
DataNode引用计数磁盘选择策略
前言
在HDFS中,所有的数据都是存在各个DataNode上的.而这些DataNode上的数据都是存放于节点机器上的各个目录中的,而一般每个目录我们会对应到1个独立的盘,以便我们把机器的存储空间基本用上.这么多的节点,这么多块盘,HDFS在进行写操作时如何进行有效的磁盘选择呢,选择不当必然造成写性能下降,从而影响集群整体的性能.本文来讨论一下目前HDFS中存在的几个磁盘选择策略的特点和不足,然后针对其不足,自定义1个新的磁盘选择策略.
HDFS现有磁盘选择策略
上文前言中提到,随着节点数的扩增,磁盘数也会跟着线性变化,这么的磁盘,会造成1个问题,数据不均衡现象,这个是最容易发生的.原因可能有下面2个:
1.HDFS写操作不当导致.
2.新老机器上线使用时间不同,造成新机器数据少,老机器数据多的问题.
第二点这个通过Balancer操作可以解决.第一个问题才是最根本的,为了解决磁盘数据空间不均衡的现象,HDFS目前的2套磁盘选择策略都是围绕着"数据均衡"的目标设计的.下面介绍这2个磁盘选择策略.
一.RoundRobinVolumeChoosingPolicy
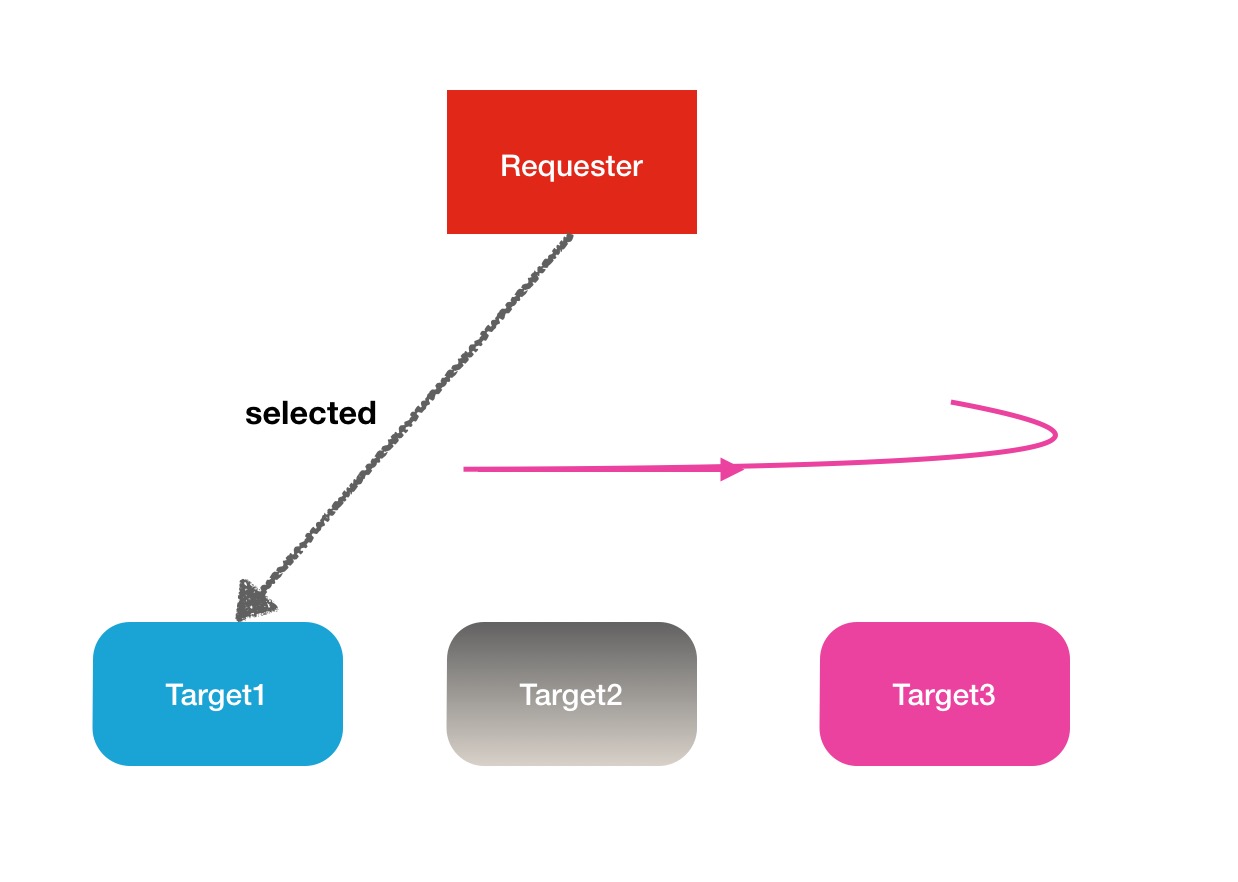
上面这个比较长的类名称可以拆成2个单词,RoundRobin和VolumeChoosingPolicy,VolumeChoosingPolicy理解为磁盘选择策略,RoundRobin这个是一个专业术语,叫做"轮询",类似的还有一些别的类似的术语,Round-Robin Scheduling(轮询调度),Round-Robin 算法等.RoundRobin轮询的意思用最简单的方式翻译就是一个一个的去遍历,到尾巴了,再从头开始.下面是一张解释图:
下面给出在HDFS中他的核心代码如下,我加了注释上去,帮助大家理解:
/**
* Choose volumes in round-robin order.
*/
public class RoundRobinVolumeChoosingPolicy<V extends FsVolumeSpi>
implements VolumeChoosingPolicy<V> {
public static final Log LOG = LogFactory.getLog(RoundRobinVolumeChoosingPolicy.class);
private int curVolume = 0;
@Override
public synchronized V chooseVolume(final List<V> volumes, long blockSize)
throws IOException {
//如果磁盘数目小于1个,则抛异常
if(volumes.size() < 1) {
throw new DiskOutOfSpaceException("No more available volumes");
}
//如果由于失败磁盘导致当前磁盘下标越界了,则将下标置为0
// since volumes could've been removed because of the failure
// make sure we are not out of bounds
if(curVolume >= volumes.size()) {
curVolume = 0;
}
//赋值开始下标
int startVolume = curVolume;
long maxAvailable = 0;
while (true) {
//获取当前所下标所代表的磁盘
final V volume = volumes.get(curVolume);
//下标递增
curVolume = (curVolume + 1) % volumes.size();
//获取当前选中磁盘的可用剩余空间
long availableVolumeSize = volume.getAvailable();
//如果可用空间满足所需要的副本块大小,则直接返回这块盘
if (availableVolumeSize > blockSize) {
return volume;
}
//更新最大可用空间值
if (availableVolumeSize > maxAvailable) {
maxAvailable = availableVolumeSize;
}
//如果当前指标又回到了起始下标位置,说明已经遍历完整个磁盘列
//没有找到符合可用空间要求的磁盘
if (curVolume == startVolume) {
throw new DiskOutOfSpaceException("Out of space: "
+ "The volume with the most available space (=" + maxAvailable
+ " B) is less than the block size (=" + blockSize + " B).");
}
}
}
}理论上来说这种策略是蛮符合数据均衡的目标的,因为一个个的写吗,每块盘写入的次数都差不多,不存在哪块盘多写少写的现象,但是唯一的不足之处在于每次写入的数据量是无法控制的,可能我某次操作在A盘上写入了512字节的数据,在轮到B盘写的时候我写了128M的数据,数据就不均衡了,所以说轮询策略在某种程度上来说是理论上均衡但还不是最好的.更好的是下面这种.
二.AvailableSpaceVolumeChoosingPolicy
剩余可用空间磁盘选择策略.这个磁盘选择策略比第一种设计的就精妙很多了,首选他根据1个阈值,将所有的磁盘分为了2大类,高可用空间磁盘列表和低可用空间磁盘列表.然后通过1个随机数概率,会比较高概率下选择高剩余磁盘列表中的块,然后对这些磁盘列表进行轮询策略的选择,下面是相关代码:
/**
* A DN volume choosing policy which takes into account the amount of free
* space on each of the available volumes when considering where to assign a
* new replica allocation. By default this policy prefers assigning replicas to
* those volumes with more available free space, so as to over time balance the
* available space of all the volumes within a DN.
*/
public class AvailableSpaceVolumeChoosingPolicy<V extends FsVolumeSpi>
implements VolumeChoosingPolicy<V>, Configurable {
...
//用于一般的需要平衡磁盘的轮询磁盘选择策略
private final VolumeChoosingPolicy<V> roundRobinPolicyBalanced =
new RoundRobinVolumeChoosingPolicy<V>();
//用于可用空间高的磁盘的轮询磁盘选择策略
private final VolumeChoosingPolicy<V> roundRobinPolicyHighAvailable =
new RoundRobinVolumeChoosingPolicy<V>();
//用于可用空间低的剩余磁盘的轮询磁盘选择策略
private final VolumeChoosingPolicy<V> roundRobinPolicyLowAvailable =
new RoundRobinVolumeChoosingPolicy<V>();
@Override
public synchronized V chooseVolume(List<V> volumes,
long replicaSize) throws IOException {
if (volumes.size() < 1) {
throw new DiskOutOfSpaceException("No more available volumes");
}
//获取所有磁盘包装列表对象
AvailableSpaceVolumeList volumesWithSpaces =
new AvailableSpaceVolumeList(volumes);
//如果所有的磁盘在数据平衡阈值之内,则在所有的磁盘块中直接进行轮询选择
if (volumesWithSpaces.areAllVolumesWithinFreeSpaceThreshold()) {
// If they're actually not too far out of whack, fall back on pure round
// robin.
V volume = roundRobinPolicyBalanced.chooseVolume(volumes, replicaSize);
if (LOG.isDebugEnabled()) {
LOG.debug("All volumes are within the configured free space balance " +
"threshold. Selecting " + volume + " for write of block size " +
replicaSize);
}
return volume;
} else {
V volume = null;
// If none of the volumes with low free space have enough space for the
// replica, always try to choose a volume with a lot of free space.
//如果存在数据不均衡的现象,则从低剩余空间磁盘块中选出可用空间最大值
long mostAvailableAmongLowVolumes = volumesWithSpaces
.getMostAvailableSpaceAmongVolumesWithLowAvailableSpace();
//得到高可用空间磁盘列表
List<V> highAvailableVolumes = extractVolumesFromPairs(
volumesWithSpaces.getVolumesWithHighAvailableSpace());
//得到低可用空间磁盘列表
List<V> lowAvailableVolumes = extractVolumesFromPairs(
volumesWithSpaces.getVolumesWithLowAvailableSpace());
float preferencePercentScaler =
(highAvailableVolumes.size() * balancedPreferencePercent) +
(lowAvailableVolumes.size() * (1 - balancedPreferencePercent));
//计算平衡比值,balancedPreferencePercent越大,highAvailableVolumes.size()所占的值会变大
//整个比例值也会变大,就会有更高的随机概率在这个值下
float scaledPreferencePercent =
(highAvailableVolumes.size() * balancedPreferencePercent) /
preferencePercentScaler;
//如果低可用空间磁盘列表中最大的可用空间无法满足副本大小
//或随机概率小于比例值,就在高可用空间磁盘中进行轮询调度选择
if (mostAvailableAmongLowVolumes < replicaSize ||
random.nextFloat() < scaledPreferencePercent) {
volume = roundRobinPolicyHighAvailable.chooseVolume(
highAvailableVolumes, replicaSize);
if (LOG.isDebugEnabled()) {
LOG.debug("Volumes are imbalanced. Selecting " + volume +
" from high available space volumes for write of block size "
+ replicaSize);
}
} else {
//否则在低磁盘空间列表中选择磁盘
volume = roundRobinPolicyLowAvailable.chooseVolume(
lowAvailableVolumes, replicaSize);
if (LOG.isDebugEnabled()) {
LOG.debug("Volumes are imbalanced. Selecting " + volume +
" from low available space volumes for write of block size "
+ replicaSize);
}
}
return volume;
}
}低剩余空间磁盘和高剩余空间磁盘的标准是这样定义的:
/**
* @return the list of volumes with relatively low available space.
*/
public List<AvailableSpaceVolumePair> getVolumesWithLowAvailableSpace() {
long leastAvailable = getLeastAvailableSpace();
List<AvailableSpaceVolumePair> ret = new ArrayList<AvailableSpaceVolumePair>();
for (AvailableSpaceVolumePair volume : volumes) {
//可用空间小于最小空间与平衡空间阈值的和的磁盘加入低磁盘空间列表
if (volume.getAvailable() <= leastAvailable + balancedSpaceThreshold) {
ret.add(volume);
}
}
return ret;
}
/**
* @return the list of volumes with a lot of available space.
*/
public List<AvailableSpaceVolumePair> getVolumesWithHighAvailableSpace() {
long leastAvailable = getLeastAvailableSpace();
List<AvailableSpaceVolumePair> ret = new ArrayList<AvailableSpaceVolumePair>();
for (AvailableSpaceVolumePair volume : volumes) {
//高剩余空间磁盘选择条件与上面相反
if (volume.getAvailable() > leastAvailable + balancedSpaceThreshold) {
ret.add(volume);
}
}
return ret;
}现有HDFS磁盘选择策略的不足
OK,我们已经了解了HDFS目前存在的2种磁盘选择策略,我们看看HDFS在使用这些策略的是不是就是完美的呢,答案显然不是,下面是我总结出的2点不足之处.
1.HDFS的默认磁盘选择策略是RoundRobinVolumeChoosingPolicy,而不是更优的AvailableSpaceVolumeChoosingPolicy,我猜测的原因估计是AvailableSpaceVolumeChoosingPolicy是后来才有的,但是默认值的选择没有改,依然是老的策略.
2.磁盘选择策略考虑的因素过于单一,磁盘可用空间只是其中1个因素,其实还有别的指标比如这个块目前的IO情况,如果正在执行许多读写操作的时候,我们当然希望找没有进行任何操作的磁盘进行数据写入,否则只会更加影响当前磁盘的写入速度,这个维度也是下面我自定义的新的磁盘选择策略的1个根本需求点.
自定义磁盘选择策略之ReferenceCountVolumeChoosingPolicy
新的磁盘选择策略的根本依赖点在于ReferenceCount,引用计数,他能让你了解有多少对象正在操作你,引用计数在很多地方都有用到,比如jvm中通过引用计数,判断是否进行垃圾回收.在磁盘相关类FsVolume中也有类似的1个变量,刚好可以满足我们的需求,如下:
/**
* The underlying volume used to store replica.
*
* It uses the {@link FsDatasetImpl} object for synchronization.
*/
@InterfaceAudience.Private
@VisibleForTesting
public class FsVolumeImpl implements FsVolumeSpi {
...
private CloseableReferenceCount reference = new CloseableReferenceCount(); @Override
public int getReferenceCount() {
return this.reference.getReferenceCount();
}@Override
public synchronized V chooseVolume(final List<V> volumes, long blockSize)
throws IOException {
if (volumes.size() < 1) {
throw new DiskOutOfSpaceException("No more available volumes");
}
V volume = null;
//获取当前磁盘中被引用次数最少的1块盘
int minReferenceCount = getMinReferenceCountOfVolumes(volumes);
//根据最少引用次数以及引用计数临界值得到低引用计数磁盘列表
List<V> lowReferencesVolumes =
getLowReferencesCountVolume(volumes, minReferenceCount);
//根据最少引用次数以及引用计数临界值得到高引用计数磁盘列表
List<V> highReferencesVolumes =
getHighReferencesCountVolume(volumes, minReferenceCount);
//判断低引用磁盘列表中是否存在满足要求块大小的磁盘,如果有优选从低磁盘中进行轮询磁盘的选择
if (isExistVolumeHasFreeSpaceForBlock(lowReferencesVolumes, blockSize)) {
volume =
roundRobinPolicyLowReferences.chooseVolume(lowReferencesVolumes,
blockSize);
} else {
//如果低磁盘块中没有可用空间的块,则再从高引用计数的磁盘列表中进行磁盘的选择
volume =
roundRobinPolicyHighReferences.chooseVolume(highReferencesVolumes,
blockSize);
}
return volume;
}@Test
public void testReferenceCountVolumeChoosingPolicy() throws Exception {
@SuppressWarnings("unchecked")
final ReferenceCountVolumeChoosingPolicy<FsVolumeSpi> policy =
ReflectionUtils.newInstance(ReferenceCountVolumeChoosingPolicy.class,
null);
initPolicy(policy);
final List<FsVolumeSpi> volumes = new ArrayList<FsVolumeSpi>();
// Add two low references count volumes.
// First volume, with 1 reference.
volumes.add(Mockito.mock(FsVolumeSpi.class));
Mockito.when(volumes.get(0).getReferenceCount()).thenReturn(1);
Mockito.when(volumes.get(0).getAvailable()).thenReturn(100L);
// First volume, with 2 references.
volumes.add(Mockito.mock(FsVolumeSpi.class));
Mockito.when(volumes.get(1).getReferenceCount()).thenReturn(2);
Mockito.when(volumes.get(1).getAvailable()).thenReturn(100L);
// Add two high references count volumes.
// First volume, with 4 references.
volumes.add(Mockito.mock(FsVolumeSpi.class));
Mockito.when(volumes.get(2).getReferenceCount()).thenReturn(4);
Mockito.when(volumes.get(2).getAvailable()).thenReturn(100L);
// First volume, with 5 references.
volumes.add(Mockito.mock(FsVolumeSpi.class));
Mockito.when(volumes.get(3).getReferenceCount()).thenReturn(5);
Mockito.when(volumes.get(3).getAvailable()).thenReturn(100L);
// initPolicy(policy, 1.0f);
Assert.assertEquals(volumes.get(0), policy.chooseVolume(volumes, 50));
volumes.clear();
// Test when the low-references volumes has not enough available space for
// block
// First volume, with 1 reference.
volumes.add(Mockito.mock(FsVolumeSpi.class));
Mockito.when(volumes.get(0).getReferenceCount()).thenReturn(1);
Mockito.when(volumes.get(0).getAvailable()).thenReturn(50L);
// First volume, with 2 references.
volumes.add(Mockito.mock(FsVolumeSpi.class));
Mockito.when(volumes.get(1).getReferenceCount()).thenReturn(2);
Mockito.when(volumes.get(1).getAvailable()).thenReturn(50L);
// Add two high references count volumes.
// First volume, with 4 references.
volumes.add(Mockito.mock(FsVolumeSpi.class));
Mockito.when(volumes.get(2).getReferenceCount()).thenReturn(4);
Mockito.when(volumes.get(2).getAvailable()).thenReturn(200L);
// First volume, with 5 references.
volumes.add(Mockito.mock(FsVolumeSpi.class));
Mockito.when(volumes.get(3).getReferenceCount()).thenReturn(5);
Mockito.when(volumes.get(3).getAvailable()).thenReturn(200L);
Assert.assertEquals(volumes.get(2), policy.chooseVolume(volumes, 100));
}我在代码注释中已经进行了很详细的分析了,这里就不多说了.
总结
当然根据引用计数的磁盘选择策略也不见得是最好的,因为这里忽略了磁盘间数据不均衡的问题,显然这个弊端会慢慢凸显出来,所以说你很难做到1个策略是绝对完美的,可能最好的办法是根据用户使用场景使用最合适的磁盘选择策略,或者定期更换策略以此达到最佳的效果.引用计数磁盘选择策略的相关代码可以从我的github patch链接中查阅,学习.
相关链接
参考文献:Round-Robin 百度百科
github patch链接:https://github.com/linyiqun/open-source-patch/blob/master/hdfs/others/HDFS-volumeChoosingPolicy/HDFS-001.patch

 浙公网安备 33010602011771号
浙公网安备 33010602011771号