

论文阅读 | Semi-supervised Stochastic Multi-Domain Learning using Variational Inference
论文地址:https://arxiv.org/abs/1906.02897?context=cs.CL
研究的问题:
关注的是半监督的多域学习的问题,具体地说,由于文本的来源是各种各样的,它们的形式并不一致,域标签也并不总是可用的。同时,有一些跨域的内容,比如“新闻”下面包括政治、体育、旅游等。要准确地建模某种域的数据需要特定的知识。一个直接的思路是用一个模型联合学习所有数据,而不受域的约束。本文用潜在变量来刻画域,在建模的过程中,研究了离散的混合模型和连续向量的模型,以及如何用基于梯度的方法和变分推理来进行训练。
研究方法:
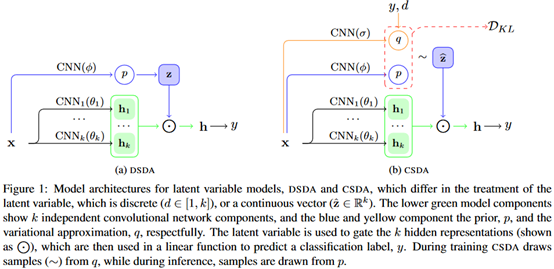
SDA(Stochastic Domain Adaptation):使用潜在变量来表示一个隐式的“域”。 ,z为潜在域。
,z为潜在域。
在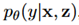 中,z作为门,决定哪些channel来用作表示输入。具体是通过一个CNN
中,z作为门,决定哪些channel来用作表示输入。具体是通过一个CNN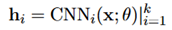 ,其中k表示channel数量。
,其中k表示channel数量。
根据z的性质,这里做出了两种不同的先验假设,分别是,设它是一个离散值(DSDA);设它是一个连续向量(CSDA)。
DSDA:设z是一个整数随机变量, 。这样的先验下通过输入x预测z,通过softmax预测,目标函数就是极大似然估计,如下所示:
。这样的先验下通过输入x预测z,通过softmax预测,目标函数就是极大似然估计,如下所示:
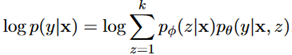
CSDA:借鉴自LDA将文档建模为多个主题的混合体的方法。一个直接的想法,使用二进制函数作为域描述符来建模z。对于k个域,也就是有2的k次方个域的组合,使用“01”这样的二进制串可以表示所有的主题的域。这样域的各个部分可以专注于一个特定的主题。这是一个理想化的方法,但是文档中存在很多边缘化的表示,比如在体育中讲政治的事情,很难对它来建模。
对于z的一些可能的分布,本文讨论了其中两种,beta分布和狄利克雷分布。
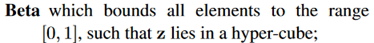

预期上狄利克雷分布会更好一些,因为它在主题模型中被广泛使用。
在这两种情况下,先验就分别被建模为:
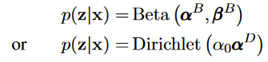
先验中的参数作为神经网络的输入也被参数化了。对于Beta先验,有
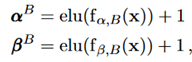
其中 表示element-wise乘法,
表示element-wise乘法,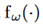 是一个非线性函数,这里用的是CNN。
是一个非线性函数,这里用的是CNN。
对于狄利克雷先验,参数化如下:
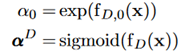
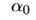 用来表示模型整体的sparsity,
用来表示模型整体的sparsity,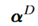 用来表示模型每个channel的affinity。
用来表示模型每个channel的affinity。
整体结构如下图所示。
最后,讨论了模型的训练问题。提出了一种基于VAE的变分推理方法,最大化evidence lower bound
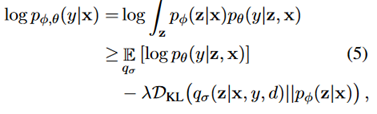
其中,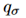 是变分分布,对应于前述的beta先验和狄利克雷先验,其区别在于,q条件不仅存在于x上,还存在于标签y和域d上,这里是通过嵌入y和d来实现的,将它们和x的CNN编码连接起来组成分布参数。
是变分分布,对应于前述的beta先验和狄利克雷先验,其区别在于,q条件不仅存在于x上,还存在于标签y和域d上,这里是通过嵌入y和d来实现的,将它们和x的CNN编码连接起来组成分布参数。
实验部分:
用的是Multi-Domain Sentiment Dataset,多领域的情感分析数据集。为了模拟半监督域的情况,删除了一半标记数据的域属性。
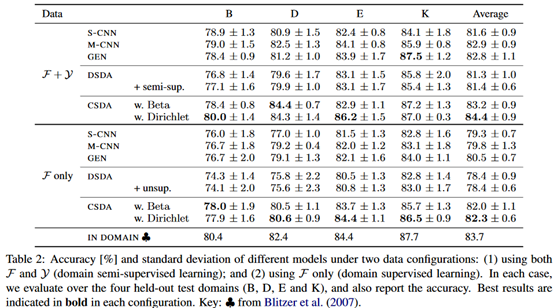
评价:
半监督学习也是当下比较流行的一个研究领域,在NLP的相关问题中,半监督学习的效果比CV领域的效果还要更好一些。本文讨论了用潜在变量来表示隐式的域,在建模先验的时候分别尝试了beta分布和狄利克雷分布,训练的方法类似于VAE。在VAE中隐变量的分布用的是高斯分布,但是在NLP任务中,狄利克雷分布在主题建模上效果更好一些。公式部分在附录中给出了更详细的一些推导。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号