对线面试官系列:搞懂MySQL 回表机制,看这一篇就够了!
@
前言
请各大网友尊重本人原创知识分享,谨记本人博客:南国以南i、微信公众号:白码梦想家
提示:以下是本篇文章正文内容,下面案例可供参考
背景
Hello 朋友们,接下来为大家开启,面试题相关系列☞《对线面试官》
自信出击,让 offer 手到擒来!!!
基础知识
- 聚簇索引: 聚簇索引的
叶子节点存储的是整行数据,且数据的物理存储顺序与聚簇索引的顺序一致。- 非聚簇索引: 非聚簇索引的
叶子节点存储的是索引列的值和对应行的主键值,而不是整行数据。
聚族索引与非聚族索引区别:
叶节点是否存放一整行记录,
一个表中除了主键id字段是聚族索引,其它字段都是非聚族索引
回表定义
回表(Look-up)指的是在MySQL中, 在使用非聚集索引进行查询时,才会涉及回表问题 。MySQL首先通过非聚簇索引找到对应的主键值,后利用这个主键值在聚簇索引中定位到具体的行,并获取所需的其他列数据。
简单来说,回表是一种二次查找的操作,用于获取非聚集索引无法提供的其他列的值。
经典示例:
假设有一个名为users的表,其中包含三列:id(主键,聚簇索引)、name(非聚簇索引)和age。如果执行查询SELECT * FROM users WHERE name = 'Alice';,则MySQL会首先通过name列的非聚簇索引找到所有name为'Alice'的记录的主键值,然后利用这些主键值在id列的聚簇索引中查找并返回整行数据。
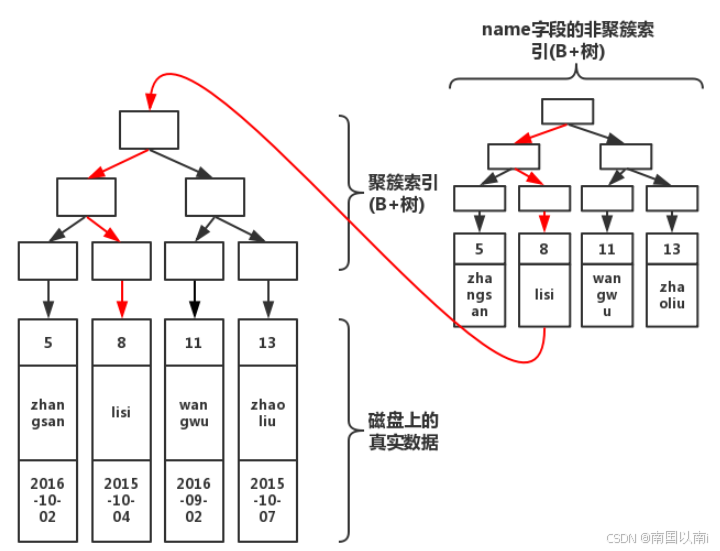
由图可知流程,首先从非聚簇索引开始寻找聚簇索引,找到非聚簇索引上的聚簇索引后,就会到聚簇索引的B+树上进行查询,通过聚簇索引B+树找到完整的数据。该过程比较专业的叫法也被称为
“回表”。
回表的影响
回表操作会增加查询的成本,因为它需要额外的I/O操作来访问聚簇索引并获取整行数据。特别是在数据量较大的情况下,回表操作可能会对查询性能产生显著影响。
如何避免回表?
如果无法避免回表操作,可以通过以下方法进行优化:
1. 使用覆盖索引
定义:覆盖索引(Covering Index)的方式。覆盖索引是指创建一个包含了查询所需的所有列的索引,这样就可以直接从索引中获取所需的数据,而无需回到表中查找。使用覆盖索引可以减少I/O操作和提高查询性能。
做法: 在创建索引时,确保索引包含了查询中需要的所有列。这样,MySQL可以直接从索引中获取所需的数据,而无需回表。
注意: 覆盖索引(Covering Index)和索引覆盖(Index Covering)实际上是同一概念的不同表述方式,它们指的是同一个优化技术。因此,从本质上来说,覆盖索引和索引覆盖没有区别。
应用场景:
- 当查询的列是索引的一部分时,如果这些列足以满足查询需求,就可以使用覆盖索引。
- 在进行分页查询时,如果查询条件已经包含在索引中,并且只需要获取索引中的部分列数据,就可以使用覆盖索引来提高查询效率。
- 在进行统计查询时,如果统计信息可以通过索引直接计算得出,也可以使用覆盖索引来减少数据访问量。
示例:
CREATE INDEX idx_name_age ON table_name(name, age);
SELECT name, age FROM table_name WHERE name = 'Alice';
2. 使用聚簇索引
定义: 聚簇索引是一种特殊的索引,它将数据和索引存储在一起。在InnoDB存储引擎中,主键索引就是聚簇索引。
做法: 确保查询中频繁使用的列是主键或包含在聚簇索引中。这样,当通过这些列进行查询时,可以直接从聚簇索引中获取数据,无需回表。
注意: 每个表只能有一个聚簇索引,因为数据只能有一种物理存储顺序。
3. 优化查询条件
做法:尽量避免在查询条件中使用不在索引列中的列,因为这会导致回表查询。优化查询条件,使之尽可能使用索引列。
示例:
-- 优化前(假设没有针对customer_name的索引)
SELECT * FROM customers WHERE customer_name = 'John Doe';
-- 优化后(添加索引)
ALTER TABLE customers ADD INDEX (customer_name);
SELECT * FROM customers WHERE customer_name = 'John Doe';
4. 减少SELECT *的使用
做法: 尽量避免使用SELECT *,只查询需要的列。这样可以减少数据传输量,提高查询效率,并在某些情况下避免回表。
示例:
-- 优化前
SELECT * FROM table_name WHERE id = 1;
-- 优化后
SELECT id, name FROM table_name WHERE id = 1;
5. 使用联合索引
定义: 联合索引是将多个列组合成一个索引。
做法: 将查询中经常一起出现的列组合成联合索引。这样,当这些列一起出现在查询条件中时,可以减少回表次数。
示例:
CREATE INDEX idx_name_age ON table_name(name, age);
SELECT * FROM table_name WHERE name = 'Alice' AND age = 20;
6. 使用子查询或临时表
做法: 将需要查询的数据先存储在临时表或子查询中,然后再进行关联查询。这样可以减少回表次数,特别是当关联查询涉及多个表时。
7. 定期优化和重建索引
做法: 随着数据的更新和增长,索引可能会变得不再紧凑,影响查询性能。定期优化和重建索引可以保持索引性能。
8. EXPLAIN分析查询计划
做法: 通过EXPLAIN语句分析查询计划,了解查询是如何执行的,从而找到优化的方法,减少回表查询的次数。
9.调整表结构
做法: 如果回表操作非常频繁,可以考虑调整表结构,将需要查询的列放在索引中,或者使用聚簇索引来减少回表操作。
10. 使用缓存
做法: 如果查询的数据具有一定的重复性,可以考虑使用缓存来减少回表操作。
通过以上方法,可以有效地避免MySQL中的回表操作,提高查询性能和数据库的整体性能。
回表总结
回表是MySQL数据库中一种常见的操作,用于获取非聚集索引无法提供的其他列的值。回表操作会增加额外的I/O操作和访问时间,影响查询的性能。为了避免回表操作,可以使用覆盖索引的方式。如果无法避免回表操作,可以通过优化查询语句、调整表结构和使用缓存等方式来优化回表操作。在实际应用中,需要根据具体的场景和需求来选择合适的优化策略。
我是南国以南i记录点滴每天成长一点点,学习是永无止境的!转载请附原文链接!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号