
Java基础复习计划
散碎知识点
-
Java 的方法签名
包括方法名和参数,不包括返回值,重载时需要注意。 -
一个 Java 文件中只允许有一个 public 类
-
java.lang包不用导,里面包含了常用的 Object、Package、System 以及各种基本数据类型的封装类。 -
JVM 中一个字节以下的整型数据会在 JVM 启动的时候加载进内存,除非用
new Integer()显式的创建对象,否则都是同一个对象。
String 类型也是类似,因为 String 是不可变的,所以也可以这么玩,看后面的示例代码。
字符串拼接的编译器优化,在 hotspot 中,例如编译 "tao" + "bao" 会直接变成 "taobao",使用变量 b+c 则不会进行优化,而是使用语法糖来处理,就是新建一个 sb(StringBuilder) 来处理。
这也是为了提高效率,避免占用过多的内存,当然并不是全部都这样,比如整形只会缓存一个字节,太多了反而会负优化,python 中也有这样的机制。
PS:从编译的角度去看
String s1 = "abc";
String s2 = "abc";
String s3 = new String("abc");
String s4 = "ab" + "c";
String s = "ab";
String s5 = s + "c";
System.out.println(s1 == s2); // true
System.out.println(s1 == s3); // false
System.out.println(s1 == s4); // true
System.out.println(s1 == s5); // false
-
==对于引用型变量表示的是两个变量在堆中存储的地址是否相同(包括 String)
PS:源码中String 的 toLowerCase 方法是重新 new String() 的。 -
重载是在同一个类中,有多个方法名相同,参数列表不同(参数个数不同,参数类型不同),与方法的返回值无关,与权限修饰符无关。
-
default 不能修饰变量
-
Java一律采用 Unicode 编码方式,每个字符无论中文还是英文字符都占用 2 个字节
-
thread.Join把指定的线程加入到当前线程,可以将两个交替执行的线程合并为顺序执行的线程。
比如在线程 B 中调用了线程 A 的 Join() 方法,直到线程 A 执行完毕后,才会继续执行线程 B。
t.join();使调用线程 t 在此之前执行完毕。
t.join(1000);等待 t 线程,等待时间是 1000 毫秒。 -
创建 Statement 是不传参的,PreparedStatement 是需要传入 sql 语句
静态内部类
静态的内部类相当于是外部类的静态成员,可以通过 外部类.内部静态类 来访问,比如进行定义对象以用来 new。
除非是内部类,否则类不能用 static 修饰.
先来定义几个内部类:
class Enclosingone {
// 非静态内部类
public class InsideOne {
public String name = "one";
}
// 静态内部类
public static class InsideTwo {
public String name = "two";
}
// 外部类可以访问内部类的私有变量
private class Inner {
private int inProp = 5;
}
public void accessInnerProp() {
System.out.println(new Inner().inProp);
}
}
测试类:
public class Main {
public static void main(String[] args) {
// 创建非静态内部类
Enclosingone.InsideOne one = new Enclosingone().new InsideOne();
// 创建静态内部类
Enclosingone.InsideTwo two = new Enclosingone.InsideTwo();
System.out.println(one.name + "::" + two.name);
new Enclosingone().accessInnerProp();
}
}
补充一点,内部类可分为四种:
- 成员内部类
成员内部类是最普通的内部类,它的定义为位于另一个类的内部。
成员内部类,就是作为外部类的成员,可以直接使用外部类的所有成员和方法,即使是 private 的。虽然成员内部类可以无条件地访问外部类的成员,而外部类想访问成员内部类的成员却不是这么随心所欲了。在外部类中如果要访问成员内部类的成员,必须先创建一个成员内部类的对象,再通过指向这个对象的引用来访问。
外部类访问形式:ClassName.this.name - 局部内部类
局部内部类是定义在一个方法或者一个作用域里面的类,它和成员内部类的区别在于局部内部类的访问仅限于方法内或者该作用域内。
简单说就是定义在方法里的类,要使用外部类方法中的变量(形参),此变量必须是 final 才行。 - 静态嵌套类
就是修饰为 static 的内部类。
声明为 static 的内部类,不需要内部类对象和外部类对象之间的联系,就是说我们可以直接引用outer.inner,即不需要创建外部类,也不需要创建内部类。
静态修饰的内部类就只能访问外部类的静态成员变量,具有局限性 - 匿名内部类
多数用来做回调,匿名内部类不能有访问修饰符和 static 修饰符的。
匿名内部类是唯一一种没有构造器的类。
Java 语言规范里只说了enclosing class 可以访问 inner class 的 private/protected 成员,inner class 也可以访问 enclosing class 的 private/protected 成员,但是没有规定死要如何实现这种访问。
几个参考链接:
http://www.cnblogs.com/hasse/p/5020519.html
https://www.cnblogs.com/chenssy/p/3388487.html
占位符
占位符一般来说用的很少,在 Java 中常用的有两种占位符 % 和 {},% 后面可以是 d、f、s 等,中间也可以加其他参数。
- % 只能用于 String 类对象中,不能用于 MessageFormat 类对象。
- {} 只能用于 MessageFormat 类对象中,不能用于 String 类对象;使用时,括号内的数字要与后面的参数位置对应。
总的来说 String.format() 方法用起来不如 MessageFormat.format() 方法强大。
常用的几种形式:
System.out.printf("%f %s", d, f);
String.format("我是%1$s,我来自%2$s,今年%3$s岁", "中国人", "北京","22")); // s 是字符串
// 或者使用 new Object[]{} 填充
MessageFormat.format("该网站{0}被访问了 {1} 次.", url, count));
类型转换
一幅图概况:
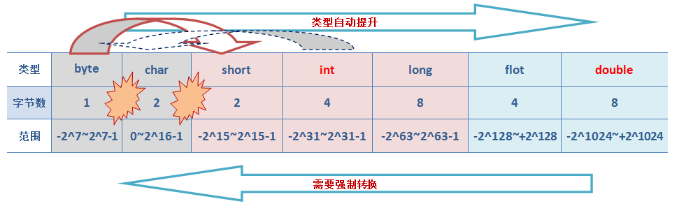
首先来看八种基本数据类型的大小情况:
| 数据类型 | 所占字节 |
|---|---|
| boolean | 未定 |
| byte | 1字节 |
| char | 2字节 |
| short | 2字节 |
| int | 4字节 |
| long | 8字节 |
| float | 4字节 |
| double | 8字节 |
顺便提一句,Java 中默认是使用 unicode 码表来存储的,所以 char 就是 2 个字节咯。
隐式转换就不多说了,低的自动转成高的,下面来看几个特别的问题:
// 编译错误
float f = 3.14;
// 编译正常
float f = 3.14F;
// 编译错误
int i = 2;
byte b = i + 3;
byte b2 = i;
// 编译正确
byte b = 12;
下面就来解释这些错误的原因:
首先,Java 中整数的默认数据类型是 int,小数的默认数据类型是 double。
所以第二行代码会报错,编译器认为会发生精度丢失;如果你指定输入的数是 float 类型,或者强制类型转换成 float 就不会报错了。
第六行开始的代码报错,以及最后一行编译正确的原因是:
b=i+3 会编译报错,因为 3 是 int 类型的,所以 i+1 运算完后也是 int,赋给 byte 就会明显的精度丢失,报错。
jvm 在编译过程中,对于默认为 int 类型的数值时,当赋给一个比 int 型数值范围小的数值类型变量(在此统一称为数值类型 k,k 可以是 byte/char/short 类型),会进行判断,如果此 int 型数值超过数值类型 k,那么会直接编译出错。
因为你将一个超过了范围的数值赋给类型为 k 的变量,k 装不下嘛,你有没有进行强制类型转换,当然报错了。
但是如果此 int 型数值尚在数值类型 k 范围内,jvm 会自定进行一次隐式类型转换,将此 int 型数值转换成类型 k。
与上面不同,byte b = 12; 执行时 JVM 会进行上面的检查,但是 byte b = i + 3; 时,JVM 已经进行了 i+3 的运算,类型已经明确为 int,这时不能再“隐式强转”了。
char 型其本身是 unsigned 型,同时具有两个字节,其数值范围是
0 ~ 2^16-1,这直接导致 byte 型不能自动类型提升到 char,char 和 short 直接也不会发生自动类型提升(因为负数的问题),同时,byte 当然可以直接提升到 short 型。
强转的优先级优先运算优先级;
TAG:隐式类型转换、显式类型转换(强制类型转换)
参考:https://www.cnblogs.com/liujinhong/p/6005714.html
精度丢失问题
经常拿来说事的例子:
举例:double result = 1.0 - 0.9;
这个结果不用说了吧,都知道结果是:0.09999999999999998。
就这是 java 和其它计算机语言都会出现的问题,出现这个问题的原因可以解释为:
float 和 double 类型主要是为了科学计算和工程计算而设计的。
他们执行二进制浮点运算,这是为了在广泛的数字范围上提供较为精确的快速近似计算而精心设计的。
然而,它们并没有提供完全精确的结果,所以我们不应该用于精确计算的场合。
float 和 double 类型尤其不适合用于货币运算,因为要让一个 float 或 double 精确的表示 0.1 或者 10 的任何其他负数次方值是不可能的
(其实道理很简单,十进制系统中能不能准确表示出 1/3 呢?同样二进制系统也无法准确表示 1/10)。
浮点运算很少是精确的,只要是超过精度能表示的范围就会产生误差。往往产生误差不是因为数的大小,而是因为数的精度。因此,产生的结果接近但不等于想要的结果。尤其在使用 float 和 double 作精确运算的时候要特别小心。
首先明确几个问题,计算机是如何把十进制整数如何转化为二进制数的:
# 以 11 为例(一直除以2取余)
11/2=5 余 1
5/2=2 余 1
2/2=1 余 0
1/2=0 余 1
0 结束
11 二进制表示为(从下往上):1011
所有的整数除以 2 一定能够最终得到 0。换句话说,所有的整数转变为二进制数的算法绝对不会无限循环下去,整数永远可以用二进制精确表示 ,但小数就不一定了。
那就来看看计算机是如何把十进制小数如何转化为二进制数:
# 算法是乘以2直到没有了小数为止。举个例子,0.9表示成二进制数
0.9*2=1.8 取整数部分 1
# 取 1.8 的小数部分
0.8*2=1.6 取整数部分 1
0.6*2=1.2 取整数部分 1
0.2*2=0.4 取整数部分 0
0.4*2=0.8 取整数部分 0
0.8*2=1.6 取整数部分 1
0.6*2=1.2 取整数部分 0
......... 0.9
二进制表示为(从上往下): 1100100100100......
上面的计算过程循环了,也就是说 *2 永远不可能消灭小数部分,这样算法将无限下去。很显然,小数的二进制表示有时是不可能精确的。
这也就解释了为什么浮点型减法出现了"减不尽"的精度丢失问题。
解决方案
下面就来看看解决方案:
方案一
如果不介意自己记录十进制的小数点,而且数值不大,那么可以使用 long ,int 等基本类型,具体用 int 还是 long 要看涉及的数值范围大小,缺点是要自己处理十进制小数点,最明显的做法就是处理货币使用分来计算,而不用元(只涉及加减)。
例子:
int resultInt = 10 - 9;
// 最终时候自己控制小数点
double result = (double) resultInt / 100;
或者这样来写:System.out.println(((1.0 * 100) - (0.9 * 100))/100);
方案二
使用 BigDecmal,而且需要在构造参数使用 String 类型.
在《Effective Java》这本书中就给出了一个解决方法。该书中也指出,float 和 double 只能用来做科学计算或者是工程计算,在商业计算等精确计算中,我们要用
java.math.BigDecimal
然后加减乘除运算是使用 BigDecmal 提供的方法来进行的,这样的结果是精确的。
例子:
double d = 1.0 - 0.9;
BigDecimal a = new BigDecimal("1.0");
BigDecimal b = new BigDecimal("0.9");
System.out.println(d);
System.out.println(a.subtract(b));
如果涉及到金钱的运算就使用 BigDecmal 就行了。
运算符
有些运算符我都快忘记了,那些不常用的,比如:&(与)、| (或 )、!(非)、~(取反)、^(异或)。
这些运算都是对于二进制来说的,一句话简单解释:
与运算中,1&1=1,1&0=0,0&0=0;
或运算中,1|1=1,1|0=1,0|0=0;
异或运算中,11=0,10=1,0^0=0;
非和取反就不说了,这俩简单。
然后再补充一些公式:
公式:
-n = ~n + 1,或者可以根据反码和补码来计算(~ 是进行取反操作)
负数的二进制计算:取绝对值,然后算出二进制,然后取反,再 +1一个数 %(n) 等同于这个数 &(n-1)
如果你想取一个数的低四位,那么可以与上 15(1111),这样就只会保留低四位了。
因为一个数连续异或另一个数两次不变,所以根据这个特性可以只用两个变量就可以交换两个数:
public void swap() {
int x = 1;
int y = 2;
x = x^y;
y = x^y;
x = x^y;
System.out.printf("x=%d, y=%d",x,y);
}
这个思路简直太 nice~了,拜膜 dalao
如果想了解补码、反码:http://blog.csdn.net/smilecall/article/details/42454471
补充:精度小于 int 的数值运算的时候都回被自动转换为 int 后进行计算。
就是说两个 short 相加最终结果其实是 int,但是 short 类型的进行 += 操作就没问题。
(+= 是 java 语言规定的运算符,java 编译器会对它进行特殊处理,因此可以正确编译)
补充点(关于自增)内容,看下面的代码:
int x = 1;
// 顺序:先左边,后右边,最后比较
// ++ 的优先级比 <> 高,<> 比 == 高
if (++x == x++) { // 成立
System.out.println(x);
System.out.println("yes");
}
System.out.println("-----------");
int y = 1;
y = ++y; // y=2
y = y++; // y=2
System.out.println(y);
// 打印
boolean a = false;
boolean b = true;
System.out.println(a = b); // true
int x = 1;
int y = 2;
System.out.println(x = y); // 2
// 实际打印的是 = 左边的变量
注意一下优先级就可以了,关于最后的这种运算,前面的文章写了好几次了,注意内部会使用一个 temp 来做缓存,这样就没问题了。
对于位运算:
左移 << :二进制往左移,低位补 0。
右移 >> :二进制往右移,高位的空位补符号位,若左操作数是正数,则高位补“0”,若左操作数是负数,则高位补“1”。
无符号右移 >>> :二进制往右移,高位总是补 0。
左移相当于乘以 2^n,右移相当于除以 2^n,n 指的是移动的位数,这样效率非常高。
如果移动的位数超过了该类型的最大位数,那么编译器会对移动的位数取模。
如对 int 型移动 33 位,实际上只移动了 33%2=1 位
附:优先级表
| 优先级 | 运算符 | 结合性 |
|---|---|---|
| 1 | ()、 []、 . |
从左到右 |
| 2 | ! 、+(正) 、 -(负) 、~ 、++ 、-- |
从右向左 |
| 3 | * 、/ 、% |
从左向右 |
| 4 | +(加) 、-(减) |
从左向右 |
| 5 | << 、>> 、>>> |
从左向右 |
| 6 | < 、<= 、> 、>= 、instanceof |
从左向右 |
| 7 | == 、 != |
从左向右 |
| 8 | &(按位与) |
从左向右 |
| 9 | ^(异或) |
从左向右 |
| 10 | ` | ` |
| 11 | && |
从左向右 |
| 12 | ` | |
| 13 | ?: |
从右向左 |
| 14 | = 、+= 、-= 、*= 、/= 、%= 、&= 、` |
= 、^=` 、`~=` 、`<<=` 、`>>=` 、`>>>=` |
重写
方法的重写(override)两同两小一大原则:
- 子类返回类型小于等于父类方法返回类型
- 子类抛出异常小于等于父类方法抛出异常
- 子类访问权限大于等于父类方法访问权限
重写就是在子类定义一个方法,和父类的某个方法名相同,参数类型相同,最好加个 @override 注解。
继承
父类没有无参的构造函数,子类需要在自己的构造函数中显式调用父类的构造函数
创建一个子类时,首先会创建出一个父类,再创建子类,在子类中保存了这个父类的引用,这就是为什么 super 可以调用父类的方法。
下面来看一个例子,来理解创建对象的过程,了解父与子的静态代码块、构造方法之间的顺序:
public class Fu {
// 测试用静态代码块
static {
System.out.println("Fu 的静态代码块");
}
public Fu() {
System.out.println("Fu 的构造方法");
}
}
public class Zi extends Fu {
// private static Zi zi = new Zi();
static {
System.out.println("Zi 的静态代码块");
}
// private static Zi zi = new Zi();
public Zi() {
System.out.println("Zi 的构造方法");
}
static {
System.out.println("Zi 的第二段静态代码块");
}
}
/**
* 测试类
*/
public class Test {
public static void main(String[] args) {
Zi zi = new Zi();
}
}
我把类都整合到上面这一个代码段里了,下面是结果:
new 一个子对象,依次打印的是:
Fu 的静态代码块
Zi 的静态代码块
Zi 的第二段静态代码块
Fu 的构造方法
Zi 的构造方法
可以看出是先执行父类静态代码块,再执行子类代码块,然后是父的构造方法,子的构造方法。
还可以看出的是静态代码块是依次执行的,包括静态变量。
当把第 12 行的注释打开,再执行的时候,结果是:
Fu 的静态代码块
Fu 的构造方法
Zi 的构造方法
Zi 的静态代码块
Zi 的第二段静态代码块
Fu 的构造方法
Zi 的构造方法
最开始 new 子类的时候,肯定会先执行父的静态代码块,然后就会执行子类的静态代码块,第一句就是 static Zi zi = new Zi() ,这里需要先创建一个子对象,就需要执行父和子的构造方法,注意:在这里子的静态代码块还没执行到(父类的静态代码块只会执行一次)。
对比来看,如果只把 18 行的注释打开,结果就是:
Fu 的静态代码块
Zi 的静态代码块
Fu 的构造方法
Zi 的构造方法
Zi 的第二段静态代码块
Fu 的构造方法
Zi 的构造方法
这就更能充分的证明上面的观点了。
数组
数组复制方法效率比较:
- 使用 for 循环:
灵活,代码不够简洁,效率一般 - 使用
System.arraycopy():
通过源码可以看到此方法是 native 修饰的,说明是一个原生态方法,实现是用 c/c++ 写的,效率较高 - 使用
Arrays.copyOf():
通过查看源码可以看到它的内部是调用的 System.arraycopy() ,所以效率一般是不及直接使用第二种的。 - 使用 clone :
返回的是 Object,需要强转,一般来说 clone 是效率最差的。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号