实现
def depth_tree(tree_node):
if tree_node is not None:
if tree_node._left is not None:
return depth_tree(tree_node._left)
if tree_node._right is not None:
return depth_tree(tree_node._right)
递归层数太多---会有栈溢出的问题
(2)广度优先算法 和 实现
队列实现
def level_queue(root):
if root is None:
return
my_queue = []
node =root
my_queue.append(node)
while my_queue:
node = my_queue.pop(0)
if node.lchild is not None:
my_queue.append(node.lchild)
if node.rchild is not None:
my_queue.append(node.rchild)
读书使人心眼明亮

 浙公网安备 33010602011771号
浙公网安备 33010602011771号