

Python爬虫与一汽项目【三】爬取中国五矿集团采购平台
网站地址:http://ec.mcc.com.cn/b2b/web/two/indexinfoAction.do?actionType=showMoreCgxx&xxposition=cgxx
本来以为这是个老老实实的get请求,谁知道在翻页的时候发现提交请求的方式是post,
好在首页用get方式可以轻松获取到html源码,没有像之前的东方电气那么烦人。
在这里采用了简单的post提交方式,因此观察翻页即可发现,页面的改变和FormData有关
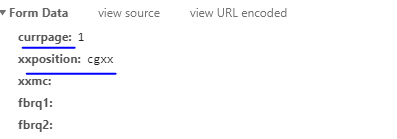
通过更改formdata中的currpage即可实现翻页提交。
使用post方式时,数据放在data或者body中,不能放在url中,放在url中将被忽略。
urllib2用一个Request对象来映射所提出的HTTP请求。
通过请求的地址创建一个Request对象,
通过调用urlopen并传入Request对象,将返回一个相关请求response对象,
这个应答对象如同一个文件对象,所以要在Response中调用.read()
def get_one_page(url,data):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36'
}
#将传过来的data进行编码,变成bytes格式的数据
dataEncode = urllib.parse.urlencode(data).encode('utf-8')
#获取网页响应内容,用到了urllib模块
request = urllib.request.Request(url=url, headers=headers,data=dataEncode)
response = urllib.request.urlopen(request)
#获取应答对象
return response.read().decode('utf-8')
except RequestException:
return None
主方法中构造data
def main():
url = "http://ec.mcc.com.cn/b2b/web/two/indexinfoAction.do?actionType=showMoreCgxx&xxposition=cgxx"
#构造post表单所提交的数据
data = {
'currpage': 1,
'xxposition': 'cgxx'
}
html = get_one_page(url,data)
print(html)
接下来可以通过循环构造最大页数,并将最大页传给data,循环获取每一页的内容即可。
#直接修改data的value值即可
for i in range(2,page_num+1):
data['currpage'] = i

 浙公网安备 33010602011771号
浙公网安备 33010602011771号