

刨根究底字符编码之二——关键术语解释(下)

关键术语解释(下)
一、第1层 抽象字符表ACR (Abstract Character Repertoire抽象字符清单):明确字符的范围(即确定支持哪些字符)
1.
抽象字符表ACR是一个编码系统支持的所有抽象字符的集合,可以简单理解为无序的字符集合,用于确定字符的范围,即要支持哪些字符。
抽象字符表ACR的一个重要特点是字符的无序性,即其中的字符并没有编排数字顺序,当然也就没有数字编号。
2.
“抽象”字符不具有某种特定的字形,不应与具有某种特定字形的“具体”字符混淆。
3.
字符表可以是封闭的(即字符范围是固定的),即除非创建一个新的标准,否则不允许添加新的字符,比如ASCII字符表和ISO/IEC 8859系列都是这样的例子;字符表也可以是开放的(即字符范围是不固定的),即允许不断添加新的字符,比如Unicode字符表和一定程度上Code Page代码页(代码页后文会有详细解释)是这方面的例子。
二、第2层 编号字符集CCS(Coded Character Set):用数字编号表示字符(即用数字给字符编号)
【注:一般将“Coded Character Set”翻译为“编码字符集”或“已编码字符集”,但这里的“编码”二字容易导致与后文的“编码方式”及“编码模式”中的“编码”二字混淆,带来理解上的困扰,因此觉得翻译为“编号字符集”为宜。】
1.
前面讲了,抽象字符表里的字符是没有编排顺序的,但无序的抽象字符表只能判断某个字符是否属于某个字符表,却无法方便地引用、指称该字符表中的某个特定字符。
为了更方便地引用、指称字符表中的字符,就必须为抽象字符表中的每个字符进行编号。
所谓字符编号,就是将抽象字符表ACR中的中每个抽象字符(简称字符)表示为1个非负整数N或者映射到1个坐标(非负整数值对x, y),也就是将抽象字符的集合映射到一个非负整数或非负整数值对的集合,映射的结果就是编号字符集CCS。因此,字符的编号也就是字符的非负整数代码。
例如,在一个给定的抽象字符表中,表示大写拉丁字母“A”的字符被赋予非负整数65、字符“B”是66,如此继续下去。
2.
由此产生了编号空间(Code Space,一般翻译为代码空间、码空间、码点空间)的概念:根据抽象字符表中抽象字符的数目,可以设定一个字符编号的上限值(该上限值往往设定为大于抽象字符表中的字符总数),从0到该上限值之间的非负整数范围就称之为编号空间。
编号空间的描述:
1)可以用一对非负整数来描述,例如:GB2312的汉字编号空间是94 x 94;
2)也可以用一个非负整数来描述,例如:ISO-8859-1的编号空间是256;也可以用字符的存储单元尺寸来描述,例如:ISO-8859-1是一个8比特的编号空间(2^8=256);
3)还可以用其子集来描述,如行、列、面(Plane平面、层面)等等。
3.
编号空间中的一个位置(Position)称为码点(Code Point代码点)或码位(Code Position代码位)。一个字符占用的码点所在的坐标(非负整数值对)或所代表的非负整数,就是该字符的编号,又称之为码点值(即码点编号)。
不过,严格来讲,字符编号并不完全等同于码点编号(即码点值)。因为事实上,由于某些特殊的原因,编号字符集CSS里的码点数量要大于抽象字符表ACR中的字符数量。
在编号字符集中,除了字符码点之外,还存在着非字符码点和保留码点,所以字符编号不如码点编号准确;但若对字符码点的码点编号称之为字符编号,倒也更为直接。
在Unicode编码方案中,字符码点又称之为Unicode标量值(Unicode Scalar Value,感觉不如字符码点更为直观),非字符码点和保留码点详见后文介绍。
4.
注意,经常直接以“码点”指代“码点值”——当说到“码点”的时候,有可能是在说编号空间(即码点空间)中的一个位置,即码点;也有可能实际是在说某个码点的码点值,即码点编号。具体根据上下文而定。
这种类似的指代非常普遍,又比如“字符集”、“字符编号”和“字符编码”这三个概念就经常相互指代。以“码点”指代“码点值”,根据上下文,倒也还不难理解;但“字符集”、“字符编号”和“字符编码”三者也经常相互指代,虽然有其历史原因,但目前的实际情况所导致的结果却是使人迷惑、让人抓狂!
5.
因此,所谓编号字符集,可简单理解为就是把抽象字符进行逐个编号或者说逐个映射为码点值(即码点编号)后所得到的结果。编号字符集CSS常简称为字符集。
注意不要将编号字符集CSS和抽象字符表ACR相混淆。多个不同的编号字符集CCS可以表示同一个抽象字符表ACR。
6.
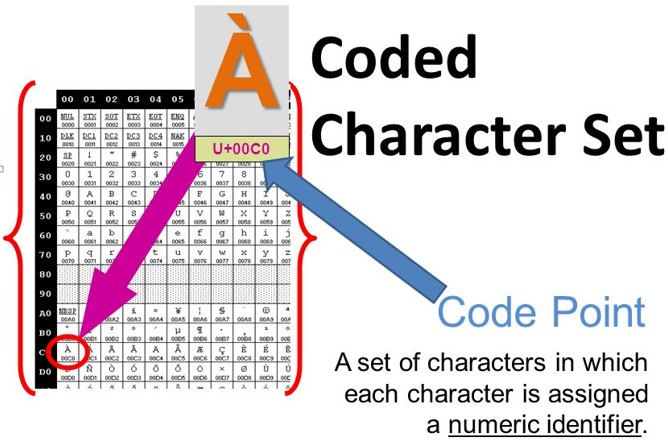
在Unicode标准中,一个单个的抽象字符,既有可能与多个码点对应(为了与其它标准兼容,比如码点编号为U+51C9与U+F979的这两个码点实际上是同一个字符“凉”,这是为了兼容韩国字符集标准KS X 1001:1998,具体可参看Unicode的官方文档),也有可能使用一个由多个码点所组成的码点序列表示(为了表示由基本字符与组合字符组合在一起所组成的字符,比如à,由码点编号为U+0061的基本字符字母“a”和码点编号为U+0300的组合字符读音符号“̀”组成);同时,也并非每一个码点都对应于一个字符,也存在着非字符码点或保留码点。详见后文解释。
7.
特别注意:虽然“编号”与后文某种字符编码方式CEF中的“编码”(即码元序列,解释详见后文)以及某种字符编码模式CES中的“编码”(即字节序列,解释详见后文)存在着对应的关系,但“编号”与“编码”是截然不同的两个概念。
对字符编号的过程——即确定字符码点值的过程,跟计算机还没有直接关系,可认为是一个纯数学的问题,因为只是将字符与编号(即码点值、码点编号)对应起来;根本还没涉及编码算法的问题——即根据指定的字符编码方式CEF对编号进行编码以形成码元序列,以及根据指定的字符编码模式CES对码元序列进一步编码以形成字节序列。
但这两个概念经常被混用,实实在在是让人困惑的源头,这是很令人无奈与遗憾的现实。
三、第3层 字符编码方式CEF(Character Encoding Form字符编码形式、字符编码格式、字符编码规则):将字符编号(即码点值)编码为码元序列(即字符编码)
1.
在讲抽象字符表ACR时说过,不同于传统的封闭的ASCII字符表,Unicode字符表是一个现代的开放的字符表,未来可能有更多的字符加入进来(比如很多Emoji表情符就被源源不断地加入进来)。因此,Unicode编号字符集所需要的码点数量,必然是会不断增加的,相对来说是无限的。
但计算机所能表示的整数范围却是相对有限的。比如,一个无符号单字节整型数(unsigned char, uint8)能够表示的编号只有0~0xFF,共256个;一个无符号双字节短整型数(unsigned short, uint16)的能够表示的编号只有0~0xFFFF,共65536个;而一个无符号四字节长整型数(unsigned long, uint32)能表示的码位只有0~0xFFFFFFFF,共4294967296个。
2.
那么问题来了:
1)一方面,怎么通过相对有限的整型数来高可扩展地、高可适应地应对未来相对无限增长的字符数量呢?是用多个单字节整型数来间接表示,还是用一个足够大的多字节整型数来直接表示?
2)另一方面,ASCII字符编码作为最早出现、已被广泛应用的编码方案,完全不兼容显然不明智,那么是直接兼容呢,还是间接兼容呢?
这两方面的问题需要一个综合解决方案,这就是字符编码方式CEF(Character Encoding Form)。
3.
字符编码方式CEF,是将编号字符集里字符的码点值(即码点编号、字符编号)转换成或者说编码成有限比特长度的编码值(即字符编码)。该编码值实际上是码元(Code Unit代码单元、编码单元)的序列(Code Unit Sequence)。
那什么是码元呢?为什么要引入码元这个概念呢?字符集里的字符编号又是如何转换为计算机中的字符编码(即码元序列)的呢?别急,这里先记下这个概念,暂不深究,后文有详细解释。
4.
字符编码方式CEF也被称为“存储格式”(Storage Format)。不过,将CEF称之为存储格式实际上并不合理,因为CEF还只是逻辑层面上的、与特定的计算机系统平台无关的编码方式,尚未涉及到物理层面上的、与特定的计算机系统平台相关的存储方式(第4层才涉及到)。
在ASCII这样传统的、简单的字符编码系统中,字符编号就是字符编码,字符编号与字符编码之间是一个直接映射关系。
而在Unicode这样现代的、复杂的字符编码系统中,字符编号不一定等于字符编码,字符编号与字符编码之间不一定是一个直接映射关系,比如UTF-8、UTF-16为间接映射,而UTF-32则为直接映射。
UTF-8、UTF-16与UTF-32等就是Unicode字符集(即编号字符集)常用的字符编码方式CEF。(UTF-8、UTF-16与UTF-32后文各有详细介绍)
5.
很多文章中,将Unicode与各UTF(Unicode/UCS Transformation Format,包括UTF-8、UTF-16与UTF-32等)之间的关系表述为:Unicode为标准规范、各UTF为编码实现。
不严格地来讲,也可以勉强这么认为。不过,这种表述毕竟不够严谨,而且无助于理解Unicode标准(即Unicode编码方案、Unicode编码系统)、Unicode字符集与各UTF字符编码方式之间更为深入细致的关系。
注:从现代字符编码模型的角度来看,Unicode标准、Unicode编码方案、Unicode编码系统基本上为同义词,是包括了抽象字符表ACR、编号字符集CCS、字符编码方式CEF以及下面要讲到的字符编码模式CES甚至传输编码语法TES在内的一整套标准方案系统,并不特指某一个层面。

四、第4层 字符编码模式CES(Character Encoding Scheme):将码元序列映射为字节序列
【注:一般将“Character Encoding Scheme”翻译为“字符编码方案”,但习惯上通常将某个字符编码系统称之为“字符编码方案”,为避免引起理解上的困扰,应译作“字符编码模式”为宜。】
1.
字符编码模式CES,也称作“序列化格式”(Serialization Format),指的是将字符编号进行编码之后的码元序列映射为字节序列(即字节流),以便编码后的字符在计算机中进行处理、存储和传输。
如果说将编号字符集的码点值(即字符编号)映射(编码)为码元序列的过程属于跟特定的计算机系统平台无关的逻辑意义上的编码,那么将码元序列映射(编码)为字节序列的过程就属于跟特定的计算机系统平台相关的物理意义上的编码。
2.
由于硬件平台与操作系统设计上的历史原因,对于UTF-16、UTF-32等采用多字节码元的编码方式而言,必须使用一个原先称之为零宽度不中断空格(ZERO WIDTH NO-BREAK SPACE)的字符(Unicode字符编号为U+FEFF)来指定字节序(Byte-Order字节顺序、位元组顺序,或称为Endianness端序)是大端序还是小端序,计算机才能够正确地进行处理、存储和传输。(什么是字节序以及其大端序、小端序,解释详见后文)
不过,对于UTF-8这种采用单字节码元的编码方式来说,并不存在字节序问题,不需要指明字节序。因此,在各种计算机系统平台中,UTF-8编码的码元序列与字节序列都是相同的。(为什么UTF-8不存在字节序问题,解释详见后文)
3.
注意,由于字符编码方式CEF与字符编码模式CES中都有“编码”二字,因此,通常所说的动词编码(Encode)有可能指的是通过字符编码方式CEF将编号字符集CCS中的字符编号转变为码元序列;也有可能指的是通过字符编码模式CES将字符编码方式CEF中的码元序列转变为字节序列。
动词解码(Decode)则反过来,当然也同样存在两种可能。
而通常所说的名词编码(Coding、Encoding)也就相应地有可能指的是码元序列,也有可能指的是字节序列。
因此,必须根据上下文语境来具体理解。
4.
对于程序员而言,通过字符编码方式CEF编码后所形成的码元序列,更多的是一种逻辑意义上的中间编码(即中介编码,属于从字符编号到字节序列的中间状态,作为将字符编号转换为字节序列的中介而存在),不是平时直接“打交道”的对象。
而通过字符编码模式CES将码元序列进一步编码后所形成的字节序列,才是平时直接“打交道”最多的物理意义上的最终编码(虽然事实上还有第5层的传输编码语法TES所形成的编码,但这种编码毕竟仅用于某些特殊的传输环境,平时“打交道”的机会较少)。
五、第5层 传输编码语法TES(Ttransfer Encoding Syntax):将字节序列作进一步的适应性编码处理
由于历史的原因,在某些特殊的传输环境中,需要对上一层次的字符编码模式CES所提供的字节序列(字节流)作进一步的适应性编码处理。一般包括两种:
1)一种是把字节序列映射到一套更受限制的值域内,以满足传输环境的限制,例如用于Email传输的Base64编码或者quoted-printable编码(可打印字符引用编码),都是把8位的字节映射为7位长的数据(Email协议设计为仅能传输7位的ASCII字符);
2)另一种是压缩字节序列的值,如LZW或者进程长度编码等无损压缩技术。
(这一部分内容本文不深入阐述,有兴趣者可自行查找资料。)
六、总结一下现代字符编码模型:
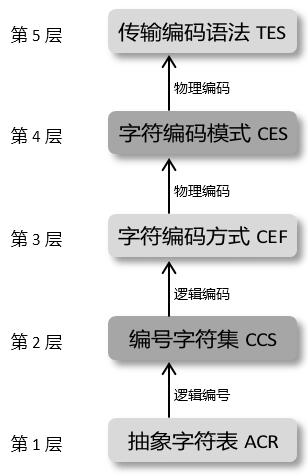
对于Unicode这样的现代字符编码系统来说,同一个字符因多个不同的字符编码方式CEF(如UTF-8、UTF-16、UTF-32等)而具有多个不同的码元序列(Code Unit Sequence),同一个码元序列因两个不同的字符编码模式CES(大端序、小端序)而又可能具有两个不同的字节序列(Byte Sequence)。
但这些不同的码元序列也好,字节序列也好,只要表示的是同一个字符,所对应的码点值(即码点编号、字符编号)一般都是相同的(在Unicode标准中,为了与其它标准兼容,有少数字符可能与多个码点对应)。
好了,关键术语先解释到这里,其他术语将在后文中陆续解释。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号