

并发编程之JMM&Volatile(一)
并发
很多程序员应该对并发一词并不陌生,并发如同一把双刃剑,如果使用得当,可以帮助我们更好的压榨硬件的性能,反之,也会产生一些难以排查的问题。这里,先简单介绍下并发的几个基本概念。
进程与线程
进程:进程是操作系统进行资源分配和调度的基本单位。
线程:线程是操作系统能够进行运算调度的最小单位,它被包含在进程之中,是进程中的实际运作单位。
上面是百度百科对进程和线程的解释,可能有点抽象,这里笔者再根据自己的理解解释下进程和线程的概念和区别:当我们打开QQ、微信、网易云音乐,这时我们启动了三个进程,操作系统会分别对这三个进程分配资源,操作系统会分配什么资源给这三个进程呢?首先是内存资源,这三个进程都有各自的内存进行数据的存取,QQ和微信分别有各自的内存资源来保存我们的用户数据、聊天数据。其次,当我们需要用QQ或者微信聊天时,操作系统只会把键盘资源分配给QQ或者微信其中一个进程,当我们输入文字,只会出现在QQ或者微信其中一个的聊天窗。下面我们再来说说线程,我们用网易云音乐,可以同时下载音乐和播放音乐,两者互不影响,这是因为在网易云音乐这个进程里,同时有两个线程,一个线程播放音乐,一个线程下载音乐,利用多线程,可以使一个进程在一段时间内同时执行两个任务。
并发与并行
并发:在单核单CPU架构中,只会出现并发,不会出现并行。比如在一个电商系统中,用户A正在下单,用户B正在改名,因此分别有线程A和线程B两个线程在CPU上交替执行,互相竞争CPU资源。假设下单操作需要执行100个指令,改名操作需要执行60个指令,单核单CPU的架构可能先在线程A中执行80个指令,然后将CPU时间片让给线程B,线程B在执行50个指令后,CPU重新把时间片让给线程A执行剩余的20个指令,再执行线程B剩余的10个指令,最后线程A和线程B都执行完毕。
并行:只要是多核CPU,不管是单CPU还是多CPU,都有可能出现并行。还是以上面的电商系统为例,用户A和用户B的线程可以同时跑在同CPU或者不同CPU的不同的处理器上,这时候就能做到线程A和线程B同时执行,互不竞争CPU处理器资源。
区别:从上面的例子,我们可以知道并发和并行的区别,并发是指在一段时间内,多个任务交替执行,并行是同一时间内,多个任务可以同时执行。
并发编程的本质
至此,我们已经了解了并发的几个基本概念。而并发的本质是要解决:可见性、原子性、有序性这三个问题。
可见性
当多个线程同时访问同一个变量,一个线程修改了这个变量的值,其他线程要能立刻看到修改的结果。
我们来看下面这段代码,首先我们声明了一个静态变量flag,默认为true,线程A只要检查到flag为true时,就循环下去,主线程启动线程A后休眠2000毫秒,再启动线程B修改flag的值为false。按理来说,在flag被线程B修改为false之后,线程A应该退出循环。然而,如果我们运行下面的代码,会发现程序并不会终止。程序之所以不会终止的原因,是因为线程A无法跳出循环,即便我们用线程B把flag改为false,但线程B修改的行为,对线程A是无感知的,即线程A并不知道此时flag已经被其他线程修改为false,线程A仍旧以为flag为true,所以无法跳出循环。
public class VisibilityTest {
private static boolean flag = true;//静态变量
public static void main(String[] args) {
new Thread(() -> {
int i = 0;
while (flag) {//如果静态变量为flag则循环下去
i++;
}
System.out.println("i=" + i);
}, "Thread-A").start();
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
new Thread(() -> flag = false, "Thread-B").start();
}
}
之所以线程A无法感知线程B修改flag变量的值,是因为在线程A启动的时候,会拷贝一份flag的副本,我们将副本命名为flag’,当线程A需要flag的值时,会去访问flag’,并不会去访问flag最新的值。那么,线程A又为什么要拷贝一份flag的值呢?为什么不直接去访问flag呢?这里就要谈到CPU缓存架构和JMM模型(Java线程内存模型)。
下图是一个双核双CPU的架构,Core是CPU内核,L1、L2、L3是CPU的高速缓存,当CPU需要对数值进行运算时,会先把内存的数据加载到高速缓存再进行运算。假设线程A跑在Core1,线程B跑在Core2,不管是读取flag还是修改flag,线程A和B都需要从主存将flag加载到高速缓存(L1、L2、L3)。因此,高速缓存有两份flag的拷贝:flag(A)和flag(B),分别用于线程A和线程B,要注意一点的是,即便flag(A)和flag(B)都是主存flag的拷贝,但线程A对flag(A)读取或者修改对线程B是不可见的,同理线程B对flag(B)的读取修改对线程A也是不可见的。在我们上面的代码中,线程B在修改缓存的flag(B)之后,会把flag(B)最新的值同步回主存的flag,但线程A并不知道主存的flag已更新,它仍旧用缓存中flag(A)的值,所以无法跳出循环。
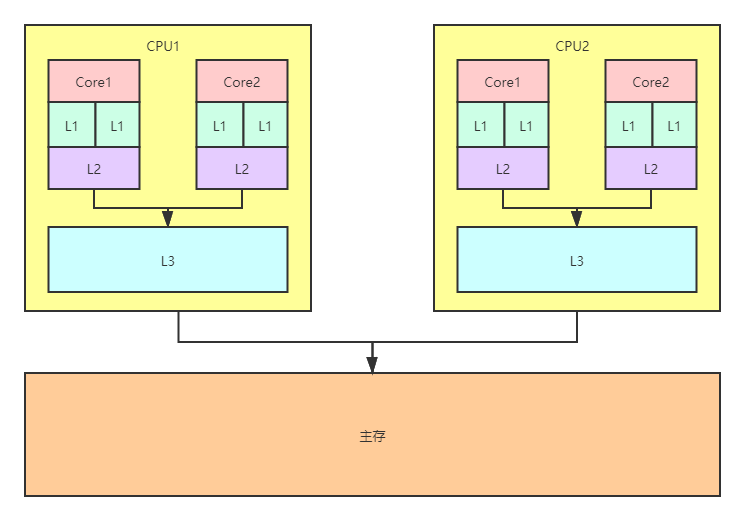
CPU缓存结构
Java的线程内存模型则参考了CPU的结构,在Java中,每个线程都有自己单独的本地内存用来存储数据,主存的共享变量也会被拷贝到本地内存成为副本,线程如果要使用共享变量,不会从主存读取或者修改,而是读取修改本地内存的副本。这也是代码VisibilityTest中,线程B在修改flag变量后,线程A无法跳出循环的原因。
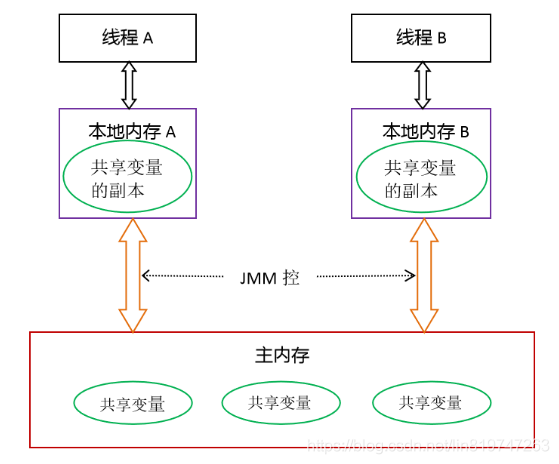
Java线程内存模型
那么,如果我们业务中存在多线程访问修改同一变量,而且要求其他线程能看到变量最新修改的值该怎么办呢?Java提供了volatile关键字,来保证变量的可见性:
private static volatile boolean flag = true;
如果我们给flag加上volatile,线程B在修改flag的值之后,线程A就能及时获取到flag最新的值,就会跳出循环。那么,除了volatile关键字,还有其他的办法来保证可见性吗?有三种方式:synchronized、休眠和缓存失效。
public class VisibilityTest2 {
private static boolean flag = true;//静态变量
public static void main(String[] args) {
new Thread(() -> {
int i = 0;
while (flag) {//如果静态变量为flag则循环下去
i++;
//System.out.println("i=" + i);//<1>调用println()方法时会进入synchronized同步代码块,synchronized可以保证共享变量的可见性
// try {
// Thread.sleep(100);//<2>休眠也可以保证贡献变量的可见性
// } catch (InterruptedException e) {
// e.printStackTrace();
// }
//shortWait(100000);//<3>模拟休眠100000纳秒,缓存失效
}
System.out.println("i=" + i);
}, "Thread-A").start();
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
new Thread(() -> flag = false, "Thread-B").start();
}
public static void shortWait(long interval) {
long start = System.nanoTime();
long end;
do {
end = System.nanoTime();
} while (start + interval >= end);
}
}
VisibilityTest2中<1>、<2>、<3>处的代码都会可以让线程A跳出循环,但三者的原理是不一样的:
- <1>调用标准输出流的println()方法,这个方法里有synchronized关键字,这个关键字可以保证本地内存对共享变量的可见性。
- <2>Thread.sleep()和Thread.yield()会让出CPU时间片,当休眠结束或者重新得到CPU时间片时,线程会去加载主存最新的共享变量。
- <3>我们调用shortWait(long interval)等待100000纳秒,由于本地内存的副本太久没有使用,线程判断副本过期,重新去主存加载,这里需要注意一点是,如果我们把等待时间设为10或者100纳秒,那么结束等待时线程又会去使用flag副本,由于等待时间不是很长,不会将副本设置为已过期,也就不会跳出循环。
至此,我们了解了线程可见性,以及保证可见性的方法。当然,在上面几种保证可见性的方法中,最优雅的还是使用volatile关键字,其他保证可见性的方式都不是那么优雅,或者说是不可控的。
原子性
即一个操作或者多个操作,要么全部执行并且执行的过程不被任何因素打断,要么就都不执行。原子性就像数据库里面的事务一样,要嘛全部执行成功,如果在执行过程中出现失败,则整体操作回滚。
我们来看下面的例子,在AtomicityTest中声明两个int类型的静态变量a和b,然后我们启动10个线程,每个线程对a和b循环1000次加1的操作,如果我们多次执行下面这段代码,会发现大部分情况下a和b最后的值都不是10000,甚至a和b的值也不相等,那么是为什么呢?
public class AtomicityTest {
private static volatile int a, b;
public static void main(String[] args) {
Thread[] threads = new Thread[10];
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(() -> {
for (int j = 0; j < 1000; j++) {
a++;
b++;
}
});
}
for (Thread thread : threads) {
thread.start();
}
for (Thread thread : threads) {
try {
thread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("a=" + a + " b=" + b);
}
}
运行结果:
a=9835 b=9999
我们来思考下,为什么a和b都不等于10000呢?静态变量a和b我们都用关键字volatile标记,所以一定能保证如果a和b的值被一个线程修改,其他线程能马上感知到。之所以出现a和b的结果都不是10000,是因为a++这个操作,并不是原子性,在一个线程执行a++这个操作时,可能被其他线程干扰。
我们可以来拆解下a++这个操作分哪几个步骤:
1.读取a的值 2.对a加1 3.将+1的结果赋值给a
我们假设线程1在执行a++操作的时,读取到a的数值为100,线程1执行完a++的第二个步骤,得出+1的结果是101,还未执行第三个步骤进行复制,此时线程2抢占了CPU时间片,线程1休眠,线程2读取到a的数值也是100,并且线程2完整的执行两次a++的所有步骤,此时a的数值为102,之后线程2休眠,线程1抢占到CPU时间片,便将之前+1的结果101赋值给a。这就是笔者所说,a++这个操作并非原子性,且被其他线程干扰,同理我们也就知道为何b的结果不是10000,而且a和b的结果还不相等。
要解决原子性问题也有很多种方式,针对AtomicityTest的代码,最简单的方式就是用synchronized加上一把同步锁:
public static void main(String[] args) {
Thread[] threads = new Thread[10];
Object lock = new Object();
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(() -> {
synchronized (lock) {
for (int j = 0; j < 1000; j++) {
a++;
b++;
}
}
});
}
……
}
运行上面的代码,a和b的结果都是10000。利用synchronized (lock)可以保证同一个时刻,最多只有一个线程访问同步代码块,其他线程如果要访问时只能陷入阻塞。这样也就能保证a++和b++的原子性。
Java每个对象的底层维护着一个锁记录,当一个对象时某个同步代码块的锁时,如果有线程进入同步代码块,对象的锁记录+1,线程离开同步代码块,则锁记录-1。如果锁记录>1,则代表当前线程重入锁,比如下面的代码,即方法A和方法B都有lock对象的同步代码块,当线程进入methodA的lock同步代码块,锁记录+1,调用methodB时执行到lock的同步代码块时,锁记录再次+1为2,当执行完methodB的同步代码块,lock的锁记录-1为1,最后执行完methodA的lock同步代码块,锁记录-1变为0,其他线程则可以竞争lock的锁权限,执行methodA或者methodB的同步代码块。
public void methodA() {
synchronized (lock) {
//...
methodB();
}
}
public void methodB() {
synchronized (lock) {
//...
}
}
我们来看看下面四个操作哪几个是原子性哪几个不是:
i = 0; //1 j = i ; //2 i++; //3 i = j + 1; //4
- i=0:是原子性,在Java中对基本数据类型变量的赋值操作是原子性操作。
- j=i:不是原子性,首先要读取i的值,再将i的值赋值给变量j。
- i++:不是原子性,操作步骤见上。
- i=j+1:不是原子性,原因同i++一样。
有序性
为了提高执行程序的性能,编译器和处理器可能会对我们编写的程序做一些优化,执行程序的顺序不一定是按照我们代码编写的顺序,即指令重排序。编译器和处理器只要保证程序在单线程情况下,指令重排序的执行结果和按照我们代码顺序所执行出来的结果一样即可。
我们看下面的两行代码,思考一下如果对调这两行代码会不会有什么问题?这两行代码那一行需要执行的指令更少?
int j = a;//<1> int i = 1;//<2>
首先我们来解决第一个问题,<1>和<2>这两行代码即便我们程序对调也不会有问题,毕竟代码<1>用到的变量和代码<2>没有交集,所以这两行代码是可以互换位置的。其次,我们来考虑<1>和<2>哪一行执行的指令更少,通过之前的学习,我们知道<2>是一个原子操作,而<1>需要读值再赋值,不是原子操作,执行代码<2>所需指令比<1>更少,所以编译器就可以做一个优化,把代码<2>和代码<1>的位置互换,优先执行指令少且变动顺序不会影响结果的代码,再执行指令多的代码。
下面的代码[1]和代码[2]是两个独立的代码块,但这两个独立的代码块最终结果又都是一样,即:i=2,j=3,那么哪一个代码块执行效率更高?
//[1] int i = 1;//<1> int j = 3;//<2> int i = i+1;//<3> //[2] int i = 1;//<4> int i = i+1;//<5> int j = 3;//<6>
为了思考代码块[1]和代码块[2]哪一个执行效率更高,我们模拟下CPU的执行逻辑。首先是代码块[1]:CPU在执行完<1>和<2>两个赋值操作后,即将执行i=i+1,这时候i的值可能已经不在CPU的高速缓存里,CPU需要去主存加载i的值进行运算和赋值。再来是代码块[2]:CPU执行完<4>的赋值操作,此时i还在高速缓存,CPU直接从高速缓存读取i的值加1再赋值给i,最后再执行代码<6>的赋值操作。
到这里,我想大家应该都明白哪个代码块效率更高,显而易见,代码块[2]的效率会更高,因为它不用面临变量i从高速缓存中淘汰,后续对i进行+1操作时又需要去主存加载变量i。而代码块[1]在执行完i的赋值操作后,又执行了其他指令,这时候可能出现高速缓存无法容纳变量i而将i淘汰,后续需要对i进行操作需要去主存加载i。
根据上面我们所了解的,指令重排序确实会提高程序的性能,但指令重排序只保证单线程情况下,重排序的执行结果和未排序的执行结果是一样的,如果是多线程的情况下,指令重排序会给我们带来意想不到的结果。
在下面的代码中,我们声明4个int类型的静态变量:a,b,x,y,主方法有一个循环,每次循环都会将这四个静态变量赋值为0,之后开启两个线程,在线程1中奖a赋值为1,b的值赋值给x,线程2中将b赋值为1,a的值赋值给y。等到两个线程执行完毕后,如果x和y都为0,则跳出循环。
public class ReOrderTest {
private static int x = 0, y = 0;
private static int a = 0, b = 0;
public static void main(String[] args) {
int i = 0;
while (true) {
i++;
x = 0;
y = 0;
a = 0;
b = 0;
Thread thread1 = new Thread(() -> {
a = 1;//<1>
x = b;//<2>
});
Thread thread2 = new Thread(() -> {
b = 1;//<3>
y = a;//<4>
});
thread1.start();
thread2.start();
try {
thread1.join();
thread2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("第" + i + "次:x=" + x + " y=" + y + "");
if (x == 0 && y == 0) {
break;
}
}
}
}
运行结果:
第1次:x=0 y=1 …… 第86586次:x=0 y=1 第86587次:x=0 y=0
运行上面的程序,我们会发现程序终究会跳出循环,按理来说,我们在线程1给a赋值,在线程2将a的值赋予给y,线程2又对b赋值,在线程1将b的值赋值给x,两个线程执行结束后,x和y本来应该都不为0,那为什么会出现x和y同时为0跳出循环的情况?可能有人想到线程的可见性,诚然有可能出现:线程1和线程2同时将这四个静态变量的值拷贝到本地内存,即便线程1对a赋值,线程2对b赋值,但线程1看不到线程2对b的修改,将b在本地内存的拷贝赋值给x,同理线程2将a在本地内存的拷贝赋值给y,因此x和y同时为0,跳出循环。但这里还要考虑到一个重排序的情况,线程1的<1>、<2>代码是可以互换位置的,同理还有线程2的<3>、<4>。考虑下线程1执行重排序后,执行顺序是<2>、<1>,而线程2执行顺序是<4>、<3>,即代码顺序变为:
//线程1 x = b;//<2> a = 1;//<1> //线程2 y = a;//<4> b = 1;//<3>
线程1执行<2>之后,线程2又执行了<4>,之后两个线程即便对a和b赋值,但对x和y来说为时已晚,x和y已经具备跳出循环的条件了。那么,有没有办法解决这个问题呢?这里又要请出我们的关键字volatile了,volatile除了保证可见性,还能保证有序性。只要将ReOrderTest 的四个静态变量标记上volatile,就可以禁止指令重排序。
private static volatile int x = 0, y = 0;
private static volatile int a = 0, b = 0;
volatile之所以可以防止指令重排序,是因为它会在使用倒volatile变量的地方生成一道“栅栏”,“栅栏”的前后指令都不能更换顺序,比如上述四个静态变量标记上volatile关键字后,线程1执行代码的顺序如下:
a = 1; //---栅栏--- x = b; //---栅栏---
变量a的后面会生成一道“栅栏”,编译器和处理器会检测到这道“栅栏”,即便我们的指令在单线程下有优化空间,volatile也能保证处理器执行指令的顺序是按照我们代码所编写的顺序。
另外,笔者之前有提过,执行a=1的执行比x=b的指令更少,处理器应该要优先执行a=1再执行x=b,但实际上Java虚拟机在执行指令的时候情况是不一定的,也有可能优先执行x=b再执行a=1,也就是说JVM虚拟机执行指令的顺序,可能会按照我们编写代码的顺序,也可能会将我们的代码调整顺序后再执行,即便是同一段代码循环执行两次,前后两次的指令顺序,有可能是按我们代码所编写的顺序,也有可能不是。
下面的代码是用于获取单例对象的代码,通过SingleFactory.getInstance()方法我们可以获取到singleFactory对象,在这个方法中,如果singleFactory不为空,则直接返回,如果为空,则进入if分支,在if分支中还有个同步代码块,同步代码块里会再判断一次singleFactory是否为null,避免多线程调用SingleFactory.getInstance(),由于可见性原因,生成多个SingleFactory对象,所以synchronized已经保证了我们的可见性,第一个进入synchronized代码块中的线程,singleFactory一定为null,所以会去初始化对象,而其他同样需要singleFactory对象的线程,会先阻塞在同步代码块之外,等到第一个线程初始化好singleFactory后离开同步代码块,其他线程进入时singleFactory已经不为null了。但我们注意到一点,为什么synchronized已经保证了可见性,singleFactory这个静态变量还要用volatile关键字来标记呢?
public class SingleFactory {
private static volatile SingleFactory singleFactory;
private SingleFactory() {
}
public static SingleFactory getInstance() {
if (singleFactory == null) {
synchronized (SingleFactory.class) {
if (singleFactory == null) {
singleFactory = new SingleFactory();
}
}
}
return singleFactory;
}
}
诚然,volatile和synchronized都能保证可见性,但这里的volatile不是用来保证可见性的,而是禁止指令重排序的。我们来思考一个问题:JVM会如何执行singleFactory = new SingleFactory()这段代码?正常应该会先在堆上分配一块内存,在内存上创建一个SingleFactory对象,最后把singleFactory这个引用指向堆上的SingleFactory对象是不是?但如果一个对象的构建及其复杂,JVM可能会把创建对象的指令优化成先开辟一块内存,将singleFactory的引用指向这块内存,然后再创建这个对象。如果执行的顺序是先开辟内存,再指向内存,最后在内存上创建对象,那么其他线程在调用SingleFactory.getInstance()时,即便对象还没创建好,但singleFactory引用已经不为null了,这个时候如果将singleFactory引用返回并调用其堆上的方法是非常危险的,所以这里需要用volatile禁止指令重排序,并不是为了volatile的可见性,而是让volatile禁止指令重排序,按部就班的分配内存,创建对象,再将引用指向对象。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号