
Write-Ahead Log(WAL)的工作原理
前言
在存储系统的运行过程中,每时每刻都发生着数据的更新,背后意味着诸如创建,删除,修改文件等数据的操作。抛开物理文件数据的改变,对于中心控制节点而言,这些都会涉及到元数据的更新操作。而为了保持系统元数据和物理数据间的状态一致性,系统所有的数据操作对应的元数据变更都需要持久化到元数据db内,但其实这里有一个性能问题,我们的每次变更如果都要实时同步到外部db内,是否意味着高频的io操作?是否有延时写入的手段呢?本文将要阐述的预写式日志Write Ahead Log(WAL),正是对此的优化。
Write Ahead Log概述
Write Ahead Log简称WAL,在分布式存储系统中的元数据更新中应用得十分广泛。WAL的主要意思是说在将元数据的变更操作写入到持久稳定的db之前,先预先写入到一个log中,然后再由另外的操作将log apply到外部的持久db里去。这种模式会减少掉每次的db写入操作,尤其当系统要处理大量的transaction操作的时候,WAL的方式相比较于实时同步db的方式有着更高的效率。
WAL还有一点很重要的帮助是可以在disaster recovery过程中起到状态恢复的作用,系统在load完元数据db后,再把未来得及提交的WAL apply进来,就能恢复成和之前最终一致的状态。
WAL的执行机理
上面只介绍了WAL的概述内容,本小节我们来深入了解WAL的内部执行细节。
首先我们要搞清楚一点的是,WAL不记录元数据的本身,而是变更的record。那么何为”变更的record“?一个删除操作记录,一个添加记录,至于每个记录会包含有什么信息呢,大家可以参考audit log的内容属性。不过WAL的log格式和audit log还是有所区别的。
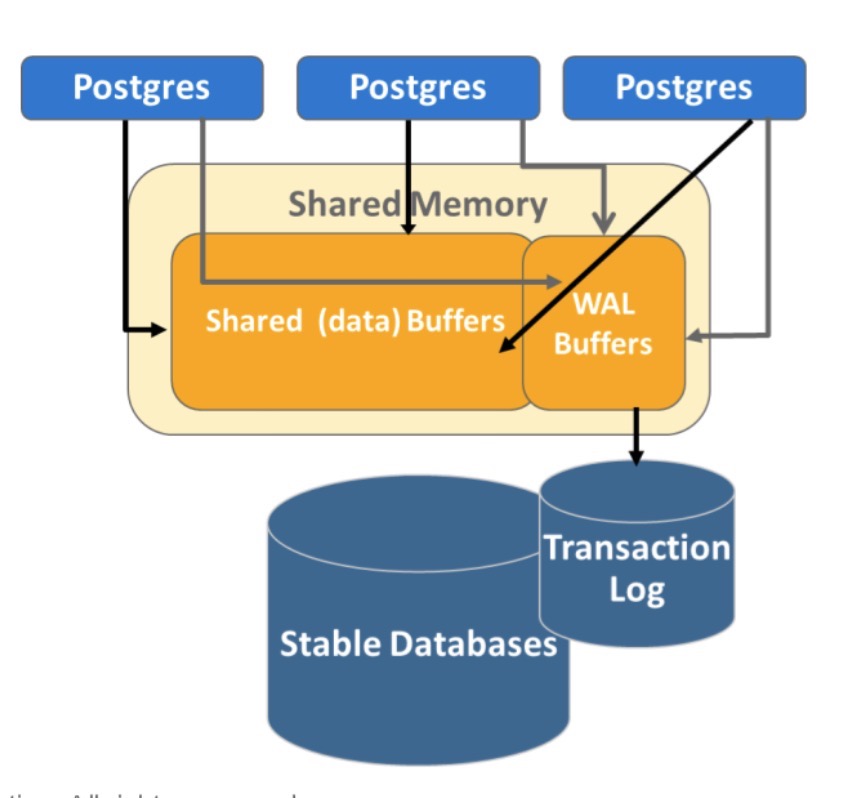
追本溯源,对于WAL来说,它是被谁写入的呢?答案是WAL buffer,当这个buffer满了的时候或者人工触发flush动作时,它就会将transaction数据写出到WAL的log内。当然,系统在每次完成一个操作时,同时会将改动应用到memory和WAL buffer内,然后自己再控制buffer flush出去的逻辑。
当老的WAL已经被apply进元数据db之后,我们会用更新commitId来表明当前最新的transaction,理论上来说低于这个commitId的WAL已经可以被清除purge出去了。这个过程我们可以理解为checkpoint过程,当前db+WAL变更=新的db。
上述WAL细节过程如下图:
HDFS的WAL原理应用
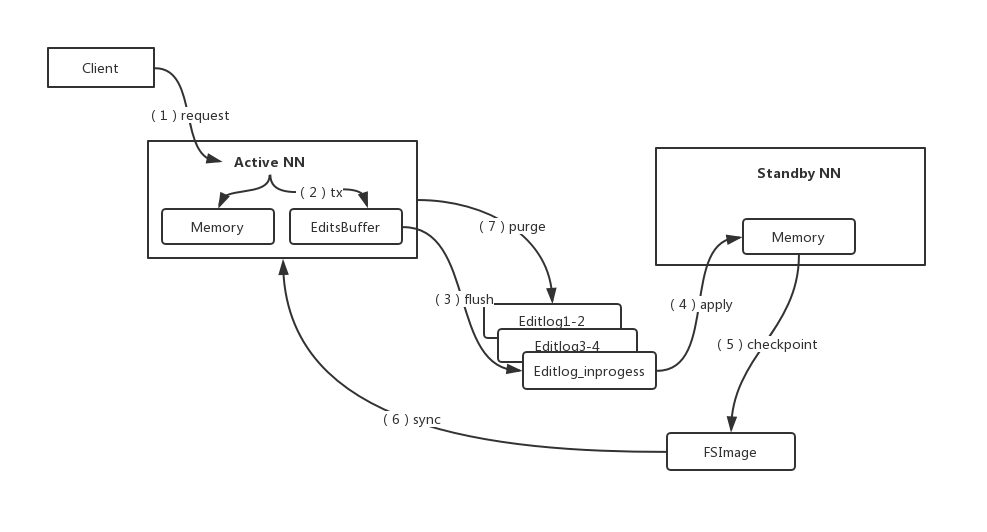
HDFS作为一个成熟的分布式系统,在其内部也有WAL模型的应用。这里的WAL则是Editlog,而对应的Stable DB则是Standby NN的fsimage。HDFS的Editlog用了双缓冲模式来加大transaction的throughput。整个过程的数据流操作是从Active NN到Editlog到Standby NN。当Standby NN准实时的读取完editlog的信息后,定期checkpoint出新的fsimage文件后,再sync到Active NN上。按照时间顺序和commit tx id,老的editlog会被purge掉。HDFS的WAL模型如下图所示(步骤如线条中数字显示):
WAL apply的控制
在系统做disaster recovery中,对于WAL的应用过程,有时可能会出现应用出差的情况,包括一些局部WAL记录格式写异常的情况。这个时候用户可以选择是否中断WAL的apply过程或者是忽略异常,来完成尽可能的数据状态恢复。这些都是WAL内部的细节控制。
以上就是本文主要阐述的关于WAL的内容了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号