
1. 定义
unordered_set 容器,可直译为“无序 set 容器”。即 unordered_set 容器和 set 容器很像,唯一的区别就在于 set 容器会自行对存储的数据进行排序,而 unordered_set 容器不会。
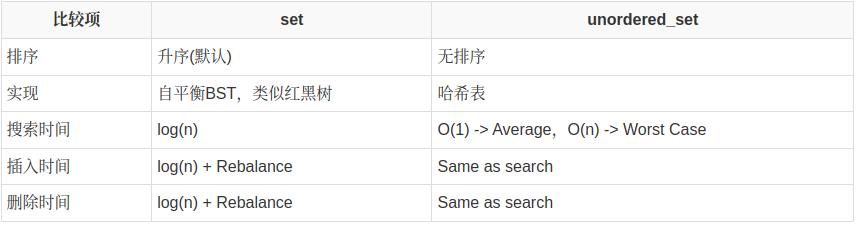
何时使用set
- 需要有序的数据。
- 将不得不按排序顺序打印/访问数据。
- 需要元素的前任/后继。
- 由于set是有序的,因此可以在set元素上使用binary_search(),lower_bound()和upper_bound()之类的函数。 这些函数不能在unordered_set()上使用。
- 有关更多情况,请参见BST优于哈希表的优势。
在以下情况下使用unordered_set
- 需要保留一组不同的元素,并且不需要排序。
- 需要单元素访问,即无遍历。
特性:
- 不再以键值对的形式存储数据,而是直接存储数据的值 ;
- 容器内部存储的各个元素的值都互不相等,且不能被修改;
- 不会对内部存储的数据进行排序
2. 头文件
#include <unordered_set>
3. 类模板成员方法
| 成员方法 | 功能 |
|---|---|
| begin() | 返回指向容器中第一个元素的正向迭代器。 |
| end(); | 返回指向容器中最后一个元素之后位置的正向迭代器。 |
| cbegin() | 和 begin() 功能相同,只不过其返回的是 const 类型的正向迭代器。 |
| cend() | 和 end() 功能相同,只不过其返回的是 const 类型的正向迭代器。 |
| empty() | 若容器为空,则返回 true;否则 false。 |
| size() | 返回当前容器中存有元素的个数。 |
| max_size() | 返回容器所能容纳元素的最大个数,不同的操作系统,其返回值亦不相同。 |
| find(key) | 查找以值为 key 的元素,如果找到,则返回一个指向该元素的正向迭代器;反之,则返回一个指向容器中最后一个元素之后位置的迭代器(如果 end() 方法返回的迭代器)。 |
| count(key) | 在容器中查找值为 key 的元素的个数。 |
| equal_range(key) | 返回一个 pair 对象,其包含 2 个迭代器,用于表明当前容器中值为 key 的元素所在的范围。 |
| emplace() | 向容器中添加新元素,效率比 insert() 方法高。 |
| emplace_hint() | 向容器中添加新元素,效率比 insert() 方法高。 |
| insert() | 向容器中添加新元素。 |
| erase() | 删除指定元素。 |
| clear() | 清空容器,即删除容器中存储的所有元素。 |
| swap() | 交换 2 个 unordered_set 容器存储的元素,前提是必须保证这 2 个容器的类型完全相等。 |
| bucket_count() | 返回当前容器底层存储元素时,使用桶(一个线性链表代表一个桶)的数量。 |
| max_bucket_count() | 返回当前系统中,unordered_set 容器底层最多可以使用多少桶。 |
| bucket_size(n) | 返回第 n 个桶中存储元素的数量。 |
| bucket(key) | 返回值为 key 的元素所在桶的编号。 |
| load_factor() | 返回 unordered_set 容器中当前的负载因子。负载因子,指的是的当前容器中存储元素的数量(size())和使用桶数(bucket_count())的比值,即 load_factor() = size() / bucket_count()。 |
| max_load_factor() | 返回或者设置当前 unordered_set 容器的负载因子。 |
| rehash(n) | 将当前容器底层使用桶的数量设置为 n。 |
| reserve() | 将存储桶的数量(也就是 bucket_count() 方法的返回值)设置为至少容纳 count 个元(不超过最大负载因子)所需的数量,并重新整理容器。 |
| hash_function() | 返回当前容器使用的哈希函数对象。 |
4. 用法
4.1 unordered_set的初始化
unordered_set的初始化
// 创建空的set
unordered_set<int> set1;
// 拷贝构造
unordered_set<int> set2(set1);
// 使用迭代器构造
unordered_set<int> set3(set1.begin(), set1.end());
// 使用数组作为其初值进行构造
unordered_set<int> set4(arr,arr+5);
// 移动构造
unordered_set<int> set5(move(set2));
// 使用处置列表进行构造
unordered_set<int> set6 {1,2,10,10};
4.2 equal_range(key)
返回一个 pair 对象,其包含 2 个迭代器,用于表明当前容器中值为 key 的元素所在的范围。
1 // C++ program to illustrate the 2 // unordered_set::equal_range function 3 #include <iostream> 4 #include <unordered_set> 5 using namespace std; 6 int main() { 7 // declaration 8 unordered_set<int> sample; 9 10 // Insert some values 11 sample.insert({20, 30, 40}); 12 13 // Test the equal_range function 14 // for a given key if it does not exist 15 auto range1 = sample.equal_range(10); 16 if (range1.first != sample.end()) { 17 for (; range1.first != range1.second; ++range1.first) 18 cout << *range1.first << endl; 19 } else 20 cout << "Element does not exist"; 21 return 0; 22 }
上面这段代码会输出
Element does not exist
体会: 感觉这个和find没啥区别,如果选择equal_range(30),那么它能找到。两个字: 没用
4.3 emplace_hint
emplace_hint() 方法的功能和 emplace() 类似,其语法格式如下:
template <class... Args>
iterator emplace_hint (const_iterator position, Args&&... args);
和 emplace() 方法相比,有以下 2 点不同:
A. 该方法需要额外传入一个迭代器,用来指明新元素添加到 set 容器的具体位置(新元素会添加到该迭代器指向元素的前面);
B. 返回值是一个迭代器,而不再是 pair 对象。当成功添加元素时,返回的迭代器指向新添加的元素;反之,如果添加失败,则迭代器就指向 set 容器和要添加元素的值相同的元素。
体会: 不推荐使用,感觉无论传入begin(),还是end(),它都是插入在开头的。
4.4 hash_function
直接当作普通的hash函数来使用吧,看下面这个例子:
// CPP program to illustrate the // unordered_set::hash() function #include <iostream> #include <string> #include <unordered_set> using namespace std; int main() { unordered_set<string> sampleSet; // use of hash_function unordered_set<string>::hasher fn = sampleSet.hash_function(); cout << fn("geeksforgeeks") << endl; return 0; }
例子中,sampleSet没有元素“geeksforgeeks“
得到的输出:
4011153232873121620

 浙公网安备 33010602011771号
浙公网安备 33010602011771号