


Google 开源技术protobuf
公司项目一直是使用protobuf序列化结构数据,但一直都是一知半解,今天就让我们来深入了解下它。
一、什么是protobuf?
1.官方描述:
protobuf是一种用于序列化结构化数据的灵活,高效,自动化的机制–以XML为例,但更小,更快,更简单。您可以定义如何一次构造数据,然后可以使用生成的特殊源代码轻松地使用各种语言在各种数据流中写入和读取结构化数据。
简单来讲, ProtoBuf 是结构数据序列化方法,可简单类比于 XML。
2.那序列化又是什么呢?
简单来说序列化就是一种用来处理对象流的机制,所谓对象流也就是将对象的内容进行流化,在对对象流进行读写操作时会引发一些问题,而序列化机制正是用来解决这些问题的!
读写对象会有什么问题呢?比如:我要将对象写入一个磁盘文件而后再将其读出来会有什么问题吗?别急,其中一个最大的问题就是对象引用!举个例子来说:假如我有两个类,分别是A和B,B类中含有一个指向A类对象的引用,现在我们对两个类进行实例化{ A a = new A(); B b = new B(); },这时在内存中实际上分配了两个空间,一个存储对象a,一个存储对象b,接下来我们想将它们写入到磁盘的一个文件中去,就在写入文件时出现了问题!因为对象b包含对对象a的引用,所以系统会自动的将a的数据复制一份到b中,这样的话当我们从文件中恢复对象时(也就是重新加载到内存中)时,内存分配了三个空间,而对象a同时在内存中存在两份,想一想后果吧,如果我想修改对象a的数据的话,那不是还要搜索它的每一份拷贝来达到对象数据的一致性,这不是我们所希望的!
以下序列化机制的解决方案:
1.保存到磁盘的所有对象都获得一个序列号(1, 2, 3等等)
2.当要保存一个对象时,先检查该对象是否被保存了。
3.如果以前保存过,只需写入"与已经保存的具有序列号x的对象相同"的标记,否则,保存该对象
通过以上的步骤序列化机制解决了对象引用的问题!
二、protobuf为什么快?
protobuf有多快呢,可以看一下下面的官方测试报告:

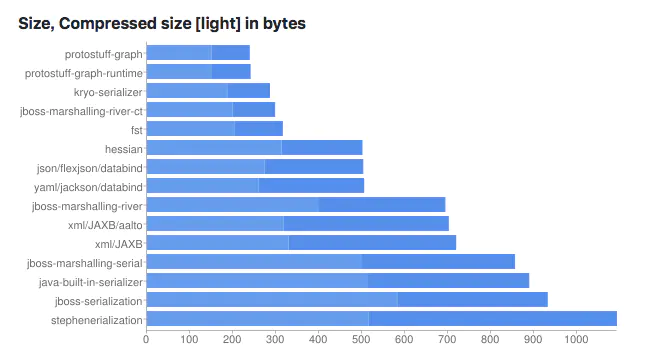
可以看到,一条消息数据,用protobuf序列化后的大小是json的10分之一,是xml格式的20分之一,但是性能却是它们的5~100倍
为什么protobuf序列化后可以这么小呢?
我们分别对比下xml,json和protobuf:
(1)xml序列化有大量的标签,虽然可读性良好,但这些标签也直接导致数据量曾大。
(2)json序列号省去了标签,转而使用键值对的方式,省去了标签,数据变得更加简约,相对于xml,数据小了许多
(3)protobuf序列化为了进一步减小数据量,直接把键都去掉,只保留了最重要的值,双方约定好第一个数据代表什么,第二个数据代表什么,从而大大压缩了数据量。
其实protobuf之所以这么快,并没有那么简单,它还在其他地方进行了优化,具体是怎么做到可以阅读以下博文:
https://www.jianshu.com/p/72108f0aefca?utm_source=oschina-app
三、protobuf插件:jprotobuf
1.何为jprotobuf:
jprotobuf是针对Java程序开发一套简易类库,目的是简化java语言对protobuf类库的使用
使用jprotobuf可以无需再去了解proto文件操作与语法,直接使用java注解定义字段类型即可
2.工作原理:
(1)扫描类上的注解的信息,进行分析(与protobuf读取proto文件进行分析过程相似)
(2)根据注解分析的结果,动态生成java代码进行protobuf序列化与反序列化的功能实现
(3)使用JDK6及以上的 code compile API进行编译后加载到classloader
-
性能:
jprotobuf 主要性能消耗在 扫描类上注解,动态生成代码编译的过程。
在执行序列化与反序列化的过程中,几乎与protobuf生成的代码效率等同
4.优点:
(1)无需编写proto文件及繁琐的手工编译过程,支持基于POJO对象的注解方式,方便快捷。
(2)支持protobuf所有类型,包括对象嵌套,数组,枚举类型
提供根据proto文件,动态生成代理对象,可省去POJO对象的编写工作。
完整支持proto文件所有功能,包括内联对象,匿名对象,枚举类型
(3)提供从POJO对象的注解方式自动生成proto文件的功能, 方便proto描述文件的管理与维护
更多内容请关注微信公众号“外里科技”


 浙公网安备 33010602011771号
浙公网安备 33010602011771号