
跨时钟域处理
跨时钟域处理
前言
该文章是我在B站看了数字逻辑君的视频后总结归纳出来的,还有不理解的地方可以移步B站直接看他视频。
在FPGA中信号一般在时钟边沿用D触发器进行采样,正确采集到一个信号的电平需要这个信号在触发器的建立时间(边沿事件前一段时间)和保持时间(边沿事件后一段时间)电平保持稳定,这个时间一般为ns级。当涉及两个不同速度时钟域数据互传时,就会容易产生信号的亚稳态(接收端的触发器在时钟有效沿附近采样到正在变化的信号,导致输出在0和1之间振荡,无法在有限时间内稳定到确定逻辑电平的现象)。其现象如下图所示:
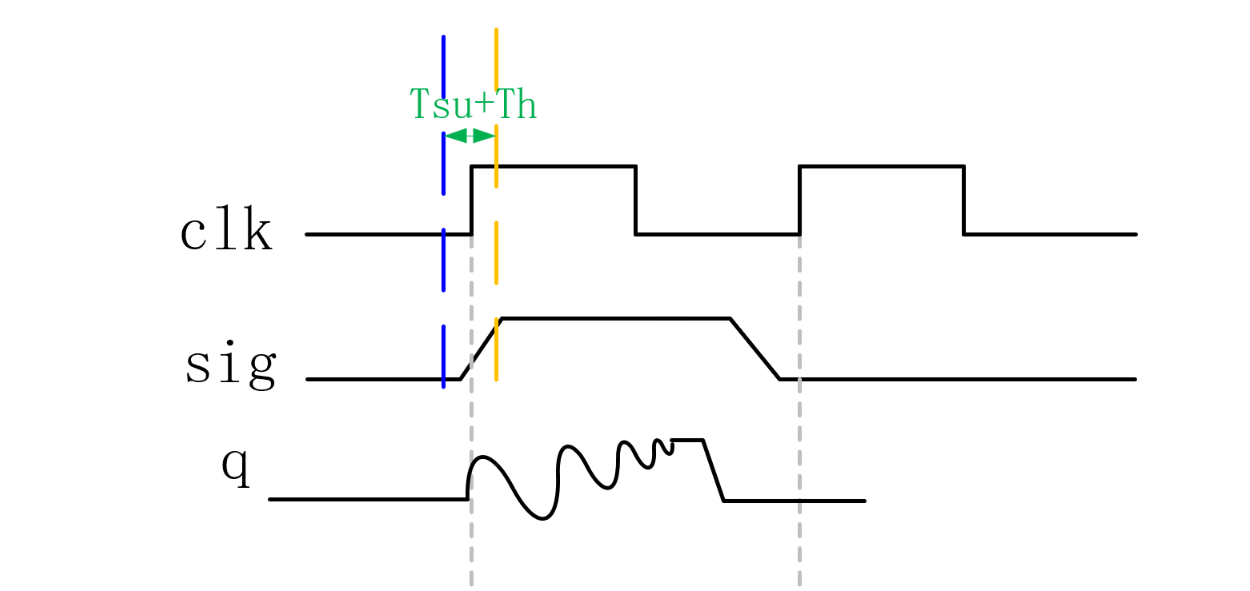
顺便一提,这种现象是无法避免的,我们能做的只是减小这种现象发生的概率,针对这种现象,我们需要进行信号的跨时钟域处理,评判系统在亚稳态处理上是否合格常用MTBF(Mean Time Between Failure),即两次失效之间的平均时间,只要平均时间达标就可以。
信号的跨时钟域处理
对于单bit信号的跨时钟处理一般有:打拍同步、展宽打拍同步、快时钟到慢时钟、速度比较等。
对于多bit信号跨时钟处理一般有:格雷码同步、多bit握手同步、Dmux、异步fifo、异步ram等。
单bit信号跨时钟域处理
我们首先来讲一下单bit信号跨时钟域的常见处理。单bit信号跨时钟有两种情况,一种为快时钟到慢时钟,一种为慢时钟到快时钟。
单bit信号慢时钟到快时钟的处理
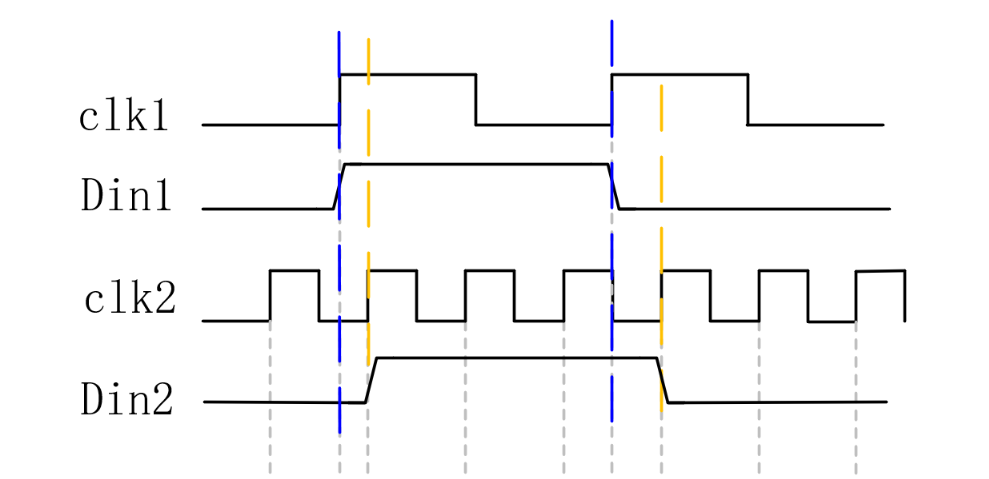
一般来说慢时钟到快时钟的信号很好处理,我们直接用快时钟对信号进行打两拍就可以了,但是还是可能导致脉冲展宽或减少,如下图所示:
我们用简单的代码做示例:
module sync_single_bit_slow2fast (
input wire clk_fast, // 快时钟域时钟
input wire rst_n, // 异步复位,低有效
input wire data_slow, // 来自慢时钟域的单比特信号
output wire data_fast // 同步到快时钟域的输出信号
);
// 两级触发器同步寄存器
reg [1:0] sync_reg;
always @(posedge clk_fast or negedge rst_n) begin
if (!rst_n) begin
sync_reg <= 2'b00;
end else begin
sync_reg <= {sync_reg[0], data_slow};
end
end
// 同步后的信号
assign data_fast = sync_reg[1];
endmodule
单bit信号快时钟到慢时钟的处理
脉冲展宽处理
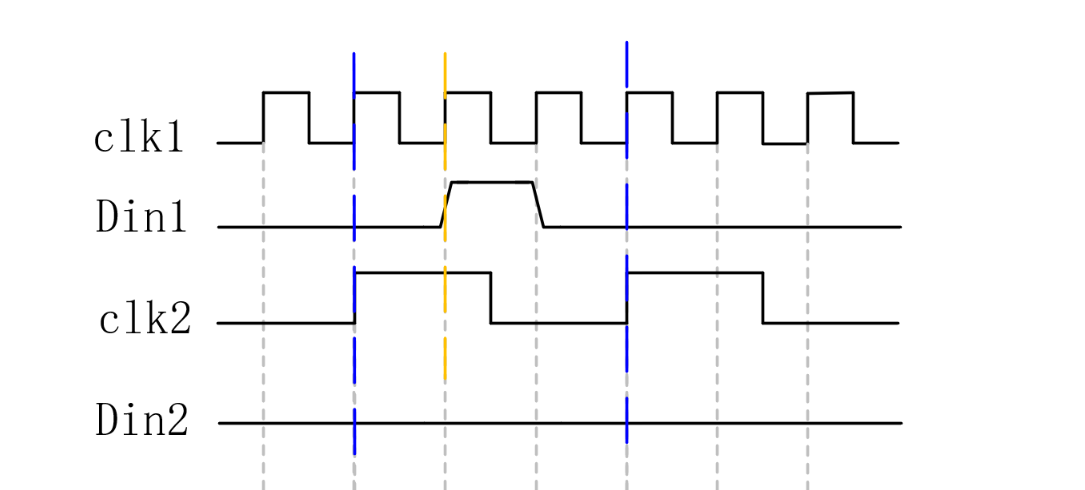
快时钟到慢时钟则需要更加复杂一点,因为有可能信号在慢时钟会捕捉不到,如下图所示:
因此,对于快时钟信号到慢时钟域的情况,第一种方法我们可以在快时钟域对信号进行打拍展宽,令脉宽长到足够被慢时钟域捕获。如下图所示:
我们做一个简单的代码示例:
`timescale 1 ns / 1 ns
module SingleBit_fast_to_slow
#(
parameter FAST_CLK_FREQ = 1000000, // 1MHz
parameter SLOW_CLK_FREQ = 100000 // 100kHz
) (
input wire clk_fast , // 快时钟域时钟
input wire clk_slow , // 慢时钟域时钟
input wire rst_n , // 异步复位,低有效
input wire data_fast , // 来自快时钟域的单比特信号
output wire data_slow // 同步到慢时钟域的输出信号
);
// 计算展宽周期:至少3个慢时钟周期以确保被采样到
localparam BROADEN_CNT = (FAST_CLK_FREQ/SLOW_CLK_FREQ) * 3;
localparam CNT_WIDTH = $clog2(BROADEN_CNT+1);
reg r_data_fast_broaden;
reg [CNT_WIDTH-1:0] r_cnt_data;
reg [1:0] r_data_sync; // 两级同步寄存器
// 检测 data_fast 的上升沿
reg data_fast_dly;
wire data_fast_posedge;
always @(posedge clk_fast or negedge rst_n) begin
if (!rst_n) begin
data_fast_dly <= 1'b0;
end else begin
data_fast_dly <= data_fast;
end
end
assign data_fast_posedge = data_fast && !data_fast_dly;
// 脉冲展宽逻辑
always @(posedge clk_fast or negedge rst_n) begin
if (!rst_n) begin
r_data_fast_broaden <= 1'b0;
r_cnt_data <= 0;
end
else begin
if (data_fast_posedge) begin
// 检测到上升沿,开始展宽
r_data_fast_broaden <= 1'b1;
r_cnt_data <= BROADEN_CNT - 1; // 开始计数
end
else if (r_cnt_data > 0) begin
// 计数器递减
r_cnt_data <= r_cnt_data - 1;
r_data_fast_broaden <= 1'b1; // 保持高电平
end
else begin
// 展宽结束
r_data_fast_broaden <= 1'b0;
end
end
end
// 慢时钟域:两级同步器
always @(posedge clk_slow or negedge rst_n) begin
if (!rst_n) begin
r_data_sync <= 2'b00;
end
else begin
// 打两拍同步
r_data_sync <= {r_data_sync[0], r_data_fast_broaden};
end
end
// 检测同步后信号的上升沿作为输出
reg r_data_sync_dly;
always @(posedge clk_slow or negedge rst_n) begin
if (!rst_n) begin
r_data_sync_dly <= 1'b0;
end else begin
r_data_sync_dly <= r_data_sync[1];
end
end
// 输出:检测慢时钟域中展宽信号的上升沿
assign data_slow = r_data_sync[1] && !r_data_sync_dly;
endmodule
反转与序列检测方法
当然,第一种方法有个弊端,当两个时钟速度差距过大时(比如差1000倍以上),你可能需要展宽成千上万次,造成资源的浪费。因此,我们还有第二种方法,就是通过反转与序列检测,将快时钟的脉冲信号变成电平变化,电路的rtl视图如下图所示:
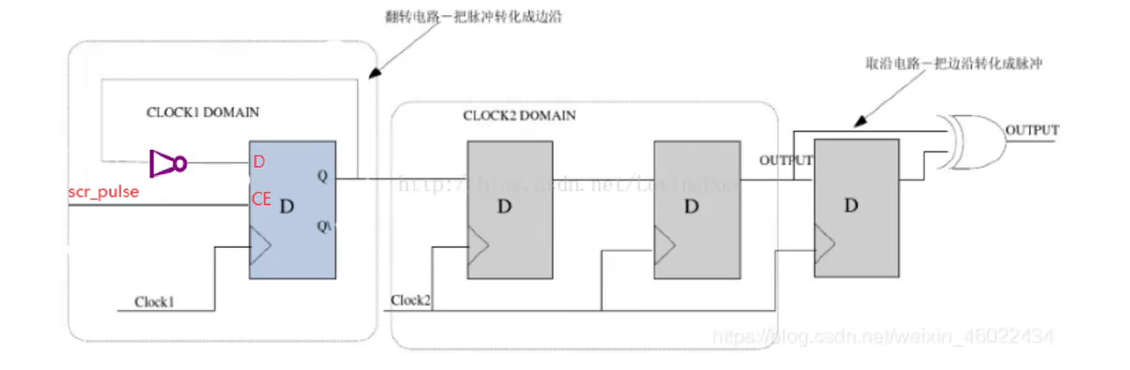
如图,第一级的D触发器使能端连接单bit信号,当单bit信号产生脉冲时,第一级的D触发器电平就会反向,再经过后面在慢时钟域的两级触发器打拍处理,并在最后一个D触发器进行异或边沿检测,再次将电平信息转换成脉冲信息,实现快时钟域到慢时钟域,资源消耗很少。
我们做一个简单的代码示例:
`timescale 1 ns / 1 ns
module fast_to_slow_sync_optimized
(
input wire clk_fast, // 快时钟
input wire clk_slow, // 慢时钟
input wire rst_n, // 异步复位
input wire src_pulse, // 快时钟域脉冲
output wire dst_pulse // 慢时钟域脉冲
);
reg src_toggle_reg;
always @(posedge clk_fast or negedge rst_n) begin
if (!rst_n) begin
src_toggle_reg <= 1'b0;
end else if (src_pulse) begin
src_toggle_reg <= ~src_toggle_reg;
end
end
reg [2:0] sync_chain;
always @(posedge clk_slow or negedge rst_n) begin
if (!rst_n) begin
sync_chain <= 3'b000;
end else begin
sync_chain <= {sync_chain[1:0], src_toggle_reg};
end
end
//边沿检测
assign dst_pulse = sync_chain[2] ^ sync_chain[1];
endmodule
总结
不管是脉冲展宽法,还是反转与序列检测的方法还是会存在问题。当快时钟域的单脉冲信号,一直产生,并且脉冲之间的间隔比较短的时候,还是会存在问题。因为快时钟域的信号频率快,所以快时钟域的信号密度会更大,慢时钟域能够显现的密度比较小,因此如果跨时钟域的信号密度比较大,超过慢时钟域的信号密度极限,在这种条件下的单bit信号的跨时钟域处理过程中是一定会出现数据丢失的。
信号的跨时钟域处理归根结底不仅需要做到两个时钟域的数据的传输,还需要做到两边时钟域信号密度的对等,实际上,经过后面的跨时钟域学习,大家会发现,不管是快到慢还是慢到快最终都是需要做到信息密度上面的同速处理。
多bit时钟的跨时钟域处理
单比特信号通过两级同步器可以大幅降低亚稳态传播概率,但多比特信号中,每个比特都可能独立进入亚稳态。即使每个比特的亚稳态概率都很低,当比特数增加时,至少有一个比特出现亚稳态的概率会显著提高。
格雷码同步法
雷码同步法是跨时钟域处理中用于多比特信号同步的经典方法,特别适用于异步FIFO的读写指针同步。格雷码是一种循环二进制编码,其核心特点是相邻数值之间只有一位发生变化。例如,从3(二进制011)到4(二进制100)需要三位同时翻转,而格雷码的3(010)到4(110)只有一位变化。
格雷码同步法需要满足的条件
格雷码+同步的方法仅仅适用于满足下面两种情况
(1)多bit的跨时钟数据必须数值依次增大或者减少的数据线或者地址线。
(2)必须是慢时钟域信号跨到快时钟域信号。
这种多bit信号的跨时钟域处理的方式实际上是针对数据逐次加1或者逐次减1的地址数据,这种地址数据转化为格雷码之后,其连续数据之间只会存在单bit信号的变化,这种方式就会将多bit的问题变成单bit的问题。如果信号的变化规则不满足上述条件,则无法使用这种同步方法。
格雷码和二进制码的转换方法
以下表格为普通二进制数和格雷码转换表:
| 十进制数 | 二进制码 | 格雷码 | 十进制数 | 二进制码 | 格雷码 |
|---|---|---|---|---|---|
| 0 | 0000 | 0000 | 8 | 1000 | 1100 |
| 1 | 0001 | 0001 | 9 | 1001 | 1101 |
| 2 | 0010 | 0011 | 10 | 1010 | 1111 |
| 3 | 0011 | 0010 | 11 | 1011 | 1110 |
| 4 | 0100 | 0110 | 12 | 1100 | 1010 |
| 5 | 0101 | 0111 | 13 | 1101 | 1011 |
| 6 | 0110 | 0101 | 14 | 1110 | 1001 |
| 7 | 0111 | 0100 | 15 | 1111 | 1000 |
我们用简单的数学关系去归纳:
对于n+1位的二进制码Bn...B3B2B1B0,我们需要n+1位的格雷码Rn ...R3R2R1R0去表示,格雷码的最高位Rn =二进制码的最高位Bn,格雷码的其余位Ri=Bi+1⊕Bi。反之,二进制码的最高位Bn=格雷码的最高位Rn,二进制码的其余位Bi=Bi+1⊕Ri。
格雷码同步法跨时钟域的实现
我们给出简单的代码示例:
module gray_cdc (
input i_clk1, // 时钟域1
input [3:0] i_din1, // 时钟域1的4位输入数据
input i_clk2, // 时钟域2
output reg [3:0] o_dout // 时钟域2的4位输出数据
);
wire [3:0] w_din_gray; // 格雷码转换后的数据
reg [3:0] r_din_gray_d0; // 第一级同步寄存器
reg [3:0] r_din_gray_d1; // 第二级同步寄存器
assign w_din_gray = (i_din1 >> 1) ^ i_din1;
always @(posedge i_clk2) begin
r_din_gray_d0 <= w_din_gray;
r_din_gray_d1 <= r_din_gray_d0;
end
assign o_dout = r_din_gray_d1;
endmodule
握手同步法
如果不是依次变化的数值,不是由慢时钟域跨到快时钟域,则无法使用格雷码+同步的方法实现。于是我们请出第二种多bit跨时钟域方法——握手同步法。
握手同步法的原理简述
握手同步法实际上就是数据发送端在发送多bit数据的同时也需要提供数据发送请求req信号。reg信号为一个单bit信号,并且reg信号在没有和ack信号握手之前不发生变化,即不受时钟频率差的影响。发送端时钟域的reg信号会跨时钟同步到接收端时钟域,当同步之后的reg信号和ack信号同时为高的时候,即说明传输握手成功。ack信号由接收时钟域产生,需要同步到发送时钟域,发送时钟域接收到经过同步之后的ack信号,就意味着当前的信号传输已经结束,故会将相关的req信号拉低,然后准备下一次需要发送的数据。当下一次发送的数据准备好之后,再次拉高相关的req信号和输出新的数据。
以下为握手时序图:
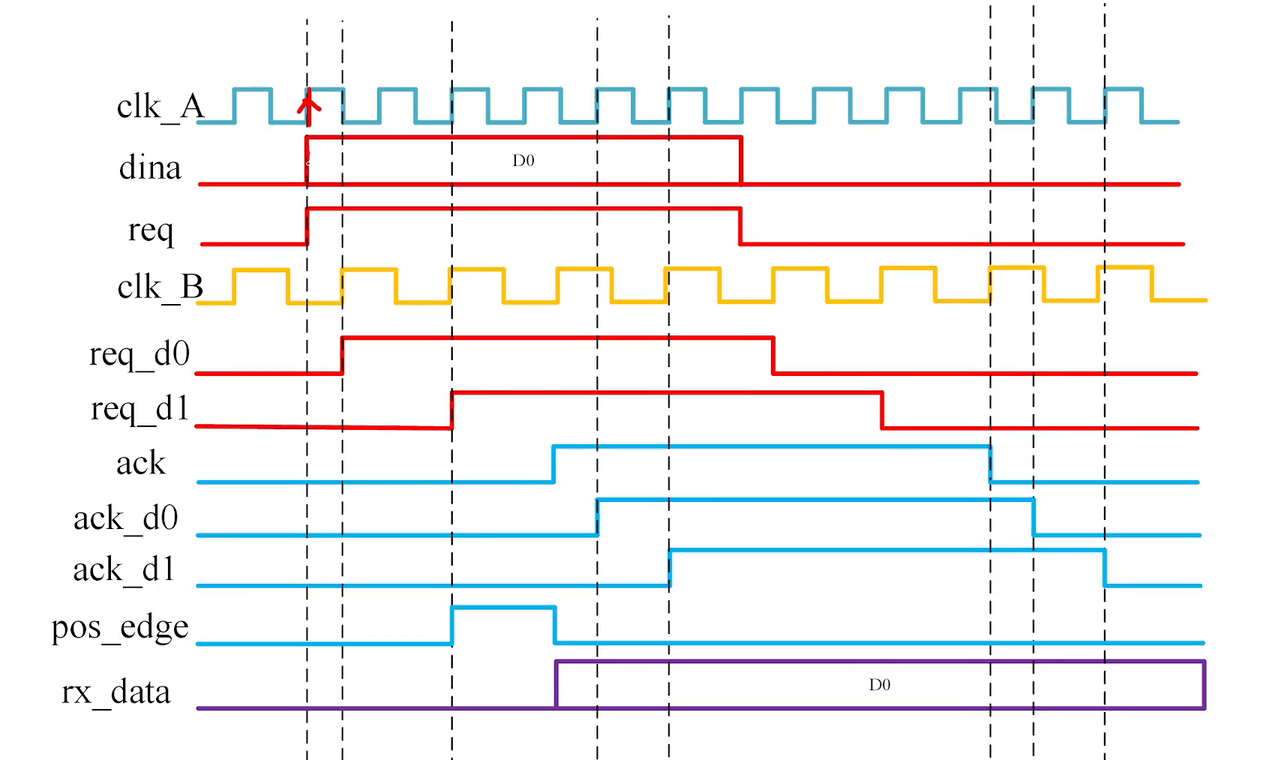
握手同步法的简单实现
数据发送端的代码示例
`timescale 1 ns / 1 ns
module data_driver
#(
parameter DATA_WIDTH = 16
)(
input wire i_clk_a , // 发送时钟域时钟
input wire i_clk_b , // 接收时钟域时钟
input wire i_rst_n , // 异步复位,低有效
input wire i_ack_b , // a时钟域握手请求
output wire [DATA_WIDTH-1:0] o_data_a , // a时钟域数据
output wire o_req_a // b时钟域握手回应
);
reg [1:0] r_ack ;
reg r_ack_delay ;
reg [DATA_WIDTH-1:0] r_data_d0 ;
reg r_req_a_d0 ;
reg r_req_a_d1 ;
reg r_req_a ;
reg r_data_ready;
wire ack_pos ;
wire req_neg ;
assign o_data_a = r_data_d0;
assign ack_pos = r_ack[1] & (!r_ack_delay); //捕捉应答信号上升沿
assign req_neg = !r_req_a_d0 & r_req_a_d1 ; //捕捉申请信号下降沿
assign o_req_a = r_req_a ;
always@(posedge i_clk_a or negedge i_rst_n) begin
if(!i_rst_n) begin
r_req_a_d0 <= 0;
r_req_a_d1 <= 0;
end
else
r_req_a_d0 <= r_req_a; //数据随便生成的
r_req_a_d1 <= r_req_a_d0;
end
always@(posedge i_clk_a or negedge i_rst_n) begin
if(!i_rst_n) begin
r_ack <= 2'b00;
end
else
r_ack <= {r_ack[0],i_ack_b}; //数据随便生成的
end
always@(posedge i_clk_a or negedge i_rst_n) begin
if(!i_rst_n) begin
r_ack_delay <= 1'b0;
end
else
r_ack_delay <= r_ack[1];
end
always@(posedge i_clk_a or negedge i_rst_n) begin
if(!i_rst_n) begin
r_data_ready <= 0;
end
else if(req_neg)
r_data_ready <= 1'b1;
else
r_data_ready <= 1'b0;
end
always@(posedge i_clk_a or negedge i_rst_n) begin
if(!i_rst_n) begin
r_data_d0 <= 0;
end
else if(req_neg)
r_data_d0 <= r_data_d0+1; //数据随便生成的
end
always@(posedge i_clk_a or negedge i_rst_n) begin
if(!i_rst_n) begin
r_req_a <= 0;
end
else if(ack_pos) //接收到应答信号将req信号拉低
r_req_a <= 1'b0;
else if(r_data_ready)
r_req_a <= 1'b1;
else
r_req_a <= r_req_a;
end
endmodule
数据接收端的代码示例:
`timescale 1 ns / 1 ns
module data_receive
#(
parameter DATA_WIDTH = 16
)(
input wire i_clk_a , // 发送时钟域时钟
input wire i_clk_b , // 接收时钟域时钟
input wire i_rst_n , // 异步复位,低有效
input wire [DATA_WIDTH-1:0] i_data_a , // a时钟域数据
input wire i_req_a , // a时钟域握手请求
output wire o_ack_b // b时钟域握手回应
);
reg [1:0] r_req ;
reg [DATA_WIDTH-1:0] r_data_d0 ;
reg [DATA_WIDTH-1:0] r_data_d1 ;
reg r_ack ;
wire req_pos ;
assign o_ack_b = r_ack;
assign req_pos = r_req[1] & (!r_ack);
always@(posedge i_clk_b or negedge i_rst_n) begin //握手请求两级打拍
if(!i_rst_n) begin
r_req <= 2'b00;
end
else
r_req <= {r_req[0],i_req_a};
end
always@(posedge i_clk_b or negedge i_rst_n) begin
if(!i_rst_n) begin
r_data_d0 <=0;
end
else if(req_pos)
r_data_d0 <= i_data_a;
else
r_data_d0 <= r_data_d0;
end
always@(posedge i_clk_b or negedge i_rst_n) begin
if(!i_rst_n) begin
r_data_d1 <=0;
end
else
r_data_d1 <= r_data_d0;
end
always@(posedge i_clk_b or negedge i_rst_n) begin
if(!i_rst_n) begin
r_ack <=1'b0;
end
else if(r_req[1])
r_ack <= 1'b1;
else
r_ack <= 1'b0;
end
endmodule
dmux同步法
Dmux这种多bit信号的CDC跨时钟域处理实际上也是一种给多bit信号增加valid信号的方法,它的核心思想是利用多bit信号的valid信号,将valid信号进行跨时钟域处理,Dmux的CDC跨时钟传输也是会受到目的时钟域和发送时钟域时钟频率的影响。
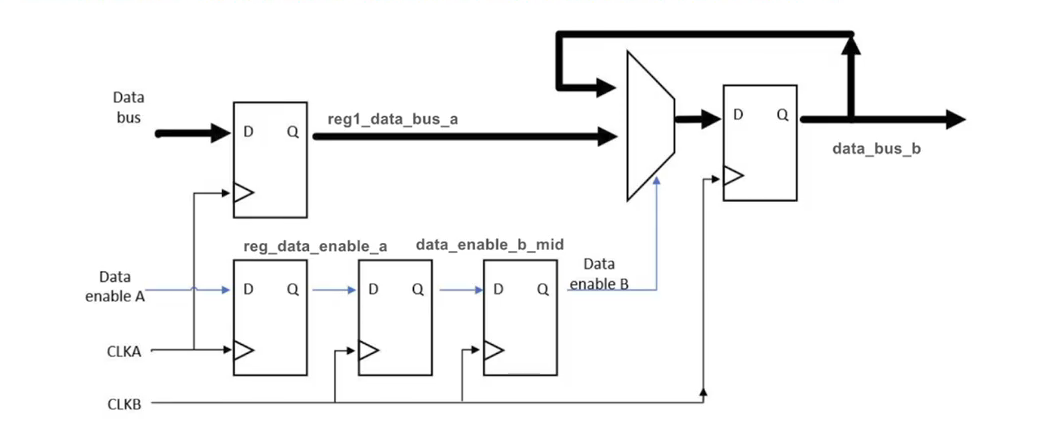
下面来先讲一下Dmux的操作流程,首先数据发送端时钟域准备好数据,拉高vaild信号,持续一个或数个周期,然后对数据和vaild信号在发送端时钟进行打拍,接收端时钟对已经在发送端时钟域打拍的vaild信号进行跨时钟处理(用单bit跨时钟处理方法),然后在接收端时钟域下,接收在发送端时钟域打拍的数据。
以下为逻辑视图:
我们再看一下从慢时钟跨到快时钟的DMUX跨时钟域方法的时序图示例:
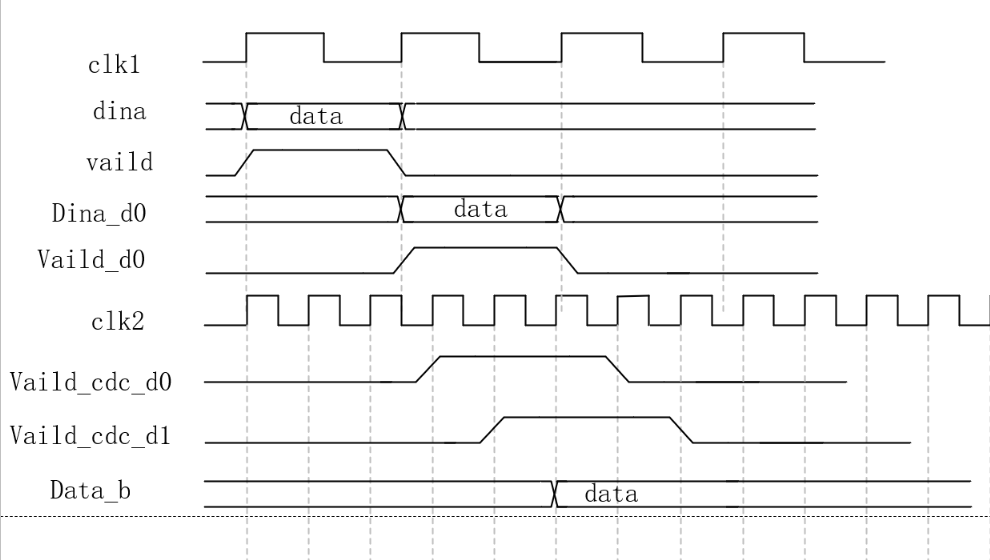
dmux方法的限制
dmux传输实际上存的限制:
(1)不管是慢到快,还是快到慢,dmux传递的信号都是必须满足一定的时序条件。
(2)即发送端的信号维持时间必须至少大于接收端时钟的三个周期,才能满足单bit跨时钟域的要求。
(3)不然valid有效信号跨过去之后,发现多bit数据data失效了是无法满足dmux条件了。
(4)同时也要保证dmux输出的validout信号和传递之后的data信号维持一致。
dmux的代码实现
module simple_cdc #(
parameter WIDTH = 8
) (
input wire clk_a,
input wire clk_b,
input wire [WIDTH-1:0] data_in,
input wire data_en_a,
output reg [WIDTH-1:0] data_b
);
// 发送端时钟域:数据打一拍
reg [WIDTH-1:0] data_reg_a;
always @(posedge clk_a) begin
data_reg_a <= data_in;
end
// 发送端时钟域:vaild信号打一拍
reg data_en_a_d0;
always @(posedge clk_a) begin
data_en_a_d0 <= data_en_a;
end
// valid信号同步
reg [1:0] en_sync;
always @(posedge clk_b) begin
en_sync[0] <= data_en_a_d0;
en_sync[1] <= en_sync[0];
end
// 目标时钟域数据锁存
always @(posedge clk_b) begin
if (en_sync[1]) begin
data_b <= data_reg_a; // 使用同步后的使能信号锁存数据
end
end
endmodule
异步fifo和异步ram
异步RAMI和异步FIFO是针对快速变化、高吞吐量信号跨时钟处理的主要方法,其中异步RAM需要控制两个时钟域对应的使能信号、时钟信号和地址信号,而异步FIFO则只需要控制两个时钟域对应的使能信号和时钟信号即可,无需地址信号。
我觉得异步fifo和异步ram方法都很类似,就是把发送端先把数据存起来,然后接收端在另一边读。这应该很容易理解,这里就不做具体原理解释和代码示例了。
结束语
以上就是FPGA跨时钟域的主要方法,在这里感谢数字逻辑君的视频。# 跨时钟域处理
前言
该文章是我在B站看了数字逻辑君的视频后总结归纳出来的,还有不理解的地方可以移步B站直接看他视频。
在FPGA中信号一般在时钟边沿用D触发器进行采样,正确采集到一个信号的电平需要这个信号在触发器的建立时间(边沿事件前一段时间)和保持时间(边沿事件后一段时间)电平保持稳定,这个时间一般为ns级。当涉及两个不同速度时钟域数据互传时,就会容易产生信号的亚稳态(接收端的触发器在时钟有效沿附近采样到正在变化的信号,导致输出在0和1之间振荡,无法在有限时间内稳定到确定逻辑电平的现象)。其现象如下图所示:
顺便一提,这种现象是无法避免的,我们能做的只是减小这种现象发生的概率,针对这种现象,我们需要进行信号的跨时钟域处理,评判系统在亚稳态处理上是否合格常用MTBF(Mean Time Between Failure),即两次失效之间的平均时间,只要平均时间达标就可以。
信号的跨时钟域处理
对于单bit信号的跨时钟处理一般有:打拍同步、展宽打拍同步、快时钟到慢时钟、速度比较等。
对于多bit信号跨时钟处理一般有:格雷码同步、多bit握手同步、Dmux、异步fifo、异步ram等。
单bit信号跨时钟域处理
我们首先来讲一下单bit信号跨时钟域的常见处理。单bit信号跨时钟有两种情况,一种为快时钟到慢时钟,一种为慢时钟到快时钟。
单bit信号慢时钟到快时钟的处理
一般来说慢时钟到快时钟的信号很好处理,我们直接用快时钟对信号进行打两拍就可以了,但是还是可能导致脉冲展宽或减少,如下图所示:
我们用简单的代码做示例:
module sync_single_bit_slow2fast (
input wire clk_fast, // 快时钟域时钟
input wire rst_n, // 异步复位,低有效
input wire data_slow, // 来自慢时钟域的单比特信号
output wire data_fast // 同步到快时钟域的输出信号
);
// 两级触发器同步寄存器
reg [1:0] sync_reg;
always @(posedge clk_fast or negedge rst_n) begin
if (!rst_n) begin
sync_reg <= 2'b00;
end else begin
sync_reg <= {sync_reg[0], data_slow};
end
end
// 同步后的信号
assign data_fast = sync_reg[1];
endmodule
单bit信号快时钟到慢时钟的处理
脉冲展宽处理
快时钟到慢时钟则需要更加复杂一点,因为有可能信号在慢时钟会捕捉不到,如下图所示:
因此,对于快时钟信号到慢时钟域的情况,第一种方法我们可以在快时钟域对信号进行打拍展宽,令脉宽长到足够被慢时钟域捕获。如下图所示:
我们做一个简单的代码示例:
`timescale 1 ns / 1 ns
module SingleBit_fast_to_slow
#(
parameter FAST_CLK_FREQ = 1000000, // 1MHz
parameter SLOW_CLK_FREQ = 100000 // 100kHz
) (
input wire clk_fast , // 快时钟域时钟
input wire clk_slow , // 慢时钟域时钟
input wire rst_n , // 异步复位,低有效
input wire data_fast , // 来自快时钟域的单比特信号
output wire data_slow // 同步到慢时钟域的输出信号
);
// 计算展宽周期:至少3个慢时钟周期以确保被采样到
localparam BROADEN_CNT = (FAST_CLK_FREQ/SLOW_CLK_FREQ) * 3;
localparam CNT_WIDTH = $clog2(BROADEN_CNT+1);
reg r_data_fast_broaden;
reg [CNT_WIDTH-1:0] r_cnt_data;
reg [1:0] r_data_sync; // 两级同步寄存器
// 检测 data_fast 的上升沿
reg data_fast_dly;
wire data_fast_posedge;
always @(posedge clk_fast or negedge rst_n) begin
if (!rst_n) begin
data_fast_dly <= 1'b0;
end else begin
data_fast_dly <= data_fast;
end
end
assign data_fast_posedge = data_fast && !data_fast_dly;
// 脉冲展宽逻辑
always @(posedge clk_fast or negedge rst_n) begin
if (!rst_n) begin
r_data_fast_broaden <= 1'b0;
r_cnt_data <= 0;
end
else begin
if (data_fast_posedge) begin
// 检测到上升沿,开始展宽
r_data_fast_broaden <= 1'b1;
r_cnt_data <= BROADEN_CNT - 1; // 开始计数
end
else if (r_cnt_data > 0) begin
// 计数器递减
r_cnt_data <= r_cnt_data - 1;
r_data_fast_broaden <= 1'b1; // 保持高电平
end
else begin
// 展宽结束
r_data_fast_broaden <= 1'b0;
end
end
end
// 慢时钟域:两级同步器
always @(posedge clk_slow or negedge rst_n) begin
if (!rst_n) begin
r_data_sync <= 2'b00;
end
else begin
// 打两拍同步
r_data_sync <= {r_data_sync[0], r_data_fast_broaden};
end
end
// 检测同步后信号的上升沿作为输出
reg r_data_sync_dly;
always @(posedge clk_slow or negedge rst_n) begin
if (!rst_n) begin
r_data_sync_dly <= 1'b0;
end else begin
r_data_sync_dly <= r_data_sync[1];
end
end
// 输出:检测慢时钟域中展宽信号的上升沿
assign data_slow = r_data_sync[1] && !r_data_sync_dly;
endmodule
反转与序列检测方法
当然,第一种方法有个弊端,当两个时钟速度差距过大时(比如差1000倍以上),你可能需要展宽成千上万次,造成资源的浪费。因此,我们还有第二种方法,就是通过反转与序列检测,将快时钟的脉冲信号变成电平变化,电路的rtl视图如下图所示:
如图,第一级的D触发器使能端连接单bit信号,当单bit信号产生脉冲时,第一级的D触发器电平就会反向,再经过后面在慢时钟域的两级触发器打拍处理,并在最后一个D触发器进行异或边沿检测,再次将电平信息转换成脉冲信息,实现快时钟域到慢时钟域,资源消耗很少。
我们做一个简单的代码示例:
`timescale 1 ns / 1 ns
module fast_to_slow_sync_optimized
(
input wire clk_fast, // 快时钟
input wire clk_slow, // 慢时钟
input wire rst_n, // 异步复位
input wire src_pulse, // 快时钟域脉冲
output wire dst_pulse // 慢时钟域脉冲
);
reg src_toggle_reg;
always @(posedge clk_fast or negedge rst_n) begin
if (!rst_n) begin
src_toggle_reg <= 1'b0;
end else if (src_pulse) begin
src_toggle_reg <= ~src_toggle_reg;
end
end
reg [2:0] sync_chain;
always @(posedge clk_slow or negedge rst_n) begin
if (!rst_n) begin
sync_chain <= 3'b000;
end else begin
sync_chain <= {sync_chain[1:0], src_toggle_reg};
end
end
//边沿检测
assign dst_pulse = sync_chain[2] ^ sync_chain[1];
endmodule
总结
不管是脉冲展宽法,还是反转与序列检测的方法还是会存在问题。当快时钟域的单脉冲信号,一直产生,并且脉冲之间的间隔比较短的时候,还是会存在问题。因为快时钟域的信号频率快,所以快时钟域的信号密度会更大,慢时钟域能够显现的密度比较小,因此如果跨时钟域的信号密度比较大,超过慢时钟域的信号密度极限,在这种条件下的单bit信号的跨时钟域处理过程中是一定会出现数据丢失的。
信号的跨时钟域处理归根结底不仅需要做到两个时钟域的数据的传输,还需要做到两边时钟域信号密度的对等,实际上,经过后面的跨时钟域学习,大家会发现,不管是快到慢还是慢到快最终都是需要做到信息密度上面的同速处理。
多bit时钟的跨时钟域处理
单比特信号通过两级同步器可以大幅降低亚稳态传播概率,但多比特信号中,每个比特都可能独立进入亚稳态。即使每个比特的亚稳态概率都很低,当比特数增加时,至少有一个比特出现亚稳态的概率会显著提高。
格雷码同步法
雷码同步法是跨时钟域处理中用于多比特信号同步的经典方法,特别适用于异步FIFO的读写指针同步。格雷码是一种循环二进制编码,其核心特点是相邻数值之间只有一位发生变化。例如,从3(二进制011)到4(二进制100)需要三位同时翻转,而格雷码的3(010)到4(110)只有一位变化。
格雷码同步法需要满足的条件
格雷码+同步的方法仅仅适用于满足下面两种情况
(1)多bit的跨时钟数据必须数值依次增大或者减少的数据线或者地址线。
(2)必须是慢时钟域信号跨到快时钟域信号。
这种多bit信号的跨时钟域处理的方式实际上是针对数据逐次加1或者逐次减1的地址数据,这种地址数据转化为格雷码之后,其连续数据之间只会存在单bit信号的变化,这种方式就会将多bit的问题变成单bit的问题。如果信号的变化规则不满足上述条件,则无法使用这种同步方法。
格雷码和二进制码的转换方法
以下表格为普通二进制数和格雷码转换表:
| 十进制数 | 二进制码 | 格雷码 | 十进制数 | 二进制码 | 格雷码 |
|---|---|---|---|---|---|
| 0 | 0000 | 0000 | 8 | 1000 | 1100 |
| 1 | 0001 | 0001 | 9 | 1001 | 1101 |
| 2 | 0010 | 0011 | 10 | 1010 | 1111 |
| 3 | 0011 | 0010 | 11 | 1011 | 1110 |
| 4 | 0100 | 0110 | 12 | 1100 | 1010 |
| 5 | 0101 | 0111 | 13 | 1101 | 1011 |
| 6 | 0110 | 0101 | 14 | 1110 | 1001 |
| 7 | 0111 | 0100 | 15 | 1111 | 1000 |
我们用简单的数学关系去归纳:
对于n+1位的二进制码Bn...B3B2B1B0,我们需要n+1位的格雷码Rn ...R3R2R1R0去表示,格雷码的最高位Rn =二进制码的最高位Bn,格雷码的其余位Ri=Bi+1⊕Bi。反之,二进制码的最高位Bn=格雷码的最高位Rn,二进制码的其余位Bi=Bi+1⊕Ri。
格雷码同步法跨时钟域的实现
我们给出简单的代码示例:
module gray_cdc (
input i_clk1, // 时钟域1
input [3:0] i_din1, // 时钟域1的4位输入数据
input i_clk2, // 时钟域2
output reg [3:0] o_dout // 时钟域2的4位输出数据
);
wire [3:0] w_din_gray; // 格雷码转换后的数据
reg [3:0] r_din_gray_d0; // 第一级同步寄存器
reg [3:0] r_din_gray_d1; // 第二级同步寄存器
assign w_din_gray = (i_din1 >> 1) ^ i_din1;
always @(posedge i_clk2) begin
r_din_gray_d0 <= w_din_gray;
r_din_gray_d1 <= r_din_gray_d0;
end
assign o_dout = r_din_gray_d1;
endmodule
握手同步法
如果不是依次变化的数值,不是由慢时钟域跨到快时钟域,则无法使用格雷码+同步的方法实现。于是我们请出第二种多bit跨时钟域方法——握手同步法。
握手同步法的原理简述
握手同步法实际上就是数据发送端在发送多bit数据的同时也需要提供数据发送请求req信号。reg信号为一个单bit信号,并且reg信号在没有和ack信号握手之前不发生变化,即不受时钟频率差的影响。发送端时钟域的reg信号会跨时钟同步到接收端时钟域,当同步之后的reg信号和ack信号同时为高的时候,即说明传输握手成功。ack信号由接收时钟域产生,需要同步到发送时钟域,发送时钟域接收到经过同步之后的ack信号,就意味着当前的信号传输已经结束,故会将相关的req信号拉低,然后准备下一次需要发送的数据。当下一次发送的数据准备好之后,再次拉高相关的req信号和输出新的数据。
以下为握手时序图:
握手同步法的简单实现
数据发送端的代码示例
`timescale 1 ns / 1 ns
module data_driver
#(
parameter DATA_WIDTH = 16
)(
input wire i_clk_a , // 发送时钟域时钟
input wire i_clk_b , // 接收时钟域时钟
input wire i_rst_n , // 异步复位,低有效
input wire i_ack_b , // a时钟域握手请求
output wire [DATA_WIDTH-1:0] o_data_a , // a时钟域数据
output wire o_req_a // b时钟域握手回应
);
reg [1:0] r_ack ;
reg r_ack_delay ;
reg [DATA_WIDTH-1:0] r_data_d0 ;
reg r_req_a_d0 ;
reg r_req_a_d1 ;
reg r_req_a ;
reg r_data_ready;
wire ack_pos ;
wire req_neg ;
assign o_data_a = r_data_d0;
assign ack_pos = r_ack[1] & (!r_ack_delay); //捕捉应答信号上升沿
assign req_neg = !r_req_a_d0 & r_req_a_d1 ; //捕捉申请信号下降沿
assign o_req_a = r_req_a ;
always@(posedge i_clk_a or negedge i_rst_n) begin
if(!i_rst_n) begin
r_req_a_d0 <= 0;
r_req_a_d1 <= 0;
end
else
r_req_a_d0 <= r_req_a; //数据随便生成的
r_req_a_d1 <= r_req_a_d0;
end
always@(posedge i_clk_a or negedge i_rst_n) begin
if(!i_rst_n) begin
r_ack <= 2'b00;
end
else
r_ack <= {r_ack[0],i_ack_b}; //数据随便生成的
end
always@(posedge i_clk_a or negedge i_rst_n) begin
if(!i_rst_n) begin
r_ack_delay <= 1'b0;
end
else
r_ack_delay <= r_ack[1];
end
always@(posedge i_clk_a or negedge i_rst_n) begin
if(!i_rst_n) begin
r_data_ready <= 0;
end
else if(req_neg)
r_data_ready <= 1'b1;
else
r_data_ready <= 1'b0;
end
always@(posedge i_clk_a or negedge i_rst_n) begin
if(!i_rst_n) begin
r_data_d0 <= 0;
end
else if(req_neg)
r_data_d0 <= r_data_d0+1; //数据随便生成的
end
always@(posedge i_clk_a or negedge i_rst_n) begin
if(!i_rst_n) begin
r_req_a <= 0;
end
else if(ack_pos) //接收到应答信号将req信号拉低
r_req_a <= 1'b0;
else if(r_data_ready)
r_req_a <= 1'b1;
else
r_req_a <= r_req_a;
end
endmodule
数据接收端的代码示例:
`timescale 1 ns / 1 ns
module data_receive
#(
parameter DATA_WIDTH = 16
)(
input wire i_clk_a , // 发送时钟域时钟
input wire i_clk_b , // 接收时钟域时钟
input wire i_rst_n , // 异步复位,低有效
input wire [DATA_WIDTH-1:0] i_data_a , // a时钟域数据
input wire i_req_a , // a时钟域握手请求
output wire o_ack_b // b时钟域握手回应
);
reg [1:0] r_req ;
reg [DATA_WIDTH-1:0] r_data_d0 ;
reg [DATA_WIDTH-1:0] r_data_d1 ;
reg r_ack ;
wire req_pos ;
assign o_ack_b = r_ack;
assign req_pos = r_req[1] & (!r_ack);
always@(posedge i_clk_b or negedge i_rst_n) begin //握手请求两级打拍
if(!i_rst_n) begin
r_req <= 2'b00;
end
else
r_req <= {r_req[0],i_req_a};
end
always@(posedge i_clk_b or negedge i_rst_n) begin
if(!i_rst_n) begin
r_data_d0 <=0;
end
else if(req_pos)
r_data_d0 <= i_data_a;
else
r_data_d0 <= r_data_d0;
end
always@(posedge i_clk_b or negedge i_rst_n) begin
if(!i_rst_n) begin
r_data_d1 <=0;
end
else
r_data_d1 <= r_data_d0;
end
always@(posedge i_clk_b or negedge i_rst_n) begin
if(!i_rst_n) begin
r_ack <=1'b0;
end
else if(r_req[1])
r_ack <= 1'b1;
else
r_ack <= 1'b0;
end
endmodule
dmux同步法
Dmux这种多bit信号的CDC跨时钟域处理实际上也是一种给多bit信号增加valid信号的方法,它的核心思想是利用多bit信号的valid信号,将valid信号进行跨时钟域处理,Dmux的CDC跨时钟传输也是会受到目的时钟域和发送时钟域时钟频率的影响。
下面来先讲一下Dmux的操作流程,首先数据发送端时钟域准备好数据,拉高vaild信号,持续一个或数个周期,然后对数据和vaild信号在发送端时钟进行打拍,接收端时钟对已经在发送端时钟域打拍的vaild信号进行跨时钟处理(用单bit跨时钟处理方法),然后在接收端时钟域下,接收在发送端时钟域打拍的数据。
以下为逻辑视图:
我们再看一下从慢时钟跨到快时钟的DMUX跨时钟域方法的时序图示例:
dmux方法的限制
dmux传输实际上存的限制:
(1)不管是慢到快,还是快到慢,dmux传递的信号都是必须满足一定的时序条件。
(2)即发送端的信号维持时间必须至少大于接收端时钟的三个周期,才能满足单bit跨时钟域的要求。
(3)不然valid有效信号跨过去之后,发现多bit数据data失效了是无法满足dmux条件了。
(4)同时也要保证dmux输出的validout信号和传递之后的data信号维持一致。
dmux的代码实现
module simple_cdc #(
parameter WIDTH = 8
) (
input wire clk_a,
input wire clk_b,
input wire [WIDTH-1:0] data_in,
input wire data_en_a,
output reg [WIDTH-1:0] data_b
);
// 发送端时钟域:数据打一拍
reg [WIDTH-1:0] data_reg_a;
always @(posedge clk_a) begin
data_reg_a <= data_in;
end
// 发送端时钟域:vaild信号打一拍
reg data_en_a_d0;
always @(posedge clk_a) begin
data_en_a_d0 <= data_en_a;
end
// valid信号同步
reg [1:0] en_sync;
always @(posedge clk_b) begin
en_sync[0] <= data_en_a_d0;
en_sync[1] <= en_sync[0];
end
// 目标时钟域数据锁存
always @(posedge clk_b) begin
if (en_sync[1]) begin
data_b <= data_reg_a; // 使用同步后的使能信号锁存数据
end
end
endmodule
异步fifo和异步ram
异步RAMI和异步FIFO是针对快速变化、高吞吐量信号跨时钟处理的主要方法,其中异步RAM需要控制两个时钟域对应的使能信号、时钟信号和地址信号,而异步FIFO则只需要控制两个时钟域对应的使能信号和时钟信号即可,无需地址信号。
我觉得异步fifo和异步ram方法都很类似,就是把发送端先把数据存起来,然后接收端在另一边读。这应该很容易理解,这里就不做具体原理解释和代码示例了。
结束语
以上就是FPGA跨时钟域的主要方法,在这里感谢数字逻辑君的视频。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号