刨根究底字符编码之一——关键术语解释(上)
声明:本系列文章参考了网上的大量资料,除了少部分资料由于未作大量修改(但基本上也有少量修改,因为网上文章随意性较大,很多明显的笔误或前后矛盾之处,如若不改反而让人迷糊)而标明了原作者和出处之外,其余由于基本上已按自己的理解作了大量改写,因此没有再一一予以说明,在此对原作者表示歉意并感谢。另外,文中图片部分来自网络,部分为本人制作,也不再一一说明。同时,文中若有错漏,还请直接招呼板砖,不用客气。

关键术语解释
一、位
1.
即比特(Bit),亦称二进制位、比特位、位元、位,指二进制数中的一位,是计算机中信息表示的最小单位。
Bit是Binary digit(二进制数位)的缩写,由数学家John Wilder Tukey提出,习惯上以小写字母b表示,如8比特可表示为8b。

2.
每个比特有0和1两个可能的值,除了代表数值本身之外,还可代表:
- 数值的正、负;
- 两种状态,如电灯的开、关,某根导线上电压的有、无,等等;
- 一个抽象逻辑上的是、否。
二、字节
1.
在计算机中,通常都会使用一连串的位(比特),称之为位串(bit string比特串)。很显然,计算机系统都不会让你使用任意长度的位串,而是使用某个特定长度的位串。
一些常见的位串长度形式具有约定好的名称,如,半字节(nibble,貌似用的不多)代表四个位的组合,字节(byte)代表8个位的组合;还有字(word)、双字(Double word,简写为Dword)、四字(Quad word,简写为Qword)、十字节(Ten byte,简写为Tbyte)。
2.
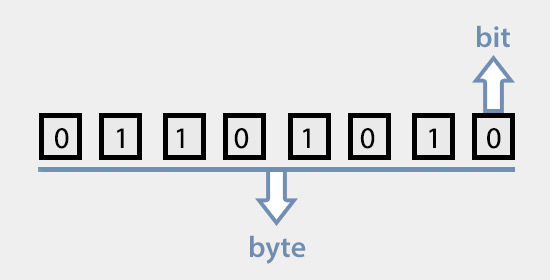
字节(byte),又称为位元组,音译为“拜特”(但很少使用这个译名),是计算机中计量存储容量和传输容量的一种基本计量单位,是由连续的、固定数量的位(即比特)所组成的位串(即比特串),一般由8个位组成,即1 byte = 8 bit。习惯上用大写的B表示,如3字节可表示为3B。
现代个人计算机(PC)的存储器编址,一般是以字节为单位的,称之为按字节编址,因此字节一般也是存储器的最小存取单元以及处理器的最小寻址单位(也有按位寻址、按字寻址等等,但在个人计算机上应用不普遍,这里不讨论)。
3.
字节作为存储器的最小存取单元以及处理器的最小寻址单位这一重要特点,跟字符编码的关系极为密切(比如,码元的单字节与多字节、字节序的大端序与小端序等,都与以字节为基础的基本数据类型密切相关,详见后文介绍)。
4.
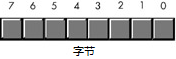
习惯上,按照下面的图来排列一个字节上的各个位的顺序,即按照从右到左的顺序,依次为最低位(第0位)到最高位(第7位):
5.
注意,字节不一定非得是8位,以前也有过4位、6位或7位作为一个字节的标准,比如IBM 701(36位字长,18位为一字节)、IBM 702(7位字长,7位为一字节)、CDC 6600(60位字长,12位为一字节byte)等,只是现代计算机的事实标准就是用8位来代表一个字节(最终形成这一事实标准除了历史原因和商业原因之外,最重要的原因应该是由于二进制的特性:2的次方计算更方便快捷)。
正是因为这个原因,在很多较为严谨的技术规格文献中,为了避免产生歧义,更倾向于使用8位组(Octet)而不是字节(Byte)这个术语来强调8比特位串。
不过,由于大众基本上都将字节理解为8比特位的8位组,因此一般文章中如果未作特别说明,基本上都将8位组直接称之为字节。
三、字与字长
1、
虽然字节是大多数现代计算机的最小存储单元和传输单元,但并不代表它是计算机可以最高效地处理的数据单位。
一般来说,计算机可以最高效地处理的数据大小,应该与其字的字长相同,这就涉及到了字及字长的概念。
字(Word):在计算机中,一串比特位(位串、比特串)是作为一个整体来处理或运算的,这串比特位称为一个计算机字,简称字。字通常分为若干个字节(每个字节一般是8位)。
字长(Word Length):即字的长度,是指计算机的每个字所包含的位数。字长决定了CPU一次操作所处理的实际比特位数量的多少。字长由CPU对外数据通路的数据总线宽度决定。
2.
计算机处理数据的速率,显然和它一次能加工的位数以及进行运算的快慢有关。如果一台计算机的字长是另一台计算机的两倍,若两台计算机的速度相同,在相同的时间内,前者能做的工作一般是后者的两倍。因此,字长与计算机的功能和用途有很大的关系,是计算机的一个重要技术指标。
在目前来讲,桌面平台的处理器字长正处于从32位向64位过渡的时期,嵌入式设备基本稳定在32位,而在某些专业领域(如高端显卡),处理器字长早已经达到了64位乃至更多的128位
四、字符集
1.
字符集(Character Set、Charset),字面上的理解就是字符的集合,是一个自然语言文字系统支持的所有抽象字符的集合。字符是各种文字和符号的总称,包括文字、数字、字母、音节、标点符号、图形符号等。
例如ASCII字符集,定义了128个字符;GB2312定义了7445个字符。而计算机系统中提到的字符集准确地来说,指的是已编号的字符的有序集合(但不一定是连续的)。
2.
常见字符集有ASCII字符集、ISO 8859系列字符集、GB系列字符集(GB2312、GBK、GB18030)、BIG5字符集、Unicode字符集等。
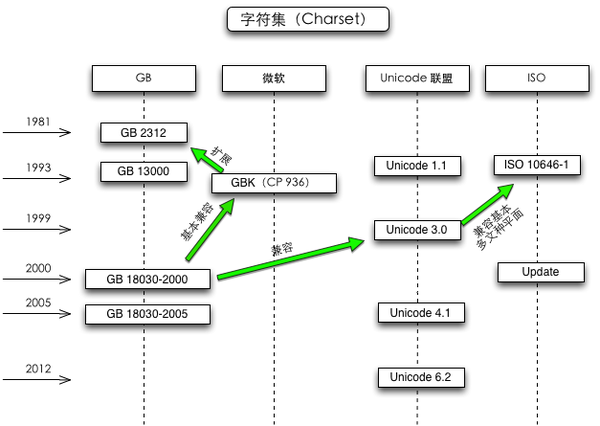
注:图中所示微软在GB2312的基础上扩展制订了GBK(Guo-Biao Kuozhan),然后GBK才成为“国家标准”(也有说GBK不是国家标准,只是“技术规范指导性文件”);但网上也有资料说是先有GBK(由全国信息技术标准化技术委员会1995年12月1日制订),然后微软才在其内部所用的CP936字码表(Code Page 936代码页936,代码页的解释详见后文)中以GBK为基础进行了扩展(即Windows系统的代码页CP936是GBK汉字内码扩展规范的一个实现)。
五、编码
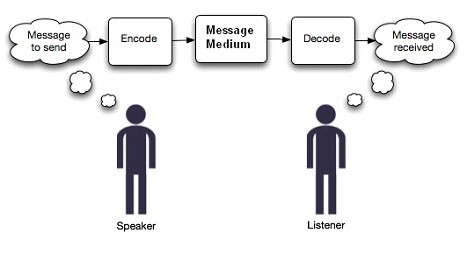
编码(Encode),是信息从一种形式或格式转换为另一种形式或格式的过程,比如用预先规定的方法将字符(文字、数字、符号等)、图像、声音或其它对象转换成规定的电脉冲信号或二进制数字。
六、解码
解码(Decode),为编码的逆过程。
七、字符编码
1.
字符编码(Character Encoding),是把字符集中的字符按一定格式(形式、方式)编码为某指定集合中某一对象(比如由0和1两个数字所组成的位串模式、由0~9十个数字所组成的自然数序列、电脉冲等)的过程,亦即在字符集与指定集合两者之间建立一个对应关系(映射关系)的过程。这是信息处理的一项基础技术。
而在计算机科学中,通常以字符集来表达信息,以计算机为基础的信息处理系统则利用电子元件(硬件)的不同状态的组合来表示、存储和处理信息。
2.
电子元件不同状态(一般是开和关或称为开和闭两种状态)的组合能代表数字系统中的数字(比如开和关代表二进制中的0和1),因此字符编码的过程也就可以理解为将字符转换映射为计算机可以接受的二进制数字的过程,其目的是为了便于字符在计算机中表示、存储、处理和传输(包括在网络中传输)。
常见的例子包括将拉丁字母表编码成摩斯电码和ASCII码。其中,ASCII将字母、数字和其它符号进行编号,并且在计算机中直接用7比特的二进制数字来表示这个编号。通常会额外地在最高位(即首位)再增加一个扩充的比特位“0”,以便于计算机系统刚好以1个字节(8比特位)的方式来进行处理、存储和传输。

八、字符编码模型
1.
字符编码模型(Character Encoding Model),是反映字符编码系统的结构特点和各构成部分相互关系的模型框架。
2.
由于历史的原因,早期一般认为字符集和字符编码是同义词,并不需要进行严格区分。因此在像ASCII这样的简单字符集为代表的传统字符编码模型中,这两个概念的含义几乎是等同的。
因为在传统字符编码模型中,基本上都是将字符集里的字符进行编号(字符编号转化为二进制数后一般不超过一个字节),然后该字符编号就是字符的编码。

但是,由统一码(Unicode)和通用字符集(UCS)为代表的现代字符编码模型则没有直接采用ASCII这样的简单字符集的编码思路,而是采用了一个全新的编码思路。
3.
这个全新的编码思路将字符集与字符编码的概念更为细致地分解为了以下几个方面:
1)有哪些字符;
2)这些字符的编号是什么;
3)这些编号如何编码成一系列逻辑层面有限大小的数字,即码元序列;
4)这些逻辑层面的码元序列如何转换为(映射为)物理层面的字节流(字节序列);
5)在某些特殊的传输环境中(比如Email),再进一步将字节序列进行适应性编码处理。
这几个方面作为一个整体,于是构成了现代字符编码模型。
4.
现代字符编码模型之所以要分解为这么几个方面,其核心思想是创建一个能够用不同方式来编码的通用字符集。注意这里的关键词:“不同方式”与“通用”。
这意味着,同一个字符集,可以通用于不同的编码方式;也就是说,可以采用不同的编码方式来对同一个字符集进行编码。字符集与编码方式之间的关系可以是一对多的关系。
更进一步而言,在传统字符编码模型中,字符编码方式与字符集是紧密结合在一起的;而在现代字符编码模型中,字符编码方式与字符集脱钩了。用软件工程的专业术语来说,就是将之前紧密耦合在一起的字符编码方式与字符集解耦了。
因此,为了正确地表示这个现代字符编码模型,需要采用更多比“字符集”和“字符编码”更为精确的概念术语来描述。
5.
在Unicode Technical Report (UTR统一码技术报告) #17《UNICODE CHARACTER ENCODING MODEL》中,现代字符编码模型分为了5个层次,并引入了更多的概念术语来描述(下面所涉及到的一些全新的概念术语,这里只做简介,暂时不作解释,但后文会陆续进行详细解释):
第1层 抽象字符表ACR(Abstract Character Repertoire抽象字符清单):明确字符的范围(即确定支持哪些字符)
第2层 编号字符集CCS(Coded Character Set):用数字编号表示字符(即用数字给抽象字符表ACR中的字符进行编号)
第3层 字符编码方式CEF(Character Encoding Form字符编码形式、字符编码格式、字符编码规则):将字符编号编码为逻辑上的码元序列(即逻辑字符编码)
第4层 字符编码模式CES(Character Encoding Scheme):将逻辑上的码元序列映射为物理上的字节序列(即物理字符编码)
第5层 传输编码语法TES(Transfer Encoding Syntax):将字节序列作进一步的适应性编码处理
后面将分层予以介绍。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号