个人项目:论文查重
| 作业所属课程 | https://edu.cnblogs.com/campus/gdgy/Networkengineering1834 |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/gdgy/Networkengineering1834/homework/11146 |
| 这个作业的目标 | 学习计算文本相似度的算法、学会使用Jprofiler性能分析、学会使用SonarLint发现并消除警告、掌握PSP表格的使用 |
一、github仓库地址
commit记录
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 40 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 240 | 360 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 90 |
| · Design Spec | · 生成设计文档 | 5 | 5 |
| · Design Review | · 设计复审 | 30 | 50 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 35 |
| · Design | · 具体设计 | 30 | 30 |
| · Coding | · 具体编码 | 180 | 300 |
| · Code Review | · 代码复审 | 60 | 100 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 90 |
| Reporting | 报告 | 50 | 80 |
| · Test Repor | · 测试报告 | 30 | 40 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 50 |
| · 合计 | 825 | 1290 |
三、算法设计
3.1余弦定理
3.1.1 原理
3.1.2 算法流程
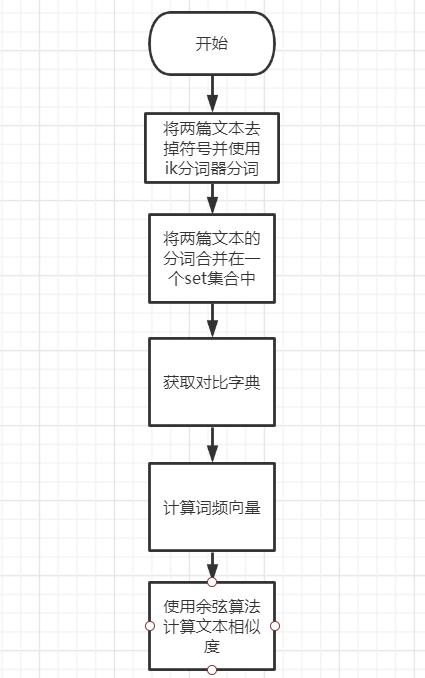
3.1.3 例子分析:
原始对比句子:
句子A:这只皮靴号码大了。那只号码合适。
句子B:这只皮靴号码不小,那只更合适。
步骤一:
使用ik分词器,将其放入两个集合中:
listA=[‘这‘, ‘只‘, ‘皮靴‘, ‘号码‘, ‘大‘, ‘了‘, ‘那‘, ‘只‘, ‘号码‘, ‘合适‘]
listB=[‘这‘, ‘只‘, ‘皮靴‘, ‘号码‘, ‘不小‘, ‘那‘, ‘只‘, ‘更合‘, ‘合适‘]
步骤二:
列出所有词,将listA和listB放在一个set中,得到:
set={'不小', '了', '合适', '那', '只', '皮靴', '更合', '号码', '这', '大'}
将上述set转换为map,key为set中的词,value为set中词出现的位置,以阿拉伯数字的形式递增。
map={'不小': 0, '了': 1, '合适': 2, '那': 3, '只': 4, '皮靴': 5, '更合': 6, '号码': 7, '这': 8, '大': 9},可以看出“不小”这个词在set中排第1,下标为0。
步骤三:
将listA和listB进行编码,将每个字转换为出现在set中的位置,转换后为:
listAcode=[8, 4, 5, 7, 9, 1, 3, 4, 7, 2]
listBcode=[8, 4, 5, 7, 0, 3, 4, 6, 2]
ps说明:我们可以看到,listAcode,结合dict1,可以看到8对应的字是“这”,4对应的字是“只”,9对应的字是“大”,就是句子A和句子B转换为用数字来表示。
步骤四:
对listAcode和listBcode进行oneHot编码,就是计算每个分词出现的次数,将listAcodeOneHot 和listBcodeOneHot作为余弦算法的两个向量,得到的结果如下:
listAcodeOneHot = [0, 1, 1, 1, 2, 1, 0, 2, 1, 1]
listBcodeOneHot = [1, 0, 1, 1, 2, 1, 1, 1, 1, 0]
步骤五:
使用listAcodeOneHot 和listBcodeOneHot 这两个向量用余弦算法计算相似度。
3.2 LCS算法原理
3.2.1 算法思想:
假设存在序列A长度为M, 序列B长度为N,生成大小为(M+1)*(N+1)的矩阵dp, 初始元素全部为0
(1)Ax代表字符串A的前i个字符组成的序列,By代表字符串B的前j个字符组成的序列
(2)Ax[i]代表字符串A的第i个字符,i>0;By[j]代表字符串B的第j个字符,j>0;
(3)dp[i][j] 代表序列Ax与序列By的最长公共子序列的长度
解法如下:
(1)如果Ax[i] = By[j],由于最长公共子序列为非连续序列,那么Ax和By的最长公共子序列LCS的最后一个元素即为当前元素,
所以: dp[i][j]=dp[i-1][j-1]+1,即历史最长公共子序列的长度加1
(2)如果Ax[i] != By[j],那么dp[i][j]的值存在两种情况:
情况一:可能是dp[i-1][j]的值,这代表字符串A的前i-1个元素与字符串B的前j个元素的最长公共子序列长度
情况二:可能是dp[i][j-1]的值,这代表字符串A的前i个元素与字符串B的前j-1个元素的最长公共子序列长度
两者取之间最大的值,即为当前dp[i][j]的值,即当前最长公共子序列的长度。
(3)至此,重复上述计算方式直到矩阵dp最后一个值,即为字符串A与字符串B的最长公共子序列值。
3.2.2 例子分析
假设存在序列A = [A,B,C,B,D,A,B],序列B = [B,D,C,A,B,A],动态规划法求最长公共子序列可以用下图表示:
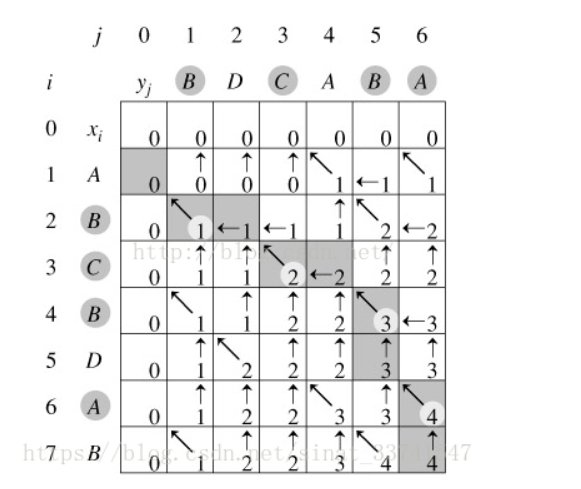
(1)设当前矩阵初始值均为0,由于i,j均大于0,忽略矩阵的第0行,及第0列
(2)从第i行,第1列开始计算,此时By[1] = B,
当i=1时,Ax[1] = A,两者不相等,取dp[i-1][j]与dp[i][j-1]两者之间最大的值,可知此时为0,
当i=2时,Ax[2] = B,两者相等,取dp[i-1][j-1]+1,可知此时应为0+1=1
当i=3时,以此类推
(3)重复上述步骤,最终得到最长子序列长度为4
3.3 余弦算法和lcs的算法分析:
由于余弦算法对于较长的文本会有比较大的误差,因此引入lcs算法,所以应当综合两种算法的优缺点,才能更加准确的计算出结果。
四、接口的设计以及实现过程。
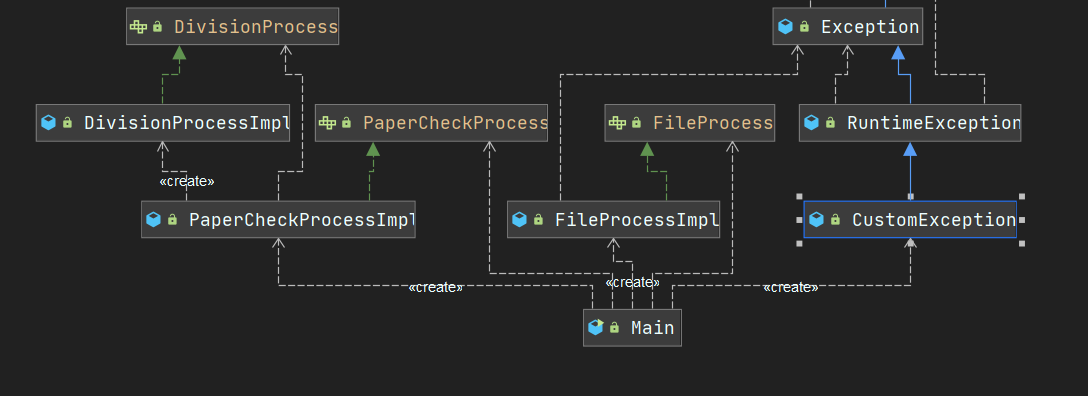
4.1 项目结构体系:
说明:service层为接口层,serviceImpl为实现层。
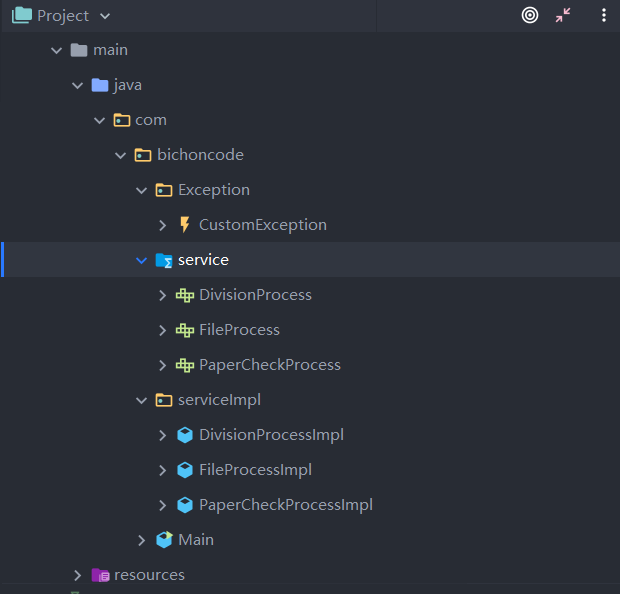
4.2 接口设计
4.2.1 分词接口DivisionProcess

4.2.2 文件接口FileProcess
(1)文件读取接口
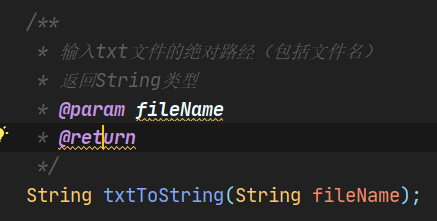
(2)文件写入接口
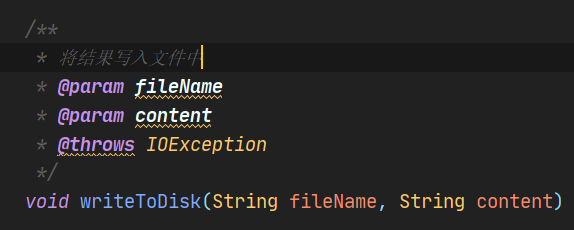
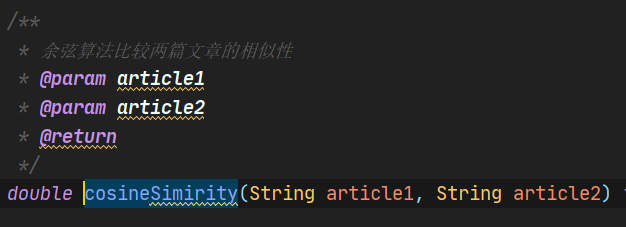
4.3 算法接口PaperCheckProcess
4.3.1 余弦算法
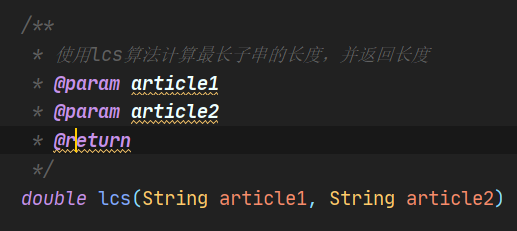
4.3.2 lcs算法
4.3.3 综合余弦算法和lcs算法
4.4 类之间的调用关系(UML图)
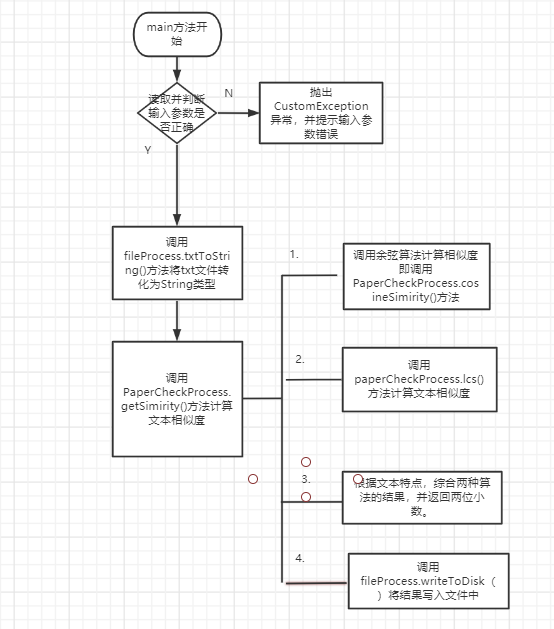
4.5 main方法的具体调用流程:
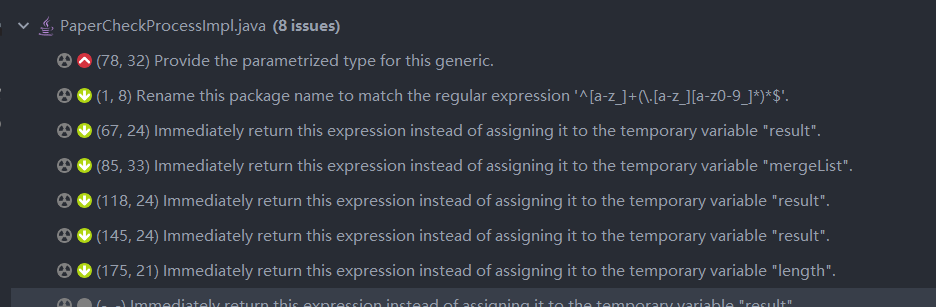
五、接口性能分析及其改进
5.1 使用SonarLint发现警告并消除
消除警告前:
消除警告后:
5.2 内存使用情况
5.3 cpu加载情况
5.4 垃圾回收行为

5.5 实例化的object的情况
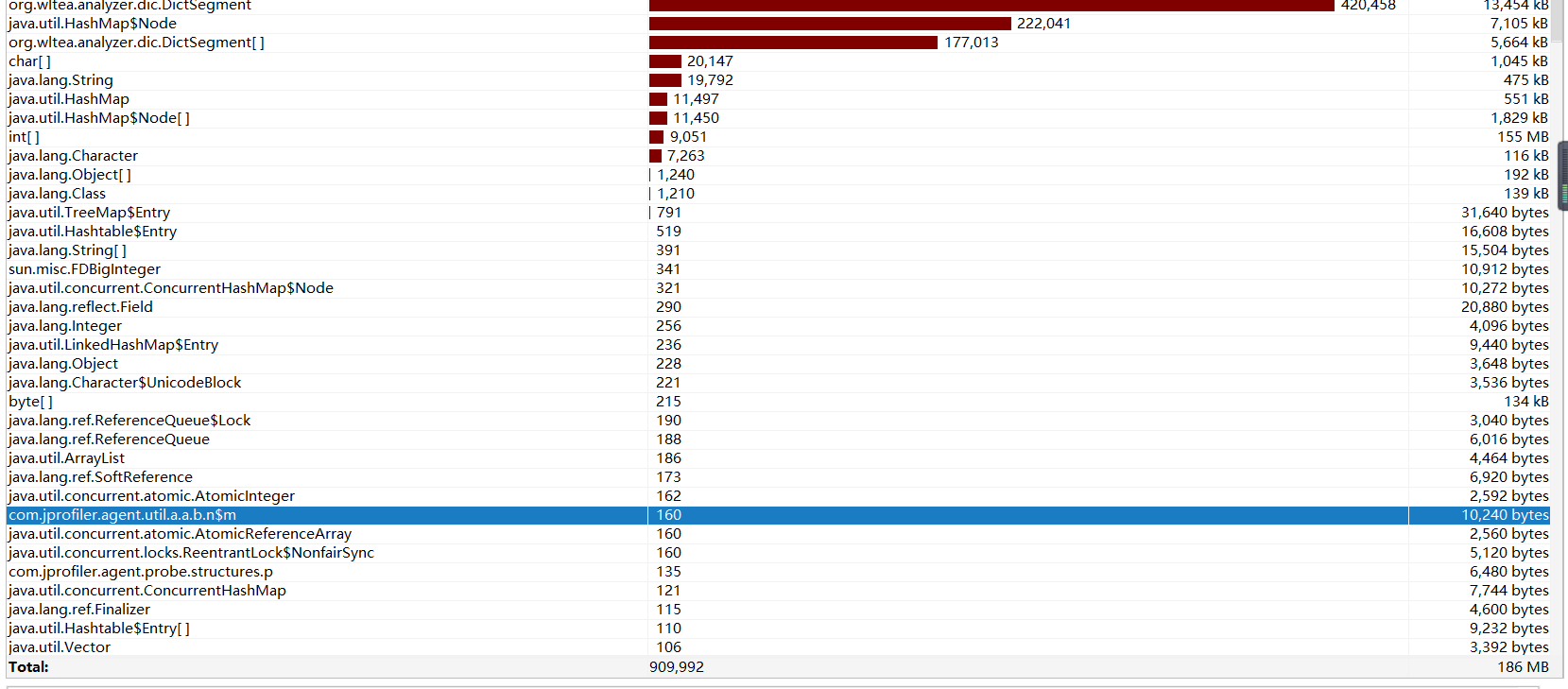
分析:占用内存最大的三个类分别是DictSegment、HashMap$Node和DictSegment[]数组,而这几个对象均是分词中最重要的对象,因此这里很难在优化了。
5.6 方法内存占用情况
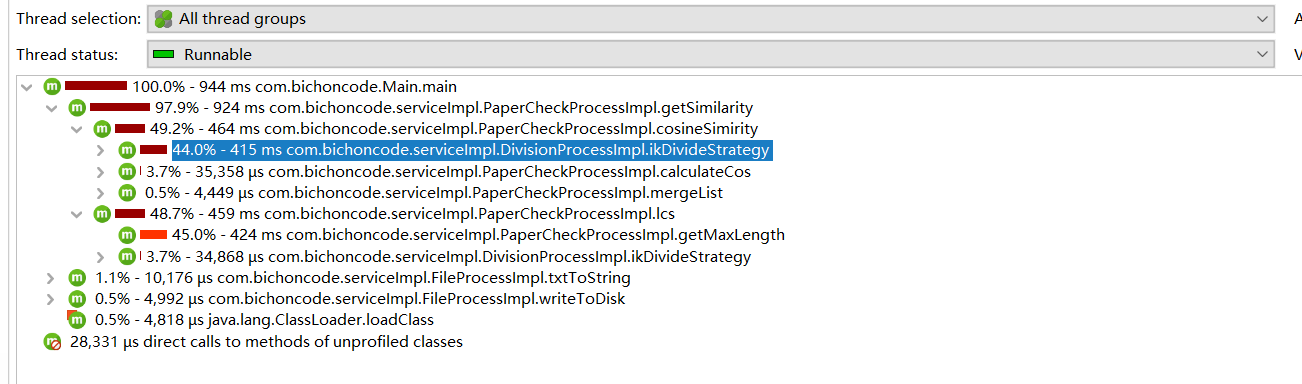
分析:从中可以看出,占用内存最大的方法是getMaxLength方法,这个方法的功能是算出两个字符串的最大子序列的长度,由于本身此方法就是采用了动态规划的思想,运用空间换取时间来提高效率,因而也无法再继续优化了。
六、 单元测试
6.1 单元测试框架:Junit5
6.2 单元测试结果(仅展示部分)
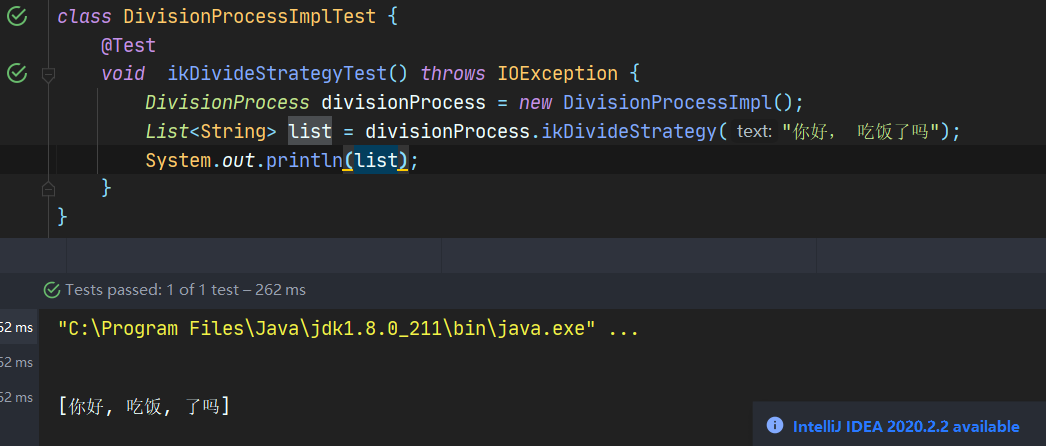
6.2.1 分词测试
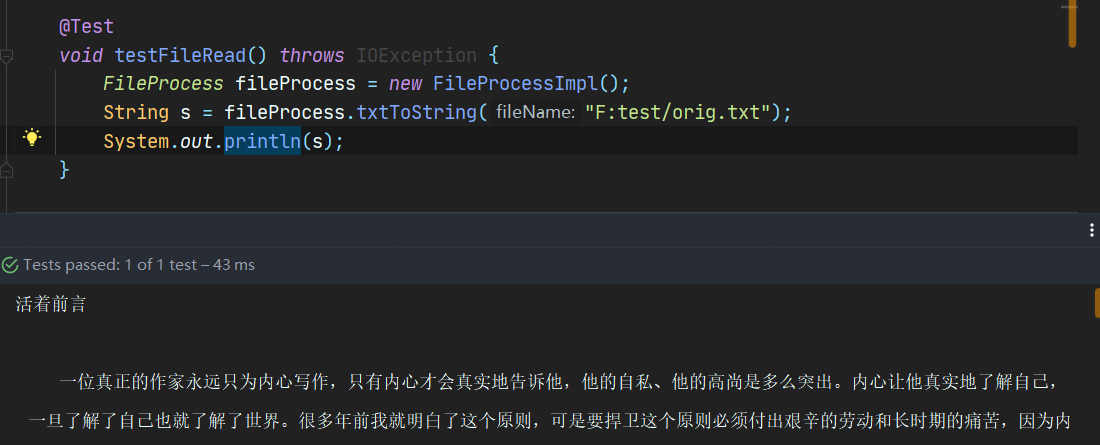
6.2.2 文件读取测试
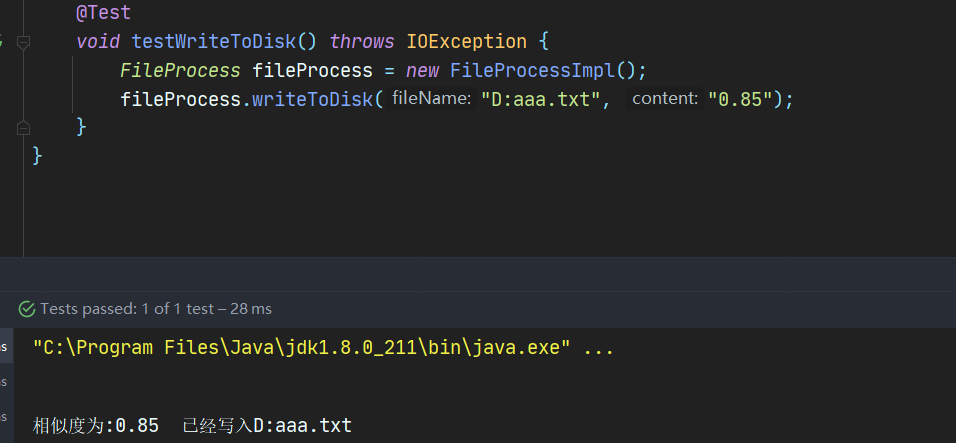
6.2.3 文件写入测试
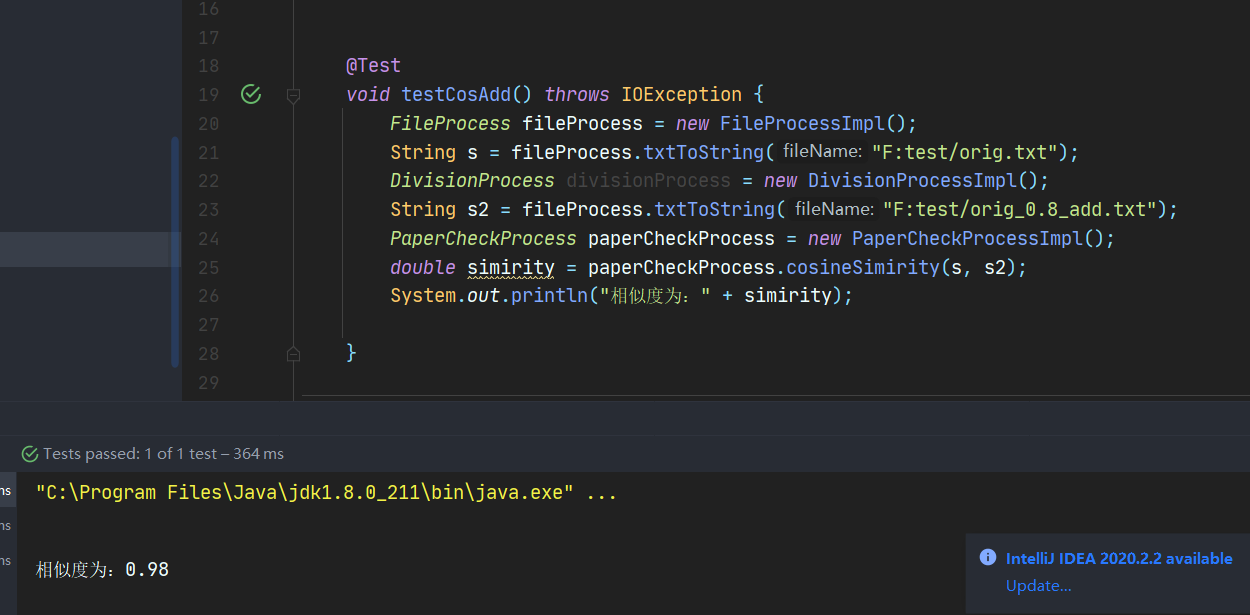
6.2.4 余弦算法测试origin_add.txt
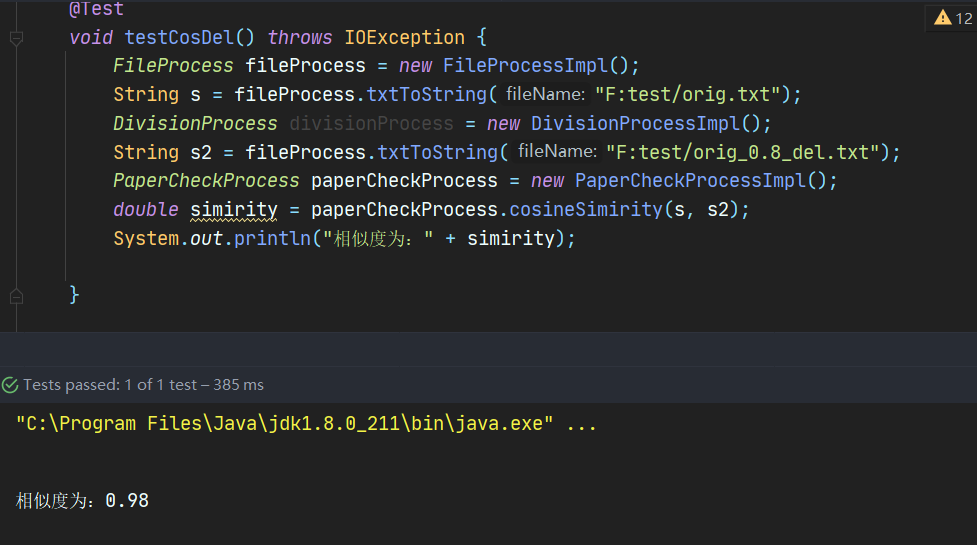
6.2.5 余弦算法测试orig_del_0.8.txt
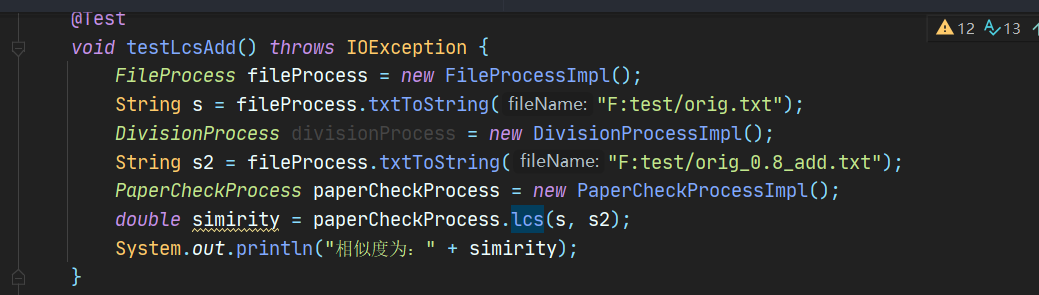
6.2.6 lcs算法测试orig_add.txt
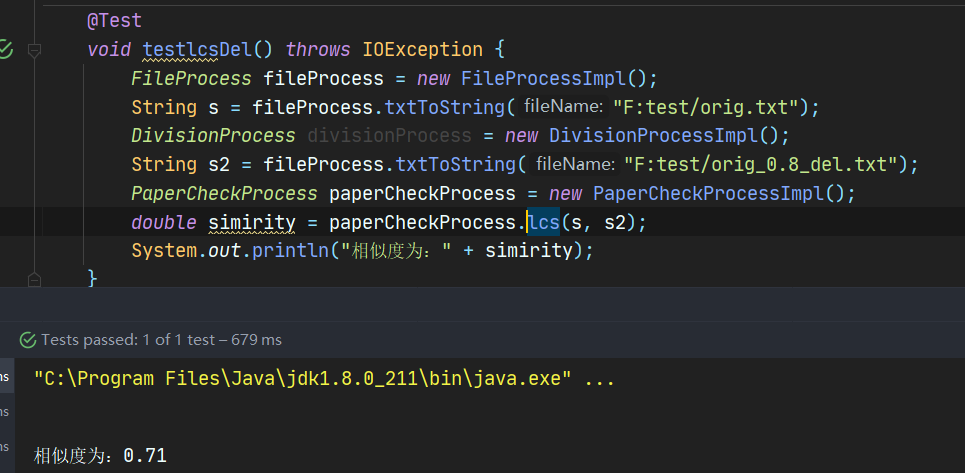
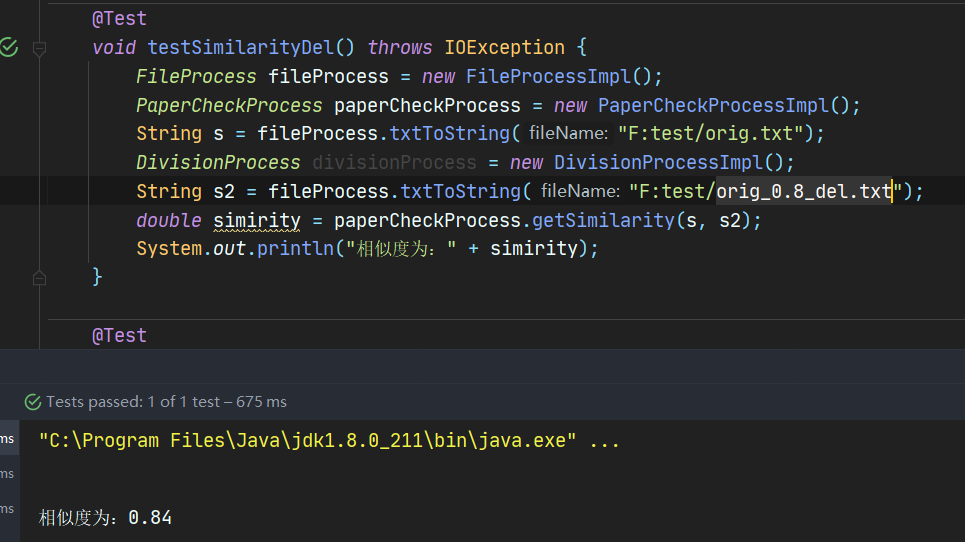
6.2.7 lcs算法测试orig_0.8_del.txt
6.2.8 lcs算法测试orig_0.8_dis_1.txt
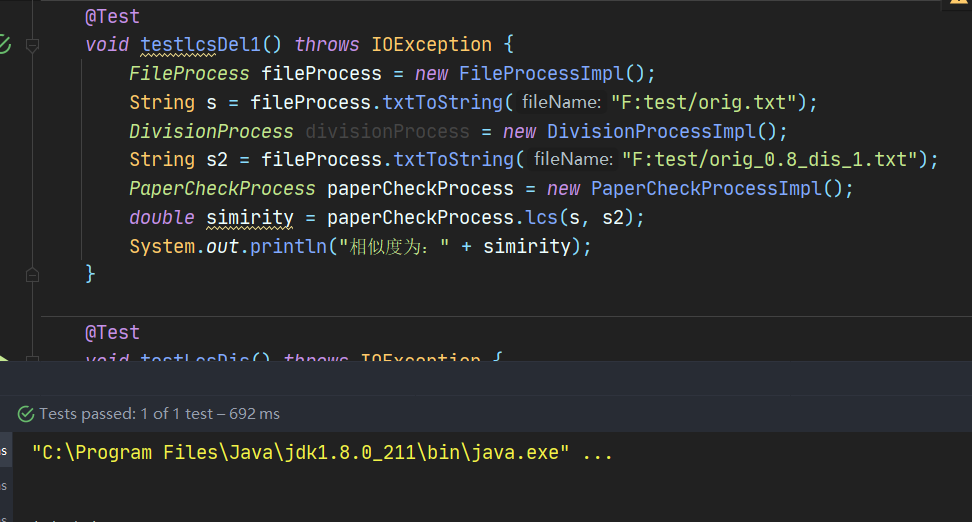
6.2.9 综合算法测试orig_0.8_add.txt
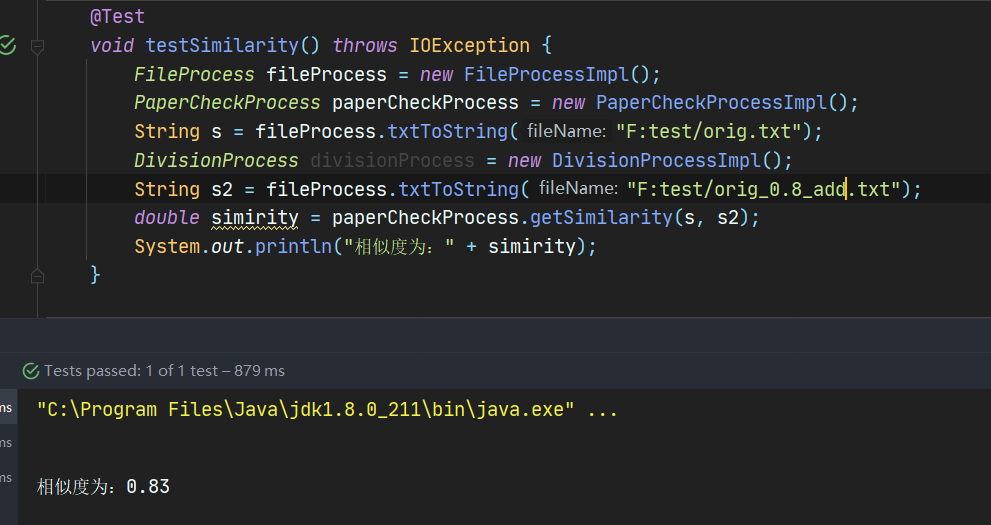
6.2.10 综合算法测试orig_0.8_del.txt
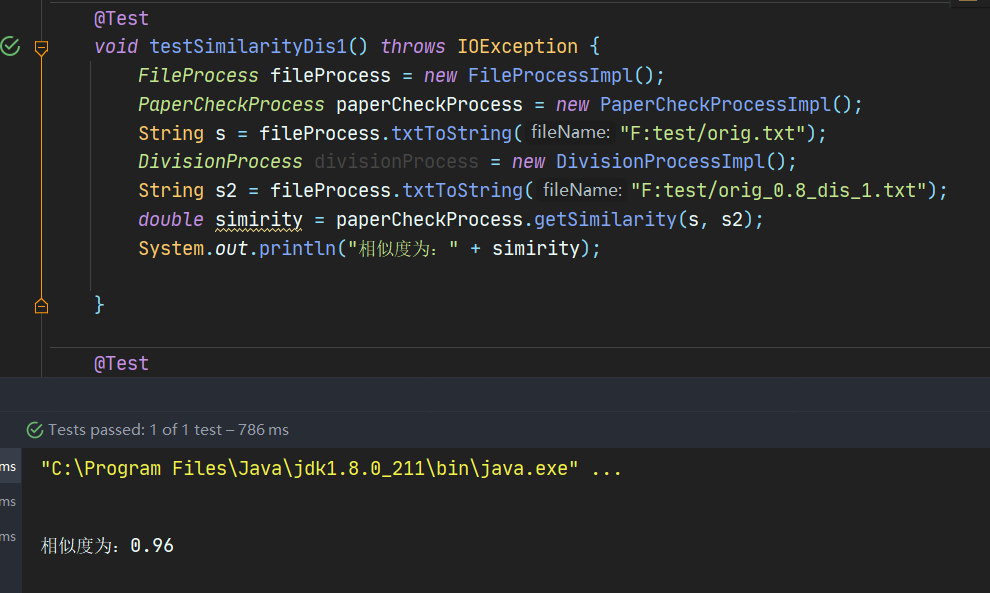
6.2.11 综合算法测试orig_0.8_dis_1.txt
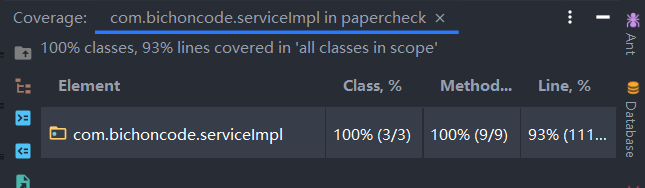
6.2.12 代码覆盖率
七、异常定义及其处理
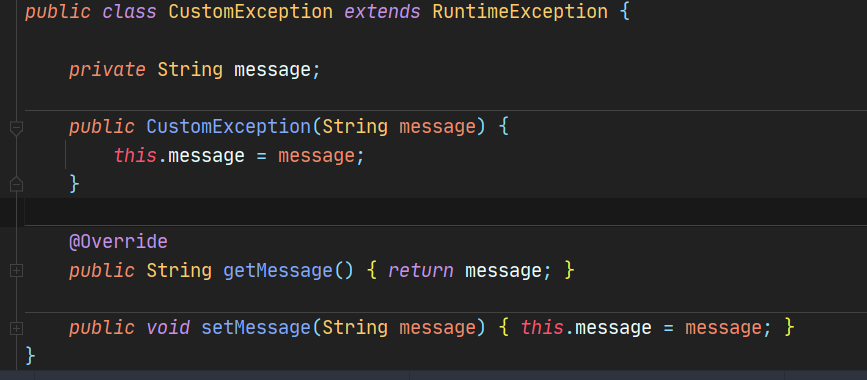
7.1 定义通用异常类CustomException
7.2 IO异常捕获示例

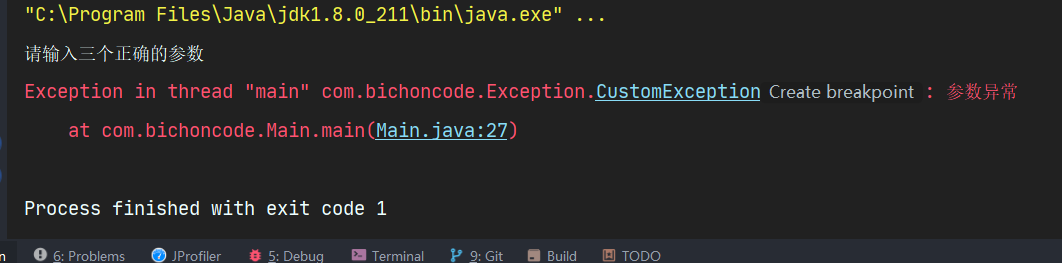
7.3 异常测试
八、jar包运行测试

说明:由于txt文件默认是UTF-8编码,而windouws环境下的cmd窗口默认是GBK编码,
因此如果直接运行jar包会出现乱码问题,出现乱码就会导致分词不准确,进而导致结果不准确,
所以在cmd窗口运行jar包时需要告诉java虚拟机使用utf-8格式的编码,
即采用java -jar -Dfile.encoding=utf-8 xxxx.jar的方式运行jar包。
九、 总结:
1.不同的算法计算出的结果是不一样的,需要根据文本的实际情况选择合适的算法。
2.同一种算法计算出的结果也不一定相同,还与分词的方式有很大的关系,因此,需要选择合适的分词方式,本项目采用ik分词的方式,将文本按照关键字进行分词,准确率较高。
3.本项目只考虑了余弦和lcs两种算法,但是实际上只有这两种算法也是远远不够的,因此以后仍需继续学习其他计算文本相似度的算法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号