

少数人的智慧
在写完《Quora是如何做推荐的》一文之后,我在思考一个问题:伴随着Quora、知乎这样的知识分享型社区的兴起,涌现了一大批各个领域的专家用户,这会对推荐系统带来哪些可能的变化呢?恰好今天在读马尔科姆·格拉德威尔的《眨眼之间》这本书的时候,看到了这么一段,
当我们在某一方面修炼到登堂入室的程度时,我们的品味会变得愈发专业精深、愈发让外行难以理解。也就是说,只有专家才能对自己的反馈信息和看法负起责任。
我忽然想起来我在09年写过一篇blog《The Wisdom of the Few》,正好和这个事情特别相关。《The Wisdom of the Few》是来自Telefonica Research的一篇论文,《The Wisdom of the Few: A Collaborative Filtering Approach Based on Expert Opinions from the Web》[1]。我当年是在SIGIR'09里面发现的,觉得很有意思。这篇论文的核心内容非常简单,主要方式是对比分析,结论也挺中肯的。
首先定义「专家/Expert」,他们必须是这样的一群人:在一个特定的领域内,能对该领域内的条目给出深思熟虑的、一致的、可靠的评价(打分)。[2]
1)通过对 Netflix Users vs. Experts(作者自己收集的)的数据进行对比分析
-
Number of Ratings and Data Sparsity
-
Average Rating Distribution
-
Rating Standard Deviation (std)
得出结论认为,
-
专家打分数据的稀疏性要好得多。
-
专家的打分对象更全面,好的坏的,流行的冷门的,都会涉及到;而不像大众打分会倾向于流行的和自己喜欢的。
-
对好电影的评价专家们更趋一致。
-
对于每单个电影的评价,专家们的分歧也相对更小。
-
对于每单个用户和专家的对比,专家给出的打分更为稳定。
2)进行 Nearest-Neighbor CF vs. Expert CF 的推荐效果对比,主要评价「准确性/MAD」和「覆盖率/Coverage」两个指标,
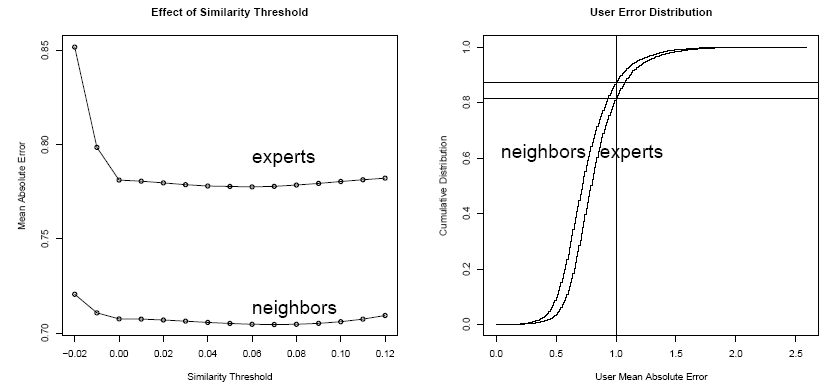
-
推荐准确性,NN-CF 差不多比 Expert-CF 要好 10%。
-
推荐覆盖率,Expert-CF 差不多比 NN-CF 要高 10%。
-
有意思的是上面的右图,用户分布与推荐准确性的关系,
-
在 MAE < 0.5 时,两种方法覆盖的用户数差不多
-
差不多在 MAE = 0.5 时,NN-CF 比 Expert-CF 多 10%
-
之后 MAE 在 [0.5, 1.0] 区间内时,NN-CF 与 Expert-CF 几乎平行
-
这个意思是说,与 Expert-CF 相比,NN-CF 仅对少部分用户(MAE<0.5的用户,占总数的10%)有明显优势。而这部分用户又可以认为是可预测性很高的用户,Expert-CF 比较容易利用其他方法提高效果。
-
结论是,Expert-CF 大多数情况下与 NN-CF 效果相当。
3)进行 Nearest-Neighbor CF vs Expert CF 的推荐效果的用户调研,推荐系统最终是为用户服务的,用户说好才是真的好!

-
Random,随机生成的推荐列表。
-
Critics' Choice,Experts 平均打分比较高的影片组成的推荐列表。
-
kNN-CF/Experts-CF,文中两种算法生成的推荐列表。
-
左图是用户满意度,调查推荐列表里是否包含用户喜欢的影片。两个评价指标,包含喜欢影片的多少,及是否有惊喜。
-
右图是用户反感度,调查推荐列表里是否包含用户讨厌的影评。两个评价指标,包含讨厌影片的多少,及讨厌程度。推荐系统里面有句名言,「错误的推荐还不如不推荐」。
-
结论是,Experts-CF 的用户满意度更高。当然了,这个结论的现实性是有一些争议的,比如,参与用户的数量很少,且大多数是男性用户。不过论文作者在这方面都有提到,比较中肯。
证明了 Expert-CF 的可用性之后,吸引人的是这个方法相对传统CF方法,能够带来的好处。
1、Data Sparsity,数据稀疏性
专家的打分数据数据通常涵盖面更广,使用这个数据作推荐,解决了传统 CF 的数据稀疏问题。
2、Noise and Malicious Ratings,噪音及恶意打分
专家的打分通常更加认真或是专业,解决了用户不小心打错分及恶意捣乱的问题。
3、Cold Start Problem,冷启动问题
专家通常更加关注自己领域内的新事物,并能够更快地给出评价。
4、Scalability,可扩展性
对于 (N-User, M-Item) 的推荐问题,传统 NN-CF 的算法复杂度是 O(N2M),计算量很大。而Expert-CF方法可以大幅度降低计算成本。比如论文里的数据,169 experts vs. 500, 000 potential neighbors (Netflix database)。
5、Privacy,用户隐私
如何更好地保护用户隐私,一直是推荐系统领域的一个热点问题。比如,基于Expert-CF方法,可以把一小撮专家打分数据下载到手机上,进行本地计算,然后得到推荐结果,而避免把过多的数据都存储在应用服务商的服务器上。
当年我这篇blog发出之后,在推荐圈引发了一些小讨论,当年还是豆瓣算法组小鲜肉现在已经成为机器学习大牛的阿稳同学也给出了自己的解读。[2]
之所以要提出专家CF的算法取代传统的CF,是基于传统CF的一些弊病,比如数据的稀疏性,数据噪声以及计算量的庞大等等,而正是这些数据上的原因导致传统CF算法推荐多样性不足、推荐不准确以及推荐可扩展性不良好等种种问题。这里提出的专家CF算法目的并不在于在某些数学精度指标上压倒传统的CF算法,而希冀能探究如下几个问题:
看这篇文章,更多的是看文中阐述的思想,虽然这可能并不是他们首创的,但毕竟他们作了一个很好的总结与分析。我一直在思索我们到底需要什么样的推荐,最近我觉得:至少在大部分的场合,我们需要的并不是与自己相似的用户的推荐,而是与自己相似的专家的推荐。无论是看书、看电影、买手机、买笔记本,那批「行内人物」的观点往往是左右我们决定的主要因素。这个结论在个性化要求相对比较低的中国显得更为真实。
一个庞大的用户集合的偏好是否可以通过一个比较小的用户集合的偏好预测出来;
对于一个源数据集来说,另一个与之不同源的、无直接相关的数据集是否具有对它进行推荐的能力;
分析专家的收藏是否可以用作普通用户的推荐;
探讨专家CF是否能解决传统CF的一些难题。
在这篇论文里,作者并没有详细地探讨如何从数据中发现一批领域专家,他们挑选的是一批来自从烂番茄网站爬取的现成的电影评论专家。这也是当年使用这个方法的一个难题,去哪里找到这些各个领域的专家。而如今7年过去了,Quora、知乎、微博、包括各个垂直专业领域的自媒体的崛起,几乎已经让这个问题迎刃而解。
类似于SaaS,目前又有个提法叫做「数据即服务」。留个讨论,你认同DaaS吗,和本文的方法结合这里面可能有什么机会呢?一起开开脑洞吧。
参考资料:
[1] http://www.nuriaoliver.com/recsys/wisdomFew_sigir09.pdf
[2] http://blog.sciencenet.cn/blog-64458-372804.html,阿稳的blog已经访问不了了,只能放这个转载了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号